







论文:Learning Transferable Visual Models From Natural Language Supervision
一、介绍
CLIP(Contrastive Language-Image Pre-training),是一种基于对比文本-图像对的预训练方法。CLIP用文本作为监督信号来训练可迁移的视觉模型,使得最终模型的zero-shot效果堪比ResNet50,泛化性非常好。
CLIP算是在跨模态训练无监督中的开创性工作,作者在开头梳理了现在vision上的训练方式,从有监督的训练,到弱监督训练,再到最终的无监督训练。这样训练的好处在于可以避免的有监督的 categorical label的限制,具有zero-shot性质,极大的提升了模型的实用性能。
CLIP 最大的贡献就是打破了之前固定种类标签的范式,无论是在收集数据集时,还是在训练模型时,都不需要像 ImageNet 那样做 1000 个类,直接搜集图片和文本的配对就行,然后去预测相似性。在收集数据、训练、推理时都更方便了,甚至可以 zero-shot 去做各种各样的分类任务。
二、模型结构
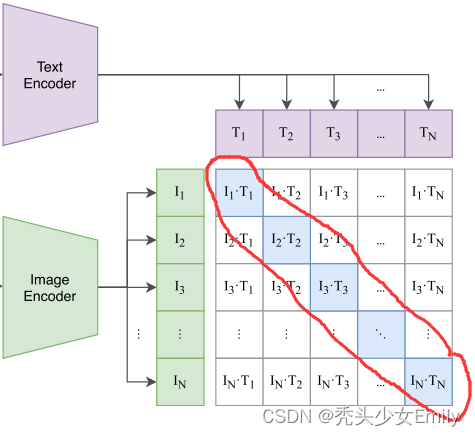
模型的结构很简洁,就是将image和text通过两个各自模态的encoder提取feature之后,将互相配对的image-text所属的feature作为正样本(图中矩阵对角线),其余不配对的样本作为负样本(除对角线之外的元素)来进行对比学习。
假如模型输入的是对图片-文本对,那么这
对互相配对的图像–文本对是正样本(下图输出特征矩阵对角线上标识蓝色的部位),其它
对样本都是负样本。这样模型的训练过程就是最大化
个正样本的相似度,同时最小化
个负样本的相似度。
2.1 Contrastive pre-training
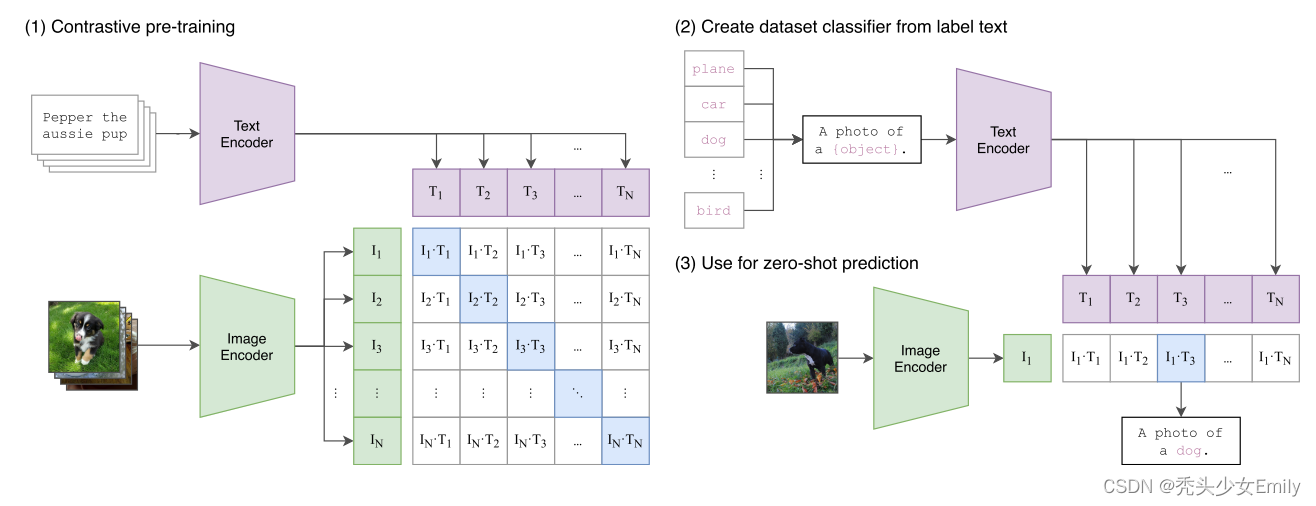
- 模型的输入是若干个 图像-文本 对如图最上面的数据中图像是一个小狗,文本是 ”Pepper the aussie pup”)。
- 图像部分:图像通过一个Image Encoder 得到一些特征,这个 encoder 既可以是 ResNet,也可以是 Vision Transformer。假设每个 training batch 都有 N 个 图像-文本 对儿,那么就会得到 N 个图像的特征(如下图中的
)

-
文本部分:文本通过一个Text Encoder得到一些文本的特征。同样假设每个training batch都有 N 个图像-文本对,那么就会得到N 个文本的特征(如下图中的
)
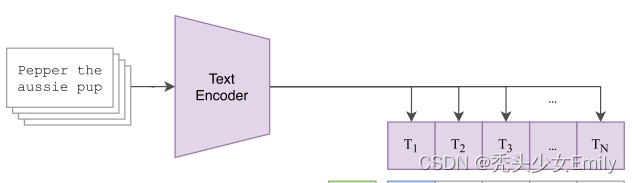
CLIP 就是在以上这些特征上去做对比学习,对比学习非常灵活,只需要正样本和负样本的定义,其它都是正常套路。这里配对的图像-文本对就是正样本(即下图中对角线(蓝色)部分,)
Text Encoder可以采用CBOW或者text transformer模型;而Image Encoder可以采用常用ResNet或者vision transformer等模型。
相似度是计算文本特征和图像特征的余弦相似性cosine similarity
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WIT(Web Image Text。WIT质量很高,而且清理的非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一(后续在WIT上还孕育出了DALL-E模型)。
2.2 Create dataset classifier from label text
问:CLIP 经过预训练后只能得到视觉上和文本上的特征,并没有在任何分类的任务上去做继续的训练或微调,那么 CLIP 是如何做推理的呢?
作者提出 prompt template:以 ImageNet 为例,CLIP 先把 ImageNet 这1000个类(如图中"plane", “car”, “dog”, …, “brid”)变成一个句子,也就是将这些类别去替代 “A photo of a {object}” 中的 “{object}” ,以 “plane” 类为例,它就变成"A photo of a plane",那么 ImageNet 里的1000个类别就都在这里生成了1000个句子,然后通过先前预训练好的 Text Encoder 就会得到1000个文本的特征。
其实如果直接用单词(“plane”, “car”, “dog”, …, “brid”)直接去抽取文本特征也是可以的,但是因为在模型预训练时,与图像对应的都是句子,如果在推理的时候,把所有的文本都变成了单词,那这样就跟训练时看到的文本不太一样了,所以效果就会有所下降。此外,在推理时如何将单词变成句子也是有讲究的,作者也提出了 prompt engineering 和 prompt ensemble,而且不需要重新训练模型。
2.3 Use for zero-shot prediction
CLIP直接利用zero-shot来分类图像,即不需要任何训练和微调,这也是CLIP亮点和强大之处。用CLIP实现zero-shot分类只需要简单的两步:
- step1:根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征。如果类别数目为n,那么将得到n个文本特征;
- step2:将要预测的图像送入Image Encoder得到图像特征,然后与n个文本特征计算缩放的余弦相似度(和训练过程保持一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果。进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
伪代码:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - 输入图片维度
# T[n, l] - 输入文本维度,l表示序列长度
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 用来学习如何从单模态变成多模态,对两个特征进行线性投射,得到相同维度的特征d_e,并进行l2归一化,保持数据尺度的一致性
# 多模态embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 算缩放的余弦相似度:[n, n],用来做分类
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n) # 对角线元素的labels,在CLIP中,正样本都是在对角线上所以真实标签为np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss
loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss
loss = (loss_i + loss_t)/2 # 对称式的目标函数
2.4 zero-shot迁移
研究zero-shot的动机:之前的自监督或有监督训练的模型(MOCO、DINO等),主要是学习一种泛化好的特征,所以在做下游任务的时候,还是需要有监督的微调,就依然存在很多问题。比如下游任务的数据集不好收集,存在分布飘偏移(distribution shift)等等。而使用文本引导视觉模型训练,就可以很好的进行zero-shot迁移;模型就可以不再训练,不再微调。
2.4.1 Prompt Engineering and Ensembling
prompt 主要是在做 fine-tune 或做推理时的一种方法,而不是在预训练阶段,所以不需要那么多的计算资源,并且效果也很好。prompt 指的是提示,即文本的引导作用。
问:为什么需要做 Prompt Engineering and Prompt Ensembling?
- polysemy(一词多义):如果在做文本和图片匹配的时候,每次只用标签对应的那 一个单词 去做文本上的特征抽取,那么很容易遇到这种问题。例如在 ImageNet 中,同时包含两个类,一类是 “construction crane”,一类是 “crane”,在相应的语境下这两个 “crane” 的意义是不一样的,在建筑工地的环境下指的是“起重机”,作为动物又指的是“鹤”,这时就有歧义性。当然别的数据集也有这种问题,如 Oxford-IIIT Pet,有一类叫 boxer,这里指的是狗的一种类别,但对于文本编码器来说它就可能翻译成“拳击手”,那这样提取特征就是不对的。总之,如果只是单独一个单词去做 prompt,那么很容易出现歧义性的问题。
- 做预训练时,匹配的文本一般都是一个句子,很少是一个单词。如果推理时传进来的是一个单词的话,很容易出现distribution gap,提取的特征可能不是很好。
三、局限性
- 性能有待提高。CLIP在很多数据集上,平均下来看可以和ResNet-50打成平手(ImageNet精度为76.2),但与现在最好的模型(VIT-H/14,MAE等精度可以上90)还存在十几个点的差距。预测大概还需要当前1000倍的规模才可以弥补上十几个点的这个差距,现有的硬件条件也无法完成。所以扩大数据规模是不行了,需要在数据计算和高效性上需要进一步提高。
- 难以理解抽象/复杂概念。CLIP在一些更抽象或更复杂的任务上zero-shot表现并不好。例如数一数图片中有多少个物体,或者在监控视频里区分当前这一帧是异常还是非异常,因为CLIP无法理解什么是异常、安全。所以在很多情况下,CLIP都不行。
- out-of-distribution泛化差。对于自然图像的分布偏移,CLIP还是相对稳健的。但如果在做推理时,数据和训练时的数据相差太远(out-of-distribution),CLIP泛化会很差。例如CLIP在MNIST数据集上精度只有88%,随便一个分类器都都能做到99%,可见CLIP还是很脆弱的。(作者研究发现,4亿个样本没有和MNIST很像的样本)
- 虽然CLIP可以做zero-shot的分类任务,但它还是从给定的那些类别里去做选择,无法直接生成图像的标题。作者说以后可以将对比学习目标函数和生成式目标函数结合,使模型同时具有对比学习的高效性和生成式学习的灵活性。
- 数据的利用不够高效。在本文的训练过程中,4亿个样本跑了32个epoch,这相当于过了128亿张图片。可以考虑使用数据增强、自监督、伪标签等方式减少数据用量。
- 引入偏见。本文在研发CLIP时一直用ImageNet测试集做指导,还多次使用那27个数据集进行测试,所以是调了很多参数才定下来网络结构和超参数。这并非真正的zero-shot,而且无形中引入了偏见。
- 社会偏见。OpenAI自建的数据集没有清洗,因为是从网上爬取的,没有经过过滤和审查,训练的CLIP模型很有可能带有一些社会偏见,例如性别、肤色。
- 需要提高few-shot的性能。很多复杂的任务或概念无法用文本准确描述,这时就需要提供给模型一些训练样本。但当给CLIP提供少量训练样本时,结果反而不如直接用zero-shot。例如3.1.4中CLIP的few-shot分类。后续工作考虑如何提高few-shot的性能。
四、结论
作者的研究动机就是在 NLP 领域利用大规模数据去预训练模型,而且用这种跟下游任务无关的训练方式,NLP 那边取得了非常革命性的成功,比如 GPT-3。作者希望把 NLP 中的这种成功应用到其他领域,如视觉领域。作者发现在视觉中用了这一套思路之后确实效果也不错,并讨论了这一研究路线的社会影响力。在预训练时 CLIP 使用了对比学习,利用文本的提示去做 zero-shot 迁移学习。在大规模数据集和大模型的双向加持下,CLIP 的性能可以与特定任务的有监督训练出来的模型竞争,同时也有很大的改进空间。


















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











