








From High-Level Deep Neural Models to FPGAs
2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO)
根据Caffe对DNN模型的高级描述,自动生成可综合的的加速器
现存的问题:
-
FPGA同时获得性能和能源效率很难。
-
DNN占用大量内存,FPGA的片上存储容量有限
为了在保持自动化的同时获得加速的收益,DNNWeaver生成的加速器使用手工优化设计的模板
首先,DNNWeaver将 DNN描述转换为新的ISA(表示DNN的宏数据流图)。DNNWeaver有分块,调度,barch等优化用于最大化数据重用和资源利用。
贡献:
- 宏数据流图指令集架构
- 可扩展和高度定制的手动优化模板
- 启发式算法优化加速器架构和相应的执行调度
Overview of DNNWEAVER
Translator 将DNN描述转化为宏数据流指令集架构(Instruction set architecture ,ISA)。一个指令表示数据流中的一个节点,指令并不会执行,只是静态的映射到加速器的控制信号然后形成一个执行调度。
Design Planner 接受表示DNN宏数据流图的指令,并使用模板资源优化算法通过计算切片和配置加速器来达到并行操作和数据重用之间的平衡,以最佳匹配FPGA的约束(片上内存和外部内存带宽)。
Design Weaver 它以Planner确定的资源分配和执行调度为输入,使用手工优化的设计模板生成加速器核心代码。Design Weaver将Planner提供的执行调度转换为嵌入在硬件模块中的状态机(state machines)和微码(microcodes)
Integrator 将内存接口代码添加到加速器代码中。不同的FPGA的外部DRAM接口不同,Integrator包含了DRAM接口的一个库 。集成后 ,生成可在目标FPGA上综合的Verilog代码。


Instruction Set Architecture Design
提供宏数据流图指令集架构的目的:
- 从软件抽象激素其设计细节
- 可以分层优化
- 容易移植到不同的FPGA平台
- 允许在编译时进行静态执行调度
加速器不需要执行这些指令。编译器静态地将这些指令转换为微码和状态机。ISA的粗粒度特性使微体系结构能够合并特定于层的优化,而无需通过软件堆栈暴露。
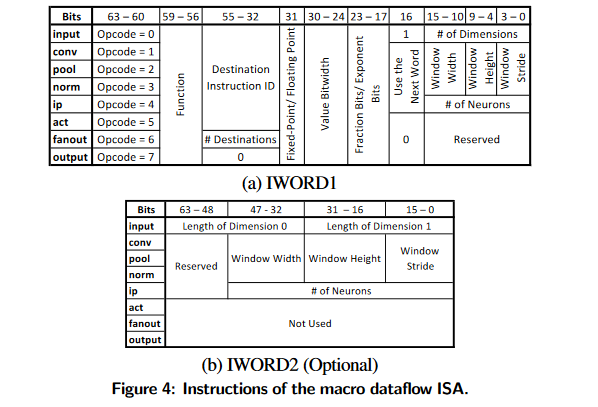
Template Accelerator Architecture
模板设计是高度可定制customizable和可扩展scalable的。基于DNN的要求和FPGA的资源约束进行收缩或扩展。
模板也被设计成通用的general。模板包括可交换组件,实现dnn不同层。如果DNN不需要某一层(如归一化),则排除相应的组件,为其他层释放资源
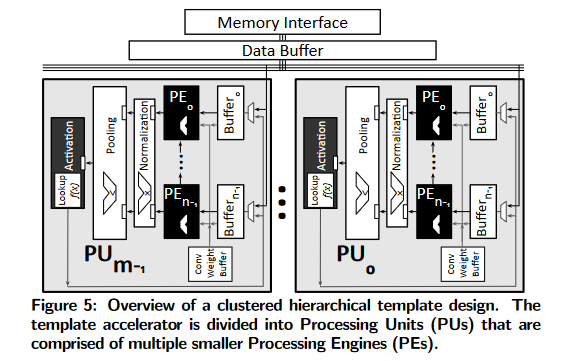
Specializing the design for a target FPGA
每个FPGA提供一定数量的硬块,包括DSP片(alu)和块ram(片上SRAM单元,称为BRAMs)。
图5中的模板架构将PU buffer映射到bram,将alu映射到DSP片。
另一个资源是可用的芯片外带宽,它决定了连接到内存接口的数据缓冲区的参数,
还为数据缓冲区生成一个静态调度,从外部内存中获取数据,并通过pu间总线向pu提供数据。静态调度避免了总线上的争用,减少了pu执行复杂握手的需要。这种方法反过来又提高了模板体系结构的可伸缩性和效率。
Processing engines
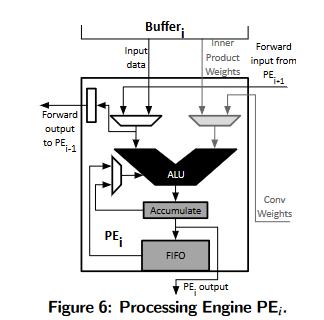
每个PE包含一个硬ALU,支持乘法运算和乘法加法运算。
相邻PE之间有一条单向链路,将输入数据从索引较高的PE (PEi+1)转发到索引较低的PE (PEi)。此转发链路用于跨相邻pe重用数据,以最小化来自内存的数据传输。
PU中的每个PE都与一个专用buffer相关联,该缓冲区向PE提供内部乘积权重和输入数据
Accelerating Layers of DNN
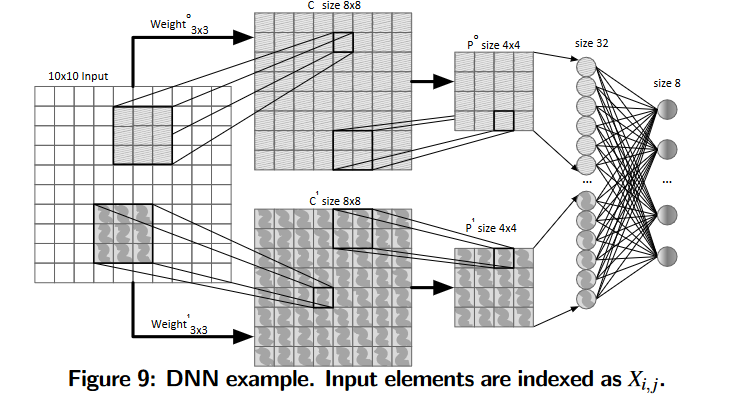
Convolution Layer
Dedicated buffer for convolution weights 通过在PU中使用卷积权值缓冲区来最小化从内存访问权值的开销,该缓冲区存储所有所需的权值,并在PU的pe之间共享
Parallelism across output elements C 00 0 C_{00}^0 C000 , C 01 0 C_{01}^0 C010 …之间,也就是每一次卷积核与特征图对应数据相乘累加的操作都是独立的,这些并行计算由PU内的pe执行。
Saving partial results to minimize data communication
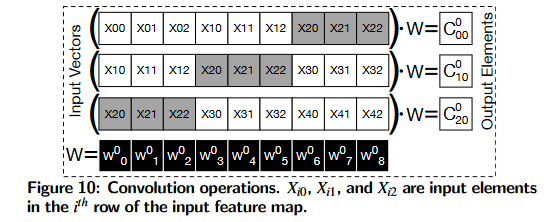
卷积操作需要访问相同的输入三次。为了减少这些冗余访问,PEs逐行读取输入并生成部分结果。然后,PEs将部分结果存储在本地FIFO中。
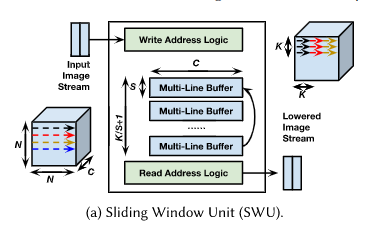
FINN:Sliding Window Units(SWUs):滑动窗口单元
将前一层的输出数据按照通道优先的方式,存储在缓冲区RAM的地址上,然后生成每个像素对应的地址,根据该地址从RAM上读取像素,生成图像矩阵,就可以将卷积运算转换为矩阵乘法。(地址重写逻辑,减少了数据重复访问)
Data forwarding
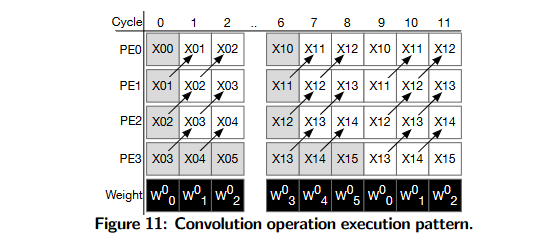
(是不是画错了?中间省略的三个周期应该是w3 w4 w5。然后最后画w6,w7,w8,再从w0开始循环)
有点脉冲阵列的思想
Reusing data across convolution kernels. 跨卷积核重用数据。使用图11中的操作序列,四个pe使用第一个内核(Weight0)计算四个相邻的输出元素。
(和第一个的专用卷积权值缓冲区的作用有什么区别?)
Pooling Layer
由于卷积层在一行中生成相邻的元素,单元首先为第一行计算max(C00, C01)并将其推到FIFO。当第二行可用时,弹出FIFO并计算
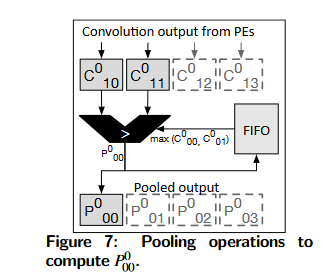
(C00,C01,C02,C03, max里面也是C00和C01,所以上面的C角标的x坐标应该是0,而不是1)
Hiding latency 为了隐藏执行延迟,池化模块将其操作与PEs中的卷积操作重叠。由于前一层卷积的内核大小是3×3, PU中的4个pe每9个周期生成4个输出元素。如图7所示,卷积输出元素被发送到具有单个3:1比较器的共享池化模块
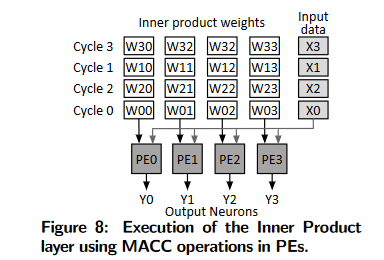
Inner Product layer(全连接层)
内积层可以表示为向量矩阵乘法:
intput shape:[H, W]
weight: [H×W, output_size]
全连接:([H, W] flatten [1, H×W]) * [H×W, output_size] = [1, output_size]
Parallelism across output elements. 所有的输入数据乘以权值的一列得到一个输出元素。上述操作对每个输出元素并行,对每一个输出元素分配一个PE用于乘加计算,那么所有的输出元素就可以同时计算出来;
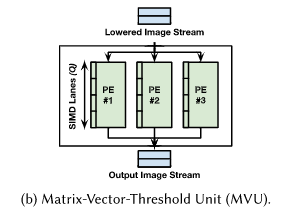
FINN:Matrix-Vector-Threshold Units(MVUs):
权值保存在PE的片上存储器上,每个PE都具有SIMD通道元素的输入。计算时,每个PE接收的输入向量相同,但是PE需要输入向量与不同的权值进行相乘累加,就可以同时计算得到多个输出。
Normalization and Activation
标准化的一部分(平方和)使用卷积硬件,另一部分(缩放)作为一个单独的单元实现。激活传递函数使用每个PU中的查找表来实现。
Design Planner
DNNWeaver利用了FPGA的可重配置使用模板资源优化(Template Resource Optimization),一个启发式搜索算法共同优化加速器架构和对应的执行调度,用以最小化片外访问和最大化性能。
两个影响性能的关键因素:
- 将计算和内存资源分配给模板架构中的各个组件,这决定了加速器中的并行度;
- 加速器上的操作调度,它决定所需的片外访问
DNN的内存要求比片上存储要高很多,所以需要把每一层的输出特征图给切片。片是输出特征图的一部分,在计算后溢出到内存中。
模板资源优化算法通过改变PU中PE的数量和切片大小最大化性能
Number of PEs-per-PU:(PU内PE数量多,内部并行度高,但是PU之间的并行度低;PU内PE少,内部并行度低,但是PU之间的并行度高)
上面的模板架构中存在两个级别的并行:1. PU内部PE的并行会生成相邻的输出元素。2. 不同的PU之间会输出不同的特征图。由于FPGA上的片上资源固定,所以需要找到每个PU中PE的数量和PU总数量之间的平衡。
Output slice :(大了,并行度高,但会片外访问;小了,并行度小,但不会片外访问)
输出切片的大小和PU中的片上存储相适应,而片上存储的大小和PE的数量有关。切片影响数据的重用,就像卷积操作中的重叠元素,数据的重用只能发生在同一个片内。
因此,算法先把一行放在PU上,这一行的大小取决于PU内PE的数量,如果还有额外的存储空间就尝试存储更多的行。通过这种方法,Design Planner为每个PU选择一个最大化数据重用和最小化外部内存访问的片。
(每个特征图的输出这样贪心的切片,最后不会省的PE很少导致并行度很低吗?难道每一层完成会释放所有PE资源?)
Template Resource Optimization search algorithm
优化目标: 通过决定PU中PE的数量和切片大小最小化执行周期数
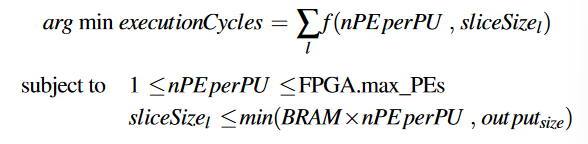

该算法将DNN宏数据流图(D)和FPGA平台的约束(F)作为输入。FPGA平台的约束(F)提供了PE的最大数量和每个PE上BRAM的容量。算法最后通过以下步骤输出nPE perPU和sliceSizel:
- 初始化执行周期无限大
- PE的数量从1开始迭代,
- 根据PU中PE的数量,计算每个层的切片大小
- 得到切片大小后,计算执行周期
- 记录较小的执行周期的PE数量和切片方案,更新eec
(似乎每一层的PEs-per-PU是固定的,然后根据固定的PE数量决定分片大小,为什么不给每一层PU分配不同的PE数量,每一层运行完就换一个FPGA的配置文件?)
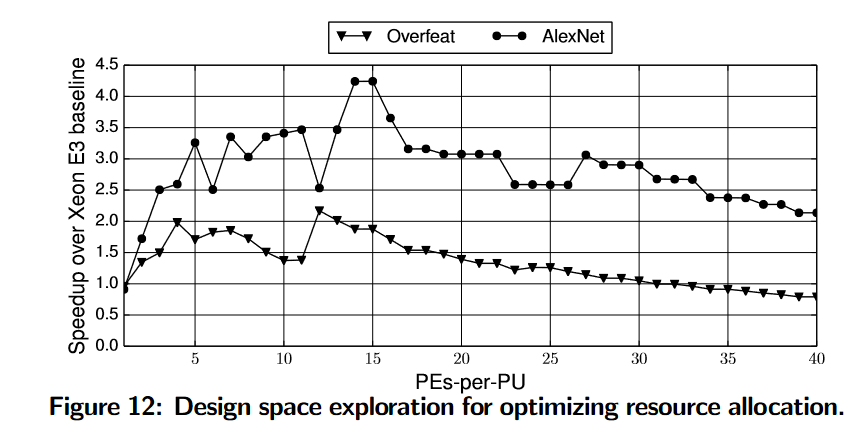
使用Xeon E3作为基准
Evaluation
评估平台及参数:
FPGA:Xilinx Zynq ZC702, Altera Stratix V GS D5, Altera Arria 10 GX-AX115
Qaurtus II v14.1 + Vivado v2015.1
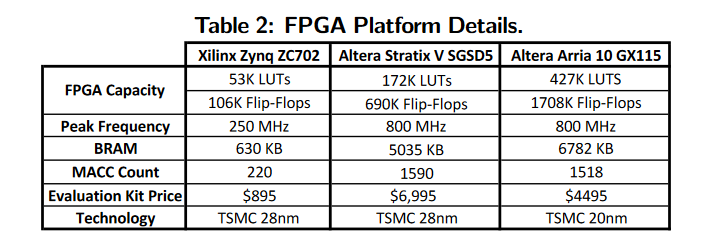
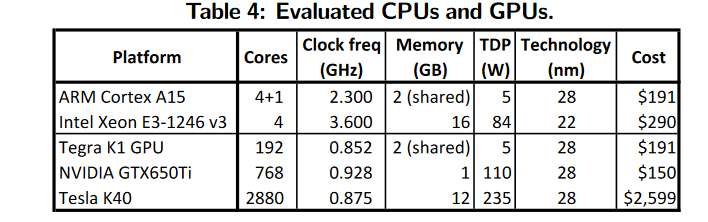
CPU&GPU
优化:多线程向量化CPU执行 + cuDNN优化GPU执行
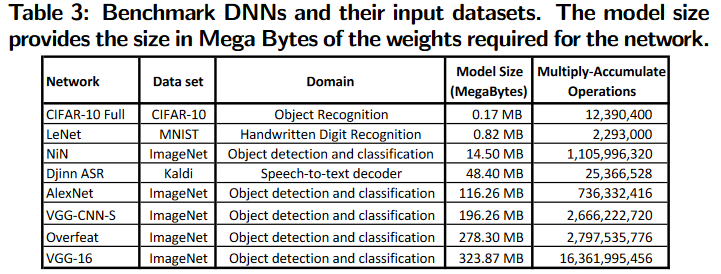
测试的DNN模型和数据集:
Benchmark DNNs and Their Input Datasets
Comparison to High Level Synthesis
HLS提供了高级抽象,但是在FPGA上优化DNN需要专业的硬件知识和编程工具的知识。在我们的实验中,两名在硬件设计方面有一定经验的硕士学生花了一个月的时间来优化Xilinx Zynq ZC702 FPG的LeNet基准的Vivado HLS实现。最终的实现运行在100 MHz,相比DNNWEAVER生成的加速器在相同的FPGA平台上提供了19.7×的减速
Experimental Results
FPGA上加速器与CPU&GPU相比的性能:
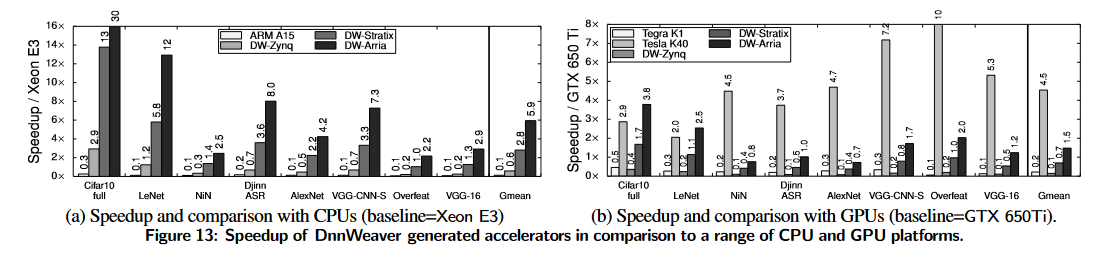
Per-Layer Performance Benefits 每层的性能收益:
统计不同层的占比:
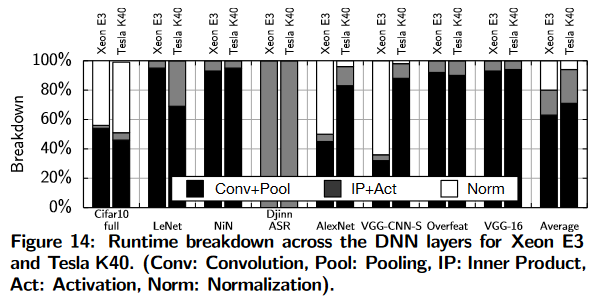
不同层在CPU和GPU的加速收益:
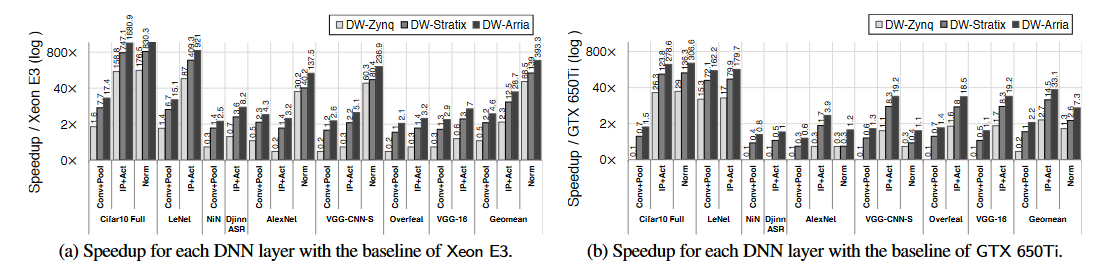
Sensitivity to on-chip storage 不同模型对片上存储的敏感性

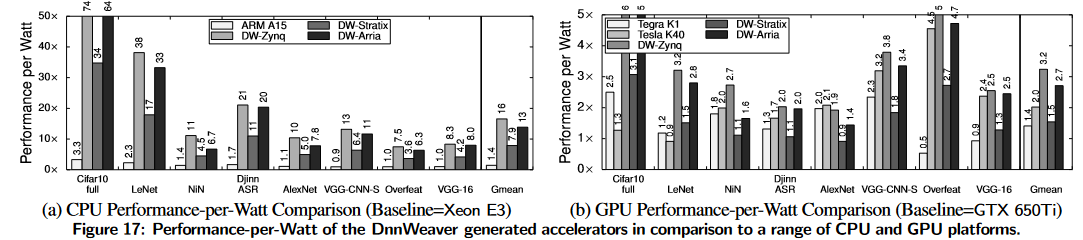
Performance-per-Watt Comparison with CPUs & GPUs
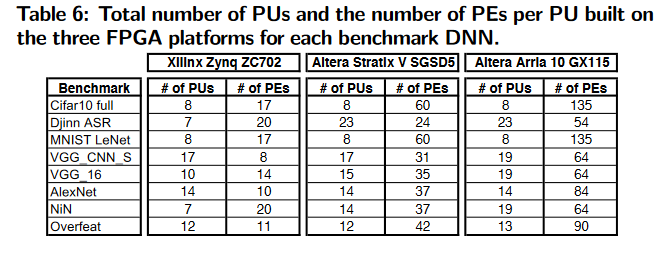
Area and FPGA Utilization
















 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









