







 HIPA是一种新的分层patch Transformer,用于单图像超分辨率(SISR)。它通过逐步合并不同大小的patch,实现自适应特征学习。文章提出了一种基于注意力的位置编码Transformer(APE-ViT)和多感受野注意力模块(MRFAM),以捕获全局依赖和局部特征。实验证明,HIPA在多个数据集上超越了现有方法,尤其是在大尺度因子下。
HIPA是一种新的分层patch Transformer,用于单图像超分辨率(SISR)。它通过逐步合并不同大小的patch,实现自适应特征学习。文章提出了一种基于注意力的位置编码Transformer(APE-ViT)和多感受野注意力模块(MRFAM),以捕获全局依赖和局部特征。实验证明,HIPA在多个数据集上超越了现有方法,尤其是在大尺度因子下。
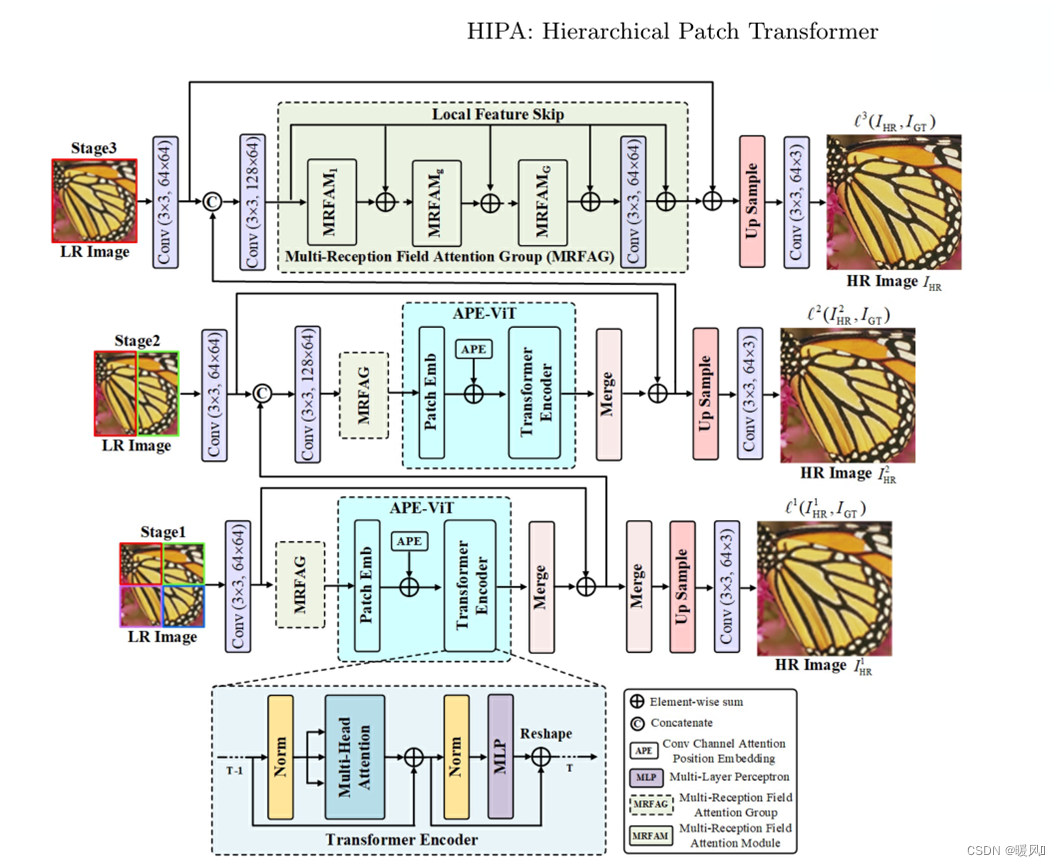
这篇文章HIPA提出了一种使用不同patch大小,分层级的提取融合特征的SR方法。提出了一种新的基于通道注意力的位置编码Transformer模块APE-ViT:就是在位置编码的时候加入了注意力。第二个模块是多感受野的注意力模块MRFAM:在不同感受野下进行特征提取,使用了三个并列分支的的卷积组合来获得不同的感受野,该模块中还提出了一种新的通道注意力机制。在位置编码中加入注意力这种想法应该是本文中第一次提出。
这篇文章暂时没放源码,也没发补充材料。
原文链接:HIPA: Hierarchical Patch Transformer for Single Image Super Resolution
HIPA: Hierarchical Patch Transformer for Single Image Super Resolution[2022]
Abstract
近来,基于Transformer的架构被引入单图像超分辨率(SISR)中,并取得了良好的性能。大多数现有的视觉Transformer将图像分割成相同数量的固定大小的patch,这对于恢复纹理丰富程度不同的块可能不是最佳选择。
本文介绍了一种新的Transformer结构HIPA,它使用分层分片逐步恢复高分辨率图像。具体来说,建立了一个级联模型,分多个阶段处理输入图像,从小块的token开始,逐步合并到完整分辨率。这种分层patch机制不仅明确地支持多分辨率下的特征聚合,而且还自适应地学习不同图像区域的patch感知特征。
- 提出了一种新的基于注意的Transformer位置编码方案,通过给不同的token分配不同的权重,让网络关注重要的token。这种方法是在本文中第一次提出。
- 还提出了一个新的多感受野的注意力模块,以扩大不同分支的卷积感受野。
在几个公共数据集上的实验结果表明,所提出的HIPA方法在定量和定性上都优于以前的方法。
1 Introduction
深度卷积神经网络(CNN)在SISR方面取得了显著的成功,目前已经提出了各种结构,然而,CNN中的卷积使用滑动窗口提取特征,仅捕获局部模式,缺乏建模全局上下文的能力。
受Transformers在自然语言处理领域取得的巨大成功及其在全局建模方面的优势的启发,视觉Transformers也被引入了SISR领域。由于多头自注意机制能够建模长距离依赖关系,因此获得了比许多基于CNN的SOTA方法更好的结果。
最近,结合CNN和Transformer的混合架构出现,增强其在特征提取方面的优势。尽管这些现有的基于Transformer的SISR模型取得了优异的结果,但几乎所有模型都将输入图像分割为固定大小的patch,并使用相同数量的patch处理所有样本,考虑到不同的图像区域有其自身的特征,这这方法可能不是最优的。
本文提出了一种分层patch Transformer,将输入图像划分为不同大小的patch层次。
- 通过交替堆叠CNN和Transformer,开发了一种多级体系结构,以充分利用CNN在提取局部特征方面的优势和Transformer在建立长期依赖关系方面的优势。
- 为了实现Transformer的不同大小的patch输入,并让Transformer从不同数量的token建立全局依赖关系,首先将LR图像划分为子块的层次结构,这些子块作为Transformer的输入,从小尺寸块开始,然后在下一阶段逐渐合并它们。
- 此外,设计了一种新的基于注意力的Transformer位置编码方案,该方案基于通道注意力,以连续的动态模型对位置信息进行建模。
- 此外,提出了一种基于不同放大因子的扩展卷积的多感受野注意模块,以扩大不同分支的卷积感受野。
如图1所示,与其他最先进的SISR方法相比,HIPA获得了更好的视觉质量。

简而言之,与现有方法的主要贡献和显著区别在于:
- 渐进模型形成了子块的层次结构,允许为Transformer实现不同大小的patch,这比使用相同数量的固定大小patch处理所有样本更有效,
- 为Transformer提出了一种新的基于注意的位置编码方案,该方案对重要的token给予更多的权重,该方法是在本文第一次提出。
2 Method
首先介绍整个网络的结构,再具体介绍其中的基于注意力的位置编码视觉Transformer :attention-based position encoding vision Transformer(APE-ViT)模块和多感受野注意力:multi-reception field attention module(MRFAM)模块,多个MRFAM串联为一个MRFAG(实验中设置为5)。
2.1 Overview
提出的HIPA包括三个阶段:前两个阶段都是基于提出的多感受野注意力模块(MRFAM)和基于注意力的位置编码ViT(APE ViT)构建的。最后一个阶段仅基于MRFAM构建,而不使用APE ViT,因为最后一级的输入是整个图像,这将大大增加计算时间和对更多内存的需求。
此外,为了实现Transformer不同大小的输入patch,在输入LR图像上采用了多patch层次结构。
- 首先将LR图像分割为不同阶段的不同非重叠面片:第一阶段四个,第二阶段两个,最后阶段整个LR图像。
- 然后在下一阶段逐步将其合并。在第二阶段,利用子块的垂直整合(13和24),而不是水平整合整合(12和34)。(当然也可以横向整合,但经过实验并没有显著差异)。
图中标注的 C o n v ( 3 × 3 , 64 × 64 ) Conv(3×3,64×64) Conv(3×3,64×64),3×3是卷积核大小,64×64是(输入通道数×输出通道数)
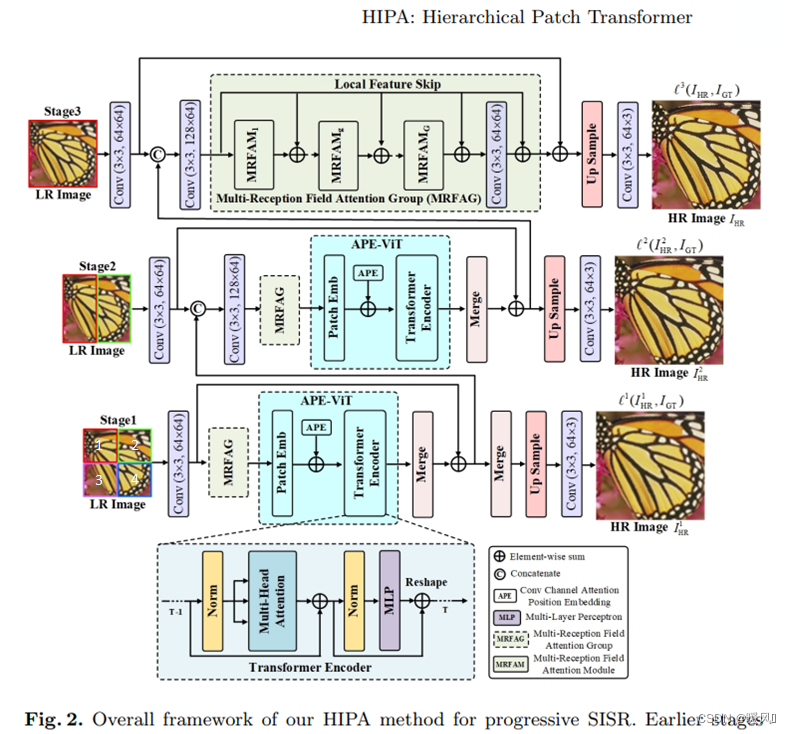
I L R I_{LR} ILR和 I H R I_{HR} IHR表示HIPA的原始LR输入和最终HR输出, I L R i , j I^{i,j}_{LR} ILRi,j表示第 i i i阶段的第 j j j个patch,例如, I L R 1 ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2735
2735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









