









Python编写的简易爬取保存网站图片程序+学习笔记
目录
一、URL的一般格式([]内为可选项)
protpcol://hostname[:port]/path/[;parameters][?query]#fragment
网络协议://服务器位置(或许也有用户信息)【端口号】/斜杠限定文件或者CGI应用程序的路径/【可选参数】【连接符或连接键值对】#拆分文档中的特殊锚
主要由三部分组成
1.协议:http,https,ftp,file,ed2k
2.服务器的域名系统或ip地址(有时候要包含端口号,各种传输协议都有默认的端口号,如http默认80)
3.斜杠限定文件或者CGI应用程序的路径
二、html标签
html标签(了解即可)
基本格式:
<tagName attribute1 = ""attribute2>text</ tagName>
常用标签:
a:超链接
img:图片
input:输入框
button:按钮
实际系统中,元素的标签类型不是由表象决定的,是通过css样式表来决定的
三、基本库urllib的使用
3.1发送请求
使用urllib的request模块
3.1.1urlopen()
#百度首页的抓取,输出了网页的源代码
>>> import urllib.request
>>> response = urllib.request.urlopen("http://www.baidu.com")
>>> html = response.read().decode('utf-8')#读取、译码
>>> print(html)
urllib.request.urlopen返回的方法是一个 HTTPResposne 类型的对象,它主要包含的方法有 read() 、 readinto() 、getheader(name) 、 getheaders() 、 fileno() 等函数和 msg 、 version 、 status 、 reason 、 debuglevel 、 closed 等属性。得到这个对象之后,赋值为 response ,然后就可以用 response 调用这些方法和属性,得到返回结果的一系列信息。例如 response.read() 就可以得到返回的网页内容, response.status 就可以得到返回结果的状态码
3.1.2 Request()
urlopen()方法可以实现最基本请求的发起,但是不足以构建一个完整的请求。如果请求中需要加入Headers等信息,就要使用更强大的Request类
urllib.request.Request()
req = urllib.request.Request(url)
# 设置头信息模拟浏览器
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
# 访问
response = urllib.request.urlopen(req)
# 读取源码
html = response.read()
可以发现,我们依然是用 urlopen() 方法来发送这个请求,只不过这次 urlopen() 方法的参数不再是一个URL,而是一个 Request。通过构造这个数据结构,一方面我们可以将请求独立成一个对象,另一方面可配置参数更加丰富和灵活。
四、代理
#参数是一个字典{‘协议类型’:‘代理ip:端口号’}
proxy_support = urllib.request.ProxyHandler({})
#定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
#安装opener
urllib.request.install_opener(opener)
#调用opener
response = urllib.request.urlopen(url)
html = response.read().decode(‘utf-8’)
实例:从三个ip地址中随机选择一个作为代理ip,并模仿浏览器去爬取网页信息
import urllib.request
import random
url = 'http://www.whatsmyip.com'
iplist = ['124.42.7.103:80','120.198.224.101:8080','222.73.68.144:8090']
#设定opener的参数,参数是一个字典{‘协议类型’:‘代理ip:端口号’}
proxy_support = urllib.request.ProxyHandler({'anonymous':random.choice(iplist)})
#定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
#设置头信息使opener模仿浏览器去打开,注意为元组类型(头信息去网站的源代码里的network里找)
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')]
#安装opener
urllib.request.install_opener(opener)
#调用opener
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
print(html)
五、爬取图片网站实战
Github链接:https://github.com/codemother/crawl_website_pictures
程序用于爬取煎蛋网相关图片并保存
程序流程图如下:
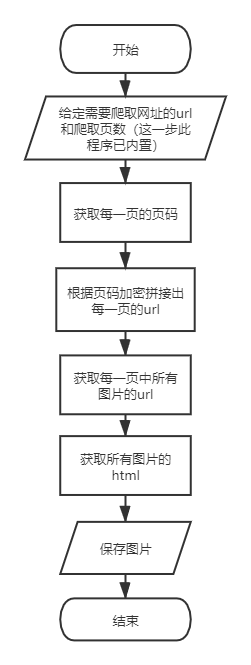
原始1.0(初始版本)
import urllib.request
import os
import base64
#定义一个读取源码的函数,方便后面代码的引用
def url_open(url):
#获取url
req = urllib.request.Request(url)
#设置头信息模拟浏览器
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
#访问
response = urllib.request.urlopen(req)
#读取源码
html = response.read()
return html
#定义一个获取页码的函数
def get_num(url):
html = url_open(url).decode('utf-8')
#查找需要的图片所在页在代码中的位置,这里加上偏移量后刚好到页码前的一个字符
a = html.find('current-comment-page')+23
#从起始位置a开始查找,目标是页码后的一个字符
b = html.find(']',a)
#返回从a到b的值,即页码
return html[a:b]
#定义一个在已知地址寻找图片的函数
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
#对于find(),找不到会返回-1,找到了会返回开始的索引值
a = html.find('img src=')
while a!= -1:
b = html.find('.jpg',a,a+255)
if b != -1:
img_addrs.append(html[a+9:b+4])
else:
b = a + 9
a = html.find('img src =',b)
return img_addrs
#保存图片
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb')as f:#首先执行with后的open,值返回给as后的f,然后运行下面的语句
img = url_open('http:'+each)
f.write(img)
#主程序
def download(folder = 'girl pictures',pages = 10):
#在当前目录创建文件夹,名称girl pictures
os.mkdir(folder)
#os.chdir()方法用于改变当前工作目录到指定的路径.这里就是将路径切换到folder
os.chdir(folder)
url = 'http://jandan.net/girl/'
page_num = int(get_num(url))
for i in range(pages):
page_num -= i
#网址使用了加密技术,这里我们把解密后经过改写的地址再次加密,和其他字符串拼接,最终显示出网站使用的url
#base64的加密需要输入bytles格式,所以这里用encode()转换
#strip()是用来去除字符串首尾指定字符的,这里用来去除加密后产生的'b'
#eval()是用来去除字符串首尾的双引号的,这里因为格式化字符串时里面本身就带有引号,导致最终多了一对引号
code = '20210604' + '-' + str(page_num)
page_url = url + eval(str(base64.b64encode(code.encode())).strip('b')) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder,img_addrs)
#if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
if __name__=='__main__':
download()
版本日志:
- 版本总结:程序爬取图片保存的功能基本实现,但是和预期仍有差距
- 本版本仍然存在的问题:
- 只能爬取固定一页的十张图,而我的程序设计预期是能爬取从主页开始往后10页的图。从具体代码分析来看:设计中的
page_num -= i功能并没有实现 - find_imgs模块虽然能实现基本功能,但是实现原理应当是有问题的,需要继续优化
- 这里没有使用代理是因为实验中多次使用代理被拦截,后续可以考虑将代理加入的问题
原始2.0(正则优化版本)
import urllib.request
import os
import base64
import re
#定义一个读取源码的函数,方便后面代码的引用
def url_open(url):
# 获取url
req = urllib.request.Request(url)
# 设置头信息模拟浏览器
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
# 访问
response = urllib.request.urlopen(req)
# 读取源码
html = response.read()
return html
#定义一个获取页码的函数
def get_num(url):
html = url_open(url).decode('utf-8')
a =re.search(r'"current-comment-page">([[]\d+[]])',html)
b =a.group(1)
c =re.search(r'\d+',b)
return c.group()
#定义一个在已知地址寻找图片的函数
def find_imgs(url):
page_html = url_open(url).decode('utf-8')
all_img_url_0 =re.findall(r'a href="(//wx.+jpg)" target=',page_html)
all_img_url_1 =[]
for i in all_img_url_0:
i ='http:'+i
all_img_url_1.append(i)
return all_img_url_1
#定义一个保存的函数
def save_imgs(all_img_urls):
for each_img_url in all_img_urls:
filename =re.split('/',each_img_url)[-1]
# 一般用下面这种方式在当前目录创建一个名为filename的文件,下面的语句是对这个文件的操作
with open(filename,'wb') as f:
each_img_html =url_open(each_img_url)
f.write(each_img_html)
def main(folder = 'girl pictures',pages = 10):
#在当前目录创建文件夹,名称girl pictures
os.mkdir(folder)
#os.chdir()方法用于改变当前工作目录到指定的路径.这里就是将路径切换到folder
os.chdir(folder)
url = 'http://jandan.net/girl'
page_num = int(get_num(url))
for i in range(pages):
page_num -= i
#网址使用了加密技术,这里我们把解密后经过改写的地址再次加密,和其他字符串拼接,最终显示出网站使用的url
#base64的加密需要输入bytles格式,所以这里用encode()转换
#strip()是用来去除字符串首尾指定字符的,这里用来去除加密后产生的'b'
#eval()是用来去除字符串首尾的双引号的,这里因为格式化字符串时里面本身就带有引号,导致最终多了一对引号
code = '202106010' + '-' + str(page_num)
page_url = url +'/'+ eval(str(base64.b64encode(code.encode())).strip('b')) + '#comments'
all_img_urls = find_imgs(page_url)
save_imgs(all_img_urls)
#if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
if __name__=='__main__':
main()
版本日志
-
版本总结:
在系统学习正则表达式后,我对1.0版的get_num,find_imgs和save_imgs模块都进行了重写,将代码逻辑全部转换为正则表达式匹配,并调整了结构,使得代码更富有逻辑,便于理解,并增强了代码的泛用性。 -
本次更新修复了以下问题:
1.在1.0版本中,程序只能爬取固定一页的十张图。而在2.0版本,程序已经可以做到爬取从首页开始往后的10页里的所有图片(并且通过修改pages参数,10页可以替换为任意页)。
2.在1.0版本很多地方代码存在逻辑漏洞并且晦涩难懂,在2.0版本这些逻辑漏洞被基本修复,且代码简洁易懂。 -
本版本仍然存在的问题:
1.程序理论上可以爬取从首页开始往后的10页里的所有图片,但实际上在中途可能会被服务器拦截,并不能保存所有图片
2.会出现Possible nested set at position 25 a =re.search(r'"current-comment-page">([[]\d+[]])',html)的警告,虽然不影响程序运行,但需要解决
3.程序中code = '202106010' + '-' + str(page_num)采用了投机取巧的方法,虽然不影响程序运行,但不符合逻辑,不能保证未来一直不会出问题,存在隐患
原始2.2(正则优化版本)
import urllib.request
import os
import base64
import re
import datetime
import shutil
#定义一个读取源码的函数,方便后面代码的引用
def url_open(url):
# 获取url
req = urllib.request.Request(url)
# 设置头信息模拟浏览器
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
# 访问
response = urllib.request.urlopen(req)
# 读取源码
html = response.read()
return html
#定义一个获取页码的函数
def get_num(url):
html = url_open(url).decode('utf-8')
a =re.search(r'"current-comment-page">(\[\d+\])',html)
b =a.group(1)
c =re.search(r'\d+',b)
return c.group()
#获取当前日期
def get_date():
today =datetime.date.today()
today_format =re.sub('-','',str(today))
return today_format
#定义一个在已知地址寻找图片的函数
def find_imgs(url):
page_html = url_open(url).decode('utf-8')
all_img_url_0 =re.findall(r'a href="(//wx.+jpg)" target=',page_html)
all_img_url_1 =[]
for i in all_img_url_0:
i ='http:'+i
all_img_url_1.append(i)
return all_img_url_1
#定义一个保存的函数
def save_imgs(all_img_urls):
for each_img_url in all_img_urls:
filename =re.split('/',each_img_url)[-1]
# 一般用下面这种方式在当前目录创建一个名为filename的文件,下面的语句是对这个文件的操作
with open(filename,'wb') as f:
each_img_html =url_open(each_img_url)
f.write(each_img_html)
def main(folder = 'girl pictures',pages = 10):
try:
#在当前目录创建文件夹,名称girl pictures
os.mkdir(folder)
except:
print('检测到之前存在的文件,将覆盖')
shutil.rmtree(folder)#删除原有文件夹
os.mkdir(folder)#创建新的同名文件夹
#os.chdir()方法用于改变当前工作目录到指定的路径.这里就是将路径切换到folder
os.chdir(folder)
url = 'http://jandan.net/girl'
page_num = int(get_num(url))
for i in range(pages):
page_num -= i
#网址使用了加密技术,这里我们把解密后经过改写的地址再次加密,和其他字符串拼接,最终显示出网站使用的url
#base64的加密需要输入bytles格式,所以这里用encode()转换
#strip()是用来去除字符串首尾指定字符的,这里用来去除加密后产生的'b'
#eval()是用来去除字符串首尾的双引号的,这里因为格式化字符串时里面本身就带有引号,导致最终多了一对引号
code = get_date() + '-' + str(page_num)
page_url = url +'/'+ eval(str(base64.b64encode(code.encode())).strip('b')) + '#comments'
all_img_urls = find_imgs(page_url)
save_imgs(all_img_urls)
#if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
if __name__=='__main__':
main()
2.1更新日志
-
修复了以下问题:
1.在2.0版程序中code = '202106010' + '-' + str(page_num)存在隐患,2.1版通过导入datetime模块实时获取日期,消除了隐患
2.在2.0版会出现Future warning的警告,2.1版通过优化对应行的正则表达式消除了这一问题 -
仍然存在的问题:
1.不能连续多次运行,如果检测到文件夹已经存在会直接报错
2.易被服务器拦截,很难获取足够多的图片
2.2更新日志
- 修复了文件夹已存在会直接报错的问题:通过try…except…语句和引入shutil模块检测并覆盖原有文件
六、爬取百度贴吧图片
程序设计预期:通过输入任意一个百度贴吧的网址就可以爬取这个贴吧10页内所有帖子内的图片
1.0版本
import os
import re
import urllib.request
import shutil
#获取一个url的html
def get_html(url):
req =urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
req.add_header('Accept','text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9')
response =urllib.request.urlopen(req)
html =response.read()
return html
#输入一个贴吧主页的url
def input_url():
url =str(input('请输入一个贴吧首页的url:'))
return url
#获取十页的url
def get_allpages_url(url):
html =get_html(url).decode('utf-8')
all_pages_url =re.findall(r'a href="(//tie.+)" class=" pagination-item "',html)
rel_pageurl =[]
for i in all_pages_url:
rel ='https:'+i
rel_pageurl.append(rel)
return rel_pageurl
#获取每一页中所有项的url
def get_every_url(url):
html =get_html(url).decode('utf-8')
all_items_url =re.findall(r'a rel="noreferrer" href="(.+)" title="',html)
rel_url =[]
for i in all_items_url:
rel ='https://tieba.baidu.com'+i
rel_url.append(rel)
return rel_url
#获取每一项里首页所有张图片的url
def get_pictures(url):
html =get_html(url).decode('utf-8')
eachitem_picture_url =re.findall(r'img class="BDE_Image.+src="(.+jpg)" size',html)
return eachitem_picture_url
#保存
def save(urls):
for i in urls:
filename =re.split(r'/',i)[-1]
with open(filename, 'wb') as f:
each_picture_html =get_html(i)
f.write(each_picture_html)
#主函数
def main():
try:
os.mkdir(r'E:\PyCharm 2021.1.2\project\tieba picture')
except:
shutil.rmtree(r'E:\PyCharm 2021.1.2\project\tieba picture')
os.mkdir(r'E:\PyCharm 2021.1.2\project\tieba picture')
os.chdir(r'E:\PyCharm 2021.1.2\project\tieba picture')
url =input_url()
all_pages_url =get_allpages_url(url)
all_item_url = []
for x in all_pages_url:
each_item_url =get_every_url(x)
all_item_url.append(each_item_url)
all_pictures_url = []
number = 1
for outside in all_item_url:
for inside in outside:
eachitem_pictures =get_pictures(inside)
try:
save(eachitem_pictures)
print('已保存%d个贴子的所有图片'%number)
print('刚刚爬取的帖子:',inside)
print('刚刚保存的帖子里的图片:',eachitem_pictures)
number += 1
except:
continue
if __name__ =='__main__':
main()
测试日志:
已实现的功能:
1.可以输入网址
2.可以爬取任意贴吧的图片
仍然存在的问题:
1.只能爬取大概60个左右的帖子里的图片,之后就无法爬取。初步分析是触发了百度贴吧的安全机制,需要行为验证,导致后面的帖子爬取图片为空
2.程序无法连续多次运行:基本运行一次后再运行进程会直接结束,而不会运行后面的程序。初步分析是百度贴吧的反爬虫机制阻止了url的访问请求,通过修改头信息(添加accept)可以再次成功运行,但是如果进行第三次运行进程也会直接结束。目前来看只有等待一段时间才能再次成功运行程序。
3.程序不会爬取一个帖子里的所有图片,而是爬取一个帖子里的首页里的图片。初步分析是程序设计之初没有考虑到每个帖子里也会有多页的情况存在,这一部分代码没有编写















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









