







一、什么是DNS
域名系统 (DNS) 将人类可读的域名 (例如,www.amazon.com) 转换为机器可读的 IP 地址 (例如,192.0.2.44)。
DNS 服务的类型
权威 DNS(Authoritative DNS):处于 DNS 服务端的一套系统,该系统保存了相应域名的权威信息。权威 DNS 即通俗上“这个域名我说了算”的服务器。权威 DNS 包含 DNS 查询的最终答案,通常是 IP 地址。客户端(例如移动设备、在云中运行的应用程序或数据中心中的服务器)实际上并不直接与权威 DNS 服务通信,但极少数情况例外。如 Amazon Route 53、Aliyun 云解析、Azure DNS zone、Google Cloud DNS 等服务都是一种权威型 DNS。
递归 DNS(Recursive DNS):又叫 LocalDNS。递归 DNS 可以理解为是一种功能复杂些的 resolver,其核心功能一个是缓存、一个是递归查询。收到域名查询请求后其首先看本地缓存是否有记录,如果没有则一级一级的查询根、顶级域、二级域……直到获取到结果然后返回给用户。日常上网中运营商分配的 DNS 即这里所说的递归 DNS。递归型 DNS 服务就像是旅馆的门童:尽管没有任何自身的 DNS 记录,但是可充当代表您获得 DNS 信息的中间程序。如 Route 53 解析程序、Google Public DNS(8.8.8.8)、114dns(114.114.114.114) 等是一种公共 DNS 服务,也是递归 DNS 服务。
二、DNS 查询流程
下图概述了递归型和权威型 DNS 服务如何协同工作以将终端用户路由到您的网站或应用程序。

- 用户打开 Web 浏览器,在地址栏中输入 www.example.com,然后按 Enter 键。
- www.example.com 的请求被路由到 DNS 解析程序,这一般由用户的互联网服务提供商 (ISP) 进行管理,例如有线 Internet 服务提供商、DSL 宽带提供商或公司网络。
- ISP 的 DNS 解析程序将 www.example.com 的请求转发到 DNS 根名称服务器。
- ISP 的 DNS 解析程序再次转发 www.example.com 的请求,这次转发到 .com 域的一个 TLD 名称服务器。.com 域的名称服务器使用与 example.com 域相关的四个 Amazon Route 53 名称服务器的名称来响应该请求。
- ISP 的 DNS 解析程序选择一个 Amazon Route 53 名称服务器,并将 www.example.com 的请求转发到该名称服务器。
- Amazon Route 53 名称服务器在 example.com 托管区域中查找 www.example.com 记录,获得相关值,例如,Web 服务器的 IP 地址 (192.0.2.44),并将 IP 地址返回至 DNS 解析程序。
- ISP 的 DNS 解析程序最终获得用户需要的 IP 地址。解析程序将此值返回至 Web 浏览器。DNS 解析程序还会将 example.com 的 IP 地址缓存 (存储) 您指定的时长,以便它能够在下次有人浏览 example.com 时更快地作出响应。
- Web 浏览器将 www.example.com 的请求发送到从 DNS 解析程序中获得的 IP 地址。这是您的内容所处位置,例如,在 Amazon EC2 实例中或配置为网站端点的 Amazon S3 存储桶中运行的 Web 服务器。
- 192.0.2.44 上的 Web 服务器或其他资源将 www.example.com 的 Web 页面返回到 Web 浏览器,且 Web 浏览器会显示该页面。
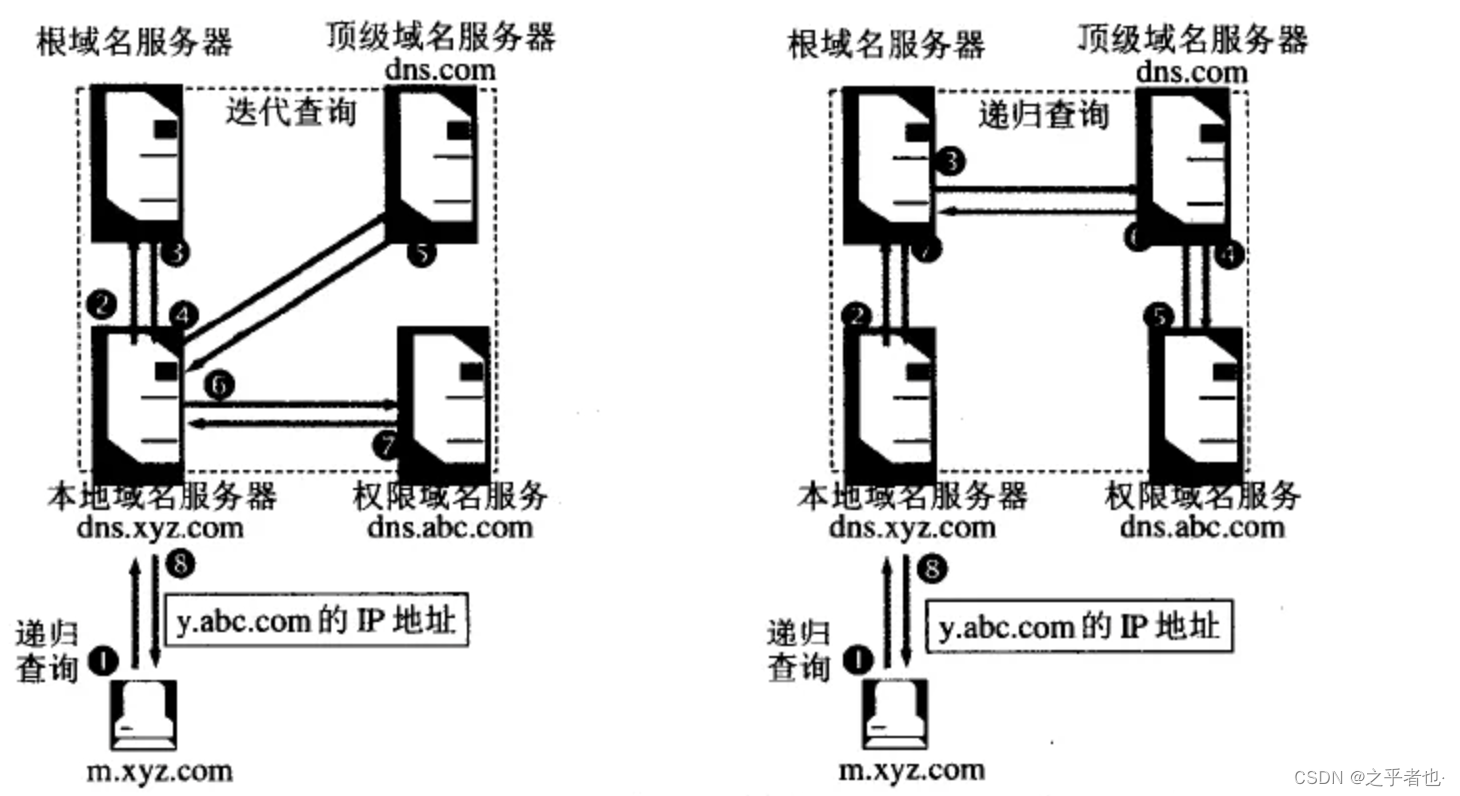
递归查询与迭代查询
递归查询:主机向本地域名服务器的查
递归查询:主机向本地域名服务器的查询一般都是采用递归查询。如果主机所询问的本地域名服务器不知道被查询的域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其它根域名服务器继续发出查询请求报文(即替主机继续查询),而不是让主机自己进行下一步查询。因此,递归查询返回的查询结果或者是所要查询的 IP 地址,或者是报错,表示无法查询到所需的 IP 地址。
迭代查询:一般DNS服务器之间属迭代查询,如:若 DNS2 不能响应 DNS1 的请求,则它会将 DNS3 的 IP 给 DNS2,以便其再向 DNS3 发出请求。
理论上讲域名查询有两种方式:
迭代查询 A问B一个问题,B不知道答案说你可以问C,然后A再去问C,C推荐D,然后A继续问D,如此迭代…
递归查询 A问B一个问题,B问C,C问D… 然后D告诉C,C告诉B,B告诉A
上图中的 1-2 为递归查询,3-6 为迭代查询。
三、智能 DNS 解析
传统 DNS 解析,不判断访问者来源,会随机选择其中一个 IP 地址返回给访问者。而智能 DNS 解析,会判断访问者的来源,为不同的访问者智能返回不同的 IP 地址,可使访问者在访问网站时可获取用户指定的 IP 地址,能够减少解析时延,并提升网站访问速度的功效。
edns-client-subnet(ECS)
在之前,它使用 DNS 解析器(LocalDNS)的 IP 地址对内容进行 DNS 查询。在特定解析器具有单一固定地理位置的时代,此模型运行良好。今天,许多流行的 DNS 解析器在地理上分散(Google DNS 和 OpenDNS 是两个很好的例子),并且特定解析器的位置不再是客户端位置的准确预测器。如果对内容的请求被路由到比需要更远的边缘位置,这可能会导致性能欠佳,因此 Google 提交了一份 DNS 扩展协议,允许 DNS resolver 传递用户的 IP 地址给 authoritative DNS server。
DNS 协议的 EDNS-Client-Subnet 扩展通过返回附加信息以响应 DNS 查询来解决此问题。该信息允许内容交付网络做出更好的决策。此扩展是作为 Faster Internet 项目的一部分开发的。
四、JAVA中迭代和递归的区别
1.含义不同
递归是重复调用函数自身实现循环。遇到满足终止条件的情况时逐层返回来结束
迭代是函数内某段代码实现循环,循环代码中参与运算的变量同时是保存结果的变量,当前保存的结果作为下一次循环计算的初始值。迭代则使用计数器结束循环。
2.结构不同
递归与迭代都是基于控制结构,都涉及重复结构
迭代用重复结构,迭代显式使用重复结构
递归用选择结构,递归通过重复函数调用实现重复
3.终止条件不同
迭代在循环条件失败时终止,迭代一直修改计数器,直到计数器值使循环条件失败;
递归在遇到基本情况时终止,使用计数器控制重复的迭代和递归都逐渐到达终止点(递归不断产生最初问题的简化副本,直到达到基本情况。)
4.小结
迭代法也称辗转法,是一种不断用变量的旧值递推新值的过程。让计算机对一组指令(或一定步骤)进行重复执行,在每次执行这组指令(或这些步骤)时,都从变量的原值推出它的一个新值。
代码实现:不断重复调用某个方法,符合一定条件后,计算出结果值。常见的累加,累乘都是迭代算法策略的基础应用。
递归算法:实现思想一样,重复的调用方法。好理解,JVM运行慢
迭代算法:实现思想一样,重复的调用某段代码。不好理解,JVM运行快
实际:解决思路为第一!
迭代大部分时候需要人为的对问题进行剖析,将问题转变为一次次的迭代来逼近答案。迭代不像递归一样对堆栈有一定的要求,另外一旦问题剖析完毕,就可以很容易的通过循环加以实现。迭代的效率高,但却不太容易理解,当遇到数据结构的设计时,比如图‘表、二叉树、网格等问题时,使用就比较困难,而是用递归就能省掉人工思考解法的过程,只需要不断的将问题分解直到返回就可以了。
总结:迭代更为底层一些;递归更为高级一些,更抽象一些;所以,有“迭代为人,递归为神”的说法。
下面用表格再总结一下:
| 递归 | 迭代 | |
|---|---|---|
| 定义 | 函数调用自身。 | 重复执行的一组指令。 |
| 应用 | 对于功能。 | 对于循环。 |
| 终止 | 通过 base case,这里不会有函数调用。 | 当不再满足迭代器的终止条件时。 |
| 用法 | 当代码大小需要很小并且时间复杂度不是问题时使用。 | 当时间复杂度需要与扩展的代码大小进行平衡时使用 |
| 代码大小 | 更少的代码 | 更多的代码 |
| 时间复杂度 | 非常高(通常是指数)的时间复杂度。 | 时间复杂度相对较低(一般为多项式-对数)。 |
| 空间复杂度 | 空间复杂度高于迭代。 | 空间复杂度较低。 |
| 堆 | 这里的栈是用来存放函数调用时的局部变量的。 | 不使用堆栈。 |
| 速度 | 执行速度很慢,因为它有维护和更新堆栈的开销。 | 通常,它比递归更快,因为它不使用堆栈。 |
| 存储 | 与迭代相比,递归使用更多内存。 | 没有开销,因为迭代中没有函数调用。 |
| 高架 | 拥有重复函数调用的开销。 | 没有开销,因为迭代中没有函数调用。 |
| 无限重复 | 如果递归函数不满足终止条件或未定义或从未达到基本情况,则会导致堆栈溢出错误,并且系统有可能在无限递归中崩溃。 | 如果迭代语句的控制条件永远不为假或控制变量没有达到终止值,就会造成死循环。在无限循环中,它一次又一次地使用 CPU 周期。 |
















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











