







名词解释:一个3分 总分30
简答题:一个5分 总分40
编程题:一个10分 总分30
高性能计算导论复习(根据复习范围)
第六章-重点:OpenMP并行编程
OpenMP
- 定义
- 共享存储体系结构上的一个并行编程模型或基于线程的并行编程模型
代码(一定会考一个)
/* 用OpenMP/C编写Hello World代码段 */
#include <stdio.h>
#include <omp.h>
int main(int argc, char *argv[])
{
int nthreads, tid;
int nprocs;
char buf[32];
omp_set_num_threads(4);
/* Fork a team of threads */
#pragma omp parallel private(nthreads, tid)
{
/* Obtain and print thread id */
tid = omp_get_thread_num();
printf("Hello world from OpenMP thread %d\n", tid);
/*Only master thread does this */
if (tid == 0)
{
nthreads = omp_get_num_threads();
printf(" Number of threads %d\n", nthreads);
}
}
return 0;
}
结果:
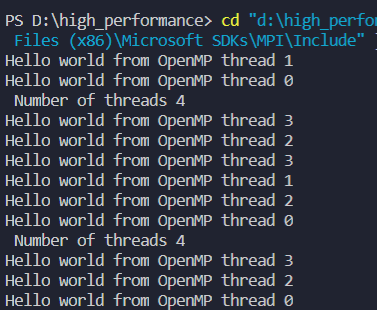


括号一定要放在后头,不然会报错
编译制导语句
- 制导标识符
- !$OMP
- Fortran
- #pragma omp
- C / C++
- !$OMP
- 制导名称
- parallel
- Do / for
- section
- 子句
- private
- shared
- reduction
- copyin
- 格式
- 制导标识符 制导名称 [Clause, …]
并行域
- 一个能被多个线程并行执行的代码段
私有变量,公有变量
shared子句
公有:shared(list)
- 数组变量、仅用于读的变量通常是共享的
- 默认是公有
private子句
私有:private(list)
- 循环变量、临时变量、写变量一般是私有的
- 在parallel结构中声明的变量是私有的
循环制导(很重要)
并行Do / for循环制导
- for制导指令指定紧随它的循环语句由线程组并行执行,用来将一个for循环任务分配到多个线程,各个线程各自分担其中一部分工作。
- for指令一般可以和parallel指令合起来形成parallel for指令使用,也可以单独用在parallel指令的并行域中。
#pragma omp [parallel] for [clauses]
for循环语句
循环变量要是私有的
- 几个例子(细看看,我觉得肯定会考吧)


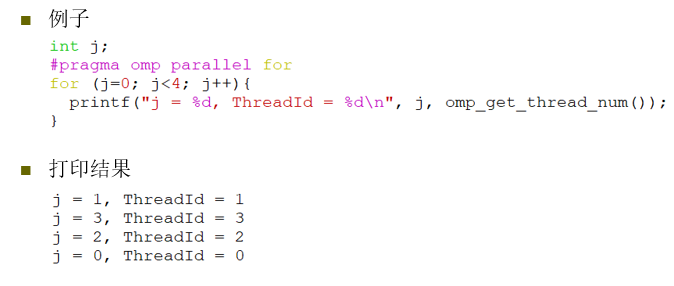
四个求 π \pi π代码(四选一必考一个,还会考写打印结果-写一种就好)
并行域并行求解
代码:
#include <omp.h>
#include <stdio.h>
static long num_steps = 1000000;
double step;
#define NUM_THREADS 2
int main(int argc, char *argv[])
{
int i;
double x, pi, sum[NUM_THREADS];
double start = 0.0, stop = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS);
start = omp_get_wtime();
#pragma omp parallel private(i)
{
double x;
int id;
id = omp_get_thread_num();
for (i = id, sum[id] = 0.0; i < num_steps; i += NUM_THREADS)
{
x = (i + 0.5) * step;
sum[id] += 4.0 / (1.0 + x * x);
}
}
for (i = 0, pi = 0.0; i < NUM_THREADS; ++i)
pi += sum[i] * step;
stop = omp_get_wtime();
printf("pi = %lf\ntime = %lf\n", pi, stop-start);
return 0;
}
运行结果:
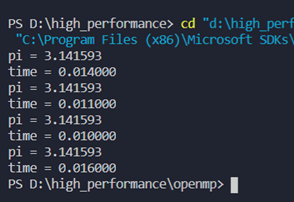
使用for循环制导计算
代码:
#include <omp.h>
#include <stdio.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 4
int main(int argc, char *argv[])
{
int i, id;
double x, pi, sum[NUM_THREADS];
double start = 0.0, stop = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS);
start = omp_get_wtime();
#pragma omp parallel private(x, id)
{
id = omp_get_thread_num();
sum[id] = 0;
//for不能加大括号,否则会报错
#pragma omp for
for (i = 0; i <= num_steps; ++i)
{
x = (i + 0.5) * step;
sum[id] += 4.0 / (1.0 + x * x);
}
}
for (i = 0, pi = 0.0; i < NUM_THREADS; ++i)
pi += sum[i] * step;
stop = omp_get_wtime();
printf("pi = %lf\ntime = %lf\n", pi, stop-start);
return 0;
}
运行结果:
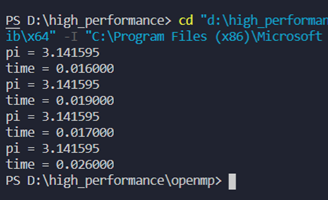
使用带reduction子句的for循环制导
代码:
#include <omp.h>
#include <stdio.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
int main(int argc, char *argv[])
{
int i;
double x = 0.0, pi = 0.0, sum = 0.0;
double start = 0.0, stop = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS);
start = omp_get_wtime();
#pragma omp parallel for reduction(+ : sum) private(x)
for (i = 1; i <= num_steps; ++i)
{
x = (i - 0.5) * step;
sum += 4.0 / (1.0 + x * x);
}
pi += sum * step;
stop = omp_get_wtime();
printf("pi = %lf\ntime = %lf\n", pi, stop-start);
return 0;
}
运行结果:
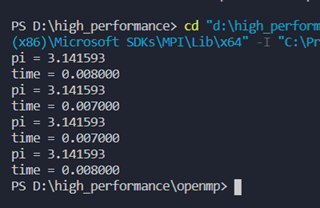
通过private子句和critical制导计算
代码:
#include <omp.h>
#include <stdio.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 4
int main(int argc, char *argv[])
{
int i, id;
double x, pi, sum;
double start = 0.0, stop = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS);
start = omp_get_wtime();
#pragma omp parallel private(id, i, x, sum)
{
id = omp_get_thread_num();
for (i = id, sum = 0.0; i <= num_steps; i += NUM_THREADS)
{
x = (i + 0.5) * step;
sum += 4.0 / (1.0 + x * x);
}
#pragma omp critical
pi += sum;
}
pi *= step;
stop = omp_get_wtime();
printf("pi = %lf\ntime = %lf\n", pi, stop-start);
return 0;
}
运行结果:
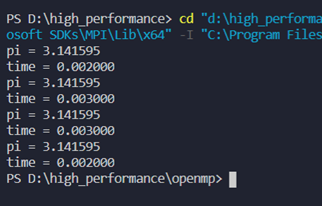
静态调度、动态调度
调度子句
schedule(kind[,chunksize])
kind:调度类型
- static
- dynamic
- guided
- runtime
- 根据环境变量OMP_SCHEDULED来选择前三种的某种类型
chunksize
- 可选,是一个完整表达式
- runtime不能使用
- kind为static是缺省系统自动划分成近似大小的区域
- kind为dynamic时使用后分配给线程的是chunksize次连续的迭代计算
- kind为guided时使用后说明最小的区间大小,默认为1




这里的公式是 S k = R k / N S_k = R_k / N Sk=Rk/N
数据竞争问题
- 如果说把循环里的变量定义为公有,那么多个线程跑的时候就会出现问题,可能某个线程运行时的该变量被其他线程运行的时候替换掉了。



section制导(简答题)
-
Sections编译制导指令用于非迭代计算的任务分配,它将sections语句里的代码用section制导指令划分成几个不同的段,由不同的线程并行执行
-
$pragma omp [parallel] sections[clauses] { [$pragma section] block [$pragma section] block ...... } //简单形式 $pragma parallel sections[clauses] ...... $pragma end parallel sections -
说明
- 各结构化块在各线程间并行执行
- sections制导可以带有PRIVATE、 FIRSTPRIVATE和其它子句
- 每个section必须包含一个结构体
-

single制导(必考)
-
#pragma omp single[clauses] { structure block } -
说明
- 结构体代码仅由一个线程执行
- 并由首先执行到该代码的线程执行
- 其它线程等待直至该结构块被执行完
-
例子(很重要)
-
作用
- 为了减少并行域创建和撤销的开销,将多个临近的parallel并行域合并
- 合并后,原来并行域之间的串行代码可以用single指令加以约束只用一个线程来完成


master制导
-
#pragma omp master[clauses] { structure block } -
说明
- 结构体代码仅由主线程执行
- 其它线程跳过并继续执行
- 通常用于I/O
single和master制导区别
- master制导包含的代码段由主线程执行,而single由任一线程执行
- master制导在结束处没有隐私同步,也不能指定nowait从句
critical制导(临界制导)
-
//如果name被省略,一个空(null)的name被假定 #pragma omp critical[(name)] { structure block } -
作用
- 保护对共享变量的修改
- 保护共享变量的更新,避免数据访问竞争,制导内的代码段仅能有一个线程执行
-
说明
- critical制导在某一时刻仅能被一个线程执行
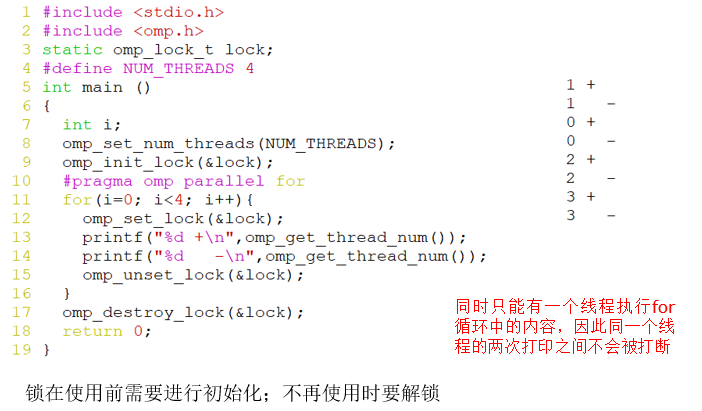
互斥锁(解答题,打印结果)
互斥锁函数
void omp_init_lock(omp_lock_t *lock);
void omp_set_lock(omp_lock_t *lock);
int omp_test_lock(omp_lock_t *lock);
void omp_unset_lock(omp_lock_t *lock);
void omp_detroy_lock(omp_lock_t *lock);
num_threads
-
int omp_get_thread_num()
- 获得线程数
-
omp_set_num_threads(int n)
- 设置进程数
-
NUM_THREADS 子句
-
设定线程数
-
#pragma omp parallel num_threads(2) -
在NUM_THREADS中提供的值将取代环境变OMP_NUM_THREADS的值(或由 omp_set_num_threads()设定的值 )
-
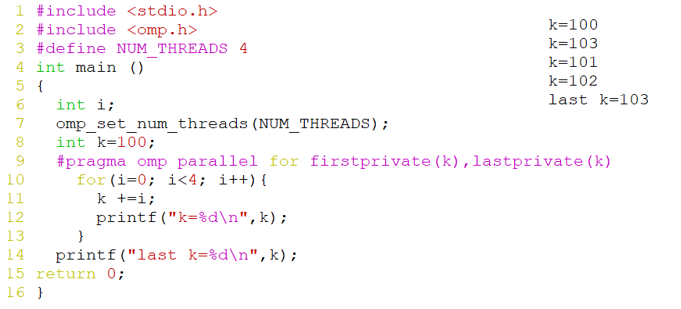
firstprivate子句(写打印结果)
- 在并行域或任务分配域开始执行时,私有变量通过主线程中的变量初始化
- firstprivate(变量列表)

lastprivate子句
- 在并行域或任务分配域结束时,将最后一个线程上的私有变量赋值给主线程的同名变量
- lastprivate(变量列表)
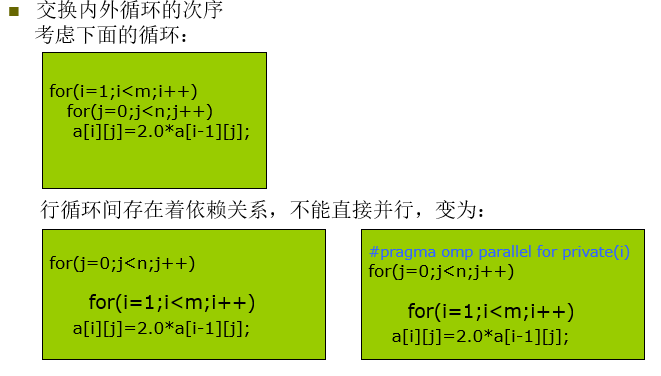
改善并行循环性能
循环中的依赖关系(例题很重要)
例子1
#include "omp.h"
#include "stdio.h"
#define n 20
int main()
{
int a[m][n], i,j;
for(i=0;i<m;i++)
for(j=0;j<n;j++)
a[i][j]=i;
#pragma omp parallel for private(i)
for(j=0;j<n;j++)
for(i=1;i<m;i++)
a[i][j]=2*a[i-1][j];
}
例子2

//通过两个线程实现
#include"omp.h"
#include"stdio.h"
#define n 20
int main()
{
int a[n], i;
for(i=0;i<n;i++)
a[i]=i;
omp_set_num_threads(4);
#pragma omp parallel num_threads(2)
#pragma omp for schedule(static,1)
for(i=2;i<n;i++)
a[i]=a[i-2]+4;
#pragma omp parallel
{
printf("\n");
#pragma omp critical
{ printf("%d:\n",omp_get_thread_num());
for(i=2;i<n;i++)
printf("%d ",a[i]-a[i-2]);
}
printf("\n");
}
}
if子句(挺重要的)
- 如果循环的迭代次数太少,循环制导有可能增加执行的代码时间,这是可以使用if子句
- 格式
- if(表达式)
//考虑以下代码
sum=0.0;
#pragma omp for private(x) shared(sum) reductuion(+:sum)
for (i=0;i< n; i++){
x = (i+0.5)/n;
sum += 4.0/(1.0+x*x);
}
pi=sum/n;
//增加条件子句
sum=0.0;
#pragma omp for private(x) shared(sum) reductuion(+:sum) if(n>5000)
for (i=id;i< num_steps; i++){
x = (i+0.5)/n;
sum += 4.0/(1.0+x*x);
}
pi=sum/n;















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









