






1.Introduction
本文思想是通过federated augmentation(FAug) 增强数据使得每一个客户端的数据达到独立同分布,再通过federated distillation(FD)来减少通信成本。
由非独立同分布数据造成降低的精确度可以通过交换数据样本来部分恢复 。联邦增强(FAUG),一种使用生成对抗网络(GAN)的数据增强方案,该网络是在隐私泄漏和通信开销之间的权衡下集体训练的。 训练后的GAN授权每个设备本地再现所有设备的数据样本,从而使训练数据集成为IID。
2 Federated distillation
为了减少通信成本,每个客户端存储标签的平均logit。
集合![]() 表示所有设备的整个训练数据集,B表示每个设备的批处理。 函数
表示所有设备的整个训练数据集,B表示每个设备的批处理。 函数![]() 是由softmax函数归一化的logit向量,其中w和a是模型的权重和输入。 函数
是由softmax函数归一化的logit向量,其中w和a是模型的权重和输入。 函数![]() 是p和q之间的交叉熵,它既用于损失函数,也用于蒸馏正则化器。 η是一个恒定的学习速率,γ是蒸馏正则化器的一个权重参数。 在第i个设备上,
是p和q之间的交叉熵,它既用于损失函数,也用于蒸馏正则化器。 η是一个恒定的学习速率,γ是蒸馏正则化器的一个权重参数。 在第i个设备上,![]() 是第k次迭代时的局部平均logit向量,当训练样本属于第i个基本真值标签时,
是第k次迭代时的局部平均logit向量,当训练样本属于第i个基本真值标签时,![]() ,是等于
,是等于![]() 的全局平均logit向量,设备数为m,而
的全局平均logit向量,设备数为m,而![]() 是基本真值标签为的样本数。
是基本真值标签为的样本数。 

即再局部训练阶段对于每个设备,从数据集中S去取一个batch和相应的真值标签。对于batch中的样本,参数更新则不仅使用硬标签更新,同时使用全局平均logit更新。并且对这个样本统计训练过过多少次,并且对这个样本的logit累计。局部模型训练完后对每个标签取平均,并且发送给服务器。
全局聚合阶段,对所有客户端的每一个标签的logit局部平均累计求和。即收集到每一个标签的logit是所有局部模型的平均之和。再对于发回给每个局部模型所有标签的全局模型平均,减去这个局部模型对于这个标签的贡献,再取平均,再发回。
3 Federated Augmentation
FAug中的每个设备识别数据样本中缺少的标签,称为目标标签,并通过无线链路将这些目标标签的少量种子数据样本上载到服务器。 服务器对上传的种子数据样本进行过采样,例如,通过谷歌的视觉数据图像搜索,以训练条件GAN。 最后,下载经过训练的GAN生成器使每个设备能够补充目标标签,直到到达一个IID训练数据集。
FAug 的运行需要保证用户生成数据的隐私性。事实上,每个设备的数据生成偏差,即目标标签,可能很容易泄露其隐私敏感信息,例如,患者的体检项目会泄露诊断结果。为了使这些目标标签对服务器保密,设备还从目标标签以外的标签上传冗余数据样本。从每个设备到服务器的隐私泄漏,表示为设备-服务器隐私泄漏(device-server privacy leakage PL),从而以额外的上行链路通信开销为代价减少。设备-服务器 PL 测量为
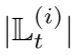 代表目标标签的数目。
代表目标标签的数目。 代表冗余标签数目。
代表冗余标签数目。
设备的目标标签信息也可能泄露给其他设备,因为它们共享一个集体训练的生成器。 事实上,设备可以通过识别其下载生成器的可生成标签来推断他人的目标标签。 这种隐私泄漏通过设备间PL来量化。 假设GAN对所有目标和冗余标记都是完全训练的,第i个器件的器件间PL定义为 . 注意,当设备间pl的分母等于最大值,即整个标签的数目时,设备间pl最小化。 只要设备的数量足够大,无论目标和冗余标签的大小,都可以实现最小泄漏。
. 注意,当设备间pl的分母等于最大值,即整个标签的数目时,设备间pl最小化。 只要设备的数量足够大,无论目标和冗余标签的大小,都可以实现最小泄漏。
实验:每个设备每 250 次局部迭代 (n=250) 交换所需信息,表示为一次全局迭代,最多 16 次全局迭代。
在FAUG中,服务器有一个由4层生成器神经网络和4层辨别器神经网络组成的条件GAN。














 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









