







文章目录
深度学习入门-从朴素感知机到神经网络
简介:深度学习入门的笔记
一、朴素感知机
1.感知机
收多个信号,输出一个信号。如图2-1是一个接受两个输入信号的感知机。
 图2-1
图2-1
x1,x2是输入信号,y是输出信号,w1,w2是权重。而图中的⚪表示“神经元”或“节点”。输入信号被送往神经元时,会被分别乘以固定的权重(w1x1、w2x2)。神经元会计算传送过来的信号的总和,只有当这个总和超过 了某个界限值时,才会输出1。这也称为“神经元被激活”。这里将这个界 限值称为阈值,用符号θ表示。 用式子表示如图2-2
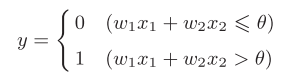 图2-2
图2-2
2.感知机实践
接下来让我们用感知机实现一些东西,体会一下什么是感知机。
2.1首先是与门:
与门即00输出0,01输出0,10输出0,11输出1。x1,x2是输入信号,只要稍微尝试不用什么技巧我们就可以确定w1=0.6,w2=0.6,θ=1使图2-1的感知机变为与门。而且有无数种这样的数值组使之成为与门。
2.2与非门和或门:
与非门即00输出1,10输出1,01输出1,11输出0。同样包括w1=-0.2,w2=-0.2,θ=-0.3在内的无数种。
或门即00输出0,10输出1,01输出1,11输出1。同样包括w1=0.2,w2=0.2,θ=0.1在内的无数种。
我们可以简化一下图2-2的式子,将其变为如下所示
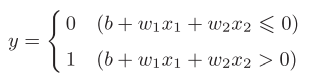 图2-3
图2-3
我们将移过来的b称为偏置。如此我们可以很容易用代码实现与门、与非门、或门
import numpy as np
def AND(X):#与门
W = np.array([0.5, 0.5])
b = -0.7
tmp = np.sum(W * X) + b
if tmp <= 0:
return 0
else:
return 1
def OR(X):#或门
W = np.array([0.2, 0.2])
b = -0.1
tmp = np.sum(W * X) + b
if tmp <= 0:
return 0
else:
return 1
def NAND(X):#与非门
W = np.array([-0.2, -0.2])
b = 0.3
tmp = np.sum(W * X) + b
if tmp <= 0:
return 0
else:
return 1
x = np.array([1,1])
print(AND(x))
print(NAND(x))
print(OR(x))
2.3我们通过改变权重和偏执很容易得到不同的感知机,那么我们思考下如何实现异或门。
异或门即00输出0,11输出0,01输出1,10输出1,答案是无法实现。
我们看一下或门的实现,b=-0.5,w1=1.0,w2=1.0。其感知机表达式将参数带入图2-3可以得到图2-4的式子
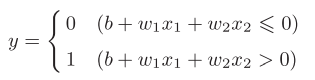 图2-4
图2-4
如此,我们可以画出一条直线x1+x2=0.5分割两个输出,如下图2-5所示,在直线上面输出为1在直线下面输出为0。
 图2-5
图2-5
那异或门的图像是怎样的呢?如下图2-6所示,曲线下方输出1,曲线上方输出0。
 图2-6
图2-6
3.多层感知机
我们换一种思路,利用我们已经获得的知识。即用与门、或门、与非门拼出一个异或门。

图2-7
如下所示,只要稍微尝试就能画出来
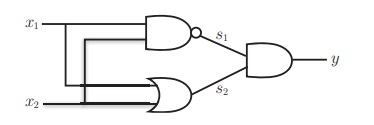 图2-8
图2-8
如此我们可以画出感知机的样子如图2-9
 图2-9
图2-9
如图2-9所示的叠加了多层的感知机我们称为多层感知机。实际上通过叠加层,我们可以通过模块化思想用2层感知机实现一个计算机,大家可以尝试阅读一本书下《计算机系统要素:从零开始构建现代计 算机》,它可以帮助我们认识到我们学的计算机到底是什么。
二、神经网络
1.从感知机到神经网络

图3-1
如图就是一个简单神经网络,和感知机很像吧,我们把中间层也成为隐藏层。上一章我们通过确定参数用感知机实现了与门、或门、与非门、异或门,但是当实现的功能更复杂时寻找合适的参数就会变得十分困难,而神经网络的出现很好的解决了这样的问题,它可以通过“学习”自己寻找合适的参数,这个寻找参数的过程我们称之为“神经网络的学习”。
1.1.感知机简化:我们可以很容易的把感知机的数学式换成更简单的样子,也就是从图3-1换成图3-2进而得到图3-3。
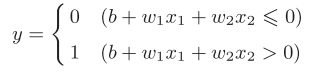 图3-1
图3-1
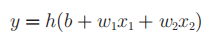 图3-2
图3-2
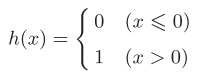 图3-3
图3-3
2.激活函数
由图3-3得到的h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数。
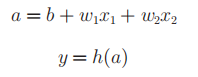
此时我们可以很明确表现出其“激活”功能。
图3-3的激活函数以阈值为界,一旦超过阈值就切换输出,我们称这种函数为阶跃函数。激活函数是感知机与神经网络的桥梁,我们把阶跃函数替换为其他函数,就可以进入神经网络的世界了。
3.sigmoid函数:
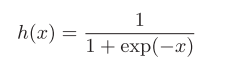 图3-4
图3-4
exp(-x)表示e的-x次幂。我们用代码实现一下sigmoid函数并给他画出来
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x): #即使输入数组也可以,广播功能
return 1/(1+np.exp(-x))
x=np.arange(-5.0,5.0,0.1)
y=sigmoid(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1) #指定y轴范围
plt.show()
我们可以看到图3-5
 图3-5
图3-5
对比下阶跃函数和sigmoid函数如图3-6

图3-6
很容易看出sigmoid更平滑,其平滑性的作用会在神经网络的学习中体现出来。注意到两者都是非线性函数,神经网络的激活函数智能用非线性函数,因为用线性函数神经网络加深层数就没有意义了,大家可以思考一下为什么。
4.三层神经网络

图3-7
为什么说三层,因为最左边那层x1x2我们称为第0层,接下来我们用numpy来实现一下图3-7的3层神经网络。
4.1符号

图3-8
我们加入偏执

图3-9
我们可以得到式子如图3-10
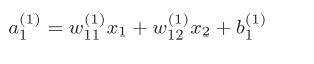
图3-10
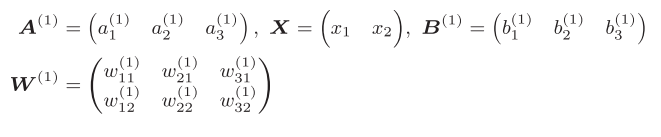
图3-11
如果我们用矩阵则可以表示为A=XW+B,我们假设参数为任意值用代码实现从第0层到第一层的传递
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
X = np.array([1.0,0.5])
W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
B1 = np.array([0.1,0.2,0.3])
A1 = np.dot(X,W1)+B1
Z1 = sigmoid(A1)
print(A1)
print(Z1)
第一层到第二层同理,而第三层到第四层也就是输出层我们将恒等函数作为激活函数。也就是indentity_function
代码实现三层神经网络如下:
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
def identity_function(x):
return x
def ini_work():
network = {}
network['W1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5],[0.3,0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network,x):
W1,W2,W3 =network['W1'],network['W2'],network['W3']
b1,b2,b3 =network['b1'],network['b2'],network['b3']
a1 = np.dot(x,W1)+b1
z1 = sigmoid(a1);
a2 = np.dot(z1,W2)+b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3)+b3
y = identity_function(a3)
return y
network = ini_work();
x = np.array([1.0,5.0])
y = forward(network,x)
print(y)
5.输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出 层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。
6.恒等函数和softmax函数
如图3-12为softmax函数
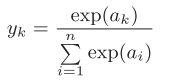
图3-12
softmax函数作为输出函数输出层的各个神经元都受到所有输入信号的影响。为了防止溢出我们改进为图3-13。通常把C‘设置为信号量的最大值也就是ai中最大的一个。

图3-13
用代码实现一下
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a-c)
sum_exp_a = np.sum(exp_a)
y = exp_a/sum_exp_a
return y
a = np.array([0.3,2.9,4.0])
y = softmax(a)
print(y)
print(np.sum(y))
此段代码运行结果如图3-14

图3-14
如上所示,softmax函数的输出是0.0到1.0之间的实数。并且,softmax 函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正因为有了这个性质,我们才可以把softmax函数的输出解释为“概率”。
即便使用了softmax函数,各个元素之间的大小关 系也不会改变。这是因为指数函数(y = exp(x))是单调递增函数。
求解机器学习问题的步骤可以分为“学习”A和“推理”两个阶段。首 先,在学习阶段进行模型的学习,然后在推理阶段,用学到的模型对未知的数据进行推理(分类)。如前所述,推理阶段一般会省略输出层的softmax函数。在输出层使用 softmax函数是因为它和 神经网络的学习有关系。
关于输出层神经元的数量对于分类问题一般和类别数量一样。















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









