






全球模型的收敛性常常受到数据异质性的影响。本研究从类似于持续学习出发,提出遗忘(forgetting)可能是联邦学习的瓶颈。观察到全局模型遗忘了来自前几轮的知识,而局部训练导致遗忘了局部分布之外的知识。基于我们的发现,我们假设解决向下遗忘将缓解数据异质性问题。
为此,我们提出了一种新颖有效的算法--联邦非真蒸馏(Federated Not-True Distillation,FedNTD),它只针对非真类保留了在局部可用数据的全局视角。
1 Introduction
在连续学习中,学习者模型在任务序列上连续更新,目标是在所有任务上执行良好。不幸的是,由于每个任务的异构数据分布,对任务序列的学习经常导致灾难性的遗忘,由此对新任务的拟合干扰了先前任务的重要参数。结果,模型参数从期望保留先前知识的区域漂移开,也就是需要保留的参数由于新任务就丢失了。
第一个猜想是这种遗忘也存在于联邦学习中。虽然服务器聚集了本地模型,但是它们被训练的本地分布可能与前几轮的本地分布有很大不同。结果,全局模型在每一轮都面临着分布的变化,这可能导致持续学习中的遗忘。为了从经验上验证这一类比,我们检验了全局模型的预测一致性。更具体地说,我们在通信循环进行的同时测量全局模型的类精确度的一致性。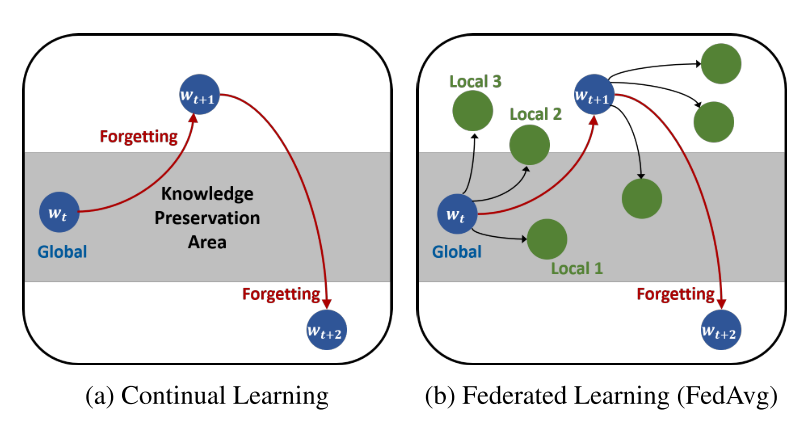
观察验证我们的猜想:全局模型的预测是在通信轮 类维度的预测不一致,极大地降低了性能。一些先前全局模型预测的很好,经过本地模型聚合后 就预测的不好了。
我们深入分析了对局部更新的参数求平均值是如何导致这种遗忘的,并证实了它发生在局部训练中:对应于局部分布之外的全局知识容易被遗忘。
我们假设减轻遗忘问题可以缓解数据异构性。提出FedNTD,FedNTD利用全局模型对本地可用数据的预测,但仅针对非真类。本文展示了FedNTD在保存本地分布之外的全局知识方面的效果以及它在联邦学习方面的好处。
本文对联邦学习中的遗忘现象进行了系统的研究。局部分布之外的全局知识容易被遗忘,并且与数据异构问题密切相关
本文贡献:
- 本文对联邦学习中的遗忘现象进行了系统的研究。局部分布之外的全局知识容易被遗忘,并且与数据异构问题密切相关。
- 提出一个简单而有效的算法FedNTD来防止遗忘。与之前的工作不同,FedNTD既不会损害数据隐私,也不会增加额外的通信负担。我们验证了FedNTD在各种设置上的有效性,并显示始终实现最先进的性能。
- 分析了FedNTD在联邦学习中的优势。FedNTD的知识保存改善了局部训练后的权重对齐和权重发散。
1.1 Preliminaries
联邦学习:目标是在由K个客户端和一个中央服务器组成的联邦学习系统中训练一个图像分类模型。每个客户端k具有本地数据集Dk,其中整个数据集![]() 在每个通信回合t,服务器将当前全局模型参数
在每个通信回合t,服务器将当前全局模型参数![]() 分发给采样的本地客户端
分发给采样的本地客户端![]() 。从
。从![]() 开始,每个客户端
开始,每个客户端![]() 使用其本地数据集Dk更新模型参数
使用其本地数据集Dk更新模型参数![]() ,目标如下:
,目标如下:

在第t轮结束时,被采样的客户端将本地更新的参数上载回服务器,并通过参数平均来聚集为![]() :
:
知识蒸馏:
2 Forgetting in Federated Learning
为了理解非IID数据如何影响联邦学习,我们在异构局部上进行了实验研究。我们选择CIFAR-10 和如中的具有四层的卷积神经网络。我们使用狄利克雷分配(LDA)将数据分割到100个客户端,通过![]() 将c类样本的分区分配给客户端。异质性水平随着α的降低而增加。我们使用FedAvg训练模型200次通信循环,并且在每一次循环中针对5个局部时期对10个随机抽样的客户端进行优化。
将c类样本的分区分配给客户端。异质性水平随着α的降低而增加。我们使用FedAvg训练模型200次通信循环,并且在每一次循环中针对5个局部时期对10个随机抽样的客户端进行优化。
2.1 Global Model Prediction Consistency
为了证实我们关于遗忘的猜想,我们首先考虑全局模型的预测如何随着通信回合的进行而变化。如果数据异质性导致遗忘,则更新后的预测(即,参数平均)与前一轮相比可能不太一致。为了检验它,我们观察模型在每一轮的类检验准确率,并测量它与前一轮的相似性。
正如所料,虽然服务器模型从i.i.d locals(IID服务器)在每轮中均匀地预测每个类,而在非IID的情况下(NIID服务器),预测是高度不一致的。在非IID的情况下,以前的全局模型对某些类的预测精度往往会显著下降。这意味着遗忘发生在联邦学习中。(证明存在这种现象。)

为了测量遗忘如何与数据异质性相关,我们借用了后向迁移(BwT)的思想,这是持续学习中流行的遗忘测量方法 : 其中
其中![]() 是第t轮时c类的准确度。注意,遗忘度量F捕获学习结束时每个类别的峰值准确度和最终准确度之间的平均差距。不同异质性水平的结果如图C所示,显示随着异质性水平的增加,全球模型的遗忘程度更严重。
是第t轮时c类的准确度。注意,遗忘度量F捕获学习结束时每个类别的峰值准确度和最终准确度之间的平均差距。不同异质性水平的结果如图C所示,显示随着异质性水平的增加,全球模型的遗忘程度更严重。
2.2 Knowledge Outside of Local Distribution
我们更仔细地观察局部训练,以研究为什么聚集局部模型会导致遗忘。在持续学习的观点中,一个直接的方法是观察新分布的拟合如何降低旧分布的性能。然而,在我们的问题设置中,本地客户端可以有任何类。假设在客户端之间只有它们在本地分布中的部分不同,那么这种严格的比较是难以处理的。因此,我们建立了局部内分布![]() (in-local distribution)和局部外分布
(in-local distribution)和局部外分布![]() (out-local distribution)来系统地分析局部训练中的遗忘现象。
(out-local distribution)来系统地分析局部训练中的遗忘现象。

(指示函数Ⅱ('),‘为真为1,反之为0。其实![]() 向量就是对每个类的样本进行比例统计,即这个类占总样本多少。
向量就是对每个类的样本进行比例统计,即这个类占总样本多少。![]() 则反之,但是多除了个C-1。)
则反之,但是多除了个C-1。)

外部本地分布![]() 的基本思想是为局部数据集中样本较少的类分配较高的比例。(我的理解是它给那些在本地数据集中样本较少的类别分配更高的权重,从而增强它们在全局知识中的表达。)因此,它对应于全局分布中局部分布
的基本思想是为局部数据集中样本较少的类分配较高的比例。(我的理解是它给那些在本地数据集中样本较少的类别分配更高的权重,从而增强它们在全局知识中的表达。)因此,它对应于全局分布中局部分布![]() 不能表示的区域。注意,如果
不能表示的区域。注意,如果![]() 是均匀的,
是均匀的,![]() 也会坍缩成均匀的,这在直觉上是对齐的。图3提供了10个客户端及其
也会坍缩成均匀的,这在直觉上是对齐的。图3提供了10个客户端及其![]() 和
和![]() 的标签分发示例
的标签分发示例
我们测量![]() 和
和![]() 的全局和局部准确度的变化,如图4所示。局部训练后,局部模型与
的全局和局部准确度的变化,如图4所示。局部训练后,局部模型与![]() 拟合良好(图a),聚合全局模型也表现良好;另一方面,
拟合良好(图a),聚合全局模型也表现良好;另一方面,![]() 的精度显著下降,全局模型的精度也有所下降(图b)。
的精度显著下降,全局模型的精度也有所下降(图b)。
 总而言之,在局部训练中容易忘记关于外局部分布
总而言之,在局部训练中容易忘记关于外局部分布![]() 的知识,从而导致全局模型的遗忘。基于我们的发现,我们假设遗忘可能是联邦学习的绊脚石。
的知识,从而导致全局模型的遗忘。基于我们的发现,我们假设遗忘可能是联邦学习的绊脚石。
(至于说,在![]() 和
和![]() 上的正确率,我理解是:比如在
上的正确率,我理解是:比如在![]() 上的正确率是挑选最高概率的,或者说样本多的,那么本地正确率肯定高。而
上的正确率是挑选最高概率的,或者说样本多的,那么本地正确率肯定高。而![]() 也是挑选最高概率的,即样本数少的,这种训练的少正确率低,但是全局模型包含着别的本地模型,说不定这个类多,所以t-1时全局模型对这个类的训练效果好,经过比较菜的这个local,反而被干扰了。)
也是挑选最高概率的,即样本数少的,这种训练的少正确率低,但是全局模型包含着别的本地模型,说不定这个类多,所以t-1时全局模型对这个类的训练效果好,经过比较菜的这个local,反而被干扰了。)
2.3 Forgetting and Local Drift
局部更新与理想的全局方向的偏差已经被广泛讨论为异构联邦学习中缓慢和不稳定收敛的主要原因。不幸的是,考虑到分析这种漂移非常困难,常用的方法是假设局部函数梯度之间的不相似有界性.
局部外分布(out-local distribution)知识保持的一个有趣的性质是它将局部梯度向全局方向修正。(这里的局部外分布应该是对应于局部分布之外的全局知识)我们定义了梯度差异 Λ来度量局部梯度相对于全局函数的梯度不相似性,并将知识保存的效果陈述如下
Definition 2.对于均匀加权的K个客户端,局部函数 朝向全局函数
朝向全局函数 的梯度多样性Λ定义为:
的梯度多样性Λ定义为:
这里,Λ >= 1 测量局部函数 ![]() 的梯度方向相对于全局函数 f 的对齐。注意,随着局部函数梯度多个
的梯度方向相对于全局函数 f 的对齐。注意,随着局部函数梯度多个![]() 的方向变得相似,Λ 变小。例如,如果
的方向变得相似,Λ 变小。例如,如果 ![]() 的向量大小(范数)是固定的,当多个
的向量大小(范数)是固定的,当多个![]() 的方向相同时得到最小的Λ。
的方向相同时得到最小的Λ。
Proposition 1. 假设K个客户端的权重一致,局部分布为 ,如果我们假设类维度梯度gc是正交的且具有均匀的量级(与其他向量垂直,并且长度相同),通过增大
,如果我们假设类维度梯度gc是正交的且具有均匀的量级(与其他向量垂直,并且长度相同),通过增大 来削减来自于局部梯度
来削减来自于局部梯度 的梯度差异值Λ
的梯度差异值Λ
β表示知识保存对外局部分布![]() 的影响。
的影响。![]() 是 由
是 由![]() 构成的连续项。
构成的连续项。![]() 为类维度损失的总和
为类维度损失的总和![]() 。其中
。其中![]() 是对于特定类的损失值。当β=0时,没有正则化来保持外分布知识,因此局部模型只需要拟合在局部分布
是对于特定类的损失值。当β=0时,没有正则化来保持外分布知识,因此局部模型只需要拟合在局部分布![]() 上。以上的proposition认为在局外分布
上。以上的proposition认为在局外分布![]() 上保存知识(提高β来减少Λ)可以指导局部梯度方向更加向着全局模型对齐。这种遗忘视角提供了在模型的预测级别处理数据异质性的机会。
上保存知识(提高β来减少Λ)可以指导局部梯度方向更加向着全局模型对齐。这种遗忘视角提供了在模型的预测级别处理数据异质性的机会。
问题2:为什么局部外知识可以修正,把局部的梯度修正为全局方向
问题3: ![]() 为类维度损失的总和,那
为类维度损失的总和,那![]() 。为什么要在类维度梯度上乘这个,可以修正方向?怎么做到的。
。为什么要在类维度梯度上乘这个,可以修正方向?怎么做到的。
3 FedNTD: Federated Not-True Distillation
在本节中,将介绍联合非真实蒸馏(FedNTD)及其主要特性。FedNTD的核心思想是只为非真类保留全局视图。更具体地,FedNTD通过交叉熵损失LCE和非真实蒸馏损失LNTD之间的线性组合损失函数L来进行局部蒸馏:![]() (注意,这里学生模型是本地模型,教师模型是全局模型,因为第一个损失函数是本地模型与真实标签的,第二个损失函数才是本地模型和全局模型的。也就是说,本地模型对于non-true的类是要去向全局模型学习)
(注意,这里学生模型是本地模型,教师模型是全局模型,因为第一个损失函数是本地模型与真实标签的,第二个损失函数才是本地模型和全局模型的。也就是说,本地模型对于non-true的类是要去向全局模型学习)
超参数β表示知识在外部分布上的保存强度。然后,非真实蒸馏损失LNTD定义为 非真实softmax预测向量![]() 和
和![]() 之间的KL-散度损失,如下所示:
之间的KL-散度损失,如下所示:


仅对于非真类对数,采用温度为τ的softmax。图5说明了给定样品x时,非真实蒸馏是如何工作的。注意,忽略真实类对数使得LNTD到真实类的梯度信号为0。
现在我们解释学习如何最小化LNTD,以保持关于外局部分布![]() 的全局知识。众所周知,softmax输出的KL散度损失与其logit向量匹配,以缩小其距离,因此我们从logit的均方误差(MSE)损失开始,以简化讨论。虽然不严格,但这给了我们足够的直觉去理解不真实蒸馏的影响。
的全局知识。众所周知,softmax输出的KL散度损失与其logit向量匹配,以缩小其距离,因此我们从logit的均方误差(MSE)损失开始,以简化讨论。虽然不严格,但这给了我们足够的直觉去理解不真实蒸馏的影响。
假设在局部数据集D中存在N个数据点。数据xi的c类logit ![]() 与其要匹配的参考对数
与其要匹配的参考对数![]() 之间的累积MSE损失LMSE为:
之间的累积MSE损失LMSE为:
通过拆分真类和非真类的平方项,项变为:
Proposition 2 .考虑本地分布![]() ,其中
,其中 ![]() 局外分布
局外分布![]() ,其中Sc是满足
,其中Sc是满足![]() 的标记体(数据集合)。
的标记体(数据集合)。
![]() 表示每个类别的归一化logits MSE。
表示每个类别的归一化logits MSE。
注意,以上都是在一个客户端一个服务端上进行的,N是数据样本数,不是客户端数目
通过从等式13的少量计算,我们推导出上述命题。推导见附录O。该命题表明,匹配真类和非真类的logit会崩溃为局域内分布![]() 和局域外分布
和局域外分布![]() 上的损失。(本文告诉读者的就是,对每个类进行校正。如果你这个类样本多时,即
上的损失。(本文告诉读者的就是,对每个类进行校正。如果你这个类样本多时,即![]() 大,则
大,则![]() 小,则Lnot-true影响小,即全局就不用通过Lnot-true来校正你局部对这个类。如果你这个类样本少时, 即
小,则Lnot-true影响小,即全局就不用通过Lnot-true来校正你局部对这个类。如果你这个类样本少时, 即![]() 小,则
小,则![]() 大,则Lnot-true就影响大,全局就通过Lnot-true来校正你局部对这个类)
大,则Lnot-true就影响大,全局就通过Lnot-true来校正你局部对这个类)
在我们的FedNTD损失函数(等式10)中,我们通过使用![]() 跟踪来自局部数据集中的标记数据的真实类信号来获得关于局部内分布的新知识。同时,我们使用
跟踪来自局部数据集中的标记数据的真实类信号来获得关于局部内分布的新知识。同时,我们使用![]() 通过跟随全局模型的视角来保持关于非真实类信号的外部局部分布的先前知识。这里,超参数β控制学习新知识和保留先前知识之间的权衡。这类似于持续学习中的稳定性-可塑性困境,其中学习方法必须在为当前任务学习新知识的同时平衡保留先前任务的知识。
通过跟随全局模型的视角来保持关于非真实类信号的外部局部分布的先前知识。这里,超参数β控制学习新知识和保留先前知识之间的权衡。这类似于持续学习中的稳定性-可塑性困境,其中学习方法必须在为当前任务学习新知识的同时平衡保留先前任务的知识。
4.experience
4.1非IID分区策略
-
Sharding:在碎片策略中,我们按标签对数据进行排序,并将其划分为大小相同但不重叠的碎片。具体来说,一个碎片包含
 同类样本的大小,其中D是总数据集大小,N是客户端总数,s是每个用户的碎片数。然后,我们将s个碎片分配给每个客户端。s控制本地数据分布的异构性。异构性级别随着每个用户的碎片s变小而增加,反之亦然。注意,在Sharding策略中,我们只测试统计异质性(跨本地客户端的类分布的偏斜度),并且本地数据集的大小是相同的。(即|D|/N)
同类样本的大小,其中D是总数据集大小,N是客户端总数,s是每个用户的碎片数。然后,我们将s个碎片分配给每个客户端。s控制本地数据分布的异构性。异构性级别随着每个用户的碎片s变小而增加,反之亦然。注意,在Sharding策略中,我们只测试统计异质性(跨本地客户端的类分布的偏斜度),并且本地数据集的大小是相同的。(即|D|/N) - Latent Dirichlet Allocation (LDA):在LDA策略中,每个客户k被分配c类训练样本的
 比例,其中
比例,其中 ,α是控制异质性的浓度参数。异质性水平随着浓度参数α变小而增加,反之亦然。请注意,在LDA策略中,类分布和本地数据集大小在本地客户端之间是不同的。
,α是控制异质性的浓度参数。异质性水平随着浓度参数α变小而增加,反之亦然。请注意,在LDA策略中,类分布和本地数据集大小在本地客户端之间是不同的。
4.2 Performance on Data Heterogeneity

正确率旁的括号是遗忘F,值越小代表全局模型更加记住以往的知识。We believe that the gain from the prior works is actually from the forgetting prevention in their own ways. (作者认为,前人的研究成果实际上是以他们自己的方式预防遗忘。)
5 Knowledge preservation of FedNTD
作者感兴趣的是,尽管FedNTD在本地分布上的性能变化不大,但它在本地外分布上的知识保存如何对联邦学习产生帮助。
作者分析了局部训练后FedNTD中的局部模型,并提出了两个主要原因:

权重对齐:每一个权重的语义保存了多少?
权重散度:局部权重偏移了全局模型多少?
5.1 Weight Alignment
在最近的研究中,已经提出在局部模型之间存在权重参数中编码的语义信息的失配,即对于相同的坐标(即,相同位置)。由于当前的聚合方案对相同坐标的权重进行平均,因此跨局部模型匹配语义对齐在全局收敛中起着重要作用。
为了分析每个参数的语义对齐,我们通过平均具有最大激活输出的类别来确定单个神经元的类别偏好。(意思就是这个神经元对每个类的激活输出取平均,哪个类的平均值大,那么代表这个神经元偏好这个类)然后,我们测量两个不同模型之间的一个层的对齐,类别偏好相同的神经元的比例。

5.2 Weight Divergence
FedNTD的知识保存使得全局模型能够更均匀地预测每个类别。考虑一个拟合在特定原始分布上的模型,现在它在一个新分布上训练。然后,原始模型和拟合模型之间的权重距离随着原始分布和新分布之间的距离增大而增大。如果我们假设局部分布是任意生成的,那么全局模型的潜在分布的最稳健选择是均匀分布。我们将我们的论点正式改写如下:
尽管全局模型的基本分布情况未知, 归一化类精度向量是一种方便的近似:![]() 。其中A是全局模型的测试正确率。ac是类c上的类维正确率。
。其中A是全局模型的测试正确率。ac是类c上的类维正确率。
设置一个权重散度![]() ,和分布散度
,和分布散度![]() ,其中pk就是局部 内分布
,其中pk就是局部 内分布















 1328
1328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









