






一、深度学习基础篇
1. 常用指标
对于一个分类任务,我们预测情况大致如下面混淆矩阵所示:
| 预测为正样本 | 预测为负样本 | |
|---|---|---|
| 标签为正样本 | TP | FN |
| 标签为负样本 | FP | TN |
Accuracy
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN
Accuracy指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例,考虑的是全部样本。
Precision(精确率/查准率)
P r e c i s i o n = T P T P + F P Precision = \frac {TP} {TP+FP} Precision=TP+FPTP
Precision指的是正确预测的正样本数占所有预测为正样本的数量的比值,也就是说所有预测为正样本的样本中有多少是真正的正样本。precision只关注预测为正样本的部分
Recall(召回率/查全率)
R e c a l l = T P T P + F N Recall= \frac {TP} {TP+FN} Recall=TP+FNTP
它指的是正确预测的正样本数占真实正样本总数的比值,也就是我能从这些样本中能够正确找出多少个正样本。
⭐ 精度就是找得对,召回率就是找得全。
F1-Score
F
1
S
c
o
r
e
=
2
1
/
p
r
e
c
i
s
i
o
n
+
1
/
r
e
c
a
l
l
F1_{Score}=\frac{2}{1/precision+1/recall}
F1Score=1/precision+1/recall2
F-score相当于precision和recall的调和平均,用意是要参考两个指标。从公式我们可以看出,recall和precision任何一个数值减小,F1-score都会减小,反之,亦然。
P-R曲线

⭐ P-R曲线下方的面积就是平均精度AP
2. 卷积层
在卷积神经网络中,卷积操作是指将一个可移动的小窗口(称为数据窗口)与图像进行逐元素相乘然后相加的操作。这个小窗口其实是一组固定的权重,它可以被看作是一个特定的滤波器(filter)或卷积核。
特征图尺寸计算
w
o
u
t
=
w
i
n
+
2
∗
p
a
d
d
i
n
g
−
k
s
t
r
i
d
e
+
1
w_{out}=\frac{w_{in}+2*padding-k}{stride}+1
wout=stridewin+2∗padding−k+1
其中,
p
a
d
d
i
n
g
padding
padding为特征图填充圈数,主要目的是确保卷积核能够覆盖输入图像的边缘区域,同时保持输出特征图的大小,
k
k
k为卷积核大小,
s
t
r
i
d
e
stride
stride为步长。
例如:输入图片大小为 200 × 200 200×200 200×200,依次经过一层卷积(kernel size 5 × 5 5×5 5×5,padding 1 1 1,stride 2 2 2),pooling(kernel size 3 × 3 3×3 3×3,padding 0 0 0,stride 1 1 1),又一层卷积(kernel size 3 × 3 3×3 3×3,padding 1 1 1,stride 1 1 1)之后,输出特征图大小为多少?
解答:经过第一次卷积后的大小为: 本题 ( 200 − 5 + 2 ∗ 1 ) / 2 + 1 为 99.5 (200-5+2*1)/2+1 为99.5 (200−5+2∗1)/2+1为99.5,取99。经过第一次池化后的大小为: ( 99 − 3 ) / 1 + 1 为 97 (99-3)/1+1 为97 (99−3)/1+1为97,经过第二次卷积后的大小为: ( 97 − 3 + 2 ∗ 1 ) / 1 + 1 为 97 (97-3+2*1)/1+1 为97 (97−3+2∗1)/1+1为97
反卷积
反卷积又叫做转置卷积,在计算机中计算的时候,转置卷积先将卷积核转为稀疏矩阵C的形式,然后计算的时候正向传播的时候左乘这个稀疏矩阵C的转置,反向传播的时候左乘这个稀疏矩阵C。
反卷积的运算过程与卷积正好相反,是正向传播时左乘C的转置,反向传播时左乘C
1x1卷积作用
- 实现卷积核通道数的降维和升维;
- 减少参数量和计算量(先用少量普通卷积核再升维,或先降维再普通卷积等可以减少参数量以及计算量);
- 实现多个特征图的线性组合,而且可实现与全连接层的等价效果。
深度可分离卷积DSConv
- 对数据进行通道分离
- 对每个数据分别进行卷积核数为 1 1 1的卷积(DW,Conv参数不共享)
- 将映射堆叠在一起
- 使用点卷积升维(PW)
⭐ 空洞卷积
空洞卷积(Dilated Convolution),也称为膨胀卷积或者孔卷积,通过在卷积核中引入间隔(dilation rate),使卷积核在输入特征图上跳跃式地执行卷积操作,从而扩大了感受野,而不增加参数量。
在物体检测中,它可以用于提取不同尺度的特征以便于检测不同大小的物体。
K
e
=
K
+
(
K
−
1
)
∗
(
d
−
1
)
K_e = K + (K-1)*(d-1)
Ke=K+(K−1)∗(d−1)
其中,
K
K
K为空洞卷积的卷积核,
d
d
d为空洞数。
优点:
- 更大的感受野:它可以捕获更广泛区域的信息,有助于处理多尺度的特征。
- 参数效率:与传统的卷积相比,它不增加参数数量,因此在一定程度上减少了模型的复杂性。
- 降低过拟合:由于参数量较少,它有助于降低模型的过拟合风险。
卷积层的参数量
- 普通卷积层参数计算:
P a r a m s = c h a n n e l s o u t ∗ ( k e r n e l w ∗ k e r n e l h ∗ c h a n n e l i n ) + b i a s Params=channels_{out}*(kernel_w*kernel_h*channel_{in})+bias Params=channelsout∗(kernelw∗kernelh∗channelin)+bias其中 b i a s = c h a n n e l s o u t bias=channels_{out} bias=channelsout - 池化层参数计算:
池化层主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性;pooling在不同的 depth 上是分开执行的,池化操作是分开应用到各个特征图的,因此池化不需要参数控制。
卷积层的计算量
- 普通卷积层的计算量
卷积层计算量 = 卷积矩阵操作 + 融合操作 + 偏置项操作
注意:其中矩阵操作包括:先乘法,再加法
若有一张通道为 3 3 3,大小为 7 ∗ 7 7*7 7∗7 的图片,卷积核大小为: 5 ∗ 5 5*5 5∗5, s t r i d e stride stride为 1 1 1, p a d d i n g padding padding为 0 0 0,输出通道数为 64 64 64,其输出feature map的大小为 3 ∗ 3 ∗ 64 3*3*64 3∗3∗64,feature map中的每一个像素点,都是 64 64 64 个 5 ∗ 5 ∗ 3 5*5*3 5∗5∗3 的 f i l t e r filter filter共同作用于 7 ∗ 7 ∗ 3 7*7*3 7∗7∗3的图片计算一次得到的。
对于feature map上某一通道的某一点:
它的卷积矩阵操作计算量为
[
(
5
∗
5
∗
3
)
+
(
5
∗
5
−
1
)
∗
3
+
(
3
−
1
)
]
=
149
[(5*5*3)+(5*5-1)*3+(3-1)]=149
[(5∗5∗3)+(5∗5−1)∗3+(3−1)]=149,其中
(
5
∗
5
∗
3
)
(5*5*3)
(5∗5∗3) 代表矩阵乘法次数,
(
5
∗
5
−
1
)
∗
3
(5*5-1)*3
(5∗5−1)∗3代表矩阵加法次数,
(
3
−
1
)
(3-1)
(3−1) 代表通道融合操作,偏置项操作计算量等于输出通道数
64
64
64,所以feature map中某一通道的一个像素点的计算量为:
149
+
64
+
213
149+64+213
149+64+213。
所以feature map中某一通道的一个像素点的计算量为:
计算量 = 单个通道中单个像素点的计算量 * f e a t u r e feature feature m a p map map的大小*输出通道数
即 3 ∗ 3 ∗ 64 ∗ 213 = 122688 3*3*64*213=122688 3∗3∗64∗213=122688,这仅仅是单张图片的计算量,若是多张图片,则需要乘以batch size。
3. BN层
BN层原理
- 批量归一化(Batch Normalization,BN)是一种深度神经网络中常用的正则化技术,旨在
加速训练并减轻梯度消失问题。 - 批量归一化过程:
- 对于每个批次中的每个特征(神经元),计算其均值和方差。
- 使用均值和方差对批次内的每个特征进行归一化,以使其均值为0,方差为1。
- 引入两个可学习的参数:缩放因子(scale)和偏移参数(shift)。通过乘以缩放因子并加上偏移参数,使得BN层可以学习到更适合网络训练的特征变换。

⭐ 为什么说BN层可以缓减梯度消失问题
- 在不使用BN层的时候,由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区,梯度接近于零,导致梯度消失问题;
- BN层在每个批次的前向传播中会对每个特征(神经元)进行归一化,即将其均值归零、方差归一。这意味着每个特征都将具有大致相似的尺度,不会偏向于某个特定值域,从而有助于避免激活函数的饱和区域。通过归一化,激活函数在非饱和区域内更容易训练,减少了梯度消失的可能性。
训练和测试阶段BN操作的区别
- 训练时的操作:
- 在每个批次的前向传播过程中,计算该批次的均值和方差,并使用这些统计数据对该批次的特征进行归一化。
- 这意味着每个批次都会有不同的均值和方差用于归一化。
- 测试时的操作:
- 在测试时,通常用的均值和方差是全量训练数据的均值和方差,也就是使用全局统计量来代替批次统计量,这个可以通过移动平均法求得。
- 具体做法是,训练时每个批次都会得到一组(均值、方差),然后对这些数据求数学期望!每轮batch后都会计算,也称为移动平均。
BN 层通常处于网络中的什么位置
BN 通常应用于网络中的非线性激活层之前, 将卷积层的输出归一化, 使得激活层的输入服从 (0, 1) 正态分布, 避免梯度消失的问题。
4. 激活函数
激活函数作用
激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
Sigmoid与Softmax的联系与区别
ReLU

优点:
- 计算简单
- 在x>0区域上,不会出现梯度消失和梯度饱和问题
缺点:会出现神经元死亡现象。ReLU在负数区域被kill的现象叫做Dead Relu。ReLU在训练的时很“脆弱”。在x<0时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
SiLU
- SiLU(
Sigmoid-Weighted Linear Unit)是一种激活函数,也被称为Swish激活函数,它在深度学习中被广泛用于神经网络的隐藏层。 - SiLU 结合了 Sigmoid 函数和线性函数的特点,具有平滑性和非线性特性,有助于网络在训练过程中更快地收敛。
- SiLU激活函数的表达式如下:
σ ( x ) = x ∗ s i g m o i d ( x ) = x 1 + e − x \sigma \left ( x \right ) = x*sigmoid\left ( x \right ) =\frac{x}{1+e^{-x} } σ(x)=x∗sigmoid(x)=1+e−xx

Mish
M
i
s
h
(
x
)
=
x
∗
t
a
n
h
(
s
o
f
t
p
l
u
s
(
x
)
)
=
x
∗
t
a
n
h
(
l
o
g
(
1
+
e
x
)
)
Mish(x)=x * tanh(softplus(x))=x*tanh(log(1+e^x))
Mish(x)=x∗tanh(softplus(x))=x∗tanh(log(1+ex))

优点:
- 平滑性: Mish 是平滑的非线性激活函数,具有较为平滑的导数,这有助于梯度在反向传播中更稳定地流动,避免了一些激活函数如 ReLU 中可能出现的梯度消失问题。
- 非单调性: 与一些单调递增的激活函数不同,Mish 具有非单调性。一些研究表明,引入非单调性的激活函数可以带来更好的模型性能,增加了网络的表达能力。
缺点:
- 计算相对较慢: 与一些简单的激活函数相比,Mish 的计算相对较慢,因为它包含了较为复杂的操作,如 tanh 和 softplus。
5. 池化层
作用
- 对卷积层输出的特征图进行特征选择和信息的过滤,提取主要特征
- 能够实现对特征图的下采样,从而减少下一层的参数和计算量
- 通过减小特征图的维度,池化层有助于减少模型的参数数量,从而减小了过拟合的风险,提高了模型的泛化能力
- 保持特征的不变性(平移、旋转、尺度)
平均池化
平均池化是对池化区域内的图像取平均值,这种方式得到的特征信息对背景信息更加敏感,例如可以帮助分类。
最大池化
最大池化是将池化区域的像素点取最大值,这种方式得到的特征图对纹理特征信息更加敏感,减少无用信息的影响。
6. 全连接层
当图像经过全连接层(Fully Connected Layer)时,其尺寸通常会发生变化。全连接层是神经网络中的一种密集连接层,也称为全连接层或密集层,其每个神经元都与上一层的每个神经元相连接。由于全连接层的特性,图像在进入全连接层之前需要被展平成一维向量。
全连接层参数计算
例如某一网络最后一层卷积层输出的大小为 7 ∗ 7 ∗ 512 7*7*512 7∗7∗512,全连接层输出尺寸为 1 ∗ 1024 1*1024 1∗1024;则需卷积层的尺寸为: 7 ∗ 7 ∗ 512 7*7*512 7∗7∗512,所以所需参数为 512 ∗ 7 ∗ 7 ∗ 1024 + 1024 = 25691136 512*7*7*1024+1024=25691136 512∗7∗7∗1024+1024=25691136。(参数量巨大,这也是为什么说全连接层参数冗余的原因,全连接层参数就可占整个网络参数80%左右)
7. L1和L2正则化
正则化通常是应用在损失函数中的一种技术,旨在限制模型的复杂性,防止过拟合。正则化通过在损失函数中添加一个正则化项来实现,这个正则化项是模型参数的函数,它会在训练过程中对模型参数进行约束。
f
(
θ
)
=
损失函数
+
正则化项
f\left ( \theta \right ) =损失函数+正则化项
f(θ)=损失函数+正则化项
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;
- L2正则化可以防止模型过拟合,在一定程度上,L1也可以防止过拟合,提升模型的泛化能力;
- L1(拉格朗日)正则假设参数的先验分布是Laplace分布,可以保证模型的稀疏性,也就是某些参数等于0;
- L2(岭回归)正则假设参数的先验分布是Gaussian分布,可以保证模型的稳定性,也就是参数的值不会太大或太小。
在实际使用中,如果特征是高维稀疏的,则使用L1正则;如果特征是低维稠密的,则使用L2正则
- L1和L2正则先验分别服从什么分布 ?
- L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
8. Dropout
- Dropout可以认为是一种极端的Bagging,每一个模型都在单独的数据上训练,同时,通过和其他模型对应参数的共享,从而实现模型参数的高度正则化。
- Dropout是一种用于神经网络正则化的技术,旨在减少过拟合问题,提高模型的泛化能力。
Dropout原理
在神经网络前向传播时,让某个神经元的激活值以一定的概率P停止工作,这样可以使模型泛化性更强,减少过拟合。
⭐ Dropout起到正则化效果的原因
- Dropout可以使部分节点失活,起到简化神经网络结构的作用,从而起到正则化的作用。
- Dropout使神经网络节点随机失活,所以神经网络节点不依赖于网络中的某些隐含节点的固定作用,模型的鲁班性更好。Dropout最终产⽣收缩权重的平方范数的效果,压缩权重效果类似L2正则化。
Dropout 在训练和测试时都需要吗?
- Dropout 在训练时采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。
- 而在测试时,应该用整个训练好的模型,因此不需要Dropout。
BN和Dropout共同使用时会出现的问题
BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。
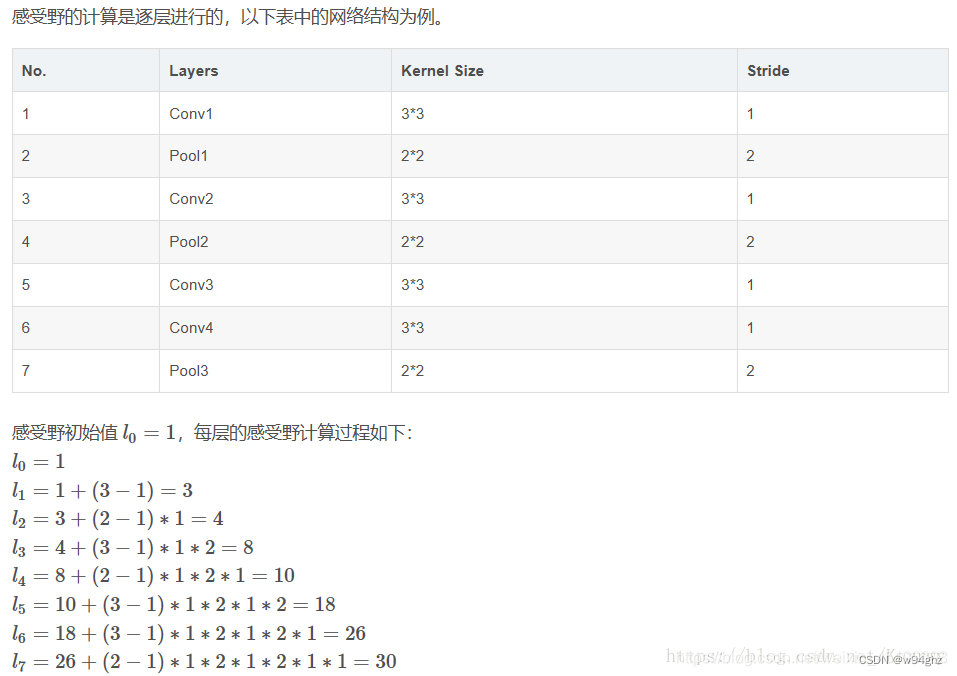
9. 感受野
感受野( R e c e p t i v e Receptive Receptive F i e l d Field Field )的定义是卷积神经网络每一层输出的特征图( f e a t u r e feature feature m a p map map)上的像素点在原始输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应原始输入图片上的区域。
感受野计算
在计算感受野时有下面几点需要说明:
- 第一层卷积层的输出特征图像素的感受野的大小等于卷积核的大小。
- 深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系。
- 计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小。
前向公式:
l
k
=
l
k
−
1
+
(
(
f
k
−
1
)
∗
∏
i
=
1
k
−
1
s
i
)
l_k=l_{k-1}+\left ( \left ( f_k-1 \right ) *\prod_{i=1}^{k-1} s_i \right )
lk=lk−1+((fk−1)∗i=1∏k−1si)
反向公式:
F
(
i
)
=
(
F
(
i
+
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
)
F\left ( i \right )=\left ( F\left ( i+1 \right ) \times Stride+ Ksize \right )
F(i)=(F(i+1)×Stride+Ksize)
从最后一层开始,最后一层的感受野为这一层卷积核的大小
10. 梯度下降算法的正确步骤
- 用随机值初始化权重和偏差
- 把输入传入网络,得到输出值
- 计算预测值和真实值之间的误差
- 对每一个产生误差的神经元,调整相应的权重值以减少误差
- 重复迭代,直至得到网络权重的最佳值
11. 梯度消失和梯度爆炸产生的原因和解决办法
- 梯度消失
- 产生的原因:
在深度神经网络中,反向传播过程中梯度通过多层传播,逐渐缩小。在链式法则的作用下,每一层都会乘以一个权重矩阵的梯度,如果这些权重都小于1,那么梯度会指数级地减小,导致梯度消失。 - 解决办法:
- 使用恰当的激活函数:
ReLU等激活函数在正区域的导数为1,有助于缓解梯度消失问题。 - 使用批标准化:批标准化可以使输入数据在层之间具有更一致的分布,有助于缓解梯度消失问题。
- 使用残差结构:残差连接可以在网络中引入跳跃连接,使得梯度能够更容易地传播。
- 权重初始化:使用适当的权重初始化方法,如
Xavier初始化,可以确保权重在前向和反向传播时的方差保持一致。
- 使用恰当的激活函数:
- 产生的原因:
- 梯度爆炸
- 产生的原因:
与梯度消失相反,当网络非常深时,反向传播中的梯度可以指数级地增大,导致梯度爆炸。 - 解决办法
- 使用梯度裁剪:设置一个阈值,如果梯度的范数超过该阈值,就进行梯度裁剪,将梯度缩放到一个较小的范围内。
- 权重初始化:使用适当的权重初始化方法,如
Xavier初始化,可以确保权重在前向和反向传播时的方差保持一致。
- 产生的原因:
12. 如何评判模型是欠拟合还是过拟合,如何解决此问题
欠拟合是指机器/深度学习模型无法在训练数据上获得足够好的拟合,导致模型对新的、未见过的数据表现不佳。
解决方法:
- 增加模型复杂度
- 减少正则化参数
过拟合是指模型在训练数据上表现得非常好,但在测试数据上表现不佳,无法泛化到未见过的数据。
解决方法:
3. 简化模型: 减少模型的复杂性,可以通过减少层次或减少神经元数量来实现。这有助于限制模型的容量,防止过拟合。
4. 增加训练数据: 增加更多的训练数据可以帮助模型更好地泛化,减少过拟合的风险。
5. 添加适当的正则化项,如Dropout、L1正则化或L2正则化,以防止模型过度拟合训练数据。
6. 使用early stopping
13. L1 loss、L2 loss、Smooth L1 loss
14. 预训练
在CV里,网络底层参数使用其它任务学习好的参数,高层参数仍然随机初始化。之后,用该任务的训练数据训练网络,底层参数微调
- Frozen:冷冻训练
- Fine-Tuning:加载预训练模型并在其上进行微调训练被称为 Fine-tuning。Fine-tuning 是一种常见的迁移学习方法,它利用预训练模型的已学习特征来加速模型训练和提高模型性能。在 Fine-tuning 过程中,我们通常会将预训练模型的最后一层或几层替换为新的全连接层,并在新数据集上进行训练。这样可以使预训练模型适应新数据集的特征,并提高模型的泛化能力。
优点:
- 训练数据较少时, 难以训练复杂网络
- 加快训练任务的收敛速度
- 初始化效果好,有利于优化
15. 标签平滑Label Smoothing
Label Smoothing 又被称之为标签平滑,常常被用在分类网络中来作为防止过拟合的一种手段,整体方案简单易用,在小数据集上可以取得非常好的效果。
- 不管是在object detection的分类网络或者是多分类网络导入label smoothing皆有不错的效果,基本上算轻松又容易提升准确度的做法
- 当数据量足够多的时候,Label smoothing这个技巧很容易使网络变得欠拟合。
- factor通常设置为 0.1 0.1 0.1,之前做对比实验试过使用0.2,0.3等参数,会发现皆无较好的效果,反而使网络变得难以收敛。
- 可以利用label smoothing的特性来做点微小的改动,比如遇上相似类型的事物时,可以将factor分配给相似的类别,而不是全部类别,这通常会有不错的效果。
迁移学习
- 迁移学习(Transfer Learning)是一种机器学习方法,它利用一个任务(通常是源任务)上学到的知识来帮助改善另一个相关任务(目标任务)的性能。迁移学习的核心思想是,先在一个相关但不完全相同的任务上训练模型,然后将模型的学习到的知识迁移到目标任务上,从而减少目标任务的训练时间和样本需求,提高性能。
二、图像处理篇
图像校正
- 基于轮廓的图像矫正方法步骤如下:
- 图片灰度化。
- 阈值二值化。
- 检测轮廓。
- 寻找轮廓的包围矩形,并且获得角度。
- 根据角度进行旋转矫正。
- 对旋转后的图像进行轮廓提取。
- 对轮廓内的图像区域抠出来,成为一张独立图像。
- 基于直线探测的图像矫正算法步骤如下:
- 用霍夫线变换探测出图像中的所有直线
- 计算出每条直线的倾斜角,求他们的平均值。
- 根据倾斜角旋转矫正。
- 最后根据文本尺寸裁剪图片。
总结:
(1) 基于轮廓提取的矫正算法更适用于车牌、身份证、人民币、书本、 发票一类矩形形状而且边界明显的物体矫正。
(2) 基于直线探测的矫正算法更适用于文本类等无明显边界图像的矫正
canny算子
- 将彩色图像转化为灰度图。
- 使用高斯滤波器平滑图像。
- 计算图像梯度的幅值和方向。
- 对梯度幅值进行非极大值抑制。
- 使用双阈值进行边缘的检测和连接; Canny 算子使用滞后阈值,滞后阈值需要两个阈值(高阈值和低阈值),若某一像素位置的幅值超过 高阈值,该像素被保留位边缘像素;若某一像素位置的幅值小于阈 值,该像素被排除;若某一像素位置的幅值在两个阈值之间,该像素 仅仅在连接到一个高于高阈值的像素时被保留
超分辨率重建
三、目标检测篇
1. NMS
- 常用于目标检测任务中,用于消除重叠的边界框,保留最具代表性的边界框。
- NMS算法并不是一种后处理,而是一种在目标检测算法中常用的技术。在目标检测过程中,通常会生成一系列候选边界框,而NMS算法会对这些候选边界框进行筛选,去除冗余的边界框,从而提高目标检测的准确性和效率。因此,NMS可以被视为一种在目标检测后处理阶段使用的技术。
- NMS的算法步骤如下:
- 获取当前目标类别下所有bbx的信息;
- 将bbx按照
confidence从高到低排序,并记录当前confidence最大的bbx; - 计算最大
confidence对应的bbx与剩下所有的bbx的IOU,移除所有大于IOU阈值的bbx; - 对剩下的bbx,循环执行(2)和(3)直到所有的bbx均满足要求(即不能再移除bbx)
缺点
- NMS算法中的最大问题就是它将相邻检测框的分数均强制归零(既将重叠部分大于重叠阈值Nt的检测框移除)。在这种情况下,如果一个真实物体在重叠区域出现,则将导致对该物体的检测失败并降低了算法的平均检测率(average precision, AP);
- NMS的阈值也不太容易确定,设置过小会出现误删,设置过高又容易增大误检。
SoftNMS
当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个BBoX。
为了解决这个问题,可以使用SoftNMS,其基本思想是用稍低一点的分数来代替原有的分数,而不是像NMS一样直接置零。
2. 介绍YOLO系列
3. IOU系列:IOU、GIOU、DIOU、CIOU等
目标框回归损失应该考虑三个重要的几何因素:重叠面积,中心点距离,长宽比,详情可移步:IOU系列:IOU、GIOU、DIOU、CIOU、SIOU、Alpha-IoU、WIOU详解
- IOU Loss:主要考虑检测框和目标框重叠面积;
- GIOU Loss:在IOU的基础上引入最小外接框,解决边界框不相交时loss等于0的问题;
- DIOU Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息;
- CIOU Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息;
- EIOU Loss:在CIOU的基础上,将宽高比改成了分别回归宽高值,并添加Focal Loss解决BBox回归中的样本不平衡问题;
- α \alpha αIOU Loss:通过调节 α \alpha α,使探测器更灵活地实现不同水平的bbox回归精度;
- SIOU Loss:在EIOU的基础上,加入了类别信息的权重因子,以提高检测模型的分类准确率;
- WIOU Loss:解决质量较好和质量较差的样本间的BBR平衡问题。
4. 如何解决类别不平衡问题
- 欠采样或过采样:增加少数类别的样本数量,可以通过在训练集中复制少数类别的样本或生成合成样本的方式来实现,或者在多数中进行部分采样。
- 数据增强:
- 随机变换、旋转、裁剪等操作来生成更多样本
GAN、Diffusion model生成新样本
- 更换损失函数:使用特定于类别不平衡问题的损失函数,如
Focal Loss或样本加权的损失函数,以更好地处理不平衡数据。 - 在线困难样例挖掘(OHEM):根据输入样本的损失进行筛选,筛选出hard example(多样性和高损失的样本),表示对分类和检测影响较大的样本,然后将筛选得到的这些样本应用到随机梯度下降中训练。
5. 如何解决漏检和误检的问题
- 使用更多的数据和多样性:数据增强(旋转,缩放,翻转等)
- 增加模型复杂度:使用更深层次的神经网络架构或更多的卷积层,更换更佳的backbone
- NMS算法:阈值设置不合理,导致过滤的边界框过多,导致漏检,可以考虑采用
soft-nms - 损失函数设计:通过调整损失函数,例如使用标签平滑技术,可以使模型更容易拟合,降低过度自信的问题
- 类别不平衡处理:如果某些类别的目标在数据集中比其他类别更少见,可以使用类别权重或重新采样技术来处理类别不平衡问题。
6. 注意力机制
计算机视觉中的注意力机制的基本思想是让模型学会专注,把注意力集中在重要的信息上而忽视不重要的信息。
Attention机制的本质就是利用相关特征图学习权重分布,再用学出来的权重施加在原特征图之上最后进行加权求和。不过施加权重的方式略有差别,大致总结为如下四点:
- 这个加权可以是保留所有分量均做加权(即soft attention);也可以是在分布中以某种采样策略选取 部分分量(即hard attention),此时常用RL来做。
- 加权可以作用在空间尺度上,给不同空间区域加权;
- 加权可以作用在Channel尺度上,给不同通道特征加权;
- 加权可以作用在不同时刻历史特征上,结合循环结构添加权重,例如机器翻译,或者视频相关的工作。
为了更清楚地介绍计算机视觉中的注意力机制,通常将注意力机制中的模型结构分为三大注意力域来分析。
主要是:空间域(spatial domain),通道域(channel domain),混合域(mixed domain)。
- 空间域——将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。对空间进行掩码的生成,进行打分,代表是Spatial Attention Module。
- 通道域——类似于给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高。对通道生成掩码mask,进行打分,代表是senet, Channel Attention Module。
- 混合域——空间域的注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。
7. 卷积神经网络中常用的Attention
在卷积神经网络中常用到的主要有两种:一种是Spatial Attention, 另外一种是Channel Attention。当然有时也有使用空间与通道混合的注意力,其中混合注意力的代表主要是BAM, CBAM。
-
Spatial Attention
对于卷积神经网络,CNN每一层都会输出一个C x H x W的特征图,C就是通道,同时也代表卷积核的数量,亦为特征的数量,H 和W就是原始图片经过压缩后的图的高度和宽度,
Spatial Attention就是对于所有的通道,在二维平面上,对H x W尺寸的特征图学习到一个权重,对每个像素都会学习到一个权重。你可以想象成一个像素是C维的一个向量,深度是C,在C个维度上,权重都是一样的,但是在平面上,权重不一样。 -
Channel Attention
对于每个C(通道),在channel维度上,学习到不同的权重,平面维度上权重相同。所以基于通道域的注意力通常是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息。
spatial 和 channel attention可以理解为关注图片的不同区域和关注图片的不同特征。channel attention的全面介绍可以参考论文:SCA-CNN,通道注意力在图像分类中的网络结构方面,典型的就是SENet。
四、操作系统篇
线程与进程的区别 ✅
- 定义:
进程是操作系统进行资源分配的最小单元,是计算机中的程序关于某数据集合上的一次运行活动,是操作系统结构的基础。线程是操作系统能够进行运算调度的最小单位(是CPU调度的最小单位)。它被包含在进程之中,是进程中的实际运作单位。一个进程可以有很多线程,每条线程并行执行不同的任务。
- 资源占用
- 每个进程有独立的内存和资源,进程之间的资源互不干扰。
- 线程之间会共享进程的内存和资源。
- 稳定性:
- 进程的稳定性更高,因为进程之间相互隔离,互不影响,一个进程崩溃通常不会影响其他进程。
- 线程的稳定性较低,因为一个线程的错误可能导致整个进程崩溃。
- 创建和销毁开销:
- 进程编程调试简单可靠性高,但是创建销毁开销大;
- 线程正相反,开销小,切换速度快,但是编程调试相对复杂。
TCP协议
TCP协议,传输控制协议(英语:Transmission Control Protocol,缩写为:TCP)是一种面向连接的、可靠的、基于字节流的通信协议。
- 三次握手(建立连接)
- 四次握手(断开连接)


















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











