








目录
本文面向CNN小白,实现了一个CNN里的"Hellow world"。需要一点点深度学习基础就能看懂,零基础请参考我的深度学习入门笔记。
顺序:
- 深度学习入门-从感知机到神经网络:从零开始认识什么是神经网络。
- 神经网络的学习-搭建神经网络实现mnist手写数据集识别:手敲一个神经网络识别mnist数据集
- 误差反向传播-bp算法思想实现mnist手写数据集识别:使用误差反向传播算法,提速训练
- 深度学习入门-ANN神经网络参数优化问题:介绍优化神经网络的一些方法
- 基于卷积神经网络实现mnist手写数据集识别:就是本文
本文是基于《深度学习入门》所写的笔记,这一章用到的所有代码会在文章末尾分享。
一、CNN理论
1. CNN结构
在之前的章节中使用的神经网络相邻层的所有神经元之间都有连接,称为全连接神经网络。相比于全连接神经网络,卷积神经网络多了卷积层convolution和池化层pooling。具体结构如下:
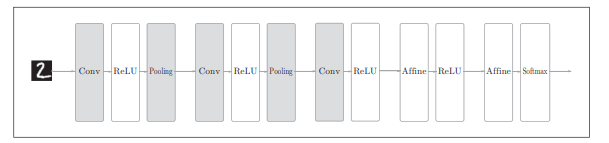
2. 卷积层
简单说,全连接层忽略了图片的形状,图片在计算机上存储是三维的,不仅有长宽高还有通道,通道就是第三维,而前面的例子中将三维的图片(1,28,28)看作一维(784 , ),忽略了图片的一些重要信息,卷积层和池化层的存在就是为了提取这些信息。
2.1 卷积运算
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z5RFEmMI-1645618177087)(卷积神经网络代码实现.assets/C-4.png)]](https://img-blog.csdnimg.cn/077d25fdef734e70be536440fbfa1175.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
上图中,输入数据是(1,4,4)也就是一个通道,4x4大小。滤波器同理(1,3,3)。那如何得出结果的呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XcR7JTza-1645618177088)(卷积神经网络代码实现.assets/C-5.png)]](https://img-blog.csdnimg.cn/90fce08784de485fa05f20fc08ec20dc.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
如上图就是卷积运算。滤波器与输入数据对应元素的积的和为输出的一个元素。注意不是矩阵乘法是普通的乘。
2.2 填充
使用填充主要是为了调整输出的大小。比如,对大小为(4, 4)的输入 数据应用(3, 3)的滤波器时,输出大小变为(2, 2),相当于输出大小 比输入大小缩小了 2个元素。这在反复进行多次卷积运算的深度网络中会成为问题。如果输出大小为1那就无法卷积运算了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wnNl98Qm-1645618177088)(卷积神经网络代码实现.assets/C-6.png)]](https://img-blog.csdnimg.cn/202d99680c2245d8866aeaa6803293d8.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
上图是对数据进行幅度为1的填充,默认填充0。
2.3 步幅
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N7bUzN9S-1645618177089)(卷积神经网络代码实现.assets/C-7.png)]](https://img-blog.csdnimg.cn/b9a751cf19d74ac592bda55390a006fd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
一张图片很好理解,就是滤波器在输入数据上滑动的距离。
2.4 三维数据的运算

如上图所示,每个通道上进行卷积运算,每个通道上的运算结果相加。注意输出仍然是一个通道。
2.5 多滤波器
我们结合方块来思考,注意图中各个参数名称,会用在代码里。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-22pn8e6m-1645618177090)(卷积神经网络代码实现.assets/C-10.png)]](https://img-blog.csdnimg.cn/3e175689a8dc4a6d9cce6bbfd71c4357.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
如果我们想输入也要变成多通道的呢,只要加滤波器就行了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cCWOh4E6-1645618177091)(卷积神经网络代码实现.assets/c-11.png)]](https://img-blog.csdnimg.cn/5b05fd5cb7784591ade675aca90947ea.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
一个滤波器对应一个输出通道。如果再加上偏置,就会变成这样
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k7i013pw-1645618177091)(卷积神经网络代码实现.assets/C-12.png)]](https://img-blog.csdnimg.cn/509eb009a99c4990bf5ab97b7abea26d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
2.6 批处理
在以前的章节我们用了mini_batch,同样的道理,一次性处理多个数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aE2fyOmI-1645618177092)(卷积神经网络代码实现.assets/C-13.png)]](https://img-blog.csdnimg.cn/a598806ef27c47ae99a0ff098dfcb6b3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
一定要熟悉这些个"方块"下面的参数,这是理解代码的关键,自己带入数据手算一些会很有感觉。
3. 池化层
池化层很好理解,如图是进行了2x2步幅为2的max池化。就是选择2x2中最大的数据作为输出,通常情况下池化层"滤波器"的size和步幅一样。(池化层并没有滤波器,只是我很难给它取一个好听的名字,一定注意它和滤波器可以不一样大小)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TPyaJUHr-1645618177092)(卷积神经网络代码实现.assets/C-14.png)]](https://img-blog.csdnimg.cn/720c31a96c764da4ab413a2d662fd052.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
理论部分说完了,大家根据代码继续理解。
二、CNN实现
1. im2col原理与代码
如前面大家看到的,CNN传递的是四维数据(N,C,H,W)。直接进行四维的运算很麻烦而且不容易理解。下面我们介绍一个简单的方法(只要理解维度的转换就很简单,不理解会有一点小难)。
如何避免四维运算呢?直接把四维变成二维:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CMk8blgs-1645618177093)(卷积神经网络代码实现.assets/C-15.png)]](https://img-blog.csdnimg.cn/9a7f7541b17049cdb1a0ff3719e24b0d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
上图的例子是三维转成二维,四维也是一样的,只是我们画不出来四维图像。下面这个图更清晰:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1qeNT6op-1645618177093)(卷积神经网络代码实现.assets/C-16.png)]](https://img-blog.csdnimg.cn/3d913df25d2e4a7ba833da3f5ae9f16f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
展开过程详解:
上图左面的我们成为输入数据,右边称为展开图
输入数据我们知道是四维(N,C,H,W),上图是N=1的情况,多批数据也是一样的,输入数据展开后接到这个展开图后面就行。总之,展开图维度与数据批数无关,是二维的。
以N=1为例子:
在理论部分我们知道,滤波器高和长为H,W,通道为C。展开的过程就是将一个C x H x W 的三维数组里面的元素展开为一维数组,元素的个数和值并不变。所谓 C x H x W可以称为:每个通道上一个该位置滤波器大小的所有元素。
相信大家有了初步的理解,下面我们结合代码来深入理解一下,代码中有大量注释,大家可以多用数据做测试,debug一下看一看循环结果就会容易理解。注意:transpose轴变换我们可以简单的理解为改变多维数组索引的顺序,暂时不要看一些轴变换的图,不好理解。比如原来数组a.shape=(N,C,H,W),tranpose(0,3,1,2)后变成a.shape=(N,H,W,C)。
轴变换前:a[N=0,C=1,H=2,W=3] = 1
轴变换后:a[N=0,H=2,W=3,C=1] = 1
下面开始看代码
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据
filter_h : 滤波器的高
filter_w : 滤波器的长
stride : 步幅
pad : 填充
Returns
-------
col : 2维数组
"""
N, C, H, W = input_data.shape#N 是数据个数 C 是通道数 H 是高 W 是长
out_h = (H + 2*pad - filter_h)//stride + 1 #计算输出数据 即输出特征图 out_h 输出特征图高
out_w = (W + 2*pad - filter_w)//stride + 1#计算输入数据 即输入特征特 out_w 输出特征图长
# // 整除
img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')
#np.pad 填充数组input_data
#constant_values没有赋值,默认填充0
#第一维度(shape[0])前面填充0个后面填充0个
#第二维度同理(0,0),第三第四维度同理(pad,pad)
#数据量和通道默认(0,0), 咩咩咩咩咩咩咩咩,,长和高根据pad参数填充
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
# col 6维数组
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
# 一次操作取了N批C个通道上
# col 的第三维y,第四维x赋值 img第三维度y导y_max隔stride是步长,隔stride取一位,第四维度同理
# 数据批量和通道数不变的
# filter_h也会简写为FH或fh
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1)
# transpose轴变换 轴变换的目的是改变索引顺序方便reshape成想要的模样
# filter_h也会简写为FH或fh
# col.shape = (N*out_h*out_w,C*FH*FW)
return col
由于我们会用到误差反向传播,展开的数据我们要还原回去,下面直接贴上代码,是im2col的逆过程,理解了im2col这个不是问题。如果理解im2col有困难可以看一下下面这张手写图,能理解就略高这张图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c9llOtj失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j-1645188053296)(C:\Users\iu的男票\Desktop\IMG_20220218_184662915.)(C:\Users\iu的男票\Desktop\IMG_20220218_182915.jpg)]](https://img-blog.csdnimg.cn/3572db6999664d6db548a40868ac66f1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
col :
input_shape : 输入数据的形状(例:(10, 1, 28, 28))
filter_h :
filter_w
stride
pad
Returns
-------
"""
N, C, H, W = input_shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
#正好和im2col的操作相反 此时col.shape=(N,C,filter_h,filter_w,out_h,out_w)
img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
#变为未填充的模样
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]
2.卷积层与池化层的实现
代码思想和之前的误差反向传播章节一样,前面也介绍过理论,代码中有大量注释,直接看代码。
注意:前向传播和反向传播是相逆的,关于一些求导问题借鉴ReLU等以前实现的层的思想。
import numpy as np
from CNN_util import im2col,col2im
class Convolution:
def __init__(self,W ,b, stride = 1,pad =0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
# 中间数据(backward时使用)
self.x = None
self.col = None
self.col_W = None
# 权重和偏置参数的梯度
self.dW = None
self.db = None
def forward(self,x):
# FN 滤波器的个数(滤波器个数也是输出特征图通道数,但是和数据批数是无关的) C 滤波器通道数
#FH 滤波器高 FW 滤波器长 C 通道数(和滤波器通道数一样才能进行通道方向的卷积)
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int((H + 2 * self.pad - FH) / self.stride + 1)
out_w = int((W + 2 * self.pad - FW) / self.stride + 1)
#im2col四维变二维,实际上把N放在了一维度,把C放在了二维度
#im2col作为黑盒,详细见im2col讲解
#实际上im2col是把元素相乘变为矩阵相乘
col = im2col(x, FH, FW, self.stride, self.pad)
#col.shape =(N*out_h*out_w,FH*FW*C)
col_W = self.W.reshape(FN,-1).T
#col_W.shape=(FN,FH*FW*C) 转置后(FH*FW*C,FN)
#其实col_W.shape=(FN,C*FH*FW),这里提醒大家reshape是按索引顺序来的所以不能直接col_W=reshape(-1,FN)
#不过值相同所以我没有按顺序写
#矩阵乘法的规定了 滤波器通道数和输入数据通道数必须相同,否则无法相乘
out = np.dot(col,col_W) + self.b
#out.shape = (N*out_h*out_w,FN)
#out的一个元素每个通道上 一个滤波器与输入数据对应元素乘积和 的和
#行就是输出数据的一个通道上每批数据的每个元素,列就是输出数据的每个通道上的一批数据的一个元素 (一批指批处理)
out = out.reshape(N, out_h, out_w, -1).transpose(0,3,1,2)
#二维变成思维,然后再进行轴变换,把通道索引变到输出数据长索引和输出数据宽索引前面
#其实就是变成了下一层输入数据的模样,要知道本层输入数据也是(批,通道,高,长)
#此时 out.shape = (N,FN,out_h,out_w)
#本层滤波器的个数就是下一层输入数据的通道数
self.x = x
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
#根据误差反向传播思想,详细见误差反向传播章节
#与Affine层不同的此处会注释一下
FN, C, FH, FW = self.W.shape
# 与forward相反 把通道索引变在最后
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
#transpose后 dout.shape=(批,out_h,out_w,通道)
#reshape后dout.shape=(批*out_h*out_w,滤波器个数(输出通道数))
self.db = np.sum(dout, axis=0)
#在forward中加了N*out_h*out_w个b,反向传播就要加这些个dout
self.dW = np.dot(self.col.T, dout)
#反向传播矩阵求导操作 dW.shape = (FH*FW*C,FN) 这四个参数熟悉吧,就是滤波器的参数也就是W该有的参数
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
#dw换成标准形式 也就是w的输入形式
dcol = np.dot(dout, self.col_W.T)
#反向传播矩阵求导操作 dcol.shape=(批*out_h*out_w,C*FH*FW)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
#反向操作im2col
return dx
"""
dx = np.dot(dout,self.W.T)
self.dW = np.dot(self.x.T,dout)
self.db = np.sum(dout,axis=0)
"""
class Pooling:
def __init__(self,pool_h,pool_w,stride = 1,pad = 0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
self.x = None
self.arg_max = None
def forward(self,x):
N,C,H,W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
col = im2col(x,self.pool_h,self.pool_w,self.stride,self.pad)
col = col.reshape(-1,self.pool_h*self.pool_w)
#一行即是一个池化的应用区域内的值
# col.shape=(N*C*out_h*out_w,pool_h*pool_w)
arg_max = np.argmax(col, axis=1)
#最大值索引数组
out = np.max(col,axis=1)
#每行只留下最大值 max池化
out = out.reshape(N,out_h,out_w,C).transpose(0,3,1,2)
#重新reshape为四维后做轴变换调整为输入数据标准形式
self.x = x
self.arg_max = arg_max
return out
def backward(self, dout):
dout = dout.transpose(0, 2, 3, 1)
#forward的反向操作 此时dout.shape=(批,out_h,out_w,通道数)
pool_size = self.pool_h * self.pool_w
#pool_size 为im2col展开的列数
dmax = np.zeros((dout.size, pool_size))
#池化层输出是所有im2col展开行的最大值,元素的个数即为原展开行的行数
#dout.size = arg_max.size
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
#在最大值索引处赋予最大值
dmax = dmax.reshape(dout.shape + (pool_size,))
#dout.shape+pool_size是在dout的维度上又加了一个维度pool_size
#dmax.shape = (批,out_h,out_w,C,pool_size)
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
#dcol.shape = (N*out_h*out_w,C*pool_size)而pool_size = pool_h*pool_w 正式im2col的输出
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dx
4.CNN卷积神经网络的实现
我们现在实现一个三层卷积神经网络。
卷积神经网络训练速度很慢,这里第一层是卷积池化层,第二层第三层是全连接层仍然需要一个多小时的时间,所以在CNN网络中加了一个保存参数的方法。除了参数过于庞大其他和以前的全连接神经网络没有什么区别
import numpy as np
from collections import OrderedDict
from CNN_layer import Convolution,Pooling
from bp.net_layer import Affine,Relu,SoftMaxTithLoss
import pickle
"""
该网络:卷积 ReLU 池化 Affine ReLU Affine Softmax
三层网络 一个卷积层 两个全连接层
"""
class SimpleConvNet:
def __init__(self,input_dim = (1,28,28),
conv_param = {'filter_num':30,
'filter_size':5,
'pad':0,'stride':1},
hidden_size = 100,
output_size = 10,
weight_init_std = 0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2 * filter_pad)/ filter_stride+1
#conv_output_size 卷积层输出特征图的大小
pool_output_size = int(filter_num*(conv_output_size/2)*(conv_output_size/2))
"""
pooling层的实际输出是四维(N,C,out_h,out_w) 接全连接层的输入应该是(N,C*out_h*out_w)
从而应该是pool_output_size = int(1 + (conv_output_size - pool_h) / 池化层.stride)
此处算的两个算式值相同,我认为作者应该是默认了某种情况仅适用于这个例子,而注释的要更普遍一些
"""
#各层参数
self.params = {}
self.params['W1'] = weight_init_std*np.random.randn(filter_num,
input_dim[0],
filter_size,
filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std*np.random.randn(pool_output_size,
hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std*np.random.randn(hidden_size,
output_size)
self.params['b3'] = np.zeros(output_size)
#向有序字典中按顺序写入各个层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'],
self.params['b1'],
conv_param['stride'],
conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2,pool_w=2,stride = 2)
self.layers['Affine1'] = Affine(self.params['W2'],
self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'],
self.params['b3'])
self.last_layer = SoftMaxTithLoss()
def predict(self,x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self,x,t):
y = self.predict(x)
return self.last_layer.forward(y,t)
#bp求梯度
def gradient(self,x,t):
#向前传播
self.loss(x,t)
#backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
#反向传播交换顺序
for layer in layers:
dout = layer.backward(dout)
#设定
grads = {}
grads['W1'] = self.layers['Conv1'].dW
grads['b1'] = self.layers['Conv1'].db
grads['W2'] = self.layers['Affine1'].dW
grads['b2'] = self.layers['Affine1'].db
grads['W3'] = self.layers['Affine2'].dW
grads['b3'] = self.layers['Affine2'].db
return grads
#计算正确率
def accuracy(self,x ,t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t,axis=1)#获得正确解索引array
acc = 0.0
for i in range(int(x.shape[0]/batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y,axis=1)
acc += np.sum(y==tt)
return acc/x.shape[0]
#一般电脑训练这个网络需要一个小时,所以保存训练结果节省时间
def save_parms(self,file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
#加载训练结果
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
大家可能注意到一个问题,池化层实现中我们写的代码,其输出是四维数据,而全连接层的输入数据是二维数据,他们是怎么连接的呢?这里我们需要修改一下我们以前实现的全连接层也就死Affine,其实就改了两行,把四维数据变为二维数据,但是要保存原始的shape,反向椽笔的时候还要变回去,代码如下:
class Affine:
def __init__(self,W,b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
self.original_shape = None
def forward(self,x):
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x,self.W) + self.b
return out
def backward(self,dout):
dx = np.dot(dout,self.W.T)
self.dW = np.dot(self.x.T,dout)
self.db = np.sum(dout,axis=0)
dx = dx.reshape(*self.original_x_shape)
return dx
同时相对于以前实现的SoftMaxTithLoss我们也需要修改一下,因为正确解标签我们并不会把他展开为one-hot数组了。
class SoftMaxTithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward(self,x,t):
self.t = t
self.y = softmax(x)
self.loss =cross_entropy_error(self.y,self.t)
return self.loss
def backward(self,dout = 1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else: #非one-hot-vector是一维数组元素值为正确标签
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1 #每个输出的正确解索引减1
dx = dx / batch_size
return dx
这样的SoftMaxTithLoss可以适用于所有情况了。
5. 训练CNN
搭建好网络后我们开始训练了(load_mnist是加载数据用的,会分享给大家,大家直接用就行):
import numpy as np
from simpleConvNet import SimpleConvNet
from deeplearning.mnist import load_mnist
from learning_idea.optimizer import Adam
import matplotlib.pyplot as plt
(x_train,t_train),(x_test,t_test) = load_mnist(flatten=False)
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
"""
epoch 全覆盖次数
mini_batch_size 批处理数据数
train_size 训练数据数
iter_per_epoch 一次全覆盖批处理次数
max_iter 整个训练批处理次数
optimizer 梯度更新选择Adam算法
current_epoch 目前进行的epoch次数
"""
epoch = 20
mini_batch_size = 100
train_size = x_train.shape[0]
iter_per_epoch = max(train_size/mini_batch_size,1)
iter_per_epoch = int(iter_per_epoch)#变为整数
max_iter = epoch*iter_per_epoch
optimizer = Adam(lr = 0.001)
current_epoch = 0
"""
画图参数
"""
train_loss_list = []
train_acc_list = []
test_acc_list = []
print("开始训练请等待...")
for i in range(max_iter):
batch_mask = np.random.choice(train_size,mini_batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch,t_batch)
grads = optimizer.update(network.params,grads)
loss = network.loss(x_batch,t_batch)
train_loss_list.append(loss)
if i %iter_per_epoch==0 :
current_epoch += 1
#取1000个数据计算正确率(节省时间)
x_train_simple,t_train_simple = x_train[:1000],t_train[:1000]
x_test_sample,t_test_sample = x_test[:1000],t_test[:1000]
train_acc = network.accuracy(x_train_simple,t_train_simple)
test_acc = network.accuracy(x_test_sample,t_test_sample)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("=== epoch : "+str(current_epoch)+", train acc:"+str(train_acc)+",test acc:"+str(test_acc)+" ===")
network.save_parms("params.pkl")
print("训练结束,您的损失函数值已经降低到"+str(train_loss_list[-1])+"下面开始作图")
"""
画图
"""
plt.figure("loss")
x = np.arange(len(train_loss_list))
y = np.array(train_loss_list)
plt.plot(x,y)
plt.xlabel("mini_batch")
plt.ylabel("loss")
plt.figure("accuracy")
x = np.arange(len(train_acc_list))
y1 = np.array(train_acc_list)
y2 = np.array(test_acc_list)
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.plot(x,y1,label="train_accuracy")
plt.plot(x,y2,label="test_accuracy")
plt.legend()
plt.show()
运行结果:
开始训练请等待…
=== epoch : 1, train acc:0.27,test acc:0.217 ===
=== epoch : 2, train acc:0.956,test acc:0.958 ===
=== epoch : 3, train acc:0.976,test acc:0.979 ===
=== epoch : 4, train acc:0.98,test acc:0.979 ===
=== epoch : 5, train acc:0.983,test acc:0.983 ===
=== epoch : 6, train acc:0.984,test acc:0.986 ===
=== epoch : 7, train acc:0.985,test acc:0.986 ===
=== epoch : 8, train acc:0.989,test acc:0.988 ===
=== epoch : 9, train acc:0.988,test acc:0.984 ===
=== epoch : 10, train acc:0.998,test acc:0.988 ===
=== epoch : 11, train acc:0.994,test acc:0.984 ===
=== epoch : 12, train acc:0.994,test acc:0.991 ===
=== epoch : 13, train acc:0.995,test acc:0.991 ===
=== epoch : 14, train acc:0.996,test acc:0.986 ===
=== epoch : 15, train acc:0.997,test acc:0.989 ===
=== epoch : 16, train acc:0.996,test acc:0.987 ===
=== epoch : 17, train acc:0.997,test acc:0.988 ===
=== epoch : 18, train acc:0.999,test acc:0.989 ===
=== epoch : 19, train acc:0.998,test acc:0.987 ===
=== epoch : 20, train acc:0.999,test acc:0.984 ===
训练结束,您的损失函数值已经降低到4.546342118420302e-05下面开始作图
Process finished with exit code 0
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nRMY0bfM-1645618177094)(卷积神经网络代码实现.assets/C-1.png)]](https://img-blog.csdnimg.cn/d6574369071849bb834b6b6b1f209ce8.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C6JLZywW-1645618177094)(卷积神经网络代码实现.assets/C-2.png)]](https://img-blog.csdnimg.cn/677b4ad194834cb8996d72d5c15ea19a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rOl562-,size_20,color_FFFFFF,t_70,g_se,x_16)
看结果很棒,损失函数值已经下降到非常低的地步,也没有发生过拟合。而前一千个数据训练正确率达到了0.999,测试正确率达到了0.984。
至此,我们搭建了一个三层卷积神经网络实现了mnist手写数据集的识别。















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









