






一个深度学习应用在eeg的综述
基于深度学习的运动想象脑电信号( Electroencephalogram,EEG )分类研究

Abstract
基于脑电信号( Electroencephalogram,EEG )的脑机接口( Brain-Computer Interfaces,BCIs )构建了人脑与外部设备之间的通信通路。在基于EEG的BCI范式中,最常用的是运动想象( Motor imagery,MI )。作为一个热门的研究课题,基于MI EEG的BCI在医疗领域和智能家居行业都有很大的贡献。然而,由于EEG数据的低信噪比和非平稳特性,很难对不同类型的MI - EEG信号进行正确分类。近年来,深度学习( Deep Learning,DL )的发展极大地促进了基于MI EEG的BCI的发展。本文对基于DL的MI - EEG分类方法进行了系统的综述。具体来说,我们首先全面地讨论了基于DL的MI - EEG分类的几个重要方面,包括输入形式,网络结构,公共数据集等。然后,我们总结了模型性能比较中存在的问题,并为未来的性能公平比较研究提供了指导。接下来,我们使用作者发布的源代码对具有代表性的基于DL的模型进行了公正的评估,并对评估结果进行了细致的分析。通过对网络架构进行消融研究,我们发现( 1 )有效的特征融合对于基于多流CNN的模型来说是必不可少的。( 2 ) LSTM应与空间特征提取技术相结合,以获得良好的分类效果。
introduction
脑-机接口( Brain-Computer Interfaces,BCIs )作为人脑与外部设备之间的通信桥梁,已被广泛应用于包括康复训练,机器人控制[ 3 ],运动训练,智能直播[ 4、5],游戏产业[ 6、7 ]和身份识别[ 8 ]。通过解码大脑信号,例如脑电图仪( EEG ),BCI系统可以识别用户的意图并向外部设备发出相应的控制命令。作为记录大脑活动最常用的技术,EEG以其高时间分辨率、数据采集成本低、良好的移动性和对运动的低敏感性而闻名[ 9 ]。目前,已有多种类型的EEG信号被应用于BCI系统中,其中运动想象( Motor Imagery,MI )是最受欢迎的EEG信号之一。
展示了一个标准的基于MI - EEG的BCI系统,该系统由五大部分组成:MI - EEG数据采集、预处理、特征提取、分类和应用接口。在这5个组成部分中,大多数研究者主要关注特征提取部分和分类部分,这两个部分最具挑战性。
随着深度学习( Deep Learning,DL )在计算机视觉( Computer Vision,CV )和自然语言处理( Natural Language Processing,NLP )领域取得的巨大成功,越来越多的研究者将目光投向了深度学习,并开发了基于深度学习的MI - EEG分类模型。其中许多方法,如[ 1012 ],可以超越以前传统的基于机器学习的方法。本文对基于DL的MI - EEG分类方法进行了全面的综述。我们的研究涵盖了基于DL的MI - EEG方法的各个方面。具体地,我们对现有的基于DL的方法、网络结构、常用的正则化方法、公共数据集和常用的度量标准的输入公式进行了系统的分类和总结。我们还讨论了模型比较中的几个问题,提出了公平性能比较的准则,并使用作者发布的源代码评估了13个典型的基于DL的MI - EEG解码模型。
此外,通过开展消融研究,我们探索了一些设计因素对模型性能的影响,揭示了影响分类性能的重要设计因素。为了促进未来的研究,我们还讨论了基于DL的MI - EEG分类中的开放性问题,并提供了潜在的研究方向。
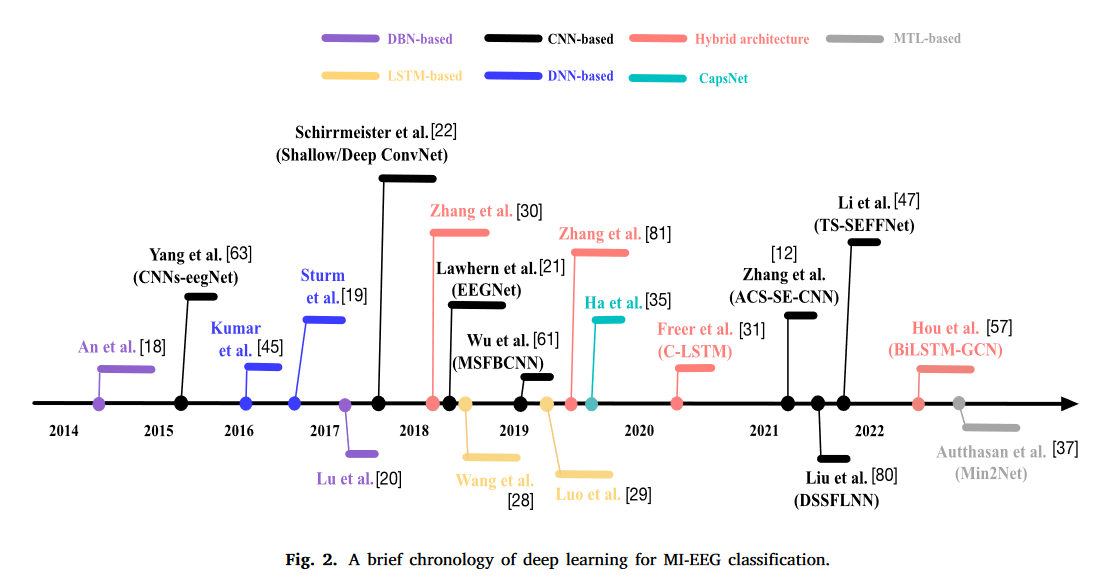
1.1简述了基于深度学习的MI - EEG分类方法的发展历史
在过去的二十年中,已经提出了数百种MI - EEG分类方法。早期的工作主要是利用手工设计的特征[ 13 ]以及传统的机器学习( Machine Learning,ML )分类器,如支持向量机( Support Vector Machine,SVM ) [ 14 ],朴素贝叶斯分类器[ 15 ]和线性判别分析( Linear Discriminant Analysis,LDA ) [ 16 ],对MIEEG进行分类。由于手工特征带来的局限性[ 17 ],传统算法的性能通常不能令人满意。
得益于深度学习( Deep Learning,DL )技术的快速发展,许多研究人员开发了更有效的基于DL的MI - EEG解码方法。与传统方法相比,基于DL的方法可以自动地从低信漏噪比噪声比( SNR )的MI - EEG数据中提取更具判别性和相关性的特征。这通常有助于获得更好的分类结果。早期的基于深度学习的模型,如[ 18-20 ],一般是基于深度信念网络( Deep Belief Networks,DBNs )或深度神经网络( Deep Neural Networks,DNNs )建立的。
这些早期模型的架构相对简单和浅层,但它们往往可以胜过大多数先前的传统非深度学习方法。为了进一步提高基于DL的方法的性能,许多研究在构建其解码模型时模拟了滤波器组公共空间模式( Filter Bank Common Spatial Pattern,FBCSP )的计算步骤。FBCSP是一种先进的( SOTA )非DL方法,已经在多个EEG解码比赛中获胜。与FBCSP相比,这些基于DL的模型可以在一个统一的框架下完成特征提取和分类等多个计算步骤。
在同一时间段内,一些研究人员开发了基于语谱图的CNN模型[ 10、24、25]用于MI - EEG分类。他们首先利用时频方法,即短时傅里叶变换( Short-Time Fourier Transform,STFT ),将原始EEG数据转换为时频表示。然后将这些时频图像输入到新提出的CNN模型中,或预训练的CNN模型,该模型在计算机视觉中取得了成功,用于分类( e.g . , VGG16 )。
一些方法[ 27-29 ]采用长短期记忆网络( Long-Short Term Memory,LSTM )建立模型,因为LSTM能够捕捉信号中的时间依赖性。已报道的结果表明,这些基于LSTM的方法比许多以前的非深度学习算法和一些早期的基于深度学习的方法能取得更好的效果。
为了进一步提高性能,越来越多的工作[ 30-32 ]提出了结合不同深度学习算法的混合架构,其中CNN和LSTM的结合是最常见的设计选择。此外,最近的一些研究[ 33 ]也利用胶囊神经网络( CapsNet ) [ 34、35 ]开发了MI - EEG解码模型。
报告的结果表明,它们的性能优于以前的一些基于CNN的方法。最近,一些研究人员将注意力转向多任务学习( MTL ),并开发了基于MTL的MI - EEG分类模型[ 36-38 ]。这些工作旨在利用其他相关任务,如输入重构[ 37 ],来辅助MI - EEG分类。其中一些[ 36、37 ]模型的性能超过了一些SOTA模型,如EEGNet [ 21 ],Deep ConvNet [ 22 ]等。图2展示了从2014年至今提出的具有代表性的基于DL的方法。
1.2. Existing reviews on MI-EEG classification
以前有一些关于MI - EEG分类的综述性工作。据我们所知,最早的回顾可以追溯到2013年。Hwang等人[ 13 ](EEG-Based Brain-Computer Interfaces: A Thorough Literature Survey: International Journal of Human–Computer Interaction: Vol 29, No 12)回顾了以前的各种基于EEG的BCI论文,这些论文都没有使用DL。另一篇早期综述文章 39 主要关注基于感觉运动节律( SMR )的BCI及其应用。同样,综述中所包含的作品也没有使用深度学习。由于在BCI中使用了更多的DL,最近的几篇综述开始更多地关注基于DL的方法。Lotte等人[ 40 ](http://dx.doi. org/10.1088/1741- 2552/aab2f2)回顾了从2007年到2017年提出的BCIs的EEG分类方法,但只有少数使用了DL。随后的两篇综述文章[ 9、41 ]重点介绍了基于DL的EEG分类方法。它们涉及多个不同的应用领域,如BCI、癫痫、睡眠等。然而,这些文章中收录的关于MI - EEG分类的著作数量非常有限。
最近,Saegh等[ 42 ]讨论了40篇与基于DL的MI - EEG分类相关的文献。尽管这项调查涵盖了该领域的许多方面,包括输入形式,使用的DL技术,常见的频率范围等,但它有以下缺点。
( 1 )只是对深度学习技术在MI - EEG分类中的应用进行了高层次的总结。它缺乏对DL技术的深入分析,例如这些DL技术是如何用于构建分类模型的,哪些设计因素可以影响特定DL架构的性能,等等。
( 2 )作者仅引用原文中报道的结果进行比较。由于不同的工作往往采用不同的数据集对[ 30、43、44 ]进行训练和测试,直接引用和比较不同文献的报道结果会导致不公平的比较和无效的结论。
( 3 )本次调查没有涵盖很多典型的、最新的解码模型,如[11](Motor Imagery EEG Decoding Method Based on a Discriminative Feature Learning Strategy | IEEE Journals & Magazine | IEEE Xplore)、12、19、45 ~ 48]。
与先前的综述不同,我们的工作对基于DL的MI - EEG分类方法进行了系统和深入的综述,涵盖了67篇与DL用于MI - EEG分类相关的论文。用于选择这些论文的标准在第2.1节中说明。我们回顾了许多最典型和最新的基于DL的MI - EEG解码方法。我们不仅系统地分类了输入形式和网络体系结构,而且讨论了不同网络体系结构的典型设计模式和常用输入形式。此外,我们选取了13个具有代表性的模型进行评估和讨论。这些模型涵盖了最常见的网络架构。在我们的评估中,我们没有引用已报道的结果,而是使用作者提供的源代码来测试它们的性能。为了公平比较,我们使用了作者采用的超参数,这些超参数给出了模型的最佳性能。通过对网络架构的消融研究,我们探索了一些常见的设计因素对模型性能的影响,并获得了以下几个重要的见解。
( 1 )有效的特征融合对于开发精确的多流CNN架构至关重要。
( 2 )单独使用LSTM无法对MI - EEG信号进行分类;应与空间特征提取技术相结合。
( 3 ) Dropout在提高模型性能方面没有显著效果。
( 4 )研究者在解码模型中除了输出层外,应尽量避免使用全连接层。这些发现可以为研究人员设计和实施新模型提供启示。最后,阐述了该领域面临的挑战和未来的研究方向。
1.3 我们的贡献
本文的主要贡献如下:
- 我们全面回顾了基于DL的MI - EEG分类模型,包括网络结构、系统分类、输入形式的总结和数据集。
- 我们选择、评估和讨论了13种典型的基于DL的MI - EEG解码模型。它们覆盖了大多数常见的网络体系结构。我们还讨论了绩效比较中存在的问题,并为未来公平绩效比较的研究提供了指导。
- 我们进行了消融研究,以考察设计因素对几种常见网络架构的影响。根据我们的实验结果,我们为研究人员在设计新模型时提供了建议。
- 本文讨论了基于深度学习的MIEEG分类面临的若干挑战和有待解决的问题,并对未来的研究方向进行了展望。
本文的其余部分组织如下。第2节提出了输入公式和网络结构的建议分类。还介绍了MI - EEG分类中常用的正则化技术、数据集和度量指标。第3节描述了可能导致绩效比较不公平的问题,并为未来的公平比较提供了指南。在第3节中,我们评估了13个典型的基于DL的解码模型,涵盖了几种常见的架构选择,并分析了影响模型性能的设计因素。第四部分讨论了研究中存在的问题和未来的研究方向。最后,第5节对本文进行总结。
2.基于深度学习的运动想象MI - EEG分类方法
得益于DL,MI - EEG分类取得了很大的进展。对于基于DL的MI - EEG分类方法,有几个方面值得我们关注,包括输入形式,网络结构,常用的公共数据集和评价指标。在这一部分中,我们对这些重要方面进行了全面的论述。第2.1节介绍了我们选择基于DL的MI - EEG分类相关综述论文的标准。2.2节对典型的输入形式进行了分类和总结。在2.3节中,我们简要讨论了基于DL的MI - EEG分类中的数据归一化问题。2.4节对典型的网络体系结构进行了分类和总结。2.5节介绍并总结了基于DL的MI - EEG分类中常用的正则化技术。在2.6节中,我们回顾和讨论了常用的MI - EEG数据集和流行的度量方法。
2 . 1 .相关文章的选择标准
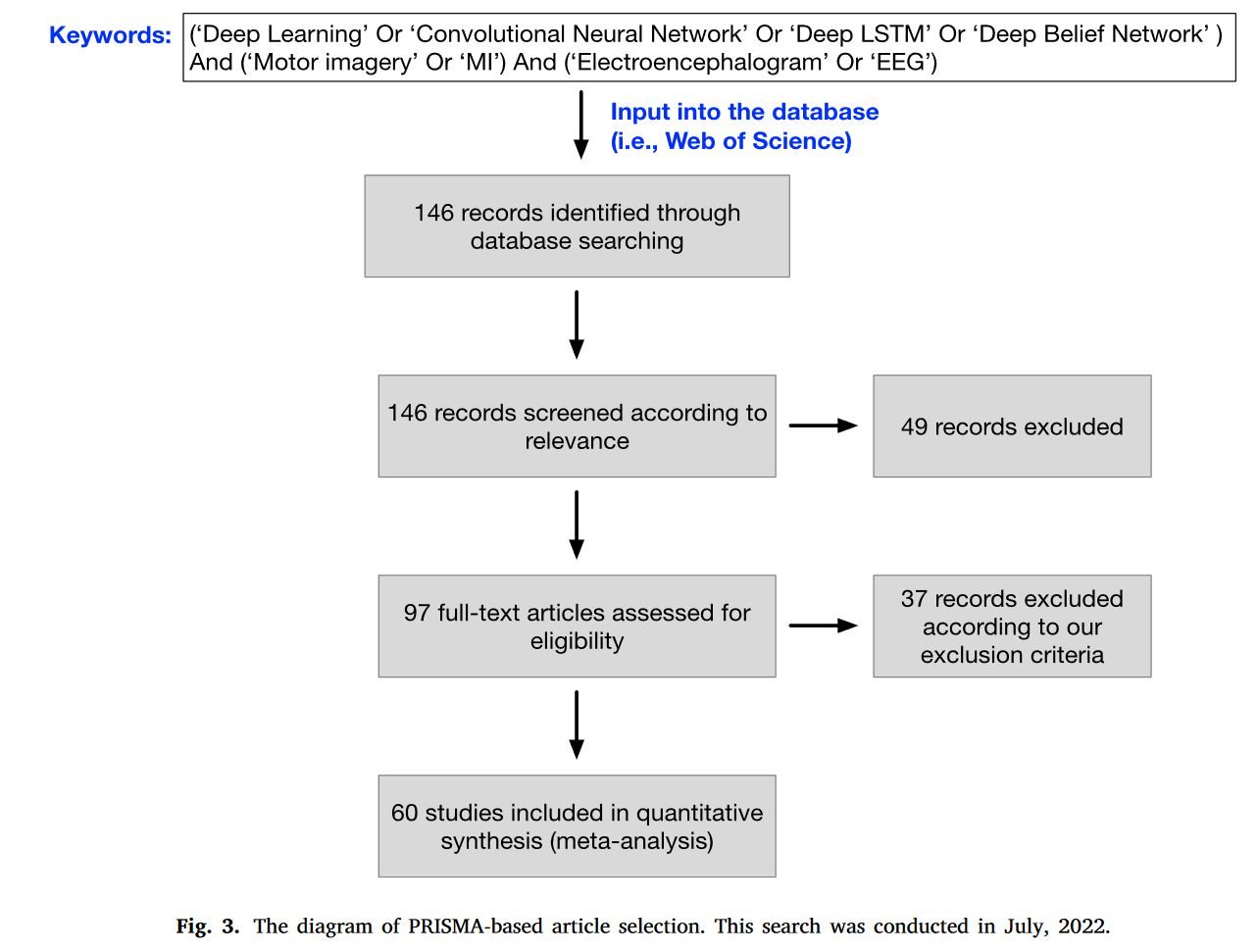
由于大量基于DL的MI - EEG分类方法已经被提出,因此在一篇文章中回顾所有这些工作是不现实的。采用PRISMA [ 49 ]系统评价和Meta分析的方法进行文献筛选。具体来说,我们首先将关键词(见图3)输入到一个著名的多学科数据库,即Web of Science。然后,我们手动丢弃一些与MI无关的搜索结果。具体而言,一些搜索结果只与其他基于EEG的BCI范式相关,如事件相关电位和稳态视觉诱发电位。接下来,我们进一步丢弃未被同行评议的搜索结果,例如arXiv论文,或者如果论文只关注非分类任务,例如特征选择。
详细展示了我们基于PRISMA的文章选择示意图。采用PRISMA方法,选取了60篇相关作品。我们还手动纳入了一些典型的和最新的作品[ 36 ~ 38,50 ~ 53],这些作品并没有被我们基于PRISMA的文章选择所选择。最后,我们选取了67篇相关的著作进行综述。
关键字的选择
扩展一下什么是PRISMA
PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analyses)是一套指南和检查列表,用于报告系统性评价和meta分析的研究结果。PRISMA旨在提高系统性评价的透明性、完整性和准确性,帮助研究者和读者更好地理解、评估和复制研究过程及结果。以下是关于PRISMA的一些关键点:
PRISMA的目标:
- 提高透明度:通过详细描述研究的每一个步骤,使读者能够了解研究是如何进行的。
- 增强可复制性:提供足够的信息,使其他研究者可以重复研究过程。
- 标准化报告:确保系统性评价报告的质量和一致性。
- 减少偏差:通过透明的报告减少研究过程中的潜在偏差。
PRISMA的组成部分:
PRISMA声明:一个27项的检查列表,涵盖了系统性评价和meta分析研究报告的所有重要方面。
PRISMA流程图:一个可视化的工具,用于展示研究的筛选过程,包括识别、筛选、合格和排除的记录数。
PRISMA扩展:针对不同类型的系统性评价(如网络meta分析、个体患者数据的meta分析等)有专门的扩展检查列表。
PRISMA的应用:
- 文献搜索:详细描述文献搜索策略,包括使用的数据库、关键词、时间范围等。
- 研究选择:说明如何选择研究,包括纳入和排除标准。
- 数据提取:描述从选定研究中提取哪些数据,以及如何处理这些数据。
- 风险评估:评估研究方法学质量或偏差风险的过程。
- 数据合成:描述如何进行meta分析(如果适用),包括使用的统计方法。
- 结果报告:提供研究结果的综合和解释。
使用PRISMA的优势:
- 提高研究质量:通过遵循PRISMA,研究者可以确保他们的系统性评价和meta分析达到高标准。
- 增加研究的可信度:透明和详细的报告使研究结果更易于被其他研究者和决策者理解和信任。
- 减少重复研究:清晰的报告可以避免不必要的重复工作。
- 促进研究的系统性:PRISMA帮助研究者系统地组织和报告研究过程。
如何使用PRISMA:
- 准备阶段:熟悉PRISMA指南和检查列表。
- 进行系统性评价:在进行系统性评价时,确保每个步骤都符合PRISMA的要求。
- 报告阶段:在撰写报告时,按照PRISMA检查列表逐项完成,确保所有必要信息都被包含。
- 使用流程图:创建PRISMA流程图来展示文献筛选过程。
- 审阅和修改:在提交之前,审阅报告,确保符合PRISMA的要求。
PRISMA是一个强大的工具,广泛应用于医疗、健康、教育等多个领域的研究中,帮助提升研究的质量和可信度。
2.2 典型的输入公式
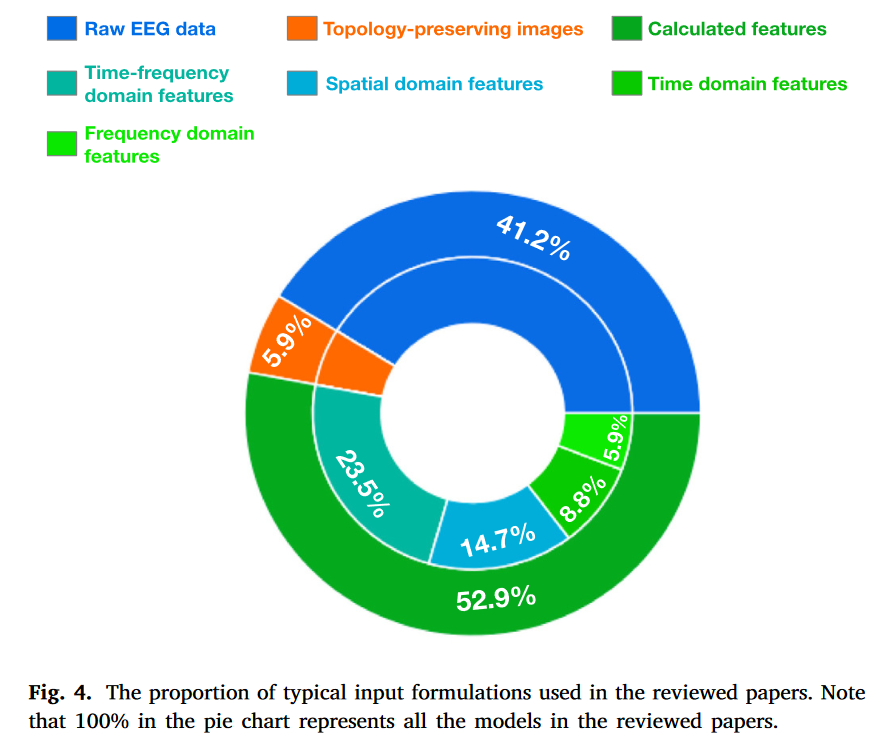
制定或选择合适的输入形式是设计准确分类模型的重要因素之一。迄今为止,基于DL的MI - EEG分类方法已经开发并采用了多种输入形式。根据这些输入公式的特点,可以将其分为3类:原始脑电数据(见第2.2 . 1节)、保留拓扑结构(Topology-preserving)图像(见2.2 . 2节)和计算特征(见第2.2 . 3节)。
显示了这三类在所回顾的模型中作为输入的比例。表1总结了不同类别输入公式的代表性出版物。由于输入公式通常与网络体系结构紧密相连,我们在2.4节中也简要讨论了不同网络体系结构中常用的输入公式。
2.2.1原始EEG数据
由于DL技术擅长从数据中提取有效特征,因此许多工作,如[ 21、22、54 ],直接使用原始EEG数据作为其DL模型的输入。与其他类型的输入公式相比,使用原始EEG数据作为输入的主要优点是不需要额外的计算步骤来处理数据。输入的原始数据一般为2D矩阵形式,其中行往往代表时间,列代表EEG通道(参见图5 ( a )) )。迄今为止,已有的DL方法中有很大比例(约41.2 % )以原始脑电数据作为输入,涵盖了各种类型的网络架构(见表2),如基于卷积神经网络的架构、基于长短期记忆网络的架构、混合深度网络等。
2.2.2拓扑保留图像
虽然2D矩阵形式的原始EEG数据已被广泛用作基于DL的MI方法的输入,但它忽略了EEG通道之间的空间关系[ 30 ]。为了解决这个问题,一些方法[ 30、44、66 ]利用EEG电极的位置信息来构建其网络的输入。为了方便起见,我们把这种类型的输入公式称为保留拓扑结构图像。
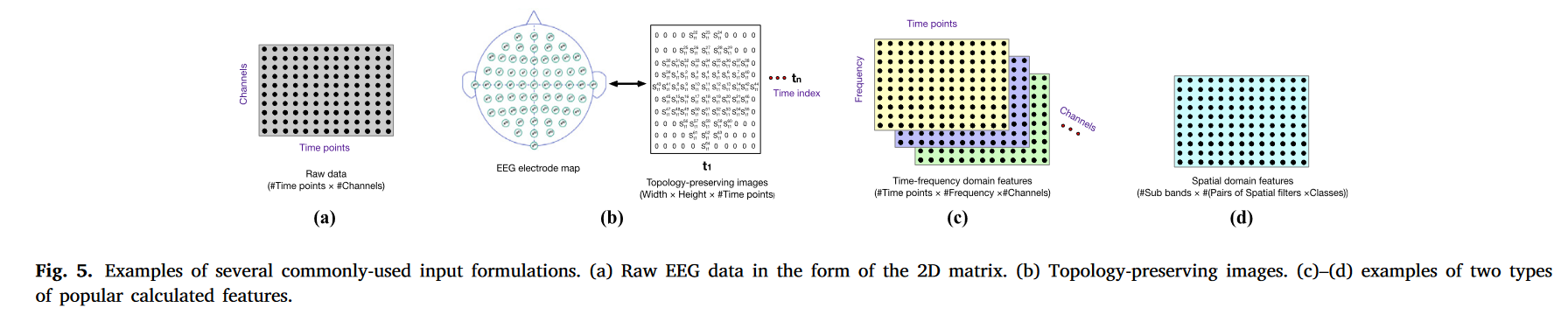
如图5 ( b )所示,保留拓扑结构图像可以看作是由2D数据段组成的序列,每个数据段都是根据EEG电极图构建的。为构建保留拓扑结构图像,采用补零的方式将EEG电极图中传感器数量较少的行进行延拓,使其长度与传感器数量最多的行相同。关于如何获得保留拓扑结构图像的更多细节可以在[ 30 ]中找到。与原始EEG数据相比,保留拓扑结构图像保留了完整的电极分布位置信息。然而,构造保留拓扑结构图像也比较耗时,并且我们需要知道对应的EEG电极帽的电极分布。对于这类输入形式,常被用作基于CNN的方法和混合CNN - LSTM方法(见表2)的输入。
2.2.3计算特征
除了原始的EEG数据和保留拓扑结构图像,许多研究使用从EEG数据中提取的特征作为模型的输入。这些计算得到的特征大致可以分为:空间域特征、时间域特征、频率域特征和时频域特征。时频域特征是最常见的输入形式。小波变换( Wavelet Transform,WT ) [ 67、69、70 ]和短时傅里叶变换( Short-Time Fourier Transform,STFT ) [ 25、73 ]常用于将EEG信号转换为时频特征图。( c )给出了一个时频特征的例子。由于CNNs对图像数据具有良好的分类效果,通常将类图像的时频特征图输入到基于CNN的模型中进行分类。第二种最常见的计算特征是空间域特征(见图5 ( d )) ),可以通过使用公共空间模式( Common Spatial Patterns,CSP ) [ 45、63、77 ]或CSP的变体[ 15、78、93 ]获得。例如,文献[ 63 ]的工作首先从EEG信号中提取增强的CSP特征,然后将提取的CSP特征输入到5层CNN模型中进行MI - EEG分类。此外,一些基于深度学习的方法还将时域特征(例如,数值测度[ 27,28,85 ] )、频域特征(例如,功率谱密度( PSD )) [ 27、88 ]和快速傅里叶变换[ 18、89 ] )作为输入。
2.3归一化
数据归一化的目的是将数据集的值转化为相同的尺度。由于EEG信号在不同会话和不同受试者之间的高度变异性,数据归一化常作为标准预处理步骤[ 27、61 ]应用于MI - EEG解码模型的输入。最常用的归一化函数是Zscore归一化,其具体形式如下。
Z
s
c
o
r
e
=
X
−
μ
σ
Z_{score}=\frac{X-\mu}{\sigma}
Zscore=σX−μ
其中X是模型的输入,μ和σ分别表示在X上计算的均值和标准差。阿皮切拉等人[ 94 ]研究并评估了数据归一化对不同EEG任务的影响,他们的结论是数据归一化可以显著提高各种EEG任务,包括MI - EEG模型的分类性能。
2.4典型网络架构
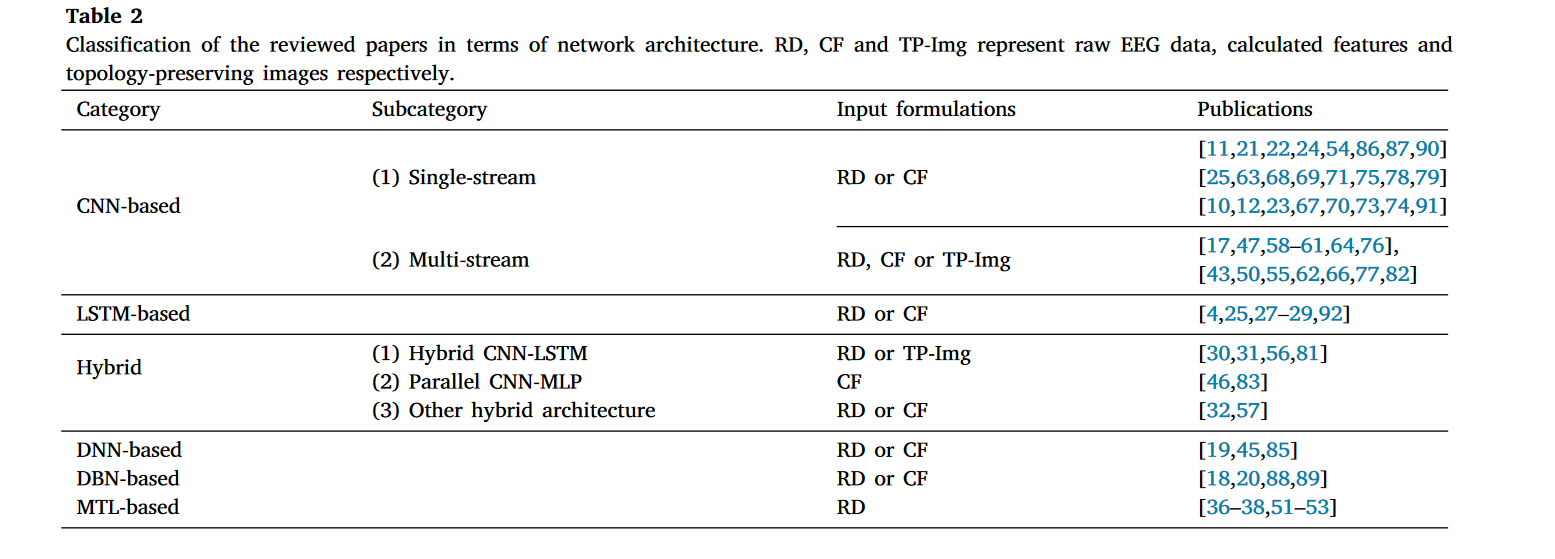
数百种基于深度学习的模型已被提出用于分类 MI-EEG 信号。在网络架构方面,我们将现有的基于深度学习的模型分为六类:基于 CNN 的、基于 LSTM 的、基于混合深度网络的、基于深度神经网络的、基于深度信念网络的和基于多任务学习的。表 2 列出了每种网络架构对应的出版物,并总结了不同网络架构中使用的输入公式。
2.4.1基于卷积神经网络( CNN )的方法
卷积神经网络是深度学习中应用最广泛的算法之一。它已被广泛应用于计算机视觉[95]、自然语言处理[96]和语音识别[97]。根据网络架构,我们将基于 CNN 的解码模型进一步分为两类,即单流 CNN 网络(见图 7(a))和多流 CNN 网络(参见图 7(b))。
单流 CNN 网络通常由卷积层、池化层、激活函数和全连接(FC)层组成。这些组件堆叠形成一个单流网络(参见图 7(a))。如表 2 所示,所审查的单流 CNN 方法使用了计算特征(例如,时频域特征、时域特征等)或原始 EEG 数据作为输入。时频域特征和原始 EEG 数据是最受欢迎的(见图 6(a))。以图像类时频特征为输入的单流 CNN 网络设计通常借鉴了计算机视觉的深度学习模型经验。例如,Xu 等人[73]首先使用他们的基于 STFT 的处理方法将 EEG 数据转换为时频图像。然后,生成的图像类表示被输入到所提出的基于知名深度学习模型(即 VGG-16[26])进行图像分类的 MI-EEG 解码框架中。 当选择原始脑电图信号或时域特征作为输入公式时,研究人员通常使用 FBCSP [15]的计算步骤作为网络设计的指南,这是一个 SOTA 的传统算法。例如,受到 FBCSP 的启发,Schirrmeister 等人 [22] 设计了一个基于单流 CNN 的模型,即 Shallow ConvNet。它首先执行时间卷积和空间卷积来模拟 FBCSP 中的带通和 CSP 滤波器。接下来,采用一系列操作(例如,平方非线性变换、平均池化和对数函数)来模拟 FBCSP 中的其他相应计算步骤。
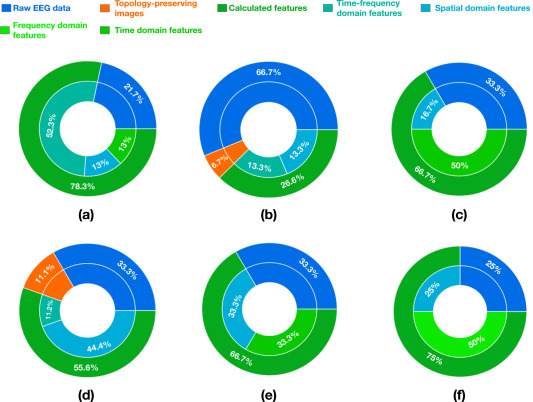
图 6. 每种网络架构使用的输入公式比例。(a)基于单流 CNN 的网络。(b)基于多流 CNN 的网络。(c)基于 LSTM 的网络。(d)基于混合深度网络模型。(e)基于 DNN 的网络。(f)基于 DBN 的网络。请注意,每个饼图中的 100%代表基于相应网络架构的所有审查模型。我们在此省略基于多任务学习架构的内容,因为所有基于此架构的审查研究都使用原始 EEG 数据作为输入。
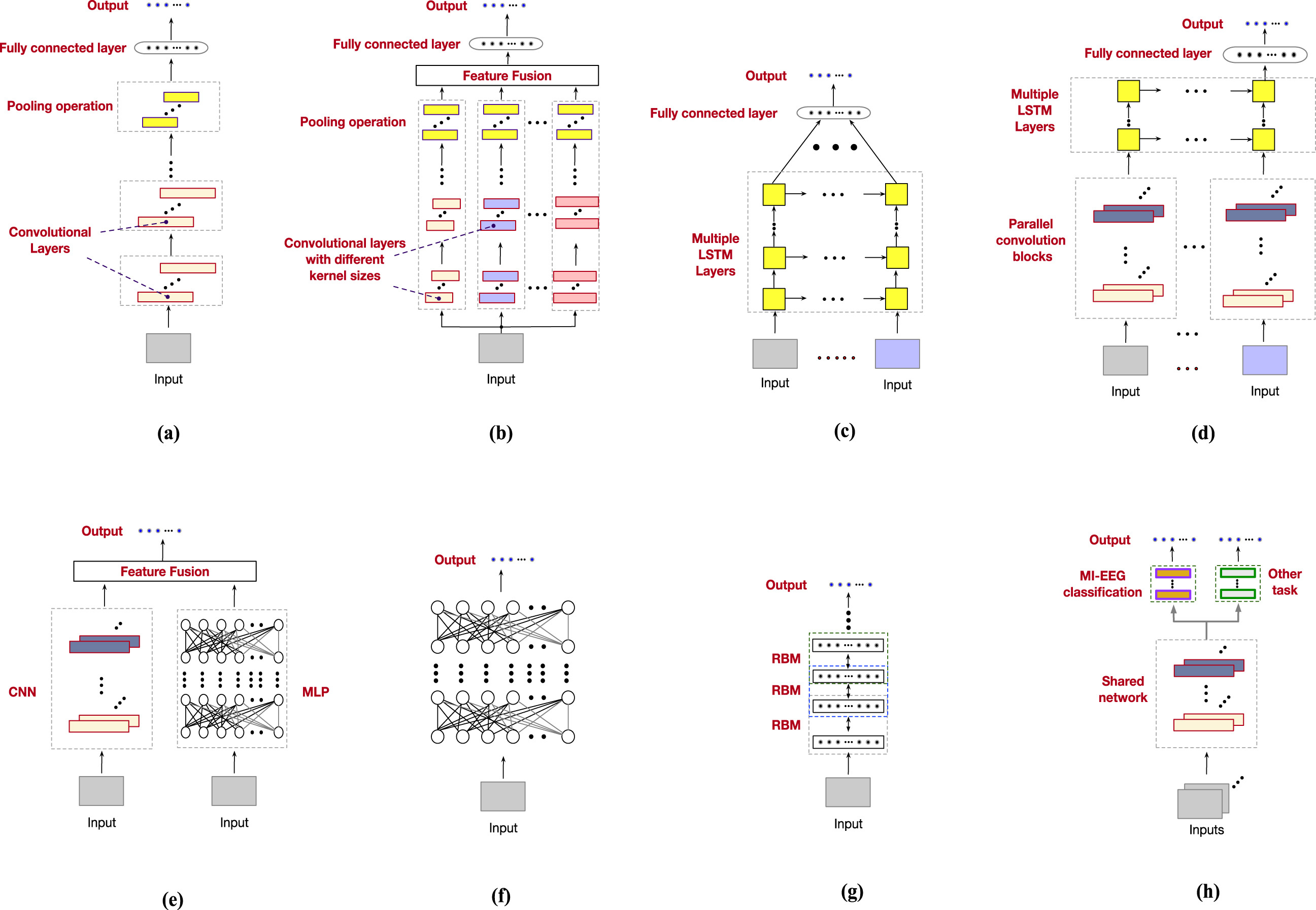
图 7. MI-EEG 分类的代表性网络架构。(a)基于单流 CNN 的网络。(b)基于多流 CNN 的网络。(c)基于 LSTM 的网络。(d)混合 CNN-LSTM 网络。(e)并行 CNN-MLP 网络。(f)基于 DNN 的网络。(g)基于 DBN 的网络。(h)基于 MTL 的网络。
多流 CNN 网络,如图 7(b)所示,通常包含多个具有不同配置(例如,卷积滤波器的大小、滤波器数量等)的特征提取分支。对于所审查的多流 CNN 方法,其中大多数,如[58]、[60]、[61],选择了原始 EEG 数据作为模型输入(见图 6(b))。考虑到卷积滤波器的最佳大小可能因人而异,这些方法通常采用几组不同核大小的 1-D 卷积,以更好地从原始 EEG 信号中提取时间和空间特征[59]、[60]。通过多尺度卷积提取的特征被融合并进一步处理以生成最终预测。例如,Jia 等人[60]提出了一种名为 MMCNN 的多流 CNN 网络,该网络直接以原始 EEG 数据为输入。所提出的模型由五个网络分支组成。这些网络分支采用不同核大小的卷积来提取多尺度特征。为了获得判别性特征,作者还在每个网络分支中添加了一个 Squeeze-and-Excitation 块[98]。 不同分支生成的特征随后融合以进行预测。
2.4.2基于长短期记忆网络( LSTM )的方法
由于能够从序列数据中检测时间依赖性,一些工作[4]、[25]、[27]、[28]、[29]、[92]尝试基于 LSTM 构建他们的解码模型。如图 7©所示,基于 LSTM 的模型通常包括一个输入层、至少一个 LSTM 层、一个全连接层和一个输出层。它们的输入通常是计算出的特征(见图 6©)。例如,张等人[27]从原始 EEG 数据中提取了多种时域和频域特征。这些提取的特征被用来训练他们提出的具有三个隐藏层的 LSTM 模型。
2.4.3基于混合深度网络的方法
为了设计更有效的解码模型,一些研究人员也尝试将不同的深度学习算法相结合。根据不同的组合,基于混合深度网络的架构可以进一步分为混合 CNN-LSTM、并行 CNN-MLP 和其他混合架构。图 6(d)说明了用于所审查的基于混合深度网络模型的输入公式的不同比例。
混合 CNN-LSTM 方法,如图 7(d)所示,是最常见的混合架构,通常包含一个 CNN 子网络,后面跟着一个 LSTM 子网络。这种设计旨在同时从 EEG 数据中学习空间和时间特征。混合 CNN-LSTM 模型的输入公式可以是原始 EEG 数据、计算特征或图像。一个著名的混合 CNN-LSTM 网络是级联模型[81],它主要由一个 2D-CNN、两个堆叠的 LSTM 层和全连接层组成。它以保留 EEG 电极位置信息的 2D 数据网格作为输入。2D-CNN 从网格状表示中提取空间特征,而堆叠的 LSTM 层用于学习时间步之间的依赖关系。
并行 CNN-MLP 方法(参见图 7(e))融合了从基于 CNN 和基于 MLP 的子网络中学习的特征,用于 MI-EEG 分类。不同子网络的输入通常是不同类型的计算特征。一个代表性的基于并行 CNN-MLP 的方法是文献[46]中的工作,其中设计了一个基于 CNN 的子网络来细化动态能量特征,并采用了一个基于 MLP 的子网络来处理静态能量特征。
其他混合架构。除了上述两种组合类型之外,一些研究[32],[57]提出了基于其他混合架构的解码模型。由于这些组合不太常见,我们将它们归类为其他混合架构。例如,Dai 等人[32]提出了一种基于深度学习的 MI-EEG 框架,该框架结合了卷积神经网络(CNN)和变分自动编码器(VAE)[99]。最近,Hou 等人[57]设计了一种名为基于注意力的 BiLSTM-GCN 的 MI-EEG 分类新解码模型。这是第一个结合双向长短期记忆(BiLSTM)[100]和图卷积神经网络(GCN)[101]的模型。
2.4.4. 基于深度神经网络(DNN)的方法
一些早期作品[19]、[45]、[85]基于 DNN 开发了他们的 MI-EEG 分类模型(见图 7(f))。如图 6(e)所示,原始 EEG 数据或计算特征是最常见的输入形式。例如,CSP-DNN[45]是一种典型的基于 DNN 的方法,包含两个隐藏层。该模型以从原始 EEG 数据中提取的 CSP 特征作为输入。报告的结果表明,它可以优于一些知名的非 DL 方法。与 CNN 相比,具有相同层数的 DNN 通常具有更多的可训练参数,这可能导致昂贵的计算复杂度,并使模型容易过拟合。因此,最近很少开发基于 DNN 的架构用于 MI-EEG 分类。
2.4.5. 基于深度信念网络(DBN)的方法
与基于 DNN 的模型类似,现有的基于 DBN 的模型通常由早期工作开发,如[18]、[20]、[88]。对于所审查的基于 DBN 的方法,它们要么直接使用原始 EEG 数据[88],要么计算特征,例如频域特征 FFT[18]、[20],作为输入(见图 6(f))。如图 7(g)所示,基于 DBN 的模型通常通过堆叠限制性玻尔兹曼机(RBM)构建。堆叠的 RBM 提取的特征最终由分类器进行分类。例如,FDBN[20]作为代表性基于 DBN 的模型之一,是一个四层网络,包含三个 RBM 和一个 softmax 层。该模型采用提取的频域特征作为输入。[20]中报告的结果表明,该模型在几种经典传统方法中表现出优异的性能。
2.4.6. 基于多任务学习(MTL)的方法
所有上述网络架构仅在它们的网络中学习单个任务,即 MI-EEG 分类。与这些模型不同,一些最近的工作[37],[38],[51]在 MI-EEG 分类中探索了多任务学习(MTL)。受人类大脑学习系统的启发,这些工作利用其他相关任务来辅助 MI-EEG 分类。基于 MTL 的架构中辅助 MI-EEG 分类的常见任务主要包括输入重建[37],[51],分类非目标 EEG 数据集[38],[53]以及区分源域和目标域[36],[52]。通过利用这些相关任务,基于 MTL 的模型在 MI-EEG 分类的目标任务上的性能可以得到提高。然而,为这些其他任务创建的附加网络分支可能会增加训练过程的复杂性[53]。如图 7(h)所示,基于 MTL 的架构的常见设计模式是首先使用共享网络从输入中提取特征表示,然后使用不同的网络分支执行不同任务。在训练过程中,同时学习多个任务。 例如,DMTL-BCI [51] 作为一种典型的基于 MTL 的 MI-EEG 分类模型,首先利用表示模块从原始输入中学习特征。然后,学习到的特征被传输到分类模块进行 MI-EEG 分类和重建模块进行输入重建。两个任务同时联合优化。原始论文中报告的结果显示,在某些代表性 MI-EEG 模型(如 EEGNet [21] 和浅层卷积神经网络 [22])上表现出优异的性能。
2.5. 正则化
正则化是一种旨在避免深度学习中过拟合的技术。在基于深度学习的 MI-EEG 分类中,已经广泛使用了多种正则化方法,主要包括 dropout、批量归一化、L1/L2 正则化、网络参数初始化、样本预处理、数据增强和迁移学习。
Dropout [102] 是一种常用的正则化技术,在训练过程中随机丢弃一定比例的神经元。几个代表性的 MI-EEG 模型,如 [21]、[22]、[47],在训练过程中使用了 dropout。在第 3.3 节中,我们通过消融研究探讨了使用 dropout 对模型性能的影响。
批标准化已被验证有助于网络更快地收敛,通过对其中间层的输入进行归一化[103]。它已在许多 MI-EEG 分类模型[21],[47],[78]中得到应用。
L1 和 L2 正则化也被一些方法[76],[80]用于 MI-EEG 分类。通过添加正则化项,可以在训练过程中减少过拟合问题。关于这种正则化的更多细节可以在[102]中找到。
现有工作通常没有指定它们的网络参数是如何初始化的。通过调查具有可用源代码的模型(见表 5),我们发现 Glorot 初始化[104]是初始化网络参数最常用的方法。一篇最近的调查论文[105]系统地讨论和总结了深度神经网络权重初始化策略,这可能有助于未来的研究选择合适的网络参数初始化方法。
适当的样本预处理策略也可以帮助在训练过程中减少过拟合。归一化和数据过滤是 MI-EEG 分类中最常见的两种样本预处理策略。前者在 2.3 节中简要讨论。至于后者,其目的是消除噪声和不必要的信息。最近的一篇综述论文[106]很好地总结了 MI-EEG 分类中的数据过滤,这可以为这一主题提供更多见解。
数据增强和迁移学习也是 MI-EEG 分类中使用的两种正则化技术。我们分别在 4.2 不平衡 MI-EEG 数据、4.3 数据分布差异两节中详细讨论了它们。
2.6. MI-EEG 数据集和评估指标
2.6.1. MI-EEG 数据集
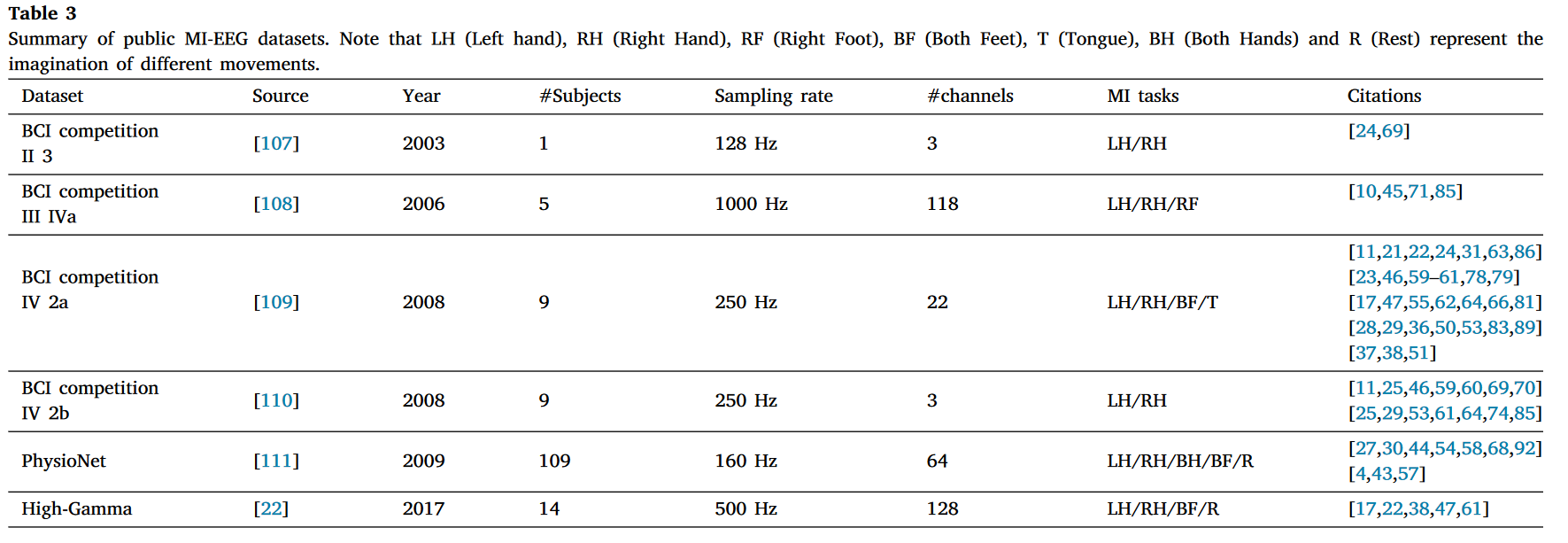
许多 MI-EEG 数据集已被收集和使用。在此,我们仅关注表 3 中总结的六个最常用的公共 MI-EEG 数据集。
在这些公开的 MI-EEG 数据集中,BCI 竞赛 IV 2a 是最受欢迎的,被 31 项已审查的研究使用(见图 8),其次是 BCI 竞赛 IV 2b(14 项已审查的研究)和 Physionet 数据集(11 项已审查的研究)。使用这三个数据集的工作占已审查研究总数的大部分。最新的公开数据集 High-Gamma 仅被 5 项已审查的研究使用。考虑到其发表时间,它可能在未来的研究中被更频繁地使用。
在性能评估方面,研究人员在他们选择的数据集上执行内部或跨受试者分类。主体内分类使用来自同一主体的数据进行模型的训练和测试,而跨主体分类是指训练数据和测试数据来自不同的主体。如图9所示,综述的研究一般在一些较早的数据集( BCI竞赛Ⅱ3、BCI竞赛ⅢⅣa等。)上进行个体内分类,在较新的数据集上进行跨个体分类,如PhysioNet数据集和High - Gamma数据集。这是因为较早的数据集通常包含少量的受试者,每个受试者收集的试验数量较多。然而,最近的数据集通常包含更多的主题,使得研究人员可以在它们上进行跨主题分析。
MI - EEG数据集通常包含不同数量和类型的MI任务(见表3)。对于BCI competitionⅡ3和BCI competitionⅣ2b,只包含想象左手运动和想象右手运动两个MI任务。选择这两个数据集的综述性工作只能执行二分类(左手vs .右手)。
然而,对于具有更多MI任务的其他几个公开的MI - EEG数据集,情况稍微复杂一些。对于这些数据集,现有的工作可能在它们的(见图10)上执行不同的分类任务。如图10 ( a )所示,所有使用BCI竞赛III IVa的综述论文都选择执行二分类。但其中一半进行了右手vs .左手的分类,另一半进行了右手vs .左脚的分类。对于BCI competition IV 2a,大部分研究( 83.9 % )在数据集(参见图10 ( b ))上执行四分类任务,其余研究选择左手vs .右手分类。关于PhysioNet,最常见的选择( 33.3 % )是执行左手vs .右手分类( (见图10 ( c )) )。值得注意的是,图10省略了High - Gamma数据集,因为使用该数据集的所有综述研究仅对其进行了四分类。
2.6.2指标
通过调查现有方法,我们发现模型评估有八个指标。它们是准确率、精确率、召回率、F1 分数、曲线下面积(AUC)分数、Cohen 的 Kappa 系数、特异性和灵敏度[50],[112],其中准确率、F1 分数、AUC 分数和 Cohen 的 Kappa 系数是最常用的。
文章[ 112、113 ]对如何使用这些度量来评估二分类和多分类进行了详细的总结。
表 3. 公共 MI-EEG 数据集概要。注意,LH(左手)、RH(右手)、RF(右脚)、BF(双脚)、T(舌头)、BH(双手)和 R(休息)代表不同动作的想象。
3 .评价与分析
在这一节中,我们首先指出现有研究中性能比较的几个常见问题,并提供了公平性能比较的指南(见第 3.1 节)。然后,在第 3.2 节中,我们评估和分析 13 个基于深度学习的 MI-EEG 分类模型,这些模型涵盖了几个最常见的网络架构。最后,在第 3.3 节中,我们通过使用消融研究进一步探索了一些设计因素对模型性能的影响。
3.1 性能评估中存在的问题
性能比较是验证所提模型有效性的常见方式。然而,我们发现一些问题限制了 MI-EEG 研究人员直接比较论文中报告的结果,因为这些评估标准和方法的固有差异。以下是我们讨论的这些常见问题。
跨学科分类在不同的工作中具有不同的意义。被试内(又称主体内( intra-subject ))验证和被试间(又称主体间性)验证是两种广泛使用的验证方案。受试者内验证[ 47、50 ]使用受试者的部分数据进行训练,使用同一受试者的其余数据进行测试。这个过程对于数据集中的每个受试者都是重复的。然而,我们发现存在三种不同的交叉被试内验证方案:leave-n-subjects-out(留出一定量的被试不做分析)、mix-up-all-subjects(混合所有的被试)和random-selection(随机选择)。
( 1 )leave-n-subjects-out。在医学领域,这种验证方案也常被称为基于被试的数据分割[ 114 ]。许多现有方法,如[21],[44],[54],采用这种交叉学科验证,其中选择特定数量的学科数据作为训练集,剩余学科的数据用作测试集。这种验证方案通常应用于 BCI 系统用于预测未见学科 MI-EEG 数据的场景。事实上,一个理想的基于 MI-EEG 的 BCI 系统应该能够准确分类未见学科信号[48]。
在机器学习是常用方法,训练集和测试集的区别,测试集是未出现过的被试数据
(2)mix-up-all-subjects.在现实世界中,在一段时间后对同一主题进行后续处理是非常现实的。在混合所有主题的方案中,数据集中每个主题的训练数据被汇总在一起用于训练模型。每个主题的剩余数据被汇总在一起用于测试训练好的模型[64],[91]。通过调查已审查的论文,我们发现这种验证方案并不常用。与留出 n 个主题的方案相比,这个方案通常被认为是一个更容易的分类任务[91]。
使用所有被试,对某个被试的一些数据进行测试,测试集是某个被试未使用的试次
(3)random-selection。在医学领域,这也常被称为按记录的数据分割[114]。具体来说,一些工作[30],[43],[58]随机从整个数据集中选择特定比例的数据用于训练,剩余数据用于测试。
训练集和测试集可能有交叉和重复
当使用这种跨被试方案时,准备好的训练集和测试集有三种可能的情况。
第一种,类似于留出 n 个主题的方案,生成的训练集和测试集包含来自不同主题的数据。 第二个问题是训练集和测试集都包含所有受试者数据的一部分,这与混合所有受试者的方案类似。第三种情况是测试集包含训练集中一些受试者数据的一部分,同时也包含一些未包含在训练集中的受试者。如果研究人员没有具体说明他们使用了哪种跨受试者方案,跨受试者分类的意义不一致可能会导致性能评估中的混淆。在这里,我们建议使用留出 n 个受试者方案,因为理想的 BCI 系统应该具有准确分类新受试者 MI-EEG 信号的能力[64],而留出 n 个受试者跨受试者方案可以很好地验证模型在这方面的能力。
评估策略和标准不同
不同的性能比较中使用的评估策略。公平的模型比较应确保所有比较的模型执行相同的分类任务。然而,一些研究(如[30]、[43]、[92])在模型比较中存在不一致性。这些不一致性可能导致无效和不公平的模型比较。例如,在这些工作中,他们提出的模型和一些比较的模型在不同的分类任务上进行了评估,即不同的类别数量(二分类与多分类)和不同的分析类型(被试内与被试间)。考虑到现有工作采用不同的评估策略进行模型比较,直接使用和分析不同工作报告的分类结果,如最近 MI-EEG 调查[42]中所做的那样,可能会误导,并且不会提供准确和有意义的见解。例如,综述论文[42]建议使用时间序列输入公式,因为使用时间序列输入公式进行评估的模型的平均分类准确率高于使用图像或计算特征作为输入的评估工作。 不幸的是,作者们只使用了不同论文中报告的结果,这些结果通常是通过使用不同的评估策略(例如,不同的训练数据和测试数据准备方式)获得的。不同的评估策略可能会显著影响模型性能[31]。因此,这些结果不能直接比较或平均——导致得出错误的结论。
代码细节不透明,无法完全复现
选定了没有可用的源代码的基线模型。一些基于深度学习的脑电图(EEG)分类模型没有公开源代码,有时模型的重要实现细节也没有在原始论文中说明。为了能够与这些模型进行性能比较,研究人员必须根据自己理解重新实现它们。在这种情况下,重新实现版本的分类性能可能与原始版本显著不同——导致无效和不公平的性能比较。
测试的数据集不同
性能比较仅在私有数据集上进行。现有的基于深度学习的文献通常使用公共的 MI-EEG 数据集(参见第 2.6 节)来评估他们的方法。然而,也有一些工作[12],[90]仅在私有数据集上评估了他们的模型。由于这些数据集不可用,私有数据的质量未知。因此,如果研究人员仅在他们的私有数据集上比较他们提出的方法与基线模型,评估结果可能会存在偏差。此外,在这些私有数据集上评估的模型性能无法被其他研究人员验证,这降低了结果的可信度。
这几条,给出了在实际的论文的模型的基线对比时,我们应该选择什么样的比较方式。
- 使用源代码或解码模型的验证实现进行比较
- 在相同条件下比较模型
- 避免在私有数据上评估模型
- 具体说明使用了哪种跨学科验证类型。
- 发布源代码并提供详细说明
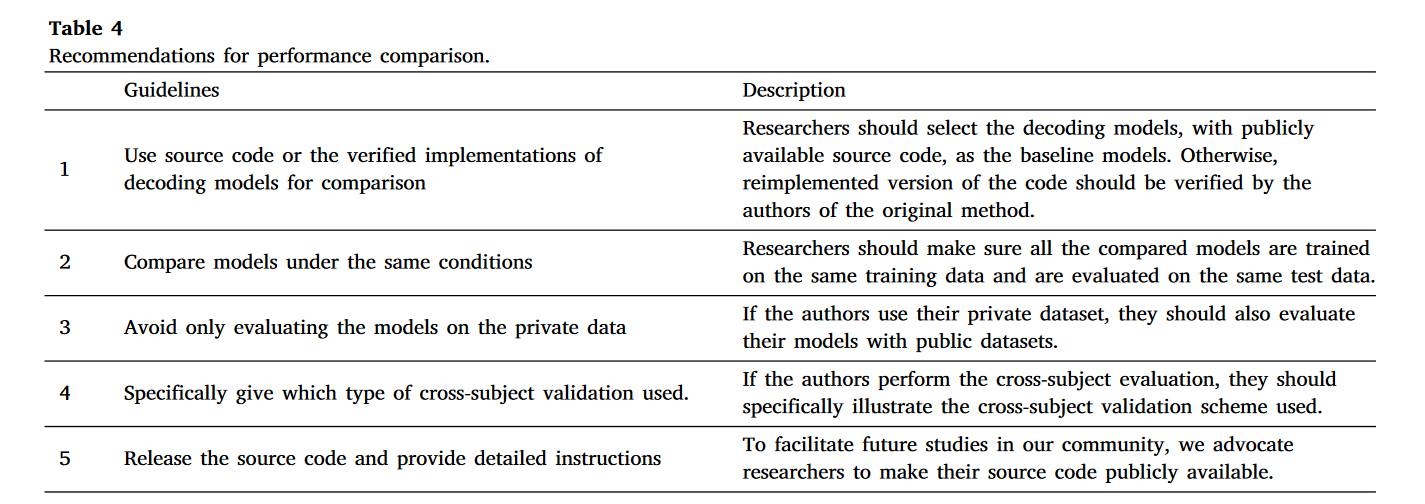
鉴于上述问题可能导致性能比较无效且/或不公平,有必要在基于深度学习的脑磁图(MI-EEG)分类领域标准化结果比较。因此,我们提出了几项指南(见表 4),供其他研究人员使用,以精确和公平地评估基于深度学习的脑磁图解码模型的性能。
表 5. 具有公开源代码的代表性 MI-EEG 解码模型。请注意,为了方便起见,我们将[54]称为 ETENet。

3.2基于深度学习的代表性脑电图解码模型的性能评估
在我们的方法中,我们通过三个标准仔细选择解码模型。第一个标准是所选模型的架构应该是以下最常见的架构之一:基于单流 CNN 的架构、基于多流 CNN 的架构、基于 LSTM 的架构和基于 CNN-LSTM 的混合架构。第二个标准是所选模型通常被高度引用并在知名会议或期刊上发表。第三,根据表 4 中的推荐指南,所选模型应公开其源代码。
根据我们的标准,我们从我们审查的 67 篇论文中选择了 12 种基于深度学习的多通道脑电图(MI-EEG)解码方法(见表 5)。此外,我们还从作者那里获得了 MBEEGNet [50]的源代码,因为我们需要用它来全面研究特征融合对基于多流卷积神经网络模型性能的影响(参见第 3.3 节)。因此,我们最终评估了我们审查的 67 篇论文中的 13 个模型。为了公平的性能评估和比较,所有模型都在同一 GPU 上训练和测试,即 Nvidia Quadro P6000。选定的基准数据集是表 3 中显示的两个最常用的公共 MI-EEG 数据集,即 BCI 竞赛 IV 2a 和 PhysioNet;我们采用四个指标(即准确率、 F1 -得分、AUC 得分和 Cohen 的 Kappa 系数)来衡量所选模型。
3.2.1实验设置
所选分类模型在两个公开数据集上的性能评估设置如下详细说明。
MI-EEG 解码模型在 PhysioNet 数据集上进行的评估。
如第 2.6 节所述,我们可以对这一数据集执行各种分类任务(见图 9,图 10)。然而,最常用的评估设置是对左右手分类进行跨受试者分析[27],[44]。因此,我们在评估中也使用了它。此外,像之前的工作[30],[43],[44]一样,我们移除了低质量记录,即受试者#88,#89,#92,#100 和#104 的 MI-EEG 数据。
在我们的评估中,我们使用了 104 名受试者的 MI-EEG 数据(左手和右手的 MI 运动)。为了进行跨受试者分析,随机选择了 70%的受试者进行训练,10%进行验证,20%进行测试。为了减少选择偏差的机会,我们准备了五个不同的评估集,每个评估集包含一个训练集、一个验证集和一个测试集。在训练过程中,使用早期停止来监控验证损失,并将超参数“耐心”设置为 30。
MI-EEG 解码模型在 BCI 竞赛 IV 2a 数据集上进行的评估。
BCI 竞赛 IV 2a 数据集包含 9 名受试者的脑电图(EEG)数据。如第 2.6 节所述,现有工作通常在此数据集上对受试者进行四类分类(见图 9,图 10)。因此,我们也评估了在此数据集上对受试者进行四类分类的代表方法。考虑到每个受试者的脑电图数据量,我们采用了与[21]类似的验证方案,在 BCI 竞赛 IV 2a 数据集上对受试者进行四折交叉验证。具体来说,选择四个折中的两个用于训练,一个用于验证,最后一个用于测试。为了防止模型过拟合,我们在训练过程中使用早停法,当验证损失在 30 个 epoch 内不下降时,训练将终止。
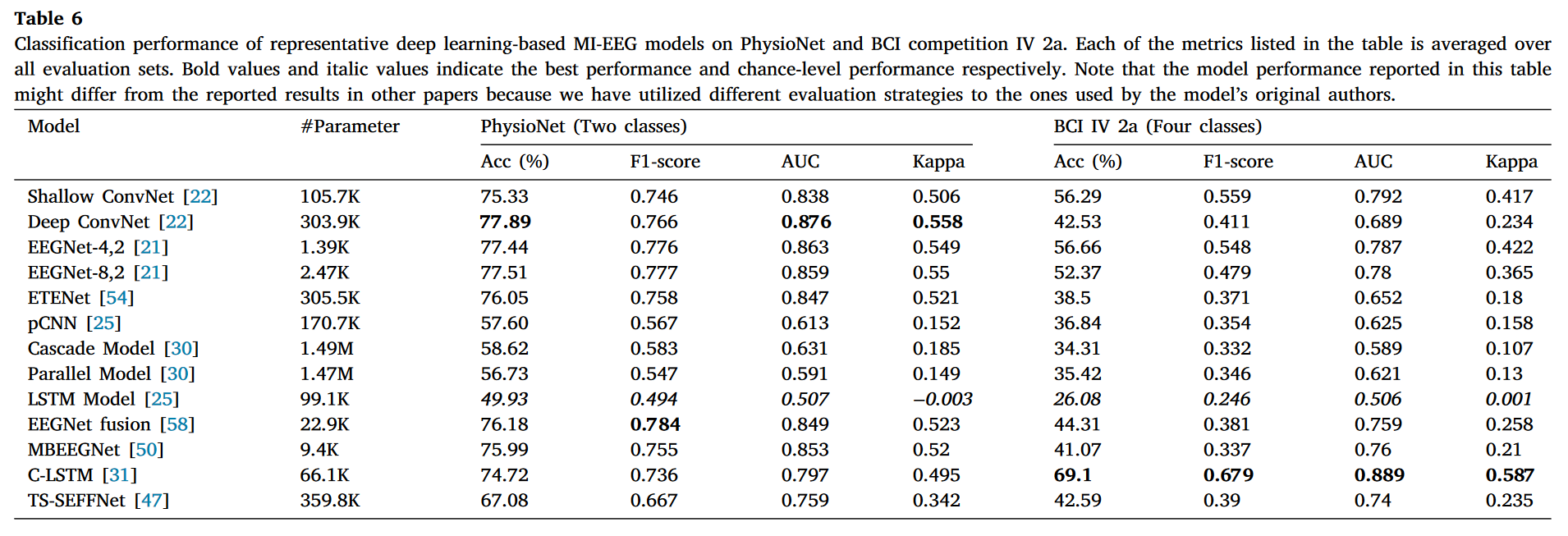
表 6. 在 PhysioNet 和 BCI 比赛 IV 2a 上代表性基于深度学习的 MI-EEG 模型的分类性能。表中列出的每个指标都是对所有评估集的平均值。粗体值和斜体值分别表示最佳性能和机会水平性能。请注意,表中报告的模型性能可能与其他论文中报告的结果不同,因为我们采用了与模型原始作者不同的评估策略。
3.2.2分类结果
lstm通过层数的叠加是否可以获得较好的结果
表 6 显示了 13 个代表性 MI-EEG 解码模型在两个广泛使用的公共数据集上的分类性能。首先,可以看出一个基于简单 LSTM 的模型[25]在两个基准数据集上只能达到约随机水平准确率。这种较差的分类性能的一个可能原因是网络深度不足,因为该模型只有一个 LSTM 层。为了调查增加更多 LSTM 层是否可以提高模型性能,我们进一步评估了在此模型中添加更多层后的分类性能。更多细节和讨论将在第 3.3 节中的消融研究中呈现。
数据量不足,会导致参数量大的模型很难达到较大的准确度。
其次,我们的评估结果显示,Shallow ConvNet、EEGNet-4,2 和 EEGNet-8,2 在两个数据集上均实现了极具竞争力的分类性能。其中,EEGNet 的两种不同配置不仅表现良好,而且高度紧凑(见表 6)。这表明开发准确且轻量级的解码模型具有潜力。尽管 Deep ConvNet 和 ETENet 在 PhysioNet 数据集上可以与上述三种基于单流 CNN 的模型达到相同的性能水平,但它们在 BCI IV 竞赛 2a 中的表现显著较差(见表 7),如表 6 所示。仔细研究这两个模型,我们发现它们与 Shallow ConvNet 密切相关。Deep ConvNet 可以被视为 Shallow ConvNet 的“更深”版本,包含更多的卷积层。考虑到训练数据的大小以及 Shallow ConvNet 如何比 Deep ConvNet 表现更好,我们认为 Deep ConvNet 在 BCI 竞赛 IV2a 中表现不佳的主要原因是因为数据不足,这阻碍了更深 CNN 发挥其全部潜力[22]。 关于 ETENet,其网络架构在输出层之前添加了一个全连接层(FC),并且在池化层之后没有 Dropout,本质上是一个浅层卷积神经网络(Shallow ConvNet)。这些差异似乎是浅层卷积神经网络和 ETENet 性能差异的原因。我们将在第 3.3 节中的消融研究中进一步调查这些差异对性能的影响。
请注意,上述所有基于单流 CNN 的模型都使用原始脑电图数据作为输入。为了研究使用时间-频率域特征作为输入的模型性能,我们还评估了一个代表性的单流 CNN 模型(即 pCNN[25]),其输入是时间-频率谱图图像。我们的评估结果(见表 6)显示,与 EEGNet-4,2 和浅层卷积神经网络等其他单流 CNN 模型相比,pCNN 在 PhysioNet 和 BCI 竞赛 IV 2a 数据集上的性能显著较差。 p − v a l u e s < 0.05 p-values<0.05 p−values<0.05
其性能较差的可能解释是,pCNN 的作者仅使用对应电极 C3、C4 和 Cz 的三个脑电图通道来生成谱图图像。因此,其他通道中存在的一些有用信息无法被模型利用,以更好地分类不同的运动诱发电位脑电图信号。不幸的是,我们无法研究其他模型(如[12]、[74]、[82])的性能,因为这些模型也使用了时间-频率域特征作为输入,但它们的源代码不可用。这可以在未来研究中进行探索,当更多相关作品公开发布它们的代码时。
表 7. 基于单流 CNN 的几个代表性模型的 Wilcoxon 符号秩检验
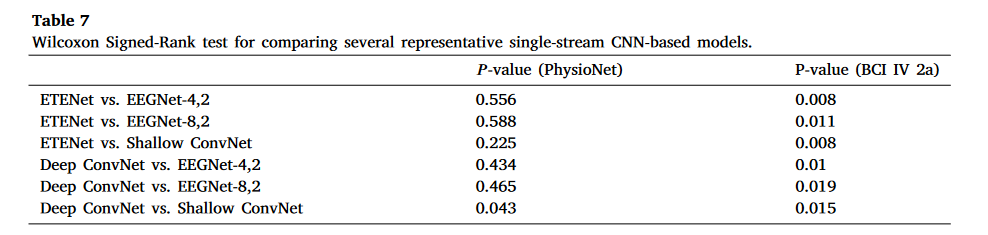
除了几个基于单流 CNN 的模型外,我们还评估了三个代表性的多流 CNN 模型,即 EEGNet 融合、MBEEGNet 和 TS-SEFFNet。尽管这三个模型具有更复杂的网络架构,但它们的分类性能(参见表 6)并不优于一些简单的单流 CNN 模型,即 EEGNet-4,2 和 EEGNet-8,2。通过研究它们的网络架构,我们发现 EEGNet 融合和 MBEEGNet 与 EEGNet 密切相关。事实上,EEGNet 融合和 MBEEGNet 都有三个特征提取分支,这些分支是 EEGNet 的不同配置,没有输出层。来自三个不同特征提取分支的特征被简单地连接起来用于最终预测。考虑到 EEGNet、EEGNet 融合和 MBEEGNet 之间的架构关系以及它们的分类性能,我们可以合理地怀疑有效的特征融合可能是影响多流 CNN 模型性能的关键因素。在我们的第 3.3 节消融研究中,我们将探讨特征融合对多流 CNN 解码模型的影响。
Wilconxon 符号秩检验
符号秩检验(Sign Rank Test),特别是威尔科克森符号秩检验(Wilcoxon Signed-Rank Test),是用于比较两组相关样本的非参数统计方法。它用于检验两个相关样本(比如在实验前后测量同一组对象)的中位数是否有显著差异。以下是关于符号秩检验的一些关键点:
符号秩检验的基本原理:
配对数据:这种检验适用于配对数据(例如,同一组人的前后测量数据)。
计算差异:计算每个配对样本的差异(D),并记录符号(正或负)。
排名:忽略符号,只根据绝对值对差异进行排名。
符号秩和:根据差异的符号,将排名分为正秩和负秩,计算正秩和(W+)和负秩和(W-)。
检验统计量:通常使用较小的一个秩和作为检验统计量(T),比较T与临界值或使用统计软件计算p值来判断显著性。
步骤:
- 假设:
- 零假设(H0):两个配对样本的中位数无显著差异。
- 备择假设(H1):两个配对样本的中位数有显著差异。
- 计算差异:
- 对于每个配对,计算差异值 D i = X i − Y i D_i = X_i - Y_i Di=Xi−Yi,其中 X i X_i Xi 和 Y i Y_i Yi 是配对中的两个观测值。
- 排名差异:
- 忽略符号,根据绝对值对差异进行排名。如果有相同的值(即绝对值相同),则使用平均秩。
- 计算符号秩和:
- 计算正秩和 W + W+ W+和负秩和 W − W- W−。
- 选择检验统计量:
- 通常选择较小的秩和作为检验统计量T。
- 确定临界值或计算p值:
- 使用统计表查找临界值,或使用软件计算p值。
符号秩检验的优点:
- 非参数性:不依赖于正态性假设,对数据分布的要求较宽松。
- 适用于小样本:即使样本量较小,也可以使用。
- 处理配对数据:专门用于分析配对数据,控制了个体差异。
符号秩检验的局限性:
- 仅适用于配对数据:不能用于独立样本。
- 无法处理零差异:如果有多个差异为零,需要特殊处理(通常排除这些配对)。
- 假设中位数差异:检验的是中位数的差异,而不是均值。
使用场景:
- 前后测量比较:比如药物治疗前后的效果比较。
- 匹配研究:如匹配的病例对照研究。
- 重复测量:当有多个时间点的数据进行比较时。
在Matlab中,你可以使用
signrank函数来进行符号秩检验,例如:% 假设x和y是配对样本 p = signrank(x, y)这个函数会返回p值,你可以根据p值来判断是否拒绝零假设。记住,符号秩检验是一个非常有用的工具,特别是在数据不满足正态分布假设时。
在分类模型评估中怎么使用
在分类模型中,传统的符号秩检验(Wilcoxon Signed-Rank Test)通常用于比较两个模型的预测性能或拟合效果,但直接比较预测值或残差的做法需要一些调整。以下是如何在分类模型中应用符号秩检验的几种方法:
方法一:使用预测概率
获取预测概率:许多分类模型(如逻辑回归、支持向量机、随机森林等)可以输出每个类别的预测概率,而不是硬分类结果。比较两个模型的预测概率可以作为比较它们的基础。
计算差异:对于每个样本,计算两个模型对正确类别的预测概率的差异(即模型1预测的正确类别概率减去模型2预测的正确类别概率)。
应用符号秩检验:使用这些差异进行符号秩检验,检验两个模型的预测概率是否有显著差异。
方法二:使用损失函数
选择损失函数:选择一个适用于分类问题的损失函数,如交叉熵损失(log loss)或0-1损失。
计算损失:对于每个样本,计算两个模型的损失(即模型预测与实际标签之间的差异)。
应用符号秩检验:使用这些损失的差异进行符号秩检验,检验两个模型的损失是否有显著差异。
方法三:使用准确率或其他指标
计算性能指标:对于每个样本,计算两个模型的分类是否正确(即是否预测对了)。可以使用准确率、精确度、召回率等指标。
转换为符号:将正确分类标记为正符号,错误分类标记为负符号。
应用符号秩检验:对这些符号进行符号秩检验,检验两个模型的分类准确性是否有显著差异。
注意事项:
- 数据配对:确保两个模型在同一个数据集上进行比较,即每个样本都有一对预测结果。
- 非参数性:符号秩检验是非参数的,所以不假设数据分布的正态性,这在分类模型中通常是一个优势。
- 样本量:即使样本量较小,符号秩检验也适用,但样本量过小时,检验的统计效能可能较低。
- 解释结果:符号秩检验只告诉我们两个模型是否有显著差异,但不能告诉我们哪个模型更好。需要结合其他性能指标来判断模型的优劣。
在Matlab中实现:
假设你有两个模型的预测结果
model1_pred和model2_pred,以及真实标签y_true,你可以使用以下代码进行符号秩检验:% 假设model1_pred和model2_pred是两个模型对同一数据集的预测概率或预测类别 % y_true是真实标签 % 使用预测概率差异 prob_diff = model1_pred - model2_pred; p = signrank(prob_diff); % 或使用分类准确率差异 correct1 = (model1_pred == y_true); correct2 = (model2_pred == y_true); accuracy_diff = correct1 - correct2; p = signrank(accuracy_diff);通过这些方法,你可以比较分类模型的预测性能,并使用符号秩检验来判断两个模型的预测能力是否有显著差异。记得结合其他性能指标(如AUC、F1分数等)来全面评估模型的表现。
最终,对于三个混合 CNN-LSTM 模型,C-LSTM 在两个经典混合 CNN-LSTM 模型(即级联模型和平行模型)之上表现出优异的性能( p − v a l u e s < 0.03 p−values<0.03 p−values<0.03 ,Wilcoxon 符号秩检验)。特别是在 BCI IV 2a 上,C-LSTM 在所有评估模型中实现了最佳的分类准确率(69.1%)。实际上,这个模型是浅层卷积神经网络的一个扩展版本。作者利用一个额外的 LSTM 层来捕捉特征之间的时间依赖性,以便做出更好的决策。对于级联模型和平行模型,尽管它们都采用了看似更复杂的输入公式,即拓扑保持图像,并且包含更多的可学习参数,但它们在这两个数据集上的性能一般。
3.2.3. 代表性模型的效率
除了模型性能外,模型效率也是一个重要的指标。在本部分,我们进一步评估和分析代表性 MI-EEG 模型的训练和测试时间。表 8 显示了 13 个代表性模型在两个公共数据集上的运行性能。以下三点需要注意。
(1)工作[115]表明,相同的深度学习模型在不同的深度学习框架实现时表现出不同的运行时间。因此,表 8 中数值接近的结果可能不可直接比较,因为不同模型的源代码可能基于不同的深度学习框架(例如 tensorflow 和 pytorch)。表 5 列出了每个模型源代码所基于的深度学习框架。
(2)少量 epoch 并不意味着模型训练时间更短,例如级联模型、LSTM 模型等。
(3)为了更好地评估代表性模型的运行性能,我们对每个模型进行了五次测试,然后计算平均值和标准差。
根据表 8,我们有几个观察结果。首先,除了 LSTM 模型外,所有以原始 EEG 数据为输入的对比模型训练速度都比以拓扑保持图像或时频谱图图像为输入的模型快,例如级联模型、并行模型和 pCNN。这可能是两个原因造成的:
(1)利用拓扑保持或谱图图像作为输入的模型通常采用更复杂的网络架构,如混合 CNN-LSTM 网络。然而,以原始 EEG 数据为输入的模型(例如 EEGNet 和浅层卷积神经网络)通常基于 CNN 架构,这些架构通常简单且包含较少的可训练参数。
训练时间的区别
(2)一些以计算特征为输入的模型,例如 pCNN,在将原始 EEG 数据转换为图像的过程中,增加了一个额外的预处理步骤。然而,以原始 EEG 数据为输入的模型没有这样的额外步骤。 其次,与基于 LSTM 的模型相比,基于 CNN 的模型通常需要更少的训练时间,因为 LSTM 单元在每个时间点执行复杂的计算,以及混合 CNN-LSTM 模型,如并行模型,通常具有复杂的网络架构。例如,一个代表性的基于 CNN 的模型,即 ETENet,在 PhysioNet 和 BCI IV 2a 上分别只需要大约 131.6 秒和 15.7 秒来完成训练过程,而 LSTM 模型在两个数据集上分别需要大约 15,614 秒和 2416.6 秒来完成训练过程。然而,这并不意味着非 CNN 模型在训练速度上总是比 CNN 模型慢。C-LSTM 是一个典型的例子。该模型在两个数据集上分别只需要大约 219.65 秒和 38 秒来完成训练过程,这比许多基于 CNN 的模型,如 pCNN、EEGNet 融合、TS-SEFFNet 等都要快。如第 3.2.2 节所述,C-LSTM 只是简单地修改了一个紧凑的模型,即浅层卷积神经网络。这可以解释为什么它只需要相对较少的训练时间。 第三,所有评估的模型在测试数据集上进行预测所需时间都很短(我们称之为测试时间)。具体来说,大多数模型可以在一秒内完成 115 个 EEG 试验的预测,除了几个具有复杂架构和/或大量参数的模型,例如 EEGNet 融合、级联模型等。LSTM 模型在预测时最慢,但其测试时间仍然可以接受(大约 11 秒)。
表 8. 基于深度学习的代表性 MI-EEG 模型的运行性能。加粗值表示最小时间成本或最小训练轮数,而斜体值表示最大时间成本或最大训练轮数。所有模型均在配备 GPU(即 Nvidia Quadro P6000)的同一台机器上评估。测试时间表示模型预测 115 个 EEG 试验所需的总时间。s 表示秒。
Nvidia Quadro P6000相当于
P6000拥有3840个CUDA核心
TITAN X和RTX 3090分别拥有3584和10496个CUDA核心
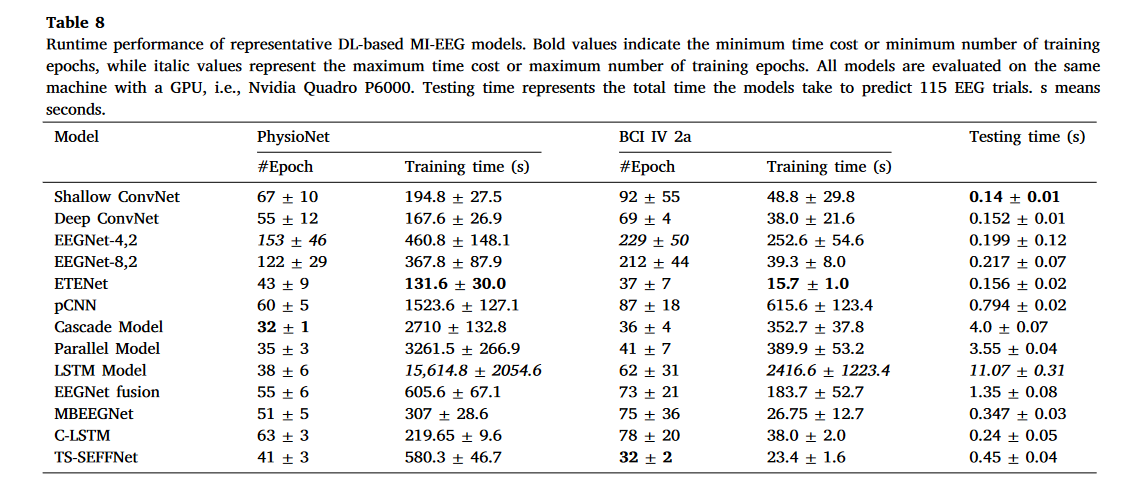
表 9. Wilcoxon 符号秩检验用于比较 EEGNet 融合与其 EEGNet 分支。基线为 EEGNet 融合。EEGNet 融合-B1、-B2 和-B3 的结构如图 11(a)所示。
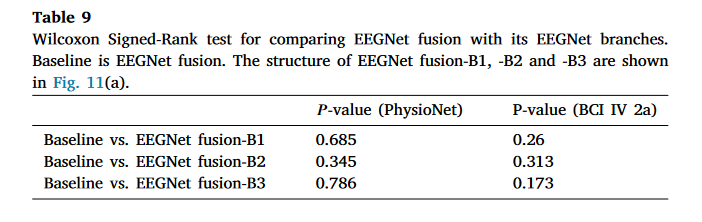
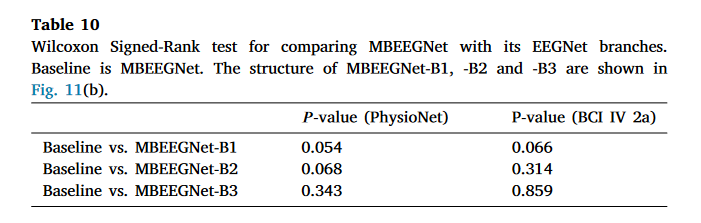
表 10. Wilcoxon 符号秩检验,用于比较 MBEEGNet 及其 EEGNet 分支。基线为 MBEEGNet。MBEEGNet-B1、-B2 和-B3 的结构如图 11(b)所示。
3.3. 典型模型的消融研究
在这一节中,我们通过消融研究探讨了某些设计因素对典型网络设计性能的影响。在我们讨论和分析消融研究的结果之前,我们首先介绍在基于深度学习的脑电图-肌电图(MI-EEG)分类中通常进行的三种消融研究类型:网络架构消融、特征消融和通道消融。
(1)网络架构消融[30],[116]通过从模型中移除相应的部分来分析 DL 模型特定部分对模型性能的影响。
(2)特征消融[117]是一种过程,其中每个输入特征被一个给定的参考值替换,并计算其与原始性能的差异并进行分析。
(3)通道消融(CA)[24]通过移除一些脑电图(EEG)通道或仅使用一些特定通道来研究特定 EEG 通道对模型性能的影响。
这里,我们主要关注网络架构消融,以揭示深度学习模型未来设计。
表 11. EEGNet 融合及其 EEGNet 融合分支的分类结果。EEGNet 融合-B1、-B2 和-B3 分别代表具有输出层的 EEGNet 融合的第一个、第二个和第三个分支。
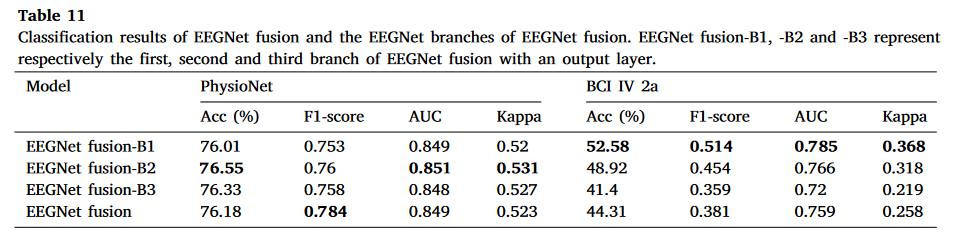
表 12. MBEEGNet 及其 EEGNet 分支的分类结果。MBEEGNet-B1、-B2 和-B3 分别代表 MBEEGNet 的第一个、第二个和第三个带有输出层的分支。
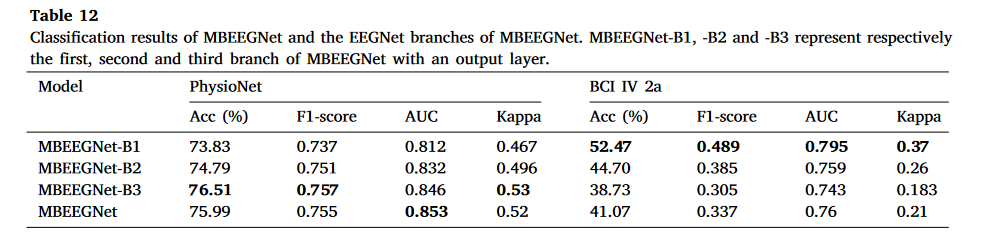
表 13. 不同隐藏层数量的 LSTM 模型的分类性能。
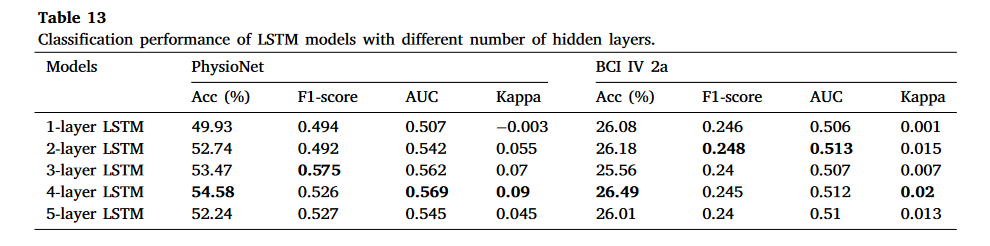
表 14. 比较单层 LSTM 模型与多层 LSTM 模型的 Wilcoxon 符号秩检验。
有效的特征融合对于设计精确的多流 CNN 模型至关重要。
我们评估的两个多流 CNN 模型,即 EEGNet 融合和 MBEEGNet,由输入层、三个不同的分支、特征连接层和输出层组成。它们的每个分支都具有与 EEGNet 相同的架构,但没有输出层(见图 11)。如第 3.2 节所述,这两个模型(即 EEGNet 融合和 MBEEGNet)在两个数据集上并未表现出比 EEGNet 两种配置更优越的性能。这引发了一个问题:上述两个多流 CNN 模型(具有多个分支)是否比每个分支对应的三个不同的 EEGNet 配置更准确?如果不是,这意味着简单地连接不同分支提取的特征并不是一个好的设计选择。为了回答这个问题,我们在两个公开数据集上分别评估了 EEGNet 融合和 MBEEGNet 每个分支的分类性能。
具体来说,我们使用了两个模型每个分支的相应源代码,并为每个分支添加了一个输出层。 通过这样做,我们获得了基于 EEGNet 融合和 MBEEGNet 的不同配置的三个 EEGNet 模型(见图 11)。然后,我们分别比较了 EEGNet 融合和 MBEEGNet 与获得的相应 EEGNet 模型的分类性能。表 11、表 12 显示了消融研究的结果。可以看出,在某些情况下,EEGNet 融合的一些分支优于完整模型(参见表 11)。同样,表 12 显示在某些情况下,MBEEGNet 的一些分支比完整模型表现更好。为了评估表 11、表 12 中显示的平均准确率差异是否随机,我们进一步进行了表 9、表 10 中所示的 Wilcoxon 符号秩检验。从表 9 中,我们看到在两个数据集上,EEGNet 融合与其 EEGNet 分支 ( p − v a l u e s > 0.15 ) ( p − values>0.15 ) (p−values>0.15)之间没有统计学上的显著差异。同样,在表 10 中,我们没有看到 MBEEGNet 与其 EEGNet 分支 ( p − v a l u e s > 0.05 ) ( p − values>0.05 ) (p−values>0.05)之间有显著的性能差异。这表明,简单地融合来自不同特征提取分支的特征不能提高分类性能。 主要原因是,在不进行特征选择的情况下融合不同的特征往往会导致无关信息的累积[118],这可能会对模型性能产生负面影响。因此,对于基于多流 CNN 的模型,特征融合层应该仔细设计。
LSTM 应与能够提取空间特征的技巧结合,当使用原始 EEG 数据作为输入时。如图 3.2 所示,具有一个隐藏层的 LSTM 在两个公开数据集上只能达到随机水平准确率。为了调查这种糟糕的性能是否由 LSTM 层数量不足引起,我们测试了具有更多隐藏层的 LSTM 的分类性能。性能结果如表 13 所示。根据表 14 所示的 Wilcoxon 符号秩检验,增加更多 LSTM 层(最多 5 个隐藏层)后,性能没有显著提高。这意味着仅仅增加 LSTM 层到 LSTM 模型中并不能在分类性能上带来显著改进。主要原因可能是纯 LSTM 模型通常缺乏捕获 EEG 通道之间空间依赖性的能力,尽管 LSTM 层能够学习时间特征。提高模型性能的一个可行策略是将 LSTM 与其他能够学习 EEG 通道之间空间依赖性的技术相结合,例如 CNN[30]、[81]或 CSP[15]。 为了找出添加额外的空间特征提取是否能提高模型性能,我们对两种典型的混合 CNN-LSTM 模型:级联模型和 C-LSTM 进行了消融研究。对于级联模型,我们从其中移除了空间特征提取部分,即一个 2D-CNN 和一个全连接层。剩余部分是一个两层隐藏层的 LSTM 模型。同样,关于 C-LSTM,我们主要保留其 LSTM 部分,并评估修剪后的 C-LSTM 的性能。对于这两个修剪后的模型,我们使用与原始模型相同的段数据作为输入。表 15、表 16 显示了消融研究的成果。可以看出,从两个混合 CNN-LSTM 模型中移除 CNN 空间特征提取导致在两个基准数据集上性能显著下降( p − values<0.05 )。这证实了为了更好地解码 MI-EEG 信号,LSTM 应该结合额外的特征提取技术进行增强。
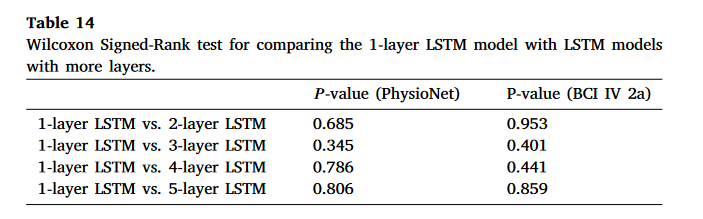
**Dropout 的使用可能对模型性能的提升贡献有限。**如第 3.2 节所述,在基于单流 CNN 的模型中,ETENet 是唯一一个在训练过程中没有采用 Dropout 的模型[119]。事实上,由于 Dropout 在减少过拟合方面的有效性,它已被广泛应用于基于深度学习的 MI-EEG 解码模型中,如[21]、[22]、[47]。因此,探索 Dropout 对模型性能的影响将很有趣。为此,我们进行了以下实验。(1)我们在 ETENet 的池化层之后添加了一个 Dropout 层,类似于许多典型的基于单流 CNN 的模型[21]、[22]、[31]。然后,我们将其分类性能与原始模型进行比较。Dropout 率设置为 0.5,与许多现有方法[21]、[22]、[31]相同。(2)我们从几个典型模型(即 Shallow ConvNet、Deep ConvNet、EEGNet-8,2 和 TS-SEFFNet)中移除了 Dropout 层,并将它们与相应的原始模型进行比较。表 17 显示了性能结果。 尽管在训练过程中应用 dropout 可以在大多数情况下提高模型性能,但根据表 17 和表 18,对于所有五种典型解码模 型,分类性能的提升并不显著。这证实了 dropout 在模型训练中的贡献是有限的。
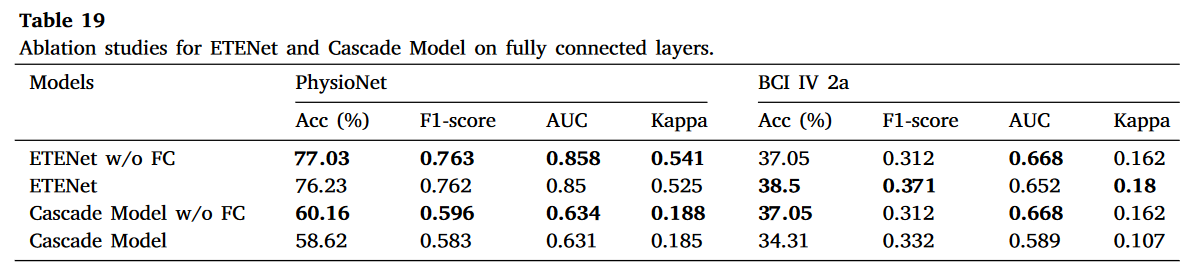
**添加全连接层到模型可能不是一个好的设计选择。**如第 3.2 节所述,ETENet 和 Shallow ConvNet 的网络架构的主要区别在于 ETENet 在输出层之前有一个额外的全连接(FC)层。通过进一步研究,我们发现这个额外的 FC 层占 ETENet 总参数数(约 305.5k)的 66%(约 201.6k)。由于 ETENet 在两个公开数据集上也没有比 Shallow ConvNet 表现出更优越的性能(见表 6),这引起了我们对 FC 层对模型性能影响的好奇。为此,在我们的消融研究中,我们评估了两个代表性模型(即 ETENet 和级联模型)去掉 FC 层后的性能。结果如表 19 所示。从表中我们可以看到,这两个模型去掉 FC 层后与它们之间没有显著的性能差异( p − values>0.4 )。这表明 FC 层对于这两个模型可能是多余的。考虑到 FC 层通常占训练参数总数的很大比例,我们建议未来的研究应该谨慎添加 FC 层。 至少,我们应该验证添加的 FC 层对模型性能有积极影响,尤其是在训练数据集不够大的情况下。
请注意,本文中提到的网络架构被用于各种其他 EEG 分类任务(例如,EEG 情绪识别[120]、EEG 抑郁症诊断[121]等),因此我们上述的结论也可以为这些 EEG 分类任务的网络设计提供信息。未来的研究需要进一步验证这一点。
表 15. 在两个公开的 MI-EEG 数据集上对级联模型进行的消融研究。

表 16. 在两个公开的 MI-EEG 数据集上对 C-LSTM 的消融研究。

表 17. 几种典型模型带和不带 dropout 的分类结果。
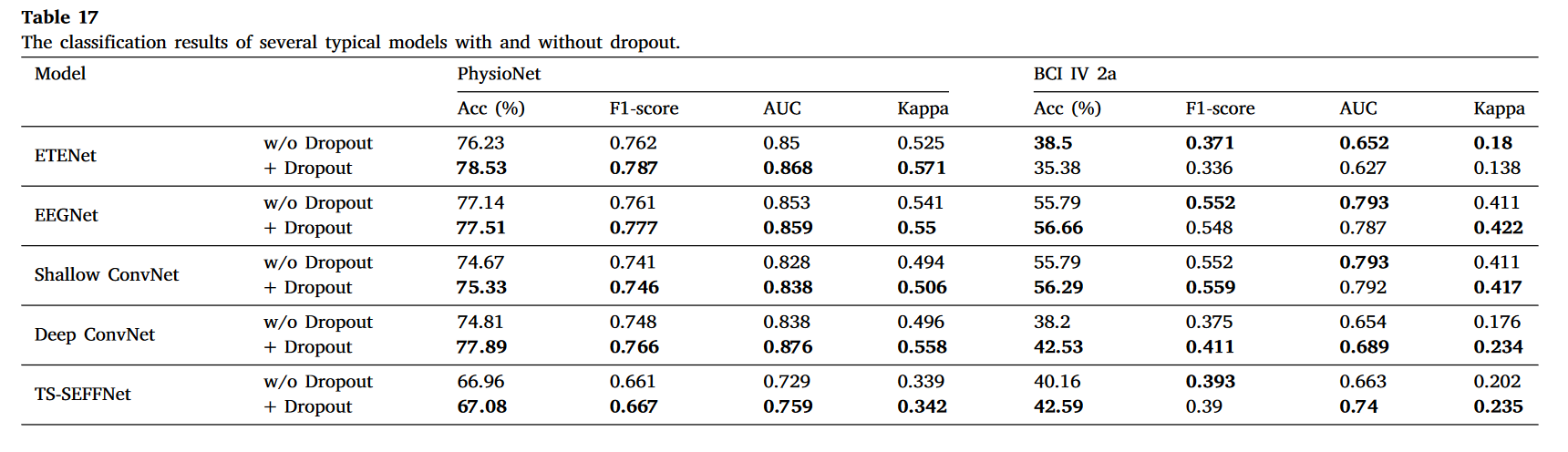
表 18. Wilcoxon 符号秩检验用于评估 MI-EEG 解码模型分类性能差异是否显著。“w/o”表示无。
表 19. ETENet 和级联模型在全连接层上的消融研究。
4. 开放性问题与未来研究方向
基于深度学习的模型在 MI-EEG 分类方面取得了显著进步,但仍存在一些限制,这减缓了该领域的发展。在本节中,我们讨论了一些开放问题和潜在的研究方向。
4.1. 网络架构设计
尽管迄今为止已经开发出各种网络架构(见第 2.4 节),但如何设计更有效的解码网络以进一步提高分类性能仍然是一个具有挑战性的问题。
基于第 3.2 节对 13 个典型模型的评估,我们可以看到 FBCSP-like 单流 CNN 架构显示出巨大的潜力,一些研究人员(例如[21])已经基于这种设计模式开发出准确且极其紧凑的模型。
除了类似 FBCSP 的单流 CNN 架构之外,使用一些新兴的网络架构,例如 CapsuleNet [34],可能是一个有希望的研究方向。然而,由于这个方向文献有限,还需要进一步研究。此外,目前还没有新架构的源代码可用。
更重要的是,现有的基于深度学习的 MI-EEG 分类模型通常设计得比较经验化。这限制了更好网络架构的发现。一个有希望的解决方案是利用**神经架构搜索(NAS)**来自动发现最优网络架构,因为一些研究[122],[123]表明,NAS 找到的网络在图像分类等领域的表现优于手工设计的网络。
4.2. 不平衡的 MI-EEG 数据
由于某些因素,例如数据缺失、受试者退出实验等,在 MI-EEG 数据集中,每个受试者以及/或每个类别的 MI 试验数量不平衡是很常见的,这对基于深度学习(DL)的模型性能有负面影响[124]。
一种常见的解决数据不平衡问题的方法是使用数据增强,这可以使不同类别和被试的试验次数保持相同。许多数据增强技术,如[11]、[31]、[59],已被提出并在 MI-EEG 分类中使用。其中一些受到图像分类任务的启发,例如添加噪声[31]、翻转数据[31]等。事实上,这些技术(即添加噪声和翻转数据)也常用于其他 EEG 分类任务[125]、[126]。此外,一项最近的研究[127]也试图通过使用生成对抗网络(GAN)来增强数据,这是解决 MI-EEG 分类中数据不平衡的一个潜在研究方向。
4.3. 数据分布差异
一些关于数据迁移的问题,脑电采集的数据差距非常大
现有基于深度学习的算法通常在训练集和测试集具有相同数据分布时能实现良好的分类性能[21]。然而,在现实世界中往往难以满足这一理想条件。例如,由于不同受试者之间存在不同的脑电图模式、受试者头皮上脑电帽的不同放置等原因,收集到的 MI-EEG 数据在受试者之间分布差异显著[64]。当从不同受试者收集的数据被分为训练集和测试集时,这两个集合之间存在数据分布差异,可能导致负迁移[64],[128]。负迁移意味着使用源域数据训练会削弱在目标域数据测试时模型的分类性能,这主要是由于源域和目标域之间的数据分布不同。
一种可能的解决方案是采用有效的迁移学习。到目前为止,一些基于深度学习的近期工作,如[36]、[52]、[73],已在脑电图分类中应用迁移学习。这些工作中的迁移学习可以归类为微调适应[73]、[129]和领域对抗适应[36]、[52]、[53]。
微调适应在 MI-EEG 分类中通常包括三个步骤。
第一步是选择一个有效的预训练模型(例如,VGG16 [130]、ResNet50 [131]、Deep ConvNet [22]等)。
第二步是将预训练模型的输出层替换为一个新的输出层,其中神经元的数量等于目标任务的类别数。
第三步是使用目标 EEG 数据或基于目标 EEG 数据的频谱图像对修改后的预训练模型进行微调,这使得模型能够应用于目标 EEG 分类任务。
领域对抗适应最近引起了广泛关注。一些研究[36]、[52]、[53]开发了领域对抗神经网络(DANN)来解决源域和目标域在 MI-EEG 分类中的分布差异。这些基于 DANN 的方法通常包含一个特征提取器、一个分类器和领域判别器。特征提取器用于从源域数据和目标域数据中获取深度表示。分类器的工作是解码获取到的特征表示。至于领域判别器,它被设计用来预测领域标签。在训练期间,判别器试图预测特征提取器提取的特征表示的来源,而特征提取器则试图欺骗判别器,使判别器无法预测特征表示的领域标签。这迫使特征提取器提取更通用的特征,从而减轻源域和目标域之间的分布差异。
所有这些基于迁移学习的方法都在它们原始论文中报告了它们相对于一些传统方法(例如,DNN、标准 CNN 等)的优越性能。特别是基于领域对抗适应的方法,所报告的结果[52],[53]表明它们可以超越一些 SOTA MI-EEG 分类模型(例如,EEGNet)。这表明基于领域对抗适应的模型具有广阔的前景。然而,对于基于领域对抗适应的方法,仍存在一些开放性问题,例如由于共享特征提取器[36],[52]导致的领域特定特征的损失,以及由于额外的判别器[36],[52]或分类器[53]导致的复杂训练过程。上述问题需要进一步研究。
最近的一项研究[132]全面调查了负迁移,并提出了一种可靠的迁移学习方案以减轻负迁移。作者根据领域相似性估计的结果提供了一些避免负迁移的解决方案,这可能会对未来的研究有所帮助,尤其是对跨学科训练。
4.4. 基于脑电图(EEG)的脑机接口(MI-BCI)系统的实际应用
最近,研究人员[57]、[60]、[78]倾向于设计越来越复杂的网络架构。尽管这些最近模型在分类性能上优于许多先前方法,但它们的高模型复杂度可能会影响推理速度,这对于实际应用至关重要[133]。事实上,大多数现有工作只关注分类性能,而忽略了其他因素,如推理速度和模型大小,这些因素对于实际应用是必不可少的。
未来研究应考虑模型复杂性,因为 BCI 系统需要在现实世界的移动设备中部署并产生实时预测。一种可能的解决方案是使用网络剪枝技术[134],这可以从训练模型中移除冗余参数,同时最小化分类性能的损失。这类技术可能有助于一些高性能但复杂的模型在现实应用中被采用。在图像分割和目标检测等领域,研究[135]、[136]表明,网络剪枝方法对于开发具有高分类精度的轻量级模型是有效的。
5. 结论
深度学习技术的快速发展在很大程度上促进了 MI-EEG 分类的发展。目前,由于能够自动执行特征工程,使用深度学习开发 MI-EEG 解码模型已成为主流。尽管各种深度学习技术已应用于 MI-EEG 分类,但大多数现有研究通常基于几种网络架构,例如 CNN、LSTM、混合深度网络等。
性能比较通常用于验证模型的有效性。然而,我们发现许多现有工作的性能比较存在几个问题。(1)跨学科分类的不同含义。(2)在性能比较中使用的不同评估策略(例如,执行不同的分类任务来评估基线和提出的模型)。(3)当没有公开可用的源代码时,对基线模型的不同解释。(4)仅在私有数据集上进行的性能比较。这些问题可能导致结果无效和/或不公平的比较。在本文中,我们提出了未来研究应使用的几个指南,以克服上述问题。
在使用的深度学习技术中,CNN 是最受欢迎的设计选择。基于 CNN 的模型通常使用原始 EEG 数据或提取的时间-频率域特征作为输入。当输入公式是前者时,SOTA 传统方法(即 FBSCP)的计算步骤通常被采用作为模型设计的指南。当后者被选为输入时,网络设计通常借鉴计算机视觉模型的经验。通过评估和比较两个基准数据集上的典型解码模型,我们惊讶地发现,一个极其简单的类似 FBCSP 的单流 CNN 解码模型(即 EEGNet)可以比许多具有更复杂网络架构的最近模型实现更好的性能。这表明类似 FBCSP 的 CNN 架构是一个有希望的设计选择。此外,通过消融研究,我们发现并验证了有效的特征融合对于开发准确的多流 CNN 模型起着不可或缺的作用。LSTM 是另一种广泛用于 MI-EEG 分类的深度学习技术。 然而,我们的实验结果表明,仅仅堆叠 LSTM 层的模型无法很好地分类原始 EEG 信号。尽管 CNN 和 LSTM 模型(即 C-LSTM)的组合可以取得非常具有竞争力的性能,但我们评估的其他两个代表性 CNN-LSTM 混合模型仅实现了平庸的性能,这可能是由于它们的复杂网络架构和数据不足。最近,一些研究人员也探索了其他可能的深度学习技术组合,例如 GCN 和 BiLSTM 的组合。由于文献有限,对这些混合架构的进一步研究是必要的。
缺少了对于图卷积的相关研究在EEG应用的推荐。
用的几个指南,以克服上述问题。
在使用的深度学习技术中,CNN 是最受欢迎的设计选择。基于 CNN 的模型通常使用原始 EEG 数据或提取的时间-频率域特征作为输入。当输入公式是前者时,SOTA 传统方法(即 FBSCP)的计算步骤通常被采用作为模型设计的指南。当后者被选为输入时,网络设计通常借鉴计算机视觉模型的经验。通过评估和比较两个基准数据集上的典型解码模型,我们惊讶地发现,一个极其简单的类似 FBCSP 的单流 CNN 解码模型(即 EEGNet)可以比许多具有更复杂网络架构的最近模型实现更好的性能。这表明类似 FBCSP 的 CNN 架构是一个有希望的设计选择。此外,通过消融研究,我们发现并验证了有效的特征融合对于开发准确的多流 CNN 模型起着不可或缺的作用。LSTM 是另一种广泛用于 MI-EEG 分类的深度学习技术。 然而,我们的实验结果表明,仅仅堆叠 LSTM 层的模型无法很好地分类原始 EEG 信号。尽管 CNN 和 LSTM 模型(即 C-LSTM)的组合可以取得非常具有竞争力的性能,但我们评估的其他两个代表性 CNN-LSTM 混合模型仅实现了平庸的性能,这可能是由于它们的复杂网络架构和数据不足。最近,一些研究人员也探索了其他可能的深度学习技术组合,例如 GCN 和 BiLSTM 的组合。由于文献有限,对这些混合架构的进一步研究是必要的。
缺少了对于图卷积的相关研究在EEG应用的推荐。
基于深度学习的 MI-EEG 分类方法取得了一些进展。然而,仍存在一些挑战,例如数据分布差异和对现实应用重要性的忽视。通过利用我们的性能比较指南和我们对典型 MI-EEG 分类架构设计性能有影响的设计因素的研究发现,我们希望未来的研究能够公平且迅速地解决这些问题。

















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









