






import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 选择模型版本,你可以选择 'gpt2' (即 'gpt2', 'gpt2-medium', 'gpt2-large', 或 'gpt2-xl')
model_name = 'gpt2-medium'
# 案例描述:Transformers库中的GPT-2模型,并用它实现下一词预测功能,即预测一个未完成句子的下一个可能出现的单词。
# 下一词预测任务是一个常见的任务,在Transformers库中有很多模型都可以实现该任务。也可以使用BERT模型来实现。选用GPT-2模型,主要在于介绍手动加载多词表文件的特殊方式。
# 加载分词器
tokenizer = GPT2Tokenizer.from_pretrained(model_name) # 自动加载改名后的文件
# 编码输入
indexed_tokens = tokenizer.encode("Who is Li BiGor ? Li BiGor is a")
# indexed_tokens
Out[2]: [8241, 318, 7455, 8436, 38, 273, 5633, 7455, 8436, 38, 273, 318, 257]
print("输入语句为:", tokenizer.decode(indexed_tokens))
tokens_tensor = torch.tensor([indexed_tokens]) # 将输入语句转换为张量
# 加载模型
model = GPT2LMHeadModel.from_pretrained(model_name)
# 将模型设置为评估模式
model.eval()
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokens_tensor = tokens_tensor.to(DEVICE)
model.to(DEVICE)
# 预测所有标记
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
# outputs.keys()
Out[3]: odict_keys(['logits', 'past_key_values'])
# logits用于预测新的词,past_key_values包含了模型每一层中 Key 和 Value,包含了模型在之前所有步骤中学到的上下文信息。
outputs[0].shape
# 输出的token序列,和输入保持一致
Out[4]: torch.Size([1, 13, 50257])
outputs[1].__len__()
Out[6]: 24
# 这里表示模型有24层Transformer decoder堆叠
outputs[1][0].__len__()
Out[7]: 2
# 这里表示包含key和value
outputs[1][0][0].shape
Out[8]: torch.Size([1, 16, 13, 64])
# 这里是第一层的key的形状,16代表16个头,16*64=1024表示token的维度
# 得到预测的下一词,仅使用输出序列的最后一个词
predicted_index = torch.argmax(predictions[0, -1, :]).item()
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
print("输出语句为:", predicted_text) # GPT-2模型没有为输入文本添加特殊词。
# 输出:Who is Li BiGor? Li BiGor is a Chinese
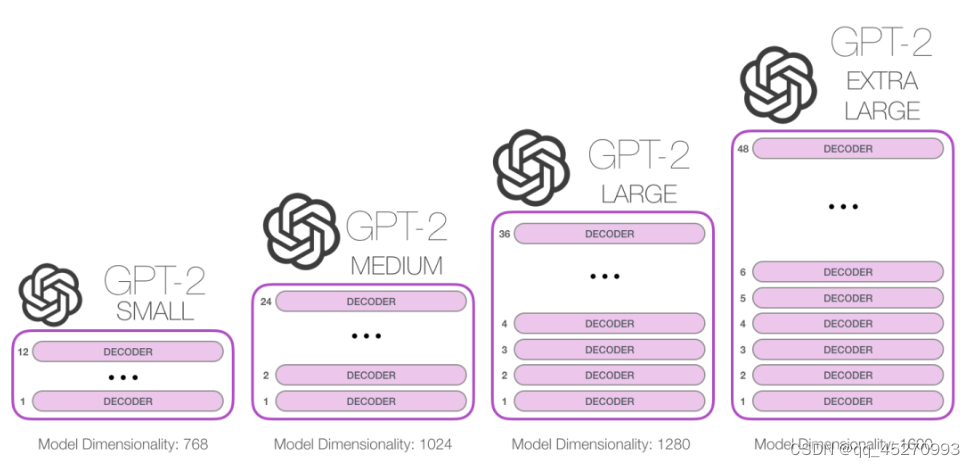
不同规模GPT2的config


















 2364
2364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









