







1.coco数据集格式
MC COCO2017年主要包含以下四个任务:目标检测与分割、图像描述、人体关键点检测,如下所示:
annotations: 对应标注文件夹
├── instances_train2017.json : 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json : 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json : 对应图像描述的训练集标注文件
├── captions_val2017.json : 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json : 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json : 对应人体关键点检测的验证集标注文件夹
Object segmentation : 目标级分割
Recognition in context : 图像情景识别
Superpixel stuff segmentation : 超像素分割
330K images (>200K labeled) : 超过33万张图像,标注过的图像超过20万张
1.5 million object instances : 150万个对象实例
80 object categories : 80个目标类别
91 stuff categories : 91个材料类别
5 captions per image : 每张图像有5段情景描述
250,000 people with keypoints : 对25万个人进行了关键点标注
""" 注意 """
COCO数据集格式中,bbox 的保存格式为 [x, y, w, h]
如果需要转换为[x1,y1,x2,y2],可以通过如下进行转换
bbox = [x1, y1, x1 + w - 1, y1 + h - 1]
JSON文件的基本格式,以实例分割为例,主要有五个部分:info、licenses、images、annotations、categories

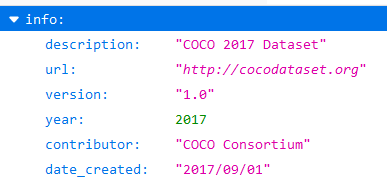
- info记录关于数据集的一些基本信息
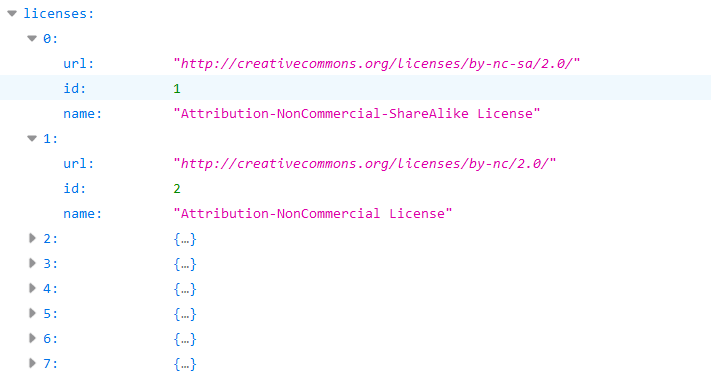
2.licenses是数据集遵循的一些许可
3.images是数据集中包含的图像,长度等于图像的数量

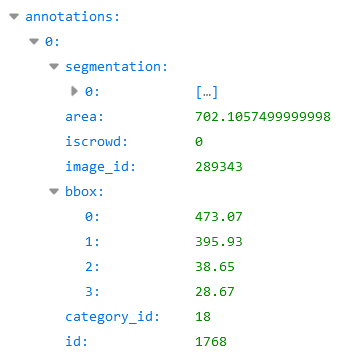
4.annotations字段是包含多个annotation实例的一个数组,annotation类型本身又包含了一系列的字段,如这个目标的category id和segmentation mask。segmentation格式取决于这个实例是一个单个的对象(即iscrowd=0,将使用polygons格式)还是一组对象(即iscrowd=1,将使用RLE格式)。
注意,单个的对象(iscrowd=0)可能需要多个polygon来表示,比如这个对象在图像中被挡住了。而iscrowd=1时(将标注一组对象,比如一群人)的segmentation使用的就是RLE格式。每个对象(不管是iscrowd=0还是iscrowd=1)都会有一个矩形框bbox ,矩形框左上角的坐标和矩形框的长宽会以数组的形式提供,数组第一个元素就是左上角的横坐标值。
area是area of encoded masks,是标注区域的面积。如果是矩形框,那就是高乘宽;如果是polygon或者RLE,那就复杂点。
最后,annotation结构中的categories字段存储的是当前对象所属的category的id,以及所属的supercategory的name。
polygon格式比较简单,这些数按照相邻的顺序两两组成一个点的xy坐标,如果有n个数(必定是偶数),那么就是n/2个点坐标。
polygon与mask之间的转换
import cv2
def mask2polygon(mask):
contours, hierarchy = cv2.findContours((mask).astype(np.uint8), cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
# mask_new, contours, hierarchy = cv2.findContours((mask).astype(np.uint8), cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
segmentation = []
for contour in contours:
contour_list = contour.flatten().tolist()
if len(contour_list) > 4:# and cv2.contourArea(contour)>10000
segmentation.append(contour_list)
return segmentation
def polygons_to_mask(img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
polygons = np.asarray(polygons, np.int32) # 这里必须是int32,其他类型使用fillPoly会报错
shape=polygons.shape
polygons=polygons.reshape(shape[0],-1,2)
cv2.fillPoly(mask, polygons,color=1) # 非int32 会报错
return maskCOCO数据集的RLE都是uncompressed RLE格式(与之相对的是compact RLE)。 RLE所占字节的大小和边界上的像素数量是正相关的。RLE格式带来的好处就是当基于RLE去计算目标区域的面积以及两个目标之间的unoin和intersection时会非常有效率。 上面的segmentation中的counts数组和size数组共同组成了这幅图片中的分割 mask。其中size是这幅图片的宽高,然后在这幅图像中,每一个像素点要么在被分割(标注)的目标区域中,要么在背景中。很明显这是一个bool量:如果该像素在目标区域中为true那么在背景中就是False;如果该像素在目标区域中为1那么在背景中就是0。对于一个240x320的图片来说,一共有76800个像素点,根据每一个像素点在不在目标区域中,我们就有了76800个bit,比如像:00000111100111110...;但是这样写很明显浪费空间,于是coco数组中用1的起始位置和length组成
RLE与mask之间的转换:
def mask2rle(img):
'''
img: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels= img.T.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)
def rle2mask(rle, input_shape):
width, height = input_shape[:2]
mask= np.zeros( width*height ).astype(np.uint8)
array = np.asarray([int(x) for x in rle.split()])
starts = array[0::2]
lengths = array[1::2]
current_position = 0
for index, start in enumerate(starts):
mask[int(start):int(start+lengths[index])] = 1
current_position += lengths[index]
return mask.reshape(height, width).T计算mask的bbox
def bounding_box(img):
# return max and min of a mask to draw bounding box
rows = np.any(img, axis=1)
cols = np.any(img, axis=0)
rmin, rmax = np.where(rows)[0][[0, -1]]
cmin, cmax = np.where(cols)[0][[0, -1]]
return rmin, rmax, cmin, cmaxcategories是一个包含多个category实例的数组,而category结构体描述如下:

参考:
COCO数据集格式解析_ViatorSun的博客-CSDN博客_coco数据集格式

















 3239
3239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











