






原因
1.直接从ollama官网pull下来的模型不知道用的是哪个gguf文件,也不知道modelfile是怎么写的,而你又想运行多个这个模型来提高并发
2.ollama cp命令只是对模型重命名,指向的还是原来的模型文件,导致并不能直接加载多个相同的模型使用
增加并发
修改配置文件:vim /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_NUM_PARALLEL=5" # 并行数量,这个数量越大模型在并行处理响应时间越长,设置为5较好,默认是1或者4
Environment="OLLAMA_KEEP_ALIVE=100h" # 运行模型保留时长,ollama有模型自动卸载功能,默认是5m,5分钟
Environment="OLLAMA_MAX_LOADED_MODELS=2" # ollama可以同时加载的模型数量。默认是3*GPU数量或者CPU推理的是3
Environment="OLLAMA_MAX_QUEUE=2048" # 在繁忙时最大请求数,超过这个数的其它请求会被拒绝,默认是512
修改好后使用systemctl daemon-reload && systemctl restart ollama命令重启ollama
复制模型
1.ollama pull拉取的模型位置 – 会有两个文件夹,一个blobs,一个manifests
- macOS:
~/.ollama/models - Linux:
/usr/share/ollama/.ollama/models - Windows:
C:\Users\%username%\.ollama\models
2.进入manifests/registry.ollama.ai/library,以我的服务器为例,如下:

到时候在ollama list后的显示逻辑就如上图
3.现在对gemma2:27b模型复制一份叫mygemma2:latest
4.在gemma2同级目录下创建文件夹mygemma2如下图:

5.编辑gemma2/27b文件:vim gemma2/27b
{"schemaVersion":2,"mediaType":"application/vnd.docker.distribution.manifest.v2+json","config":{"mediaType":"application/vnd.docker.container.image.v1+json","digest":"sha256:d109ef1844fab92b1cb56b2212da07335c936952e2ccf8adc36cb1baf9e89692","size":488},"layers":[{"mediaType":"application/vnd.ollama.image.model","digest":"sha256:d7e4b00a7d7a8d03d4eed9b0f3f61a427e9f0fc5dea6aeb414e41dee23dc8ecc","size":15628378336},{"mediaType":"application/vnd.ollama.image.template","digest":"sha256:109037bec39c0becc8221222ae23557559bc594290945a2c4221ab4f303b8871","size":136},{"mediaType":"application/vnd.ollama.image.license","digest":"sha256:097a36493f718248845233af1d3fefe7a303f864fae13bc31a3a9704229378ca","size":8433},{"mediaType":"application/vnd.ollama.image.params","digest":"sha256:2490e7468436707d5156d7959cf3c6341cc46ee323084cfa3fcf30fe76e397dc","size":65}]}
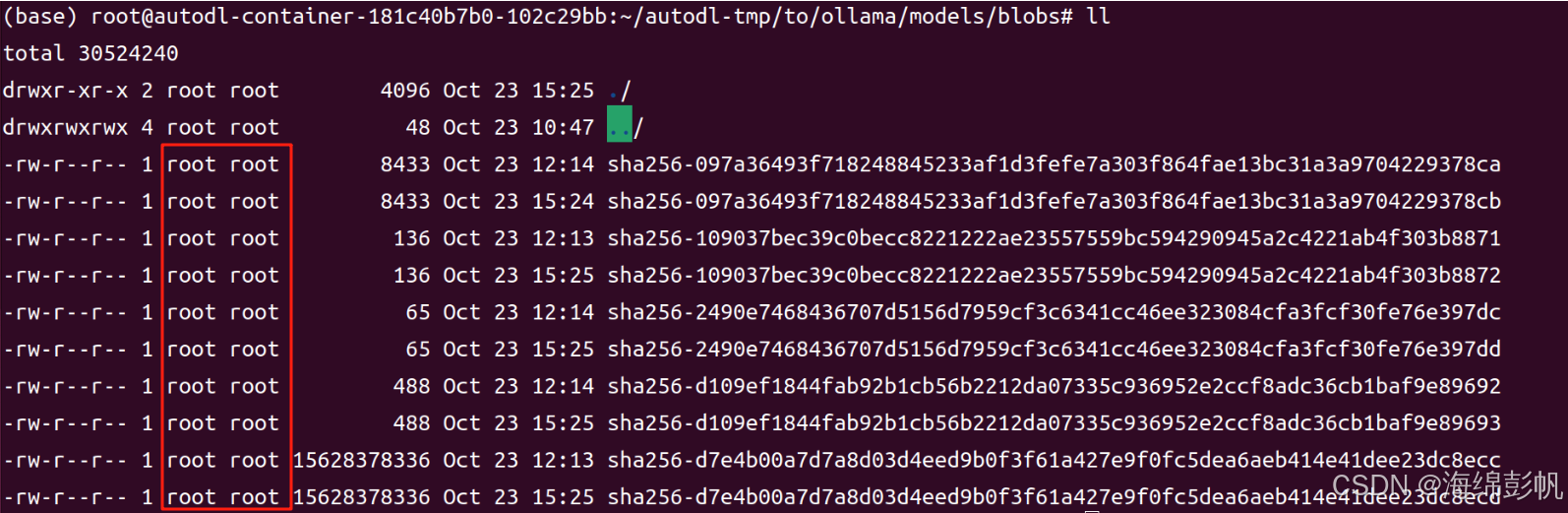
6.去另一个文件夹blobs,会发现上面的文件信息的digest模型文件都在这里能找得到,除了文件名中的:变成了-
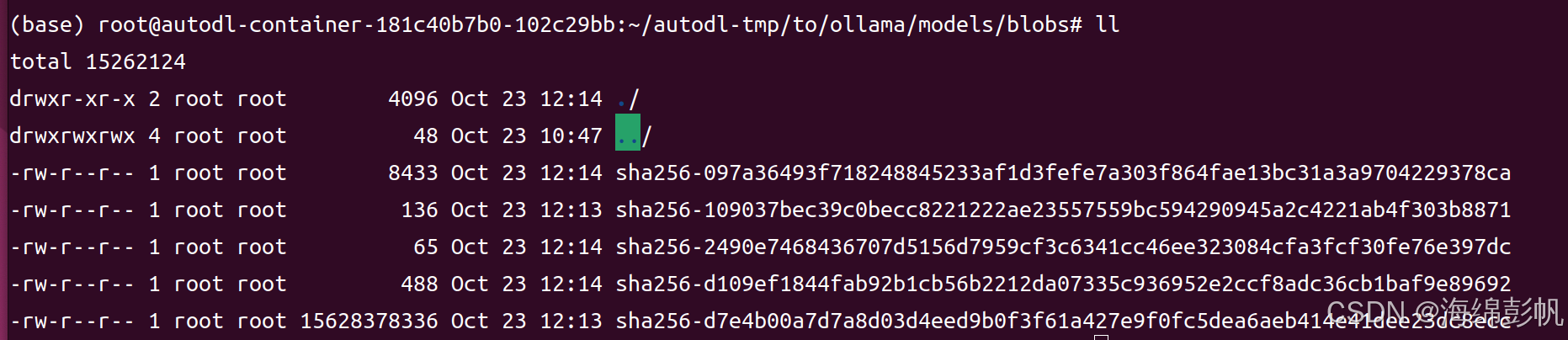
7.将blobs和上面文件信息对应的所有digest设计的文件复制一份,不过注意复制的时候改一点点名字,我这里就把最后一个字符改了
cp sha256-097a36493f718248845233af1d3fefe7a303f864fae13bc31a3a9704229378ca sha256-097a36493f718248845233af1d3fefe7a303f864fae13bc31a3a9704229378cb
cp sha256-109037bec39c0becc8221222ae23557559bc594290945a2c4221ab4f303b8871 sha256-109037bec39c0becc8221222ae23557559bc594290945a2c4221ab4f303b8872
cp sha256-2490e7468436707d5156d7959cf3c6341cc46ee323084cfa3fcf30fe76e397dc sha256-2490e7468436707d5156d7959cf3c6341cc46ee323084cfa3fcf30fe76e397dd
cp sha256-d109ef1844fab92b1cb56b2212da07335c936952e2ccf8adc36cb1baf9e89692 sha256-d109ef1844fab92b1cb56b2212da07335c936952e2ccf8adc36cb1baf9e89693
cp sha256-d7e4b00a7d7a8d03d4eed9b0f3f61a427e9f0fc5dea6aeb414e41dee23dc8ecc sha256-d7e4b00a7d7a8d03d4eed9b0f3f61a427e9f0fc5dea6aeb414e41dee23dc8ecd
复制好后如下:
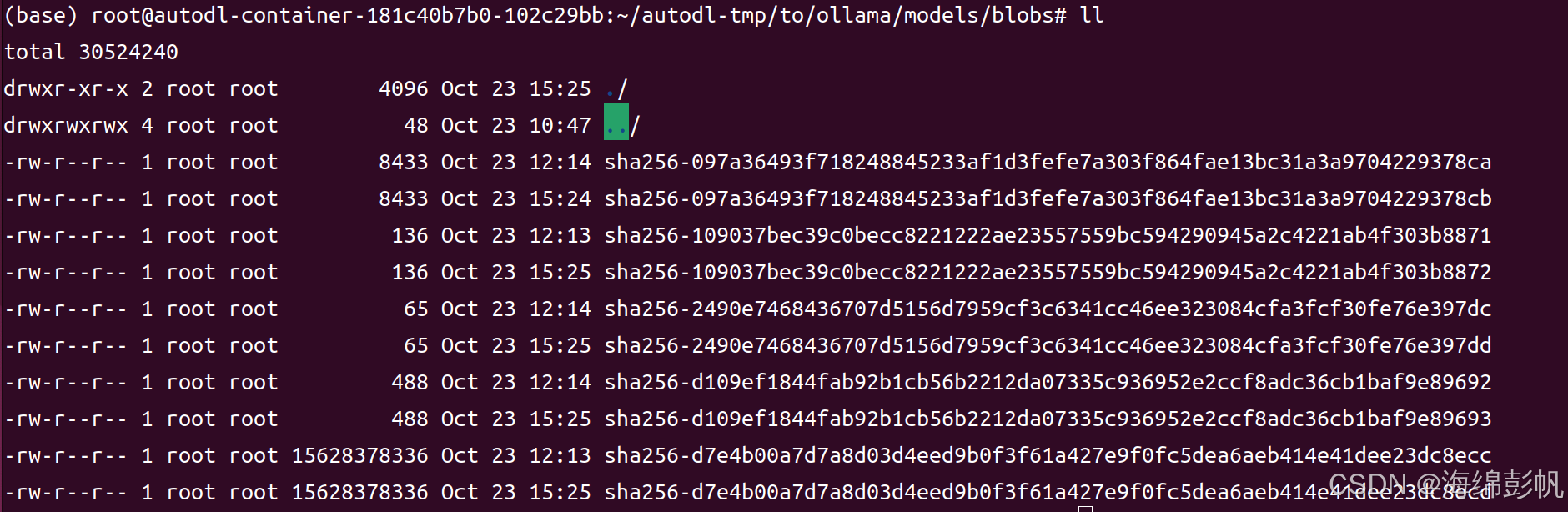
8.因为我们的取名是mygemma2:latest,所以编辑mygemma2/latest文件

将下面的内容写入latset文件,就是把复制的文件的名字按照gemma2/27b格式替换了一下
{"schemaVersion":2,"mediaType":"application/vnd.docker.distribution.manifest.v2+json","config":{"mediaType":"application/vnd.docker.container.image.v1+json","digest":"sha256:d109ef1844fab92b1cb56b2212da07335c936952e2ccf8adc36cb1baf9e89693","size":488},"layers":[{"mediaType":"application/vnd.ollama.image.model","digest":"sha256:d7e4b00a7d7a8d03d4eed9b0f3f61a427e9f0fc5dea6aeb414e41dee23dc8ecd","size":15628378336},{"mediaType":"application/vnd.ollama.image.template","digest":"sha256:109037bec39c0becc8221222ae23557559bc594290945a2c4221ab4f303b8872","size":136},{"mediaType":"application/vnd.ollama.image.license","digest":"sha256:097a36493f718248845233af1d3fefe7a303f864fae13bc31a3a9704229378cb","size":8433},{"mediaType":"application/vnd.ollama.image.params","digest":"sha256:2490e7468436707d5156d7959cf3c6341cc46ee323084cfa3fcf30fe76e397dd","size":65}]}
9.使用ollama list命令就能看到我们复制的模型

10.验证是否能加载
curl http://localhost:11434/api/chat -d '{
"model": "mygemma2:latest",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
11.使用nvidia-smi查看显存占用
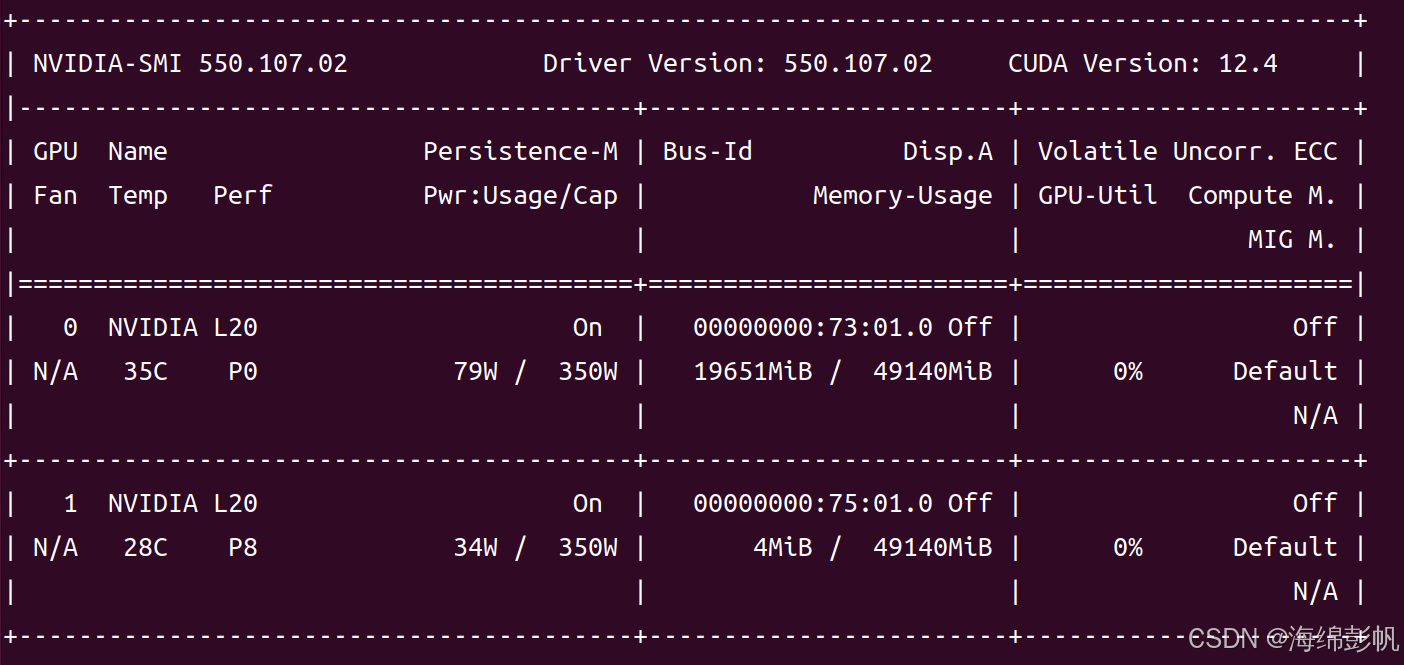
12.再运行下原始的gemma2:27b的模型
curl http://localhost:11434/api/chat -d '{
"model": "gemma2:27b",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
13.再次使用nvidia-smi查看显存占用
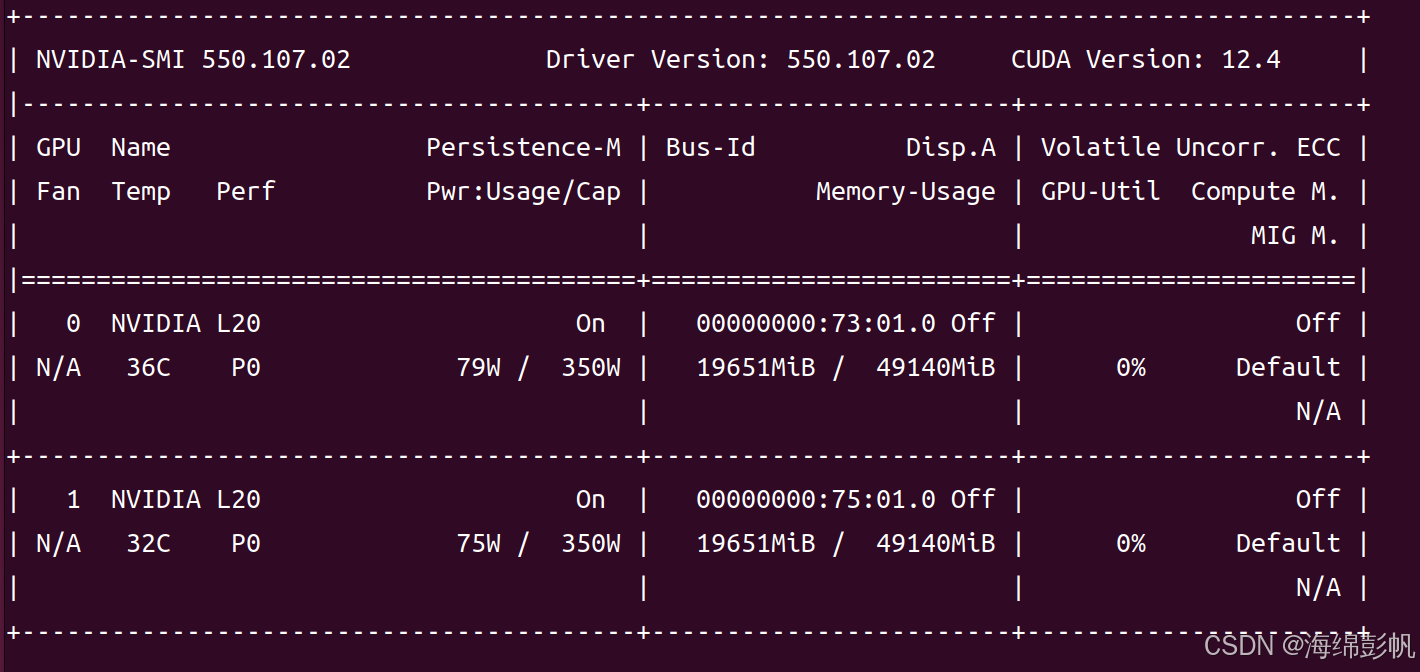
14.很明显,两个模型都同时加载到了显存当中,实现了加载同一个模型多次
注意
有时候你在运行到第9步的时候可能并没有看到新添加的模型,那你就注意所属用户,这个用户你刚开始在第6步骤是什么,你就要改成什么
命令:sudo chown -R 用户名:用户名 文件名
下一篇是代码实现,实现快速复制

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









