







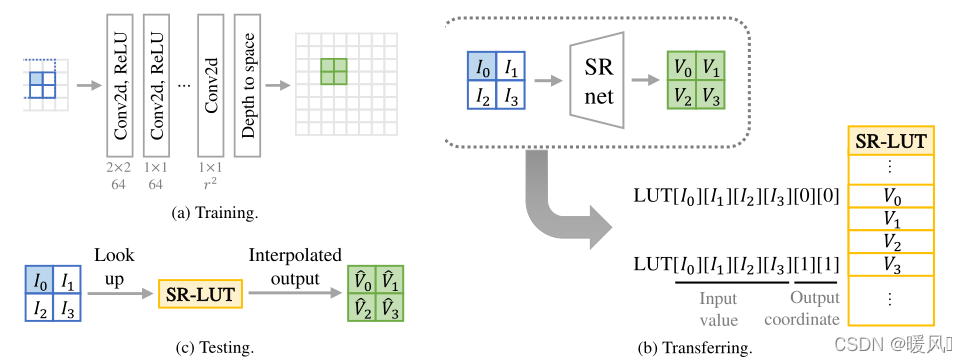
这篇文章是首次将查表法引入SR领域。将SR网络训练好的缩放像素值存在表中,在测试阶段只需要在表中查找对应值,就能完成图像重建任务。由于该方法不需要大量的浮点运算,因此可以非常快速地执行。
原文链接:SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table 【CVPR2021】
参考目录:
超分之SR-LUT
超分之SR-LUT源码解析
源码(Pytorch)
SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table
Overview
SR_LUT的整体结构为:训练网络 - 存表 - 测试(读表) (重点部分在于存表和读表)
一张图像放大r倍,可以看成是每个像素放大r倍。文章就是基于这种思想设计的,但每个像素放大后是怎样的,由周围的像素(感受野)来决定。
训练网络: 获得一个LR到HR的全图映射。
存表:
- 给定感受野大小,使用前面训练好的映射来获取该感受野对应的放大后的对应区域像素值,存到查找表中。比如说给定2×2的感受野。那对应这个区域大小一共有
25
5
4
255^4
2554种像素的排列可能。也就是说,这个像素周围环境一定是这
25
5
4
255^4
2554中的一种。
每一种像素的排列都要存到查找表中,这样以后不论碰到怎么样排列的像素我们都可以根据查找表恢复重建后的像素区域。所以表中一共需要存有$255^n$行。 n n n是指定的感受野大小。 放大后对应图像区域仅与放大倍数r有关。给定放大倍数 r r r,每个像素放大后的对应区域大小应该是 r × r r×r r×r。感受野大小是赋予每个像素的,是用来形容这个像素周围环境的,真正的主体还是该像素,所以放大后得到 r × r r×r r×r大小。- 所以整个查找表的存储量为: 25 5 n × r 2 × 8 b i t \bm{255^n \times r^2 \times 8bit} 255n×r2×8bit. (每个像素占8bit内存)
查表: 对图中每个像素位置扩展为感受野的大小,然后在查找表中找到对应的区域值,取出来作为重建块。
以上是常规的网络,但是考虑到
25
5
n
255^n
255n 行,内存消耗太多了。所以作者想出一个办法,提出了sampled-LUT变体:将255种像素值下采样,减少查找表所占的内存。采样间隔为
2
4
2^4
24 ,将输入空间划分为{ 0 , 16 , 32 , 48 , 64 , 80 , 96 , 112 , 128 , 144 , 160 , 176 , 192 , 208 , 224 , 240 , 255 }一共17个采样点。于是
25
5
n
255^n
255n种可能就下降到了
1
7
n
17^n
17n,极大减小了存储量。但这也带来了一个问题,在查表时输入图片的像素如果是非采样点,直接取其最近的采样点值代替的话,图像会损失大量细节,重建效果会非常差。于是在该部分,作者提出了各种对应感受野的插值算法。
Train deep model
训练阶段其实比较常规。文中的图不能完全的表述,这里借用另一个博主的图。
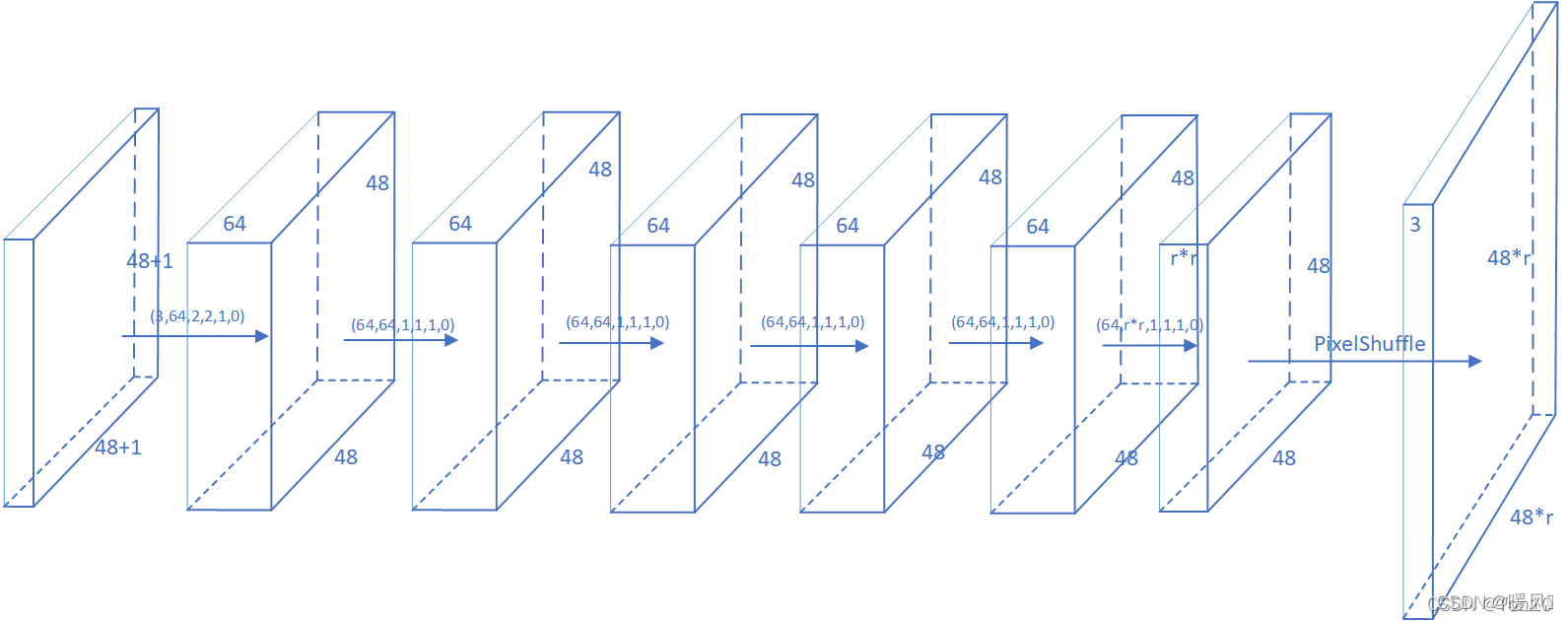
在这一步只是纯粹的网络训练,为了得到输入图像LR到重建图像SR的映射
f
f
f。(其实就是训练好卷积层的参数用于下一阶段的存表)由于存表时输入的感知野很小,所以网络不需要太多的层数去堆叠,作者采用了6层CNN网络以及一层亚像素卷积层。
- 输入patch为48×48,输入端加padding,是为了配合第一层的2×2卷积,为了保证图像大小不变。二到六层的卷积核大小的都为1×1。除了最后一层,其余的CNN层后都接ReLU来增加模型非线性度。
- 最后一层卷积输出深度为 r × r r×r r×r,对应于每个像素扩展 r r r倍。
- 网络最后使用亚像素卷积层PixelShuffle,将深度为 r × r r×r r×r的feature map ,重组为高 r × H r×H r×H,宽为 r × W r×W r×W的高分辨率图像输出,完成图像重建
作者将自集成(self ensemble)的技巧用于CNN的训练中,采用了4种增强方式,分别是旋转90°、180°、270°,之后对网络的输出做反增强操作,再取平均作为最后的输出。
Transfer to LUT

就和标题一样,做了一件事情,存表。
我们先捋一遍这部分过程:已经规定感受野大小为
n
n
n(
1
×
2
、
1
×
3
、
2
×
2
,
5
1×2、1×3、2×2,5
1×2、1×3、2×2,5,具体5是怎么样的形状未知。作者只罗列了这四种感受野大小,再大的话,占用内存就太大了),放大倍数为
r
r
r。记住每个像素放大r倍,所以我们存下来的表中应该有
r
2
r^2
r2列。
感受野大小为n时,一共有 25 5 n 255^n 255n种排列可能,每种情况,对应 r 2 r^2 r2个像素值。所以一共存 25 5 n 255^n 255n行, r 2 r^2 r2 列。看上图中 L U T [ I 0 ] [ I 1 ] [ I 2 ] [ I 3 ] [ 0 ] [ 0 ] LUT[I_0][I_1][I_2][I_3][0][0] LUT[I0][I1][I2][I3][0][0]前四位就代表了感受野大小为4,后两位对应放大倍数r=2,共四列,需要两位二进制数表示。
我们再加一个条件,采样间隔设为
W
=
2
4
W = 2^4
W=24,只剩下17个采样点,LUT的行数变为
1
7
n
17^n
17n,列为
r
2
r^2
r2。
看下具体是怎么做的,图片还是借用Ton博主的
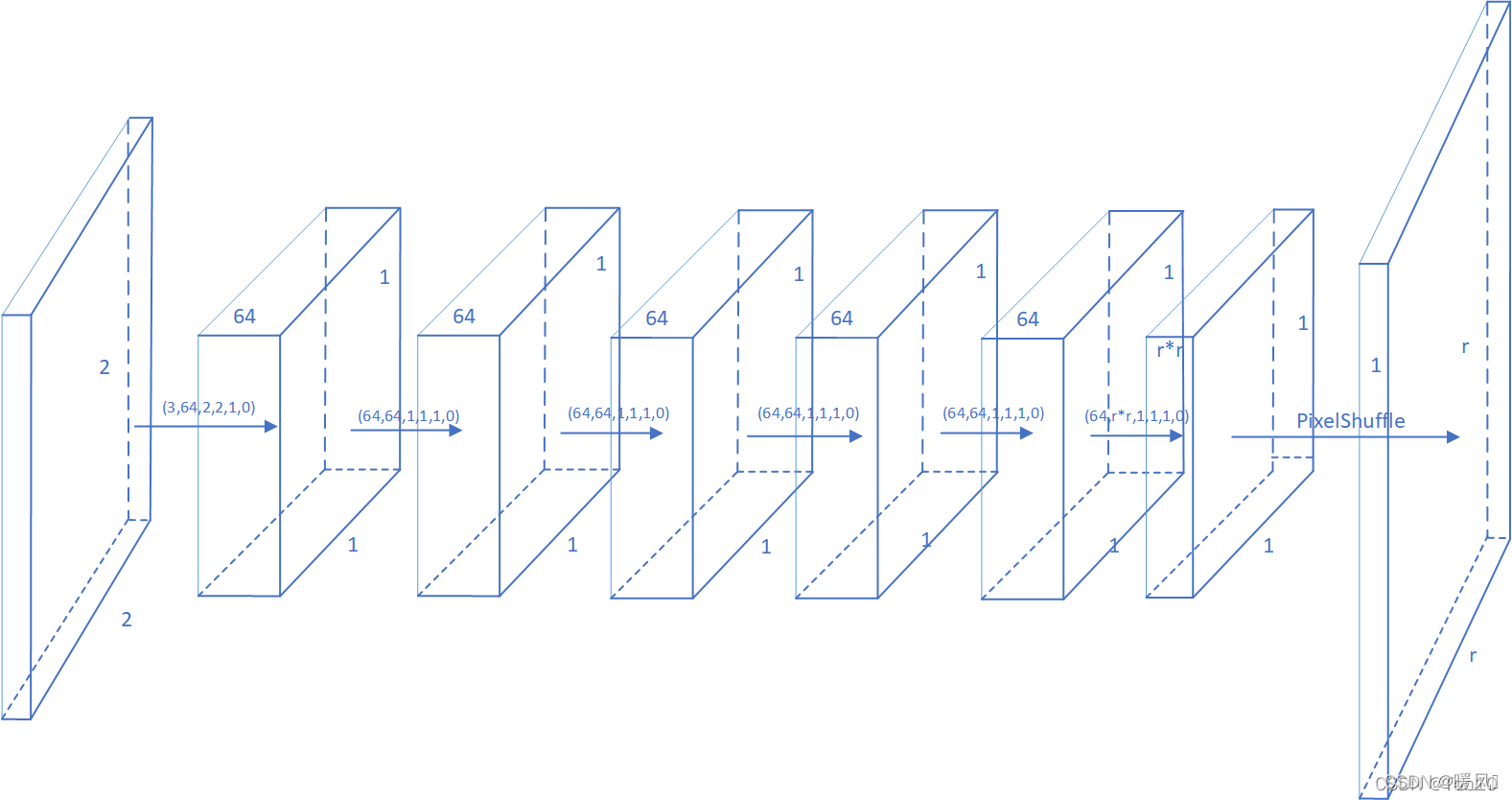
网络输入patch变为2×2(根据感受野大小),输出:深度为
r
2
r^2
r2大小为1×1。最后使用亚像素卷积将这
r
2
r^2
r2张图转换为一张
r
×
r
r×r
r×r大小的图像,将这张图像存在查找表对应行的
r
2
r^2
r2列中。
对于Sampled-LUT来说,输入格式为:
(
1
7
4
,
1
,
2
,
2
)
(17^4, 1, 2, 2)
(174,1,2,2),得到一个
(
1
7
4
,
1
,
r
,
r
)
(17^4, 1, r, r)
(174,1,r,r)格式的张量,reshape一下成
(
1
7
4
,
r
2
)
(17^4, r^2)
(174,r2)并保存为Numpy数组存起来供测试的时候使用。
Test using LUT
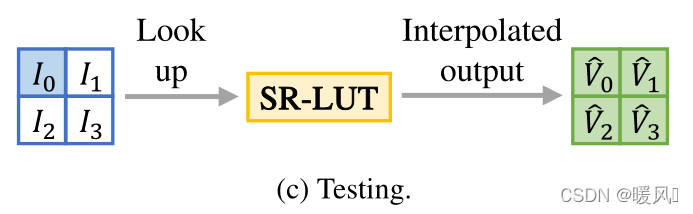
在测试阶段,就可以完全脱离CNN,只用查表得方式来恢复出图像欠缺的细节,产生高分辨率的图像。
测试的时候,输入是整张图像,对每个像素点
(
x
,
y
)
(x,y)
(x,y)遍历,找到
(
x
,
y
)
(x,y)
(x,y)周边感受野大小的像素,当前像素作为左上角,观察其右边1格、下边1格、右下1格的像素信息,相等于获取了
2
×
2
2 × 2
2×2感受野,接着去LUT里查找出以这4个像素值为索引的
r
×
r
r × r
r×r的内容结果来作为当前像素点
(
x
,
y
)
(x,y)
(x,y)重建出的
r
×
r
r × r
r×r 高分辨率像素块,因此读表是读取
2
×
2
2 × 2
2×2感受野中左上像素对应的一个
r
×
r
r × r
r×r块的过程。
这一部分中主要要学习的是插值算法。如何将一个非采样值的点从表中读取重建块。
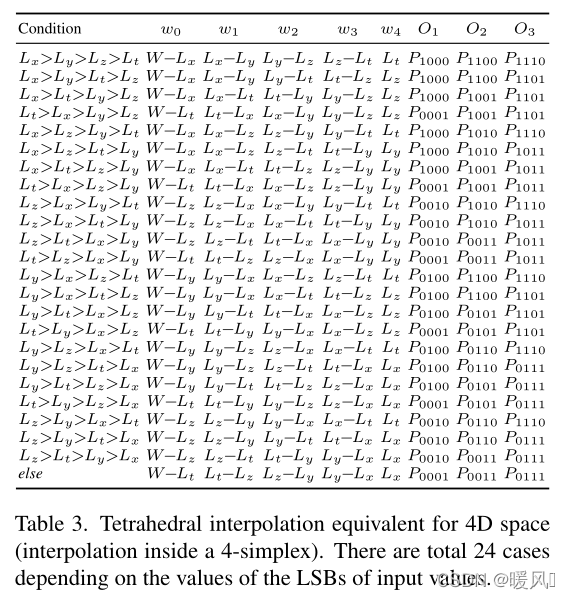
文章对不同的感受野大小使用不用的插值方式,2D感受野使用三角插值(三个顶点),3D感受野使用四面体插值(四个顶点),4D感受野使用4-单形插值(需要5个顶点)。
首先介绍一下怎么用4D感受野的像素值在查找标中找到对应行的索引值。L是
2
8
2^8
28除于采样间隔W.
P
=
I
0
×
L
×
L
×
L
+
I
1
×
L
×
L
+
I
2
×
L
+
I
3
P = I_0 \times L \times L \times L + I_1 \times L \times L + I_2 \times L + I_3
P=I0×L×L×L+I1×L×L+I2×L+I3
4D感受野下插值的步骤:
- 感受野中四个8bits像素值,分别提取MSB(高4位)和LSB(低4位),共获得四个MSB和四个LSB。
- 根据四个MSB组合排列共有16种可能分别记为 P 0000 , … , P 1111 P_{0000}, \dots , P_{1111} P0000,…,P1111,获得了16个插值的顶点,但我们只需要5个。(顶点其实就是查表中对应行的索引)
- 根据四个LSB之间的大小关系,选用五个顶点和权重值,就能得到所求表中对应的 r × r r×r r×r大小的重建块的值。
具体操作可以看代码和这篇解析:超分之SR-LUT源码解析
Conclusion
这篇文章是比较新颖的,将LUT引入到SR任务中,该结构可以训练后脱离CNN使用,应用于移动端非常的方便,速度也是非常之快。
整个结构分为三个部分:
- 训练: 使用六层卷积和亚像素卷积层重建图像,输入patch为48×48,
获得输入LR到重建SR图像的映射。 - 存表: 使用训练好的网络遍历所有可能输入情况 1 7 n 17^n 17n(Sampled-LUT),输入为小尺寸感受野n,输出 r × r r×r r×r的重建像素,将结果保存在表中,整个表共有 1 7 n 17^n 17n行, r 2 r^2 r2列。
- 测试(读表): 脱离CNN网络,输入整张图像,遍历所有像素,(使用插值算法)根据感受野读取表中 r 2 r^2 r2重建像素。
- 注意:每个阶段输入分辨率都是不一样的。
最后祝各位科研顺利,身体健康,万事胜意~














 1815
1815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









