






这一章的内容是讲解如何训练模型,并且将训练的模型更新部署到CARLA模拟器中。模型训练的代码是python写的,使用pytorch框架。
模型训练的工程在carla_data/carla_waypoint文件夹内。
1读取数据,制作索引
首先将训练集和测试集数据索引读取并保存到json文件中。
1.1 打开工程
pycharm打开文件夹carla_data/carla_waypoint,如图所示
读取数据制作索引的程序为to_coco文件下的to_coco.py,打开如下图所示。
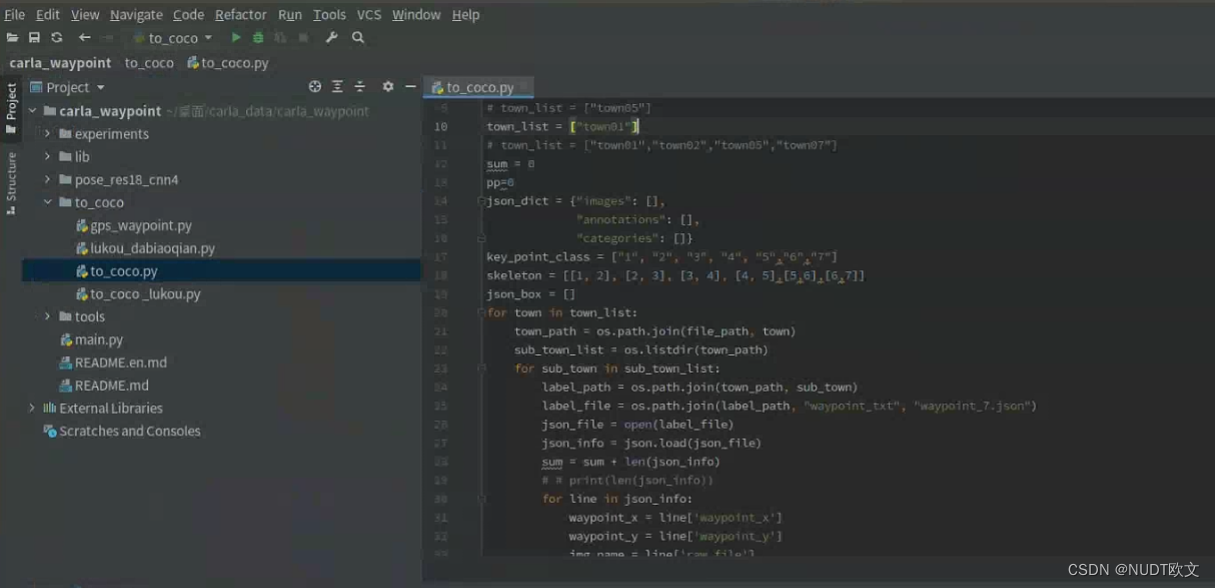
1.2 制作训练集索引的json文件
(1)代码第8行路径改成自己训练集所在的路径(即数据中的train2017)。
file_path = "/media/wrc/a6a69390-c76b-42fa-8d81-6ef8474db793/home/a/open-data/final_data/carla_1257/images/train2017/"
(2)修改代码第9行,选择想要用于训练的数据集城镇
town_list = ["town01"] #训练集`train2017`目录下有多哪些城镇就在这里选择,如果多个则写成这样:town_list = ["town01","town02","town07"]
(3)修改代码第98行,更改保存json文件的路径和文件名
with open("/media/wrc/a6a69390-c76b-42fa-8d81-6ef8474db793/home/a/open-data/final_data/carla_1257/annotations/person_keypoints_train2017.json", 'w') as w: #训练集用train表示
注意,保存的文件名为person_keypoints_train2017.json期中train2017表示训练集。此外,保存的路径在annotations(必须是这个名字)文件夹下(这个文件夹和images(数据集)文件夹并列),如果没有该文件夹则新建一个。
(4)确认上述步骤修改好后运行程序,运行成功即输入数据集的样本数量,如下:
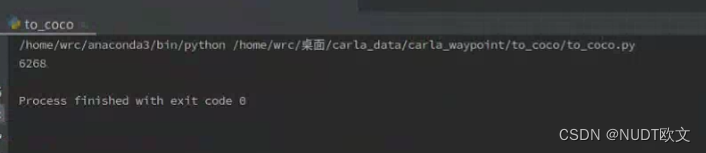
成功后即可在annotations文件夹下出现训练集的json文件。
1.3 制作测试集索引的json文件
测试集的制作过程和训练集的一样,就是路径和保存文件的名称不一样。
(1)代码第8行路径改成自己测试集所在的路径(即数据中的val2017)。
file_path = "/media/wrc/a6a69390-c76b-42fa-8d81-6ef8474db793/home/a/open-data/final_data/carla_1257/images/val2017/"
(2)修改代码第9行,选择想要用于训练的数据集城镇
town_list = ["town05"] #训练集`val2017`目录下有多哪些城镇就在这里选择,如果多个则写成这样:town_list = ["town01","town02","town07"]
(3)修改代码第98行,更改保存json文件的路径和文件名
with open("/media/wrc/a6a69390-c76b-42fa-8d81-6ef8474db793/home/a/open-data/final_data/carla_1257/annotations/person_keypoints_val2017.json", 'w') as w: #测试集用val表示
注意,保存的文件名为person_keypoints_val2017.json期中val2017表示训练集。此外,保存的路径在annotations(必须是这个名字)文件夹下(这个文件夹和images(数据集)文件夹并列),如果没有该文件夹则新建一个。
(4)确认上述步骤修改好后运行程序,运行成功即输入数据集的样本数量
2训练模型
2.1打开程序
模型训练的代码为tools文件夹下的train.py,打开如图所示:
2.2设置配置参数
修改第49行选择配置文件。
default="/home/wrc/owx/carla_fist/experiments/carla/Res18_cnn4.yaml",
这个Res18_cnn4.yaml文件就是整个程序的配置文件,文件的位置在/experiments/carla/下,该目录还有其他配置文件,可以保存自己的不同配置,方便后期快速更换。
打开Res18_cnn4.yaml,文件中有许多项参数,重点更改关注下列参数。
(1)选择用于训练的GPU编号——代码第7行:
GPUS: (0,) #GPU编号,只有一张卡时必须有这个逗号
如果只有一张显卡,则该显卡编号为0,如果有多张可以写成:
GPUS: (0,1,2) #GPU编号
(2)模型和训练记录的保存名称——代码第8、9行:
OUTPUT_DIR: 'pos_res18_cnn4' #保存训练好的模型的文件夹名称(改成自己想要的名称)
LOG_DIR: 'pos_res18_cnn4_log' #记录训练过程的文件夹名称(改成自己想要的名称)
(3)预测的导引点的数量——代码第11行:
PRINT_FREQ: 10 #预测导引点个数(暂时无需修改)
(4)数据集的路径——代码第15~17行:
ROOT: '/media/wrc/a6a69390-c76b-42fa-8d81-6ef8474db793/home/a/open-data/final_data/carla_1257/' #数据集所在目录(改成自己的)
TEST_SET: 'val2017' #测试机(无需修改)
TRAIN_SET: 'train2017'#训练集(无需修改)
(5)使用的框架模型——代码第23行:
NAME: pose_res18_cnn4 #目前选择这个(暂时不修改),还有许多模型供选择,在lib/modles/文件夹下
(6)训练过程参数设置——代码第52~68行(暂时只介绍重点的)。
第53行:
BATCH_SIZE_PER_GPU: 32 #训练批次大小
如果GPU内存不够就改小一点。
(7)测试过程参数设置——代码第69~81行(暂时只介绍重点的)。
第70行:
BATCH_SIZE_PER_GPU: 32 #训练批次大小
如果GPU内存不够就改小一点。(建议和(6)中训练过程的大小一样)
2.3 运行程序
上述配置更改后直接运行程序即可开始训练模型,运行成功界面如下:
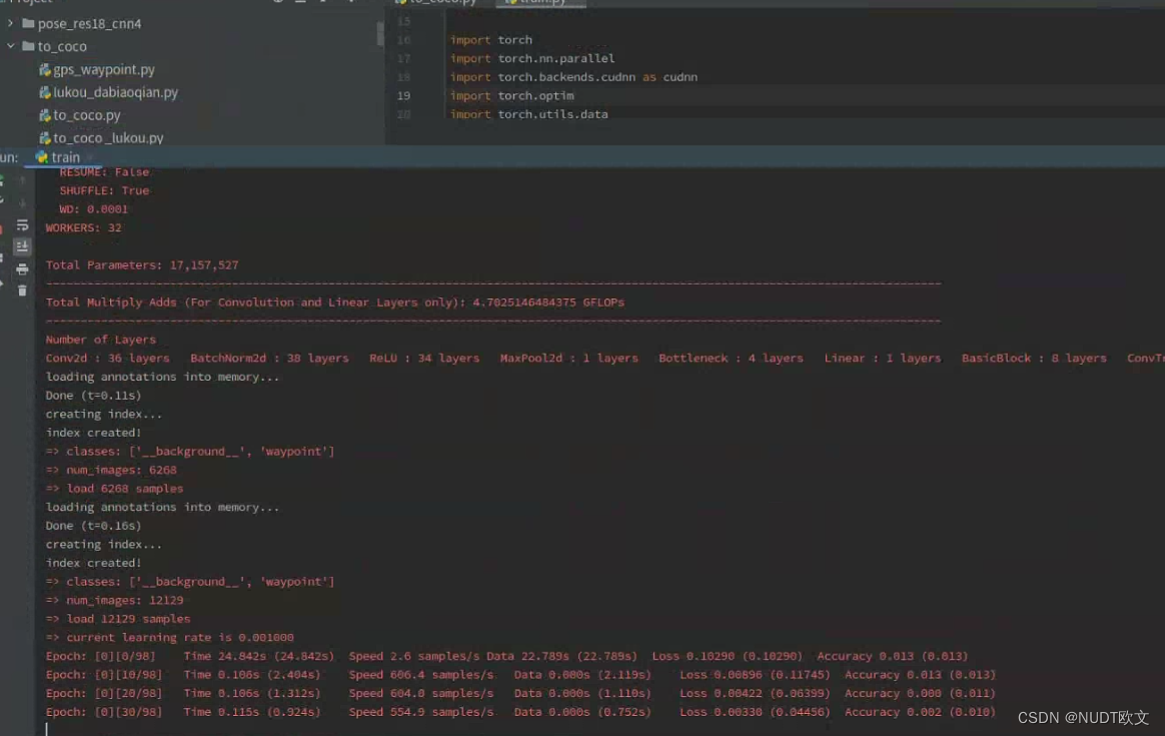
如果有报错,看是不是缺库,如果缺请安装(pip install XXX)。
3 模型部署
3.1 训练好的.pth模型
训练好的模型保存在2.2(2)中参数设置的名称的文件夹下,例如:
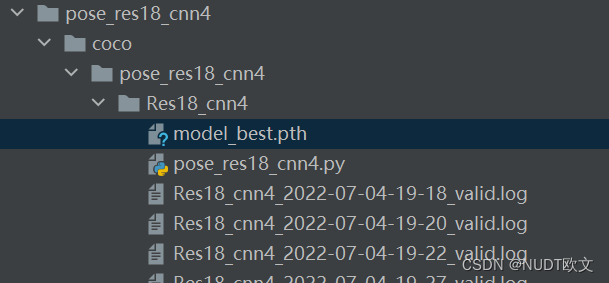
打开该文件找到model_best.pth,这就是训练好的模型。
3.2 将.pth模型转换为.onnx模型
(1)打卡程序
转化代码为tools文件夹下的torch2onnx.py文件。打开如下:
(2)修改路径
第20行,选择配置文件,该文件要和上面训练模型时所选的文件是同一个
default="/home/wrc/xujinjiang/project/TokenPose_1257_7/experiments/carla/Res18_cnn4.yaml",
第29行,模型所在的文件夹路径(即3.1所示的文件夹)
default='/home/wrc/xujinjiang/project/TokenPose_1257_7/Seed_42/pose_res18_cnn4'#换成自己的
第46行,模型的路径(即3.1所示的.pth模型路径)
model_state_file = "/home/wrc/xujinjiang/project/TokenPose_1257_7/Seed_42/pose_res18_cnn4/coco/pose_res18_cnn4/Res18_cnn4/model_best.pth"
第55行,保存转换成的.onnx模型的路径和名称。
torch.onnx.export(model,(input1, input2), '/home/wrc/桌面/res18_cnn4_carla.onnx',
第59行,可视化保存的.onnx模型的结构。运行该步骤需要下载netron库,该步骤可以不用,直接注释掉该代码就可以。
netron.start('/home/wrc/桌面/res18_cnn4_carla.onnx')
(3)运行
上述设置完毕后运行,如果缺乏库报错就安装,运行成功后就可以得到.onnx模型,之后按照前面博客所写的步骤,用tensorRT将.onnx模型转换成.engine模型,转换成功后即可用到C++程序中(前面博客)














 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









