







1 项目背景
#c 概述 项目的目的
图像分类是整个计算机视觉领域中最基础的任务,也是最重要的任务之⼀,最适合拿来进⾏学习实践。为了让新⼿们能够⼀次性体验⼀个⼯业级别的图像分类任务的完整流程,本次我们选择带领⼤家完成⼀个对图片中⼈脸进⾏表情识别的任务。本任务只对嘴唇部分的表情进⾏识别,所以我们的目标就是获取人脸嘴唇区域的图像,然后进行分类。
#c 前景 项目的应用前景
⼈脸表情识别(facial expression recognition, FER)作为⼈脸识别技术中的⼀个重要组成部分,近年来在⼈机交互、安全、机器⼈制造、⾃动化、医疗、通信和驾驶领域得到了⼴泛的关注,成为学术界和⼯业界的研究热点,是⼈脸属性分析的重点。
#c 总结 项目总结
训练步骤
通过该项目,初步对「深度学习」有了实践经验。整个学习的流程有四个步骤,分别是
-
「数据收集」,收集需要的数据,可以通过爬虫的方式去收集自己想要的数据,相关资料【杂谈】深度学习必备,各路免费爬虫一举拿下。
-
「数据处理」把收集到的数据处理成需要的格式,筛选掉不合格的数据和相关的脏数据。或者进一步提取数据。
-
「模型训练」搭建寻训练的模型,准备模型的数据接口,然后进行模型的训练。
-
「模型测试」对训练好额模型进行测试。
相关知识
在实践过程当中,学习一些相关的概念知识,整理到了第五点中。有「级联选择器」,「字典推导式」,「损失函数」,「优化器」,「学习率调度器」。
需继续学习的技术
需要继续深入学习「深度学习理论」,「Numpy」,「matplotlib」,「OpenCV」,「Pytorch」。
2 数据获取
#e 爬取数据的方法
使用爬虫工具获取图片的数据
本项目使用的爬虫项目是:https://github.com/sczhengyabin/Image-Downloader ,可以按要求爬取百度、Bing、Google 上的图片。
#c 问题 问题与解决方法
- Ubuntu中出现xcd的问题?
尝试了网上的各种方法,最后改用windows上进行
3 数据处理
#c 解释 数据处理的重要性
爬取得到的数据是⽐较脏的,需要进⾏整理,主要包括统⼀图⽚后缀和重命名。统⼀后缀格式可以减少以后写数据 API 时的压⼒,也可以测试图⽚是不是可以正常的读取,及时防⽌未知问题的出现,这很重要。
3.1 图片格式统一
#e 数据处理的代码
'''
该py文件用一个函数listfiles于将指定目录下的所有图片文件转换为jpg格式的图片文件并删除原图片文件。
参数:rootDir,表示要转换的图片文件所在的目录
返回值:无
总结:
1.使用os.walk()函数遍历指定目录下的所有文件和子目录。
2.使用cv2.imread()函数读取图片文件。
3.使用cv2.imwrite()函数保存图片文件。
4.使用os.remove()函数删除原图片文件。
'''
import os
import cv2
def listfiles(rootDir):
list_dirs = os.walk(rootDir)
'''
用于生成文件夹中的文件名通过在目录树中游走。
这个函数返回一个「三元组」(dirpath, dirnames, filenames)。
dirpath是一个字符串,表示当前正在遍历的目录的路径。
dirnames是一个列表,包含了dirpath下所有子目录的名字。
filenames是一个列表,包含了非目录文件的名字。
这行代码中的list_dirs将会是一个「迭代器」,每次迭代返回上述的三元组,
表示rootDir目录及其所有子目录中的文件和目录信息。
'''
for root, dirs, files in list_dirs:
for d in dirs:
print(os.path.join(root, d))#打印目录
for f in files:
fileid = f.split('.')[0]#获取文件名
filepath = os.path.join(root, f)#获取文件路径
print(filepath)
try:#异常处理,确保程序不会因为读取图片出错而中断
src = cv2.imread(filepath,1)#读取图片
'''
cv2.imread()函数读取图片,接收两个参数
第一个参数是图片路径,第二个参数是读取图片的方式(1表示读取彩色图片,参数0表示读取灰度图片)
返回值是一个numpy数组,表示图片的像素矩阵。
'''
print("src=",filepath,src.shape)#src.shape是图片的尺寸
os.remove(filepath)#删除原图片
cv2.imwrite(os.path.join(root,fileid+".jpg"),src)#保存图片
'''
cv2.imwrite()函数保存图片,接收两个参数
第一个参数是保存图片的路径,第二个参数是图片的像素矩阵
返回值是一个布尔值,表示是否保存成功
'''
except:
os.remove(filepath)
continue
path = "./opencv_facetest"
listfiles(path)
3.2 数据清洗
#c 解释 为何清洗数据
利⽤搜索引擎爬取得到的图⽚肯定有「不符合要求」的,数据清洗主要是「删除不合适」的图⽚,即⾮⼈脸的照⽚。如果利⽤「⼈脸检测算法」仍然⽆法清除⼲净样本,则需要⼿动筛选。当然如果你使⽤多个关键词或者使⽤不同的搜索引擎同样的关键词,或者从视频中提取图⽚,那么爬取回来的图⽚很可能有重复或者⾮常的相似,这样的数据集需要「去重」。
#e 人脸检测算法
'''
使用OpenCV检测图片中的人脸,并显示出来,删除没有人脸的图片
使用到的知识:
1. OpenCV 的人脸检测接口
2. os.listdir() 方法,用于返回指定的文件夹包含的文件或文件夹的名字的列表
3. os.remove() 方法,用于删除文件
4. plt.imshow() 方法,用于显示图片
5. plt.show() 方法,用于显示图片
6. CascadeClassifier.detectMultiScale() 方法,用于检测图片中的人脸
'''
import cv2
import os
import matplotlib.pyplot as plt
# 人脸检测的接口,这个是 OpenCV 中自带的
cascade_path = './Emotion_Recognition_File/face_detect_model/haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)
'''
xml文件是OpenCV中的一个训练好的分类器,也就是一个训练好的模型,包含了所有必要的参数和特征,用于快速准确地检测图像中的面部。
'''
# img_path = "./Emotion_Recognition_File/face_det_img/" # 测试图片路径
img_path = "./opencv_facetest" #
def DelNoneFaceImage(img_path):
"""
删除没有人脸的图片
"""
images = os.listdir(img_path)
'''
os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
这个列表以字母顺序。 它不包括 '.' 和'..' 即使它在文件夹中。
参数:path,表示要列出的目录
返回值:返回指定路径下的文件和文件夹列表
'''
for image in images:
im = cv2.imread(os.path.join(img_path, image), 1) # 读取图片
rects = cascade.detectMultiScale(im, 1.3, 5) # 人脸检测函数
'''
cascade.detectMultiScale()函数是OpenCV中的一个人脸检测函数,用于检测图片中的人脸。
它接收三个参数:
im:待检测的图像,通常是灰度图像,因为Haar特征基于灰度值计算。
1.3:scaleFactor参数,指定在图像尺寸减小时,搜索窗口的缩放比例。
值越大,检测速度越快,但可能错过一些小的或者是距离较远的面部。
5:minNeighbors参数,指定每个候选矩形应该保留的邻近矩形的最小数量。
这个参数控制着检测的质量,较高的值会减少检测到的假阳性,但也可能错过一些真正的对象。
返回值是一个矩形列表,每个矩形表示一个检测到的人脸。
'''
print("检测到人脸的数量", len(rects))
if len(rects) == 0: # len(rects) 是检测人脸的数量,如果没有检测到人脸的话,会显示出图片,适合本地调试使用,在服务器上可能不会显示
os.remove(os.path.join(img_path, image)) #
print("删除图片:", image)
print()
print("删除完成")
return
def DetcFaceImage(img_path):
"""
检测图片中的人脸,并显示出来
"""
images = os.listdir(img_path)
for image in images:
im = cv2.imread(os.path.join(img_path, image), 1) # 读取图片
rects = cascade.detectMultiScale(im, 1.3, 5) # 人脸检测函数
print("检测到人脸的数量", len(rects))
if len(rects) == 0: # len(rects) 是检测人脸的数量,如果没有检测到人脸的话,会显示出图片,适合本地调试使用,在服务器上可能不会显示
pass
plt.imshow(im[:, :, ::-1]) # 显示
'''
plt.imshow()函数用于显示图片,接收一个参数,即要显示的图片。
由于OpenCV读取的图片是BGR格式,而matplotlib显示的图片是RGB格式,所以需要将BGR格式转换为RGB格式。
[:, :, ::-1]表示将图片的第三个维度(颜色通道)反转,即将BGR转换为RGB。
'''
plt.show()
# DelNoneFaceImage(img_path)
DetcFaceImage(img_path)
3.3 提取嘴唇区域
本任务只对嘴唇部分的表情进⾏识别,所以我们的目标就是获取人脸嘴唇区域的图像,然后进行分类。我们利⽤ Opencv+Dlib 算法提取嘴唇区域, Dlib 算法会得到⾯部的 68 个关键点,我们从中得到嘴唇区域,并适当扩⼤。
人脸 68 点位置图如下:
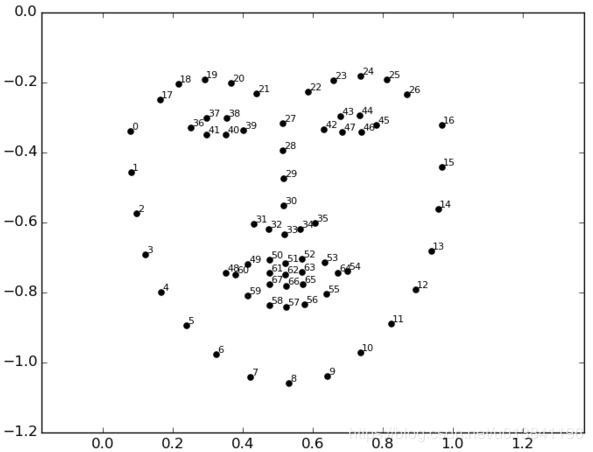
#c 问题 dlib安装问题
PS E:\Projects\Emotion_Recognition> pip install dlib
× Building wheel for dlib (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [13 lines of output]
running bdist_wheel
running build
running build_ext
Traceback (most recent call last):
ModuleNotFoundError: No module named 'cmake'
ERROR: CMake must be installed to build dlib
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for dlib
Failed to build dlib
ERROR: Could not build wheels for dlib, which is required to install pyproject.toml-based projects
解决方法,安装cmakepip install cmake ,然后指定dlib的版本pip install dlib==19.24.2
#e 提取的代码
下面的代码可以对图片进行人脸检测,检测到人脸后,会将嘴巴区域分割出来,形成数据集。
'''
该py文件用于获取人脸关键点,并根据关键点获取嘴唇区域。
思路:
1.使用Dlib库加载预训练的人脸关键点检测模型。
2.使用OpenCV加载人脸检测器。
3.遍历指定目录下的所有图片文件。
4.使用OpenCV读取图片。
5.使用Dlib检测人脸关键点。
6.根据关键点获取嘴唇区域。
7.保存嘴唇区域。
'''
import cv2
import dlib
import numpy as np
import os
import matplotlib.pyplot as plt
# 配置 Dlib 关键点检测路径
# 文件可以从 http://dlib.net/files/ 下载
PREDICTOR_PATH = "./Emotion_Recognition_File/face_detect_model/shape_predictor_68_face_landmarks.dat"
'''
预训练的人脸关键点检测模型,用于检测人脸的关键点。
'''
predictor = dlib.shape_predictor(PREDICTOR_PATH)
'''
dlib.shape_predictor()函数用于加载一个预训练的人脸关键点检测模型。
这个函数接收一个参数,表示模型文件的路径。
'''
# 配置人脸检测器路径
cascade_path = './Emotion_Recognition_File/face_detect_model/haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)
def get_landmarks(im):
'''
函数:获取人脸关键点
参数:im,表示输入的图片
返回值:返回一个矩阵,表示人脸关键点的坐标
'''
rects = cascade.detectMultiScale(im, 1.3, 5) # 人脸检测
x, y, w, h = rects[0] # 获取人脸的四个属性值,左上角坐标 x,y 、高宽 w、h
#array([[209, 156, 289, 289]])
#print(x, y, w, h)
rect = dlib.rectangle(int(x), int(y), int(x + w), int(y + h))
'''
目的:将人脸检测的结果转换为dlib的矩形对象
dlib.rectangle()函数用于创建一个矩形对象,表示一个矩形区域。
这个函数接收四个参数,分别是矩形的左上角和右下角的坐标。
'''
return np.matrix([[p.x, p.y] for p in predictor(im, rect).parts()])
'''
np.matrix()函数用于将列表转换为矩阵。
predictor(im, rect):这个函数调用使用predictor对象(之前通过dlib.shape_predictor加载的面部关键点检测器)
在图像im中的指定区域rect(一个矩形,通常是通过面部检测得到的)上检测面部关键点。
predictor函数返回一个包含检测到的面部关键点的对象。
.parts():这个方法被调用来获取检测到的所有面部关键点。它返回一个包含多个点的对象,每个点代表一个关键点的位置。
[p.x, p.y for p in ...]:这是一个列表推导式,用于遍历parts()返回的所有关键点p,
并为每个关键点创建一个包含其x和y坐标的列表。
np.matrix([...]):这将上一步得到的坐标列表转换成一个NumPy矩阵。NumPy矩阵是一个二维数组,
这里每一行代表一个关键点的x和y坐标
'''
def annotate_landmarks(im, landmarks):
'''
目的:在图片上标记关键点
参数:im,表示输入的图片
landmarks,表示关键点坐标
'''
im = im.copy()# 复制图片
for idx, point in enumerate(landmarks):
#enumerate()函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标
pos = (point[0, 0], point[0, 1])
cv2.putText(im,
str(idx),# 文本内容
pos,# 位置
fontFace=cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,# 字体
fontScale=0.4,# 字体大小
color=(0, 0, 255))# 颜色
cv2.circle(im, pos, 5, color=(0, 255, 255))# 画圆
return im
def getlipfromimage(im, landmarks):
'''
功能:获取嘴唇区域
参数:im,表示输入的图片
landmarks,表示关键点坐标
返回值:返回一个矩形区域,表示嘴唇区域
'''
xmin = 10000
xmax = 0
ymin = 10000
ymax = 0
# 根据最外围的关键点获取包围嘴唇的最小矩形框
# 68 个关键点是从
# 左耳朵0 -下巴-右耳朵16-左眉毛(17-21)-右眉毛(22-26)-左眼睛(36-41)
# 右眼睛(42-47)-鼻子从上到下(27-30)-鼻孔(31-35)
# 嘴巴外轮廓(48-59)嘴巴内轮廓(60-67)
for i in range(48, 67):
'''
for循环遍历关键点,找到嘴唇区域的最小矩形框
'''
x = landmarks[i, 0]
y = landmarks[i, 1]
if x < xmin:
xmin = x
if x > xmax:
xmax = x
if y < ymin:
ymin = y
if y > ymax:
ymax = y
print("xmin=", xmin)
print("xmax=", xmax)
print("ymin=", ymin)
print("ymax=", ymax)
roiwidth = xmax - xmin# 嘴唇区域的宽度
roiheight = ymax - ymin# 嘴唇区域的高度
roi = im[ymin:ymax, xmin:xmax, 0:3]
'''
im[ymin:ymax, xmin:xmax, 0:3]:这是一个NumPy数组切片操作,用于从原始图像中提取嘴唇区域。
它接收三个参数,分别是ymin:ymax、xmin:xmax和0:3。
ymin:ymax和xmin:xmax表示切片的范围,0:3表示提取所有的通道(RGB)。
该操作返回一个包含嘴唇区域的NumPy数组。
'''
# 将嘴唇区域扩大1.5倍
if roiwidth > roiheight:
dstlen = 1.5 * roiwidth
else:
dstlen = 1.5 * roiheight
# 计算嘴唇区域的中心点
diff_xlen = dstlen - roiwidth
diff_ylen = dstlen - roiheight
newx = xmin
newy = ymin
imagerows, imagecols, channel = im.shape
'''
im.shape是一个元组,包含三个元素,分别是图像的行数、列数和通道数。
'''
if newx >= diff_xlen / 2 and newx + roiwidth + diff_xlen / 2 < imagecols:
newx = newx - diff_xlen / 2
elif newx < diff_xlen / 2:
newx = 0
else:
newx = imagecols - dstlen
if newy >= diff_ylen / 2 and newy + roiheight + diff_ylen / 2 < imagerows:
newy = newy - diff_ylen / 2
elif newy < diff_ylen / 2:
newy = 0
else:
newy = imagerows - dstlen
'''
上述代码:通过智能调整ROI的位置,确保ROI始终位于图像的有效区域内,
既不会超出图像边界,也尽可能保持其原始尺寸和形状。
这在进行图像处理和分析时非常重要,特别是在需要精确操作图像特定区域的应用中
'''
roi = im[int(newy):int(newy + dstlen), int(newx):int(newx + dstlen), 0:3]
'''
使用了Python的切片语法来从图像中提取ROI。
int(newy):int(newy + dstlen)和int(newx):int(newx + dstlen)分别定义了ROI在y方向和x方向上的范围。
0:3指定了颜色通道的范围,对于一个标准的BGR颜色图像,这意味着选择所有三个颜色通道(蓝色、绿色、红色)
'''
return roi
def listfiles(rootDir):
list_dirs = os.walk(rootDir)
for root, dirs, files in list_dirs:
for d in dirs:
print(os.path.join(root, d))
for f in files:
fileid = f.split('.')[0]
filepath = os.path.join(root, f)
try:
im = cv2.imread(filepath, 1)
landmarks = get_landmarks(im)# 获取关键点
roi = getlipfromimage(im, landmarks)# 获取嘴唇区域
roipath = filepath.replace('.jpg', '_mouth.png')# 保存嘴唇区域
# cv2.imwrite(roipath, roi)
plt.imshow(roi[:, :, ::-1])
plt.show()
except:
# print("error")
continue
listfiles("./Emotion_Recognition_File/face_det_img/")
4 模型搭建训练与测试
4.1 数据接口准备
#c 说明 数据接口准备
直接利用文件夹作为输入,只需要把不同类的数据放到不同的文件夹中。输入一个文件夹,输出图片路径以及标签,在开始训练之前需要将数据集进行拆分,拆分成训练集(train)和验证集(val),训练集和测试集的比例为9:1,train_val_data文件结构如下所示,其中 0 代表 none、 1 代表pouting、2 代表 smile、3 代表 openmouth:
#e 准备的代码 数据接口准备
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(48),# 随机裁剪,调整为48*48像素大小,增强泛化
transforms.RandomHorizontalFlip(),# 随机水平翻转,增强泛化
transforms.ToTensor(),# 转换为张量
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])# 标准化
]),
'val': transforms.Compose([
transforms.Resize(64),# 调整为64*64像素大小
transforms.CenterCrop(48),# 中心裁剪,调整为48*48像素大小
transforms.ToTensor(),# 转换为张量
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])# 标准化
]),
}
data_dir = './Emotion_Recognition_File/train_val_data/' # 数据集所在的位置
#创建图像数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
#创建数据加载器
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],# 数据集
batch_size=64,# 每个批次加载64个样本
shuffle=True if x=="train" else False,# 训练集打乱,验证集不打乱
num_workers=8) for x in ['train', 'val']}# 使用8个子进程加载数据
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}# 数据集大小
4.2 模型定义
#c 说明 模型定义
创建数据接⼝后,开始定义⼀个⽹络 simpleconv3。一个简单的 3 层卷积。在 torch.nn 下,有各种网络层,这里就用到了 nn.Conv2d,nn.BatchNorm2d 和 nn.Linear,分别是卷积层,BN 层和全连接层。我们以一个卷积层为例:
conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=3, stride=2)
bn1 = nn.BatchNorm2d(num_features=12)
- in_channels:输入通道数
- out_channels:输出通道数
- kernel_size:卷积核的大小
- stride:卷积核的移动步长
#e 模型定义的代码 模型定义
# 定义一个简单的卷积神经网络
class simpleconv3(nn.Module):
def __init__(self):
super(simpleconv3,self).__init__()#调用父类的构造函数
self.conv1 = nn.Conv2d(3, 12, 3, 2)#定义第一个卷积层
self.bn1 = nn.BatchNorm2d(12)#定义第一个批标准化层
self.conv2 = nn.Conv2d(12, 24, 3, 2)#定义第二个卷积层
self.bn2 = nn.BatchNorm2d(24)#定义第二个批标准化层
self.conv3 = nn.Conv2d(24, 48, 3, 2)#定义第三个卷积层
self.bn3 = nn.BatchNorm2d(48)#定义第三个批标准化层
self.fc1 = nn.Linear(48 * 5 * 5 , 1200)#定义第一个全连接层
self.fc2 = nn.Linear(1200 , 128)#定义第二个全连接层
self.fc3 = nn.Linear(128 , 4)#定义第三个全连接层
def forward(self , x):#前向传播
x = F.relu(self.bn1(self.conv1(x)))#卷积层->批标准化层->激活函数
#print "bn1 shape",x.shape
x = F.relu(self.bn2(self.conv2(x)))#卷积层->批标准化层->激活函数
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1 , 48 * 5 * 5) #reshape操作
x = F.relu(self.fc1(x))#全连接层->激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x)#全连接层
return x
4.3 模型训练
#c 说明 测试的意义
- 验证模型准确性:通过测试可以验证模型的预测结果是否符合预期,确保模型的准确性和可靠性。
- 性能评估:测试可以评估模型在不同条件下的性能,包括处理速度、资源消耗等,以确保模型在实际应用中的效率。
- 发现问题:通过对模型进行系统的测试,可以发现模型设计或实现过程中的问题,如过拟合、欠拟合等。
- 模型优化:测试结果可以为模型的进一步优化提供依据,帮助开发者调整模型参数,改进模型结构。
#e 训练代码
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
import os
from tensorboardX import SummaryWriter
import torch.nn.functional as F
import numpy as np
import warnings
# 定义一个简单的卷积神经网络
class simpleconv3(nn.Module):
def __init__(self):
super(simpleconv3,self).__init__()#调用父类的构造函数
self.conv1 = nn.Conv2d(3, 12, 3, 2)#定义第一个卷积层
self.bn1 = nn.BatchNorm2d(12)#定义第一个批标准化层
self.conv2 = nn.Conv2d(12, 24, 3, 2)#定义第二个卷积层
self.bn2 = nn.BatchNorm2d(24)#定义第二个批标准化层
self.conv3 = nn.Conv2d(24, 48, 3, 2)#定义第三个卷积层
self.bn3 = nn.BatchNorm2d(48)#定义第三个批标准化层
self.fc1 = nn.Linear(48 * 5 * 5 , 1200)#定义第一个全连接层
self.fc2 = nn.Linear(1200 , 128)#定义第二个全连接层
self.fc3 = nn.Linear(128 , 4)#定义第三个全连接层
def forward(self , x):#前向传播
x = F.relu(self.bn1(self.conv1(x)))#卷积层->批标准化层->激活函数
#print "bn1 shape",x.shape
x = F.relu(self.bn2(self.conv2(x)))#卷积层->批标准化层->激活函数
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1 , 48 * 5 * 5) #reshape操作
x = F.relu(self.fc1(x))#全连接层->激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x)#全连接层
return x
warnings.filterwarnings('ignore')#忽略警告
writer = SummaryWriter()#创建一个SummaryWriter对象,用于记录训练过程中的损失和准确率
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
'''
功能:训练神经网络
参数: model,表示要训练的神经网络
criterion,表示损失函数
optimizer,表示优化器
scheduler,表示学习率调度器
num_epochs,表示训练的轮次
返回值:model,表示训练好的神经网络
'''
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))# 打印训练次数
for phase in ['train', 'val']:#训练和验证
if phase == 'train':#训练阶段
scheduler.step()#学习率调度器更新学习率
model.train(True) # Set model to training mode
else:
model.train(False) # Set model to evaluate mode
running_loss = 0.0#累计当前阶段的总损失,有助于计算平均损失
running_corrects = 0.0#累计当前阶段的总准确率,有助于计算平均准确率
for data in dataloders[phase]:#遍历数据加载器
inputs, labels = data#获取输入数据和标签
if use_gpu:#使用GPU
inputs = Variable(inputs.cuda())#将输入数据转换为Variable类型
labels = Variable(labels.cuda())#将标签转换为Variable类型
else:
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()#进行一次前向传播之前,清零之前的梯度,以防止梯度累积
outputs = model(inputs)#将输入数据喂给模型,进行一次前向传播,得到模型的输出。
_, preds = torch.max(outputs.data, 1)#从模型输出中找到每个样本预测概率最高的类别作为预测结果。
loss = criterion(outputs, labels)#计算模型输出和标签之间的损失
if phase == 'train':#训练阶段
loss.backward()#进行一次反向传播,计算梯度
optimizer.step()#更新模型参数
running_loss += loss.data.item()#累计当前阶段的总损失
running_corrects += torch.sum(preds == labels).item()#累计当前阶段的总准确率
epoch_loss = running_loss / dataset_sizes[phase]#计算平均损失
epoch_acc = running_corrects / dataset_sizes[phase]#计算平均准确率
if phase == 'train':
writer.add_scalar('data/trainloss', epoch_loss, epoch)#记录训练阶段的平均损失
writer.add_scalar('data/trainacc', epoch_acc, epoch)#记录训练阶段的平均准确率
else:
writer.add_scalar('data/valloss', epoch_loss, epoch)#记录验证阶段的平均损失
writer.add_scalar('data/valacc', epoch_acc, epoch)#记录验证阶段的平均准确率
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
writer.export_scalars_to_json("./all_scalars.json")#将记录的数据保存为json文件
writer.close()#关闭SummaryWriter对象
return model
if __name__ == '__main__':
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(48),# 随机裁剪,调整为48*48像素大小,增强泛化
transforms.RandomHorizontalFlip(),# 随机水平翻转,增强泛化
transforms.ToTensor(),# 转换为张量
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])# 标准化
]),
'val': transforms.Compose([
transforms.Resize(64),# 调整为64*64像素大小
transforms.CenterCrop(48),# 中心裁剪,调整为48*48像素大小
transforms.ToTensor(),# 转换为张量
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])# 标准化
]),
}
data_dir = './Emotion_Recognition_File/train_val_data/' # 数据集所在的位置
#创建图像数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
#创建数据加载器
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],# 数据集
batch_size=64,# 每个批次加载64个样本
shuffle=True if x=="train" else False,# 训练集打乱,验证集不打乱
num_workers=8) for x in ['train', 'val']}# 使用8个子进程加载数据
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}# 数据集大小
use_gpu = torch.cuda.is_available()# 是否使用GPU
print("是否使用 GPU", use_gpu)
modelclc = simpleconv3()# 创建模型
print(modelclc)
if use_gpu:
modelclc = modelclc.cuda()# 使用GPU
#配置神经网络训练过程中的损失函数、优化器和学习率调度器的。
criterion = nn.CrossEntropyLoss()#选择交叉熵损失函数
optimizer_ft = optim.SGD(modelclc.parameters(), lr=0.1, momentum=0.9)
'''
随机梯度下降(SGD)优化器,用于更新模型的权重。
modelclc.parameters() 提供了模型中所有可训练的参数。
lr=0.1 设置了学习率为 0.1,这是在训练过程中每次参数更新的步长。
momentum=0.9 设置了动量为 0.9,这有助于加速优化器在相关方向上的速度,并减少震荡。
'''
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1)
'''
这行代码定义了一个学习率调度器,它会在每过 step_size(这里是100个)训练轮次后,
将学习率乘以 gamma(这里是0.1)。这意味着每100个训练轮次,学习率会减少到原来的10%。
这种方法有助于模型在训练早期快速收敛,并在训练后期通过减小学习率来细化模型参数,以避免过拟合
'''
modelclc = train_model(model=modelclc,# 模型
criterion=criterion,# 损失函数
optimizer=optimizer_ft,# 优化器
scheduler=exp_lr_scheduler,# 学习率调度器
num_epochs=10) # 这里可以调节训练的轮次
#保存模型
if not os.path.exists("models"):
os.mkdir('models')
torch.save(modelclc.state_dict(),'models/model.ckpt')# 保存模型参数
4.4 模型测试
#e 测试代码
import sys
import numpy as np
import cv2
import os
import dlib
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
from PIL import Image
import torch.nn.functional as F
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')#忽略警告
class simpleconv3(nn.Module):#定义一个简单的三层卷积神经网络
def __init__(self):
super(simpleconv3,self).__init__()#复制并使用simpleconv3的父类的初始化方法,即先运行nn.Module的初始化函数
self.conv1 = nn.Conv2d(3, 12, 3, 2)#定义conv1函数的是图像卷积层:输入是3个feature,输出是6个feature,kernel是3*3,步长为2
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(12, 24, 3, 2)
self.bn2 = nn.BatchNorm2d(24)
self.conv3 = nn.Conv2d(24, 48, 3, 2)
self.bn3 = nn.BatchNorm2d(48)
self.fc1 = nn.Linear(48 * 5 * 5 , 1200)
self.fc2 = nn.Linear(1200 , 128)
self.fc3 = nn.Linear(128 , 4)
def forward(self , x):
x = F.relu(self.bn1(self.conv1(x)))
#print "bn1 shape",x.shape
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1 , 48 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
PREDICTOR_PATH = "./Emotion_Recognition_File/face_detect_model/shape_predictor_68_face_landmarks.dat"
predictor = dlib.shape_predictor(PREDICTOR_PATH)#加载人脸关键点检测模型
cascade_path = './Emotion_Recognition_File/face_detect_model/haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)#加载人脸检测器
if not os.path.exists("results"):
os.mkdir("results")
def standardization(data):
'''
功能:标准化数据
参数:data:数据
返回:标准化后的数据
'''
mu = np.mean(data, axis=0)#计算每一列的均值,axis=0表示列,axis=1表示行
sigma = np.std(data, axis=0)#计算每一列的标准差,axis表示方向
return (data - mu) / sigma
'''
数据按列减去其平均值后,再除以其标准差。
这一步是标准化的核心,目的是让处理后的数据每一列的平均值为0,标准差为1。
这样处理后的数据符合标准正态分布,有利于后续的数据处理和分析。
'''
def get_landmarks(im):
'''
功能:获取人脸关键点
参数:im:图像
返回:人脸关键点
'''
rects = cascade.detectMultiScale(im, 1.3, 5)#检测人脸
x, y, w, h = rects[0]#获取人脸区域
rect = dlib.rectangle(int(x), int(y), int(x + w), int(y + h))#转换为dlib格式的人脸区域
return np.matrix([[p.x, p.y] for p in predictor(im, rect).parts()])#获取人脸关键点
def annotate_landmarks(im, landmarks):
'''
功能:标注人脸关键点
参数:im:图像
landmarks:人脸关键点
返回:标注后的图像
'''
im = im.copy()
for idx, point in enumerate(landmarks):
pos = (point[0, 0], point[0, 1])
cv2.putText(im,
str(idx),
pos,
fontFace=cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,
fontScale=0.4,
color=(0, 0, 255))
cv2.circle(im, pos, 3, color=(0, 255, 255))
return im
testsize = 48 # 测试图大小
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
net = simpleconv3()#创建模型实例
net.eval()#评估模式
modelpath = "./models/model.ckpt" # 模型路径
net.load_state_dict(#加载模型保存的模型权重
torch.load(modelpath, map_location=lambda storage, loc: storage))
'''
map_location参数用于指定加载模型的设备位置。
这里使用了一个lambda函数lambda storage, loc: storage,
这意味着无论模型权重文件是在哪个设备上保存的(例如GPU或CPU),
都将其加载到当前设备上。这对于跨设备加载模型非常有用,特别是当原始训练环境与当前环境不同时。
lambda语法:lambda 参数:表达式
'''
# 一次测试一个文件
img_path = "./Emotion_Recognition_File/test_img/"
imagepaths = os.listdir(img_path) # 图像文件夹
for imagepath in imagepaths:
im = cv2.imread(os.path.join(img_path, imagepath), 1)
try:
rects = cascade.detectMultiScale(im, 1.3, 5)#检测人脸
x, y, w, h = rects[0]
rect = dlib.rectangle(int(x), int(y), int(x + w), int(y + h))
landmarks = np.matrix([[p.x, p.y]
for p in predictor(im, rect).parts()])
except:
# print("没有检测到人脸")
continue # 没有检测到人脸
xmin = 10000
xmax = 0
ymin = 10000
ymax = 0
for i in range(48, 67):
x = landmarks[i, 0]
y = landmarks[i, 1]
if x < xmin:
xmin = x
if x > xmax:
xmax = x
if y < ymin:
ymin = y
if y > ymax:
ymax = y
roiwidth = xmax - xmin
roiheight = ymax - ymin
roi = im[ymin:ymax, xmin:xmax, 0:3]
if roiwidth > roiheight:
dstlen = 1.5 * roiwidth
else:
dstlen = 1.5 * roiheight
diff_xlen = dstlen - roiwidth
diff_ylen = dstlen - roiheight
newx = xmin
newy = ymin
imagerows, imagecols, channel = im.shape
if newx >= diff_xlen / 2 and newx + roiwidth + diff_xlen / 2 < imagecols:
newx = newx - diff_xlen / 2
elif newx < diff_xlen / 2:
newx = 0
else:
newx = imagecols - dstlen
if newy >= diff_ylen / 2 and newy + roiheight + diff_ylen / 2 < imagerows:
newy = newy - diff_ylen / 2
elif newy < diff_ylen / 2:
newy = 0
else:
newy = imagecols - dstlen
roi = im[int(newy):int(newy + dstlen), int(newx):int(newx + dstlen), 0:3]#裁剪图像
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)#转换颜色空间将BGR转为RGB
roiresized = cv2.resize(roi,#调整图像大小
(testsize, testsize)).astype(np.float32) / 255.0
imgblob = data_transforms(roiresized).unsqueeze(0)#转换数据格式
imgblob.requires_grad = False#不需要梯度,因为是验证阶段而不是训练阶段
imgblob = Variable(imgblob)#转换数据格式
torch.no_grad()#通过上下文管理器禁用梯度计算
predict = F.softmax(net(imgblob))#net(imgblob)是模型的输出,F.softmax()是softmax函数,用于多分类问题
print(predict)
index = np.argmax(predict.detach().numpy())#获取预测结果,np.argmax()返回概率最大的类别
im_show = cv2.imread(os.path.join(img_path, imagepath), 1)
im_h, im_w, im_c = im_show.shape#获取图像的高、宽、通道数
pos_x = int(newx + dstlen)
pos_y = int(newy + dstlen)
font = cv2.FONT_HERSHEY_SIMPLEX#设置字体样式
cv2.rectangle(im_show, (int(newx), int(newy)),#画矩形框
(int(newx + dstlen), int(newy + dstlen)), (0, 255, 255), 2)
if index == 0:
cv2.putText(im_show, 'none', (pos_x, pos_y), font, 1.5, (0, 0, 255), 2)
if index == 1:
cv2.putText(im_show, 'pout', (pos_x, pos_y), font, 1.5, (0, 0, 255), 2)
if index == 2:
cv2.putText(im_show, 'smile', (pos_x, pos_y), font, 1.5, (0, 0, 255), 2)
if index == 3:
cv2.putText(im_show, 'open', (pos_x, pos_y), font, 1.5, (0, 0, 255), 2)
# cv2.namedWindow('result', 0)
# cv2.imshow('result', im_show)
cv2.imwrite(os.path.join('results', imagepath), im_show)
# print(os.path.join('results', imagepath))
plt.imshow(im_show[:, :, ::-1]) # 这里需要交换通道,因为 matplotlib 保存图片的通道顺序是 RGB,而在 OpenCV 中是 BGR
plt.show()
# cv2.waitKey(0)
# cv2.destroyAllWindows()
5 相关概念
#d 级联选择器
级联分类器(Cascade Classifier)是一种基于机器学习的对象检测技术,它能够在图像中快速识别出目标对象(如人脸、行人等)。这个概念主要用于解决对象检测问题,特别是在实时应用中,如视频监控、人脸识别等场景。
解决的问题:
- 速度与准确性的平衡:级联分类器通过一系列的简单到复杂的分类阶段(称为“级联”)来检测对象,每个阶段使用不同的特征集。这种方法可以快速排除背景区域,仅在可能包含目标对象的区域使用更复杂的特征,从而实现高效率和较高准确性的平衡。
- 实时检测:由于其高效性,级联分类器特别适合于需要实时处理的应用,如实时视频分析。
没有这个概念的影响:
- 检测速度下降:没有级联分类器,我们可能需要在整个图像上运行复杂的检测算法,这会大大增加计算量,降低检测速度,尤其是在处理高分辨率视频或实时应用时。
- 准确性和效率的挑战:缺乏有效的筛选机制可能导致算法在背景区域浪费大量计算资源,同时也可能降低检测的准确性,因为算法需要在更广泛的区域中寻找目标对象。
- 实时应用受限:在没有高效检测算法的情况下,很多需要实时反馈的应用(如动态人脸识别系统、实时监控系统)可能难以实现或者性能大打折扣。
#e 视频流中识别人脸 级联选择器
import cv2
# 加载预训练的Haar级联分类器
cascade_path = './haarcascade_frontalface_default.xml'
face_cascade = cv2.CascadeClassifier(cascade_path)#级联选择器
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
# 读取一帧图像
ret, frame = cap.read()
if not ret:
break
# 将图像转换为灰度图,因为Haar分类器需要灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 使用级联分类器检测图像中的人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 为每个检测到的人脸画一个矩形框
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 显示结果图像
cv2.imshow('Face Detection', frame)
# 按'q'退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()
#e 公园里找朋友 级联选择器
想象一下你在一个拥挤的公园里寻找你的朋友。你不能一次性仔细观察每一个人,这样做效率太低。相反,你可以采用类似级联分类器的策略:
- 远距离快速扫描:首先,你从远处开始,快速扫视人群,排除那些明显不符合你朋友特征(比如身高、衣着颜色)的人。
- 中距离筛选:接着,对于剩下可能符合的人群,你走近一些,关注更多细节,比如发型或者是特定的配饰,进一步缩小范围。
- 近距离确认:最后,对于少数几个高度匹配的目标,你可以走到很近的地方,确认是否是你的朋友。
这个过程就像是一个级联的过滤器,每一步都排除了大量不符合条件的目标,最终快速而准确地找到了你的朋友。
#d 字典推导式
字典推导式是一种简洁的构建字典的方法,它可以通过一个表达式来创建一个字典,其中包含了键值对(key-value pairs)。这个概念主要是为了解决在创建字典时需要通过循环和条件语句来添加键值对的复杂性问题。
没有字典推导式的影响:
- 代码冗长:在没有字典推导式的情况下,你可能需要使用循环和条件语句来构建字典,这会使代码变得更长、更复杂。
- 效率低下:手动通过循环添加键值对可能会比使用字典推导式慢,特别是在处理大量数据时。
- 可读性差:字典推导式提供了一种更清晰、更直观的方式来表达如何从一个序列或者其他数据结构中构建字典,没有它,代码可能会更难理解。
字典推导式对以下概念起作用:
- 简洁的代码:它提供了一种更简洁的方法来创建字典。
- 数据转换:它可以用来轻松地从一个数据结构(如列表、元组列表等)转换为字典。
- 条件过滤:在字典推导式中,可以使用if语句来过滤掉不符合条件的元素,从而只包含满足特定条件的键值对。
- 自动化处理:它可以用于自动化地处理数据集合,将其转换为字典形式,特别是在数据预处理和数据分析中非常有用。
总的来说,字典推导式是一种非常有用的工具,它可以使代码更加简洁、高效,并且提高代码的可读性。
#e 字符串转字典 字典推导式
# 字符串列表
words = ['apple', 'banana', 'cherry']
# 使用字典推导式创建一个字典,其中键是列表中的字符串,值是对应字符串的长度
word_lengths = {word: len(word) for word in words}
print(word_lengths)
# 输出{'apple': 5, 'banana': 6, 'cherry': 6}
#d 损失函数
损失函数(Loss Function)是机器学习和深度学习中的一个核心概念,用于衡量模型预测值与真实值之间的差异。其主要目的是指导模型学习,通过最小化损失函数来优化模型参数,使模型的预测更加准确。损失函数是机器学习和深度学习中不可或缺的一部分,它为模型训练提供了方向和目标,是实现模型优化和提高预测准确性的关键。
解决的问题:
- 提供反馈信号:损失函数为模型训练提供了反馈信号,指示模型当前的表现如何,以及如何调整参数以改进性能。
- 优化目标:它定义了一个明确的优化目标。在训练过程中,通过最小化损失函数,模型能够学习到数据的内在规律和模式。
- 适应不同问题:不同的问题可以通过选择合适的损失函数来更好地优化,例如分类问题常用交叉熵损失,回归问题常用均方误差损失。
没有损失函数会导致的结果:
- 无法衡量性能:没有损失函数,我们将无法量化模型预测的好坏,也就无法判断模型是否在学习或进步。
- 缺乏优化方向:模型训练需要一个明确的目标或标准来进行参数的调整和优化。没有损失函数,模型就没有明确的优化方向,无法进行有效的参数更新。
- 无法适应不同问题:不同类型的问题需要不同的优化策略。没有损失函数,就无法为不同的问题设计和选择最合适的优化目标,从而降低模型的适用性和准确性。
线性回归是一种预测连续值的算法。假设我们有一组数据点,我们想要找到一条直线,这条直线能够尽可能地接近所有的数据点。这里,损失函数的作用就是衡量这条直线与实际数据点之间的差距。
#e 均方误差(MSE) 损失函数
假设我们的直线方程为 y = wx + b,其中 w 是权重,b 是偏置。对于每个数据点 (x_i, y_i),直线给出的预测值是 ŷ_i = wx_i + b。均方误差(MSE)损失函数计算所有数据点的真实值 y_i 与预测值 ŷ_i 之间差值的平方和的平均值:
MSE = (1/n) * Σ(y_i - ŷ_i)^2
其中 n 是数据点的总数,Σ 表示求和。通过最小化这个损失函数,我们可以找到最佳的 w 和 b,使得直线尽可能地接近所有的数据点。
#e 减肥 损失函数
假设你想要减肥,你设定了一个目标:在接下来的三个月内减掉10公斤。在这个过程中,你每周都会称一次体重,记录下来,并与你的目标进行比较。
在这个例子中,你的“损失函数”可以看作是每次称重时与目标体重差距的大小。如果这个差距在减小,说明你的减肥计划正在取得进展;如果这个差距在增大或不变,说明你需要调整你的饮食或运动计划。
就像在机器学习中通过调整模型参数来最小化损失函数一样,你也可以通过调整你的饮食习惯和运动计划来“最小化”你的体重差距,更接近你的减肥目标。
#c 补充 相关概念
损失函数会影响的概念:
- 优化器(Optimizer):优化器使用损失函数的梯度来更新模型的参数,以减少损失。不同的优化器(如SGD、Adam)可能会对损失函数的下降速度和稳定性产生不同的影响。
- 正则化(Regularization):正则化项可以添加到损失函数中,以防止模型过拟合。正则化如L1、L2会影响损失函数的形式和模型的最终性能。
- 学习率(Learning Rate):学习率决定了在优化过程中参数更新的步长大小。它直接影响损失函数下降的速度和是否能够收敛到最小值。
影响损失函数的概念:
- 模型复杂度(Model Complexity):模型的复杂度决定了其拟合数据的能力。过于复杂的模型可能导致过拟合,这时即使损失函数在训练集上很低,也可能在测试集上表现不佳。
- 数据预处理(Data Preprocessing):数据的预处理方式(如标准化、归一化)会影响模型的学习过程,进而影响损失函数的表现。不同的数据分布可能需要不同的损失函数。
- 特征工程(Feature Engineering):有效的特征工程可以提高模型的性能,减少损失。选择和构造与预测任务高度相关的特征可以使损失函数更有效地指导模型学习。
#d 优化器
优化器(Optimizer)是机器学习和深度学习中用于更新和调整模型参数(如权重和偏置),以最小化损失函数的算法。优化器的目的是找到损失函数的最小值,从而提高模型的预测准确性。
创造优化器解决的问题:
- 参数更新:在模型训练过程中,需要一种方法来决定如何更新模型的参数,以便于模型能够学习到数据的特征和规律。优化器提供了这样一种方法。
- 收敛速度:不同的优化算法会影响模型训练的速度。一些优化器能够加快模型收敛的速度,使训练过程更高效。
- 避免局部最小值:在复杂的损失函数中,可能存在多个局部最小值。优化器的设计旨在帮助模型避免陷入局部最小值,寻找到全局最小值或较好的局部最小值。
没有优化器会导致的结果:
- 无法有效更新模型参数:没有优化器,我们将缺乏一种系统性的方法来调整模型参数,这将导致模型无法从训练数据中学习。
- 训练效率低下:即使可以手动调整模型参数,但这种方法效率极低,且难以找到损失函数的最小值,导致训练时间长,效果差。
- 模型性能不佳:缺乏有效的优化策略,模型可能无法达到较好的性能,特别是在处理复杂任务和大规模数据集时
#e 深度学习中优化器 优化器
在深度学习模型训练过程中,优化器负责调整模型的权重,以最小化损失函数。假设我们正在训练一个用于图像分类的卷积神经网络(CNN)。我们选择Adam优化器,因为它结合了动量(Momentum)和自适应学习率(AdaGrad)的优点,适合处理大规模数据和参数的优化问题。
import torch
import torch.nn as nn
import torch.optim as optim
model = MyCNN() # 假设MyCNN是我们定义的卷积神经网络
criterion = nn.CrossEntropyLoss() # 选择交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率设置为0.001
# 训练模型的简化代码
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad() # 清空之前的梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新权重
优化器Adam负责在每次迭代中更新模型的权重,以减少损失函数的值,从而提高模型在图像分类任务上的准确率。
#e 减肥计划 优化器
假设你正在尝试减肥,并设定了一个目标:在三个月内减重8公斤。你的“优化器”就是你制定的减肥计划,包括饮食控制和运动计划。
- 初始计划:你开始时决定每天跑步30分钟,每周五天,同时减少碳水化合物的摄入。
- 调整策略:两周后,你发现体重下降速度不如预期,于是你决定增加运动量,改为每天跑步45分钟,并且加入两天的力量训练。
- 反馈调整:每周通过称重来评估减肥效果,根据体重变化调整饮食和运动计划。
在这个过程中,你不断地根据体重变化(相当于“损失函数”)调整你的减肥计划(“优化器”),以期达到减重的目标。这个过程类似于在机器学习中使用优化器调整模型参数,以最小化损失函数。
#c 关联 相关概念
「优化器」影响的概念:
- 学习率(Learning Rate):优化器通过学习率控制参数更新的步长。学习率太高可能导致训练不稳定,太低则训练速度缓慢。
- 动量(Momentum):动量帮助优化器在正确的方向上加速,减少震荡,从而更快地收敛。
- 正则化(Regularization):虽然正则化通常定义在损失函数中,但它也影响优化器的行为,因为优化器需要考虑正则化项来更新参数,以防止过拟合。
- 学习率调度器(Learning Rate Scheduler):调度器根据预设策略调整学习率,优化器需要根据这些调整来更新参数。这有助于在训练的不同阶段采取不同的学习策略。
影响「优化器」的概念:
- 损失函数(Loss Function):优化器的目标是最小化损失函数。不同的损失函数可能会导致优化器的行为差异,因为损失函数的形状直接影响梯度的计算。
- 模型复杂度(Model Complexity):模型的复杂度决定了优化过程的难度。复杂模型可能有更多的局部最小值,这对优化器的选择和配置提出了挑战。
- 数据预处理(Data Preprocessing):数据的规模和分布会影响梯度的计算,进而影响优化器的效率和策略。例如,未经归一化的数据可能导致训练过程不稳定。
- 参数初始化(Parameter Initialization):模型参数的初始值可以影响优化器的收敛速度和是否能够达到全局最小值。不同的初始化方法可能会导致训练过程中的不同表现。
#d 学习率调度器
学习率调度器(Learning Rate Scheduler)是一种在训练过程中动态调整学习率的策略。它根据预定的规则或实时的训练指标,逐步调整学习率的大小,以提高模型训练的效率和效果。学习率调度器通过在训练过程中动态调整学习率,帮助模型更有效地学习,提高训练的稳定性和效率,最终获得更好的性能。
创造学习率调度器解决的问题:
- 避免学习率过高:如果学习率设置得过高,可能会导致模型参数更新过猛,从而使得「损失函数值」振荡甚至发散,影响模型的稳定性和「收敛速度」。
- 避免学习率过低:在训练后期,如果学习率过低,模型参数的更新将非常缓慢,这可能导致训练过程陷入「局部最小值」,或者需要更长的时间来收敛。
- 适应训练阶段:不同的训练阶段可能需要不同的学习率。在初期可能需要较高的学习率以快速下降,在接近最优解时则需要较低的学习率以细致调整,避免过度震荡。
没有学习率调度器会导致的结果:
- 训练效率低下:固定的学习率可能无法同时满足训练初期和后期的需求,导致训练效率不是最优,甚至需要更多的训练周期才能达到相同的效果。
- 模型性能不佳:如果学习率始终过高或过低,模型可能无法收敛到最佳状态,导致最终的模型性能不佳。
- 调参困难:没有学习率调度器,开发者可能需要手动多次尝试不同的学习率设置,以找到最佳的学习率,这个过程既耗时又低效。
#e StepLR调度器 学习率调度器
在PyTorch中,学习率调度器用于根据预定策略动态调整学习率。以下是一个使用StepLR调度器的简单例子,它在每过step_size个epoch后,将学习率乘以gamma来减小学习率。
import torch
import torch.optim as optim
# 定义一个简单的模型
model = torch.nn.Linear(10, 1)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 使用StepLR学习率调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
# 训练模型的代码...
# 每个epoch结束后更新学习率
scheduler.step()
#e 马拉松训练 学习率调度器
想象你正在为一场马拉松比赛训练。在训练初期,你可能会选择较高的强度(相当于高学习率),以快速提升你的体能和耐力。随着比赛日的临近(接近最优解),你可能会逐渐减少训练强度(降低学习率),进行更多的恢复性训练和技术细节的调整,以避免受伤并确保在比赛日能有最佳表现。
这个过程类似于使用学习率调度器来动态调整训练强度,确保在不同阶段采取最合适的训练策略,以达到最佳的训练效果。
#c 关联 相关概念
学习率调度器的作用和受影响的概念:
会影响的概念:
- 模型收敛速度:通过适时调整学习率,学习率调度器可以加快模型的收敛速度,特别是在训练初期通过使用较高的学习率。
- 模型性能:适当减小学习率可以帮助模型更细致地适应训练数据,避免「过拟合」,从而提高模型的泛化能力和最终性能。
- 训练稳定性:通过避免学习率过高导致的参数更新过猛,学习率调度器有助于保持训练过程的稳定性,减少损失函数的振荡。
影响学习率调度器的概念:
- 优化器(Optimizer):学习率调度器直接作用于优化器,调整其学习率参数。不同的优化器(如SGD、Adam等)可能对学习率的调整有不同的敏感度和效果。
- 训练策略:训练过程中的策略,如批大小(batch size)、训练轮次(epochs)等,会影响学习率调度器的设置。例如,较大的批大小可能需要不同的学习率调整策略。
- 模型复杂度和数据集:模型的复杂度和数据集的特性也会影响学习率调度器的选择和配置。复杂模型或难以拟合的数据集可能需要更精细的学习率调整策略。
















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











