







yolo学习心得
一、先验框(anchor)
首先可以把anchor理解为:多尺度滑动窗口。
传统的检测过程是:
1、生成图像金字塔,因为待检测的物体的scale是变化的。
2、用滑动窗口在图片的特征金字塔上面滚动生成很多候选区域。
3、各种特征提取hog和分类器svm来对上面产生的候选区域中的图片信息来分类。
4、NMS非极大值抑制得到最后的结果。
但由于cnn具有强大的提取特征的能力,可以替代第三步,但第一第二步独立于cnn之外的,需要大量循环,速度也限制了,因此要更好的定位,需要更多的scale和radio不同窗口,但又增加了时间。而窗口滑动的时候,本质就是遍历像素的过程,因此直接为每个像素分配不同的尺度和比例的窗口矩形,它们的中心都是其所属的像素点。对于长度和比例的分配们可以根据标注图像信息通过k-means聚类得到。而每个像素分配几个不同长度和比例的窗口举行就是Anchor。一般模型的anchor非常多,因此可以看这些anchor与给定矩形的IOU是否满足条件来决定是否是所要的框。
anchor box就是从训练集中真实框(ground truth)中统计或聚类得到的几个不同尺寸的框。避免模型在训练的时候盲目的找,有助于模型快速收敛。假设每个网格对应k个anchor,也就是模型在训练的时候,它只是会在每一个网格附近找出这k种形状,不会找其他的。anchor其实就是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习的目的。
yolov3使用k-means算法在训练集中所有样本的真实框(ground truth)中聚类,得到具有代表性形状的宽高(维度聚类)。但是具体几个anchor才是最合适的,作者采用实验的方式,分别用不同数量的anchor应用到模型,然后找出最优的在模型的复杂度和高召回率之间这种的那组anchor box,最终的出9个anchor box最佳。
而对于yolov3来说,输出为3个尺度的特征图,分别为13×13、26×26、52×52,对应着9个anchor,每个尺度均分3个anchor。
然而究竟是哪个anchor负责匹配它呢?和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的3个anchor box负责预测它,具体是哪个anchor box预测它,需要在训练中确定,即由那个与ground truth的IOU最大的anchor box预测它,而剩余的2个anchor box不与该ground truth匹配。YOLOv3需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的anchor box计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的anchor box只计算置信度误差(此时target为0)。
有了平移(tx,ty)和尺度缩放(tw,th)才能让anchor box经过微调与grand truth重合。 如图,红色框为anchor box,绿色框为Ground Truth,平移+尺度缩放可实线红色框先平移到虚线红色框,然后再缩放到绿色框。边框回归最简单的想法就是通过平移加尺度缩放进行微调

二、边框预测
论文中边框预测公式如下:
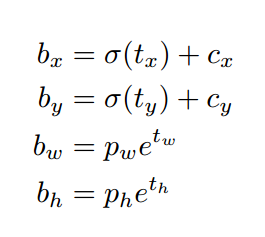
其中,Cx,Cy是feature map中grid cell的左上角坐标,在yolov3中每个grid cell在feature map中的宽和高均为1。如下图1的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故Cx=1,Cy=1.公式中的Pw、Ph是预设的anchor box映射到feature map中的宽和高(anchor box原本设定是相对于416416坐标系下的坐标,在yolov3.cfg文件中写明了,代码中是把cfg中读取的坐标除以stride如32映射到feature map坐标系中)。

最终得到的边框坐标值是bx,by,bw,bh即边界框bbox相对于feature map的位置和大小,是我们需要的预测输出坐标。但我们网络实际上的学习目标是tx,ty,tw,th这4个offsets,其中tx,ty是预测的坐标偏移值,tw,th是尺度缩放,有了这4个offsets,自然可以根据之前的公式去求得真正需要的bx,by,bw,bh4个坐标。至于为何不直接学习bx,by,bw,bh呢?因为YOLO 的输出是一个卷积特征图,包含沿特征图深度的边界框属性。边界框属性由彼此堆叠的单元格预测得出。因此,如果你需要在 (5,6) 处访问该单元格的第二个边框bbox,那么你需要通过 map[5,6, (5+C): 2(5+C)] 将其编入索引。这种格式对于输出处理过程(例如通过目标置信度进行阈值处理、添加对中心的网格偏移、应用锚点等)很不方便,因此我们求偏移量即可。那么这样就只需要求偏移量,也就可以用上面的公式求出bx,by,bw,bh,反正是等价的。另外,通过学习偏移量,就可以通过网络原始给定的anchor box坐标经过线性回归微调(平移加尺度缩放)去逐渐靠近groundtruth.
参考博客















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











