








FP-DNN: An Automated Framework for Mapping Deep Neural Networks onto FPGAs with RTL-HLS Hybrid Templates
2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM)
motivation: 由于DNN相比之前的浅模型计算更密集和存储更密集,所以在大规模数据中心和实时嵌入式系统中部署dnn具有挑战性。基于FPGA的DNN加速器的解决方案有前景,但设计周期长,需要专业硬件知识。
work: 提出了一个以tensorflow描述的DNN为输入的端到端框架FP-DNN (Field Programmable DNN),并使用RTL-HLS混合模板在FPGA板上自动生成硬件实现。
implement CNNs, LSTM-RNNs, and Residual Nets(ResNet-152,first people) with FP-DNN
FRAMEWORK
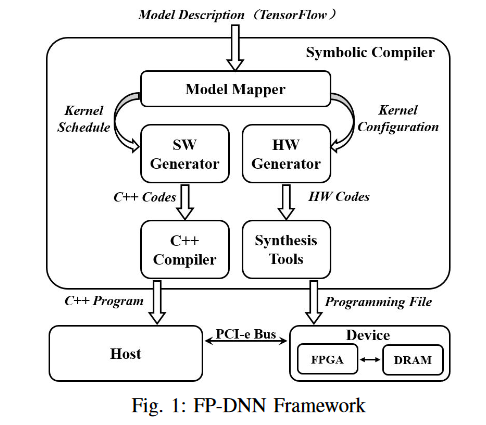
Model Mapper
通过tensorflow对模型的描述,将模型的结构和每一层配置信息提取出来。
由于没有足够的片上BRAM存储模型参数和中间结果,所以从片外的DDR中加载数据。
(可以看到每层的结果是先写入DRAM中存储,然后下一层再从DRAM中读取。作者在related work中已经写了DNNWeaver的工作,所以 为啥不用它的切片策略?)
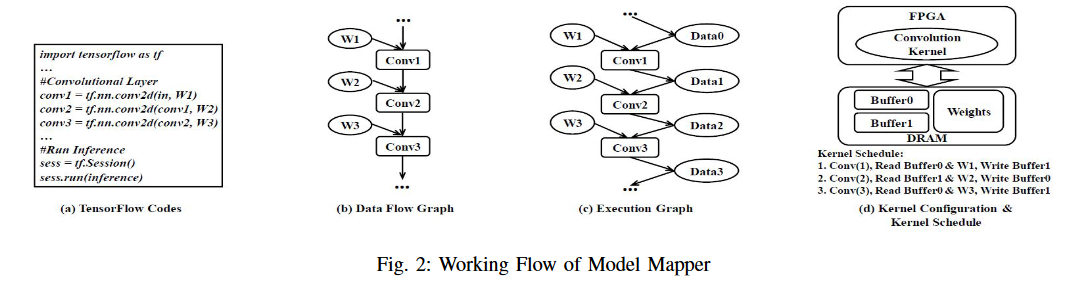
为了重用计算资源,模型映射器只分配一个硬件内核;
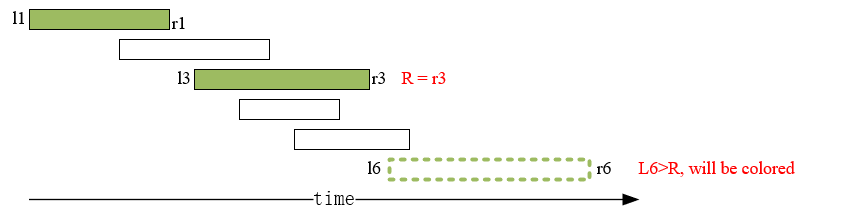
为了存储资源重用,Model Mapper在DRAM中分配几个物理缓冲区作为内存池(例如图d中的,Buffer0,Butffer1…);为了最小化物理缓冲区的数量,将数据缓冲区重用问题表示为图的着色问题: (算法导论贪心算法一章的习题)
节点:data buffer 数据缓冲区
边:不同数据缓冲区节点生存时间有交集,那么他们之间就连一条边
问题:对节点进行染色,最小化染色颜色数量,使得相邻的节点不会被分配相同的颜色
区间图的着色问题可以用多项式时间的left-edge算法求最优解

- 初始化当前颜色为颜色1,最晚结束时间R为0;按照开始时间升序排序
- 遍历还未染色的数据缓冲区节点
- 遍历节点集合,找到统一颜色下,开始时间大于R的节点
- 给开始时间最早的节点染色当前颜色
- 更新最晚节点为当前节点的结束时间,剔除当前已染色节点
- 重复上述步骤,直到找不到开始时间大于R的节点
- 染色数+1,用一个新的颜色继续染色,直到所有节点都被染完
SW Generator and HW Generator
SW Generator:软件生成器采用内核调度为主机生成c++代码,负责内核执行调度、模型初始化、数据缓冲区管理等。
HW Generator:硬件生成器实际上是一个RTL-HLS混合模板库,用于各种类型的层。
结合RTL的高效编写(verilog)计算部分和HLS的高级抽象(基于OpenCL的HLS)编写控制逻辑部分
IMPLEMENTATION
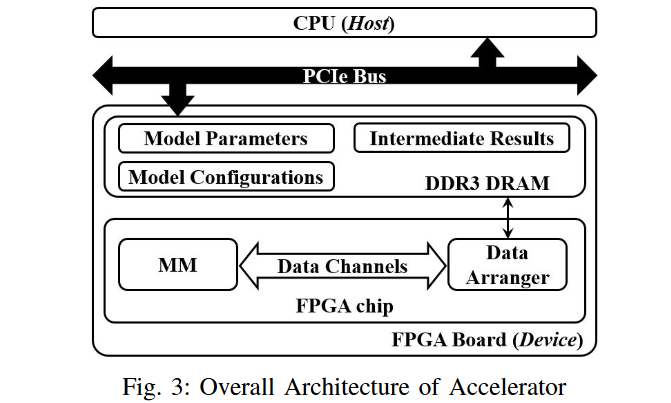
将模型推理所涉及的操作分为计算密集型(computation-intensive)部分和特定层(layer-specific)的部分。计算密集型部分用高性能矩阵乘(MM)实现,特定层使用Data Arranger实现,具有与DRAM通信的功能(取数据)
Computation-Intensive Part
Verilog实现了MM,加速矩阵乘法一直是FPGA界的经典问题,这里使用分块(tile)策略进行矩阵乘法.
MM接受输入矩阵的两个块,并执行向量乘向量的块乘法;输入的tile使用了双buffer,这些buffer以ping-pong的方式运行,使数据通信与计算重叠,提高MM的吞吐量
Layer-specific Part
将DNN中的各种层其转换为矩阵乘法,便于MM实现
Convolutional Layers
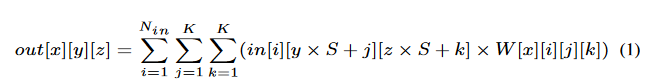
将输入特征从一个三维数组转换成一个二维数组:取每一个输入块把它们压平成一行输入矩阵,将相应的卷积核三维立方体划分为一列核矩阵
LSTM Layers
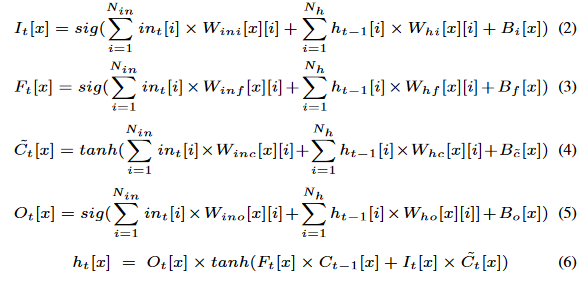
各种门参数的更新;这里是向量矩阵乘,所以不需要转换。
Fully-Connected Layers
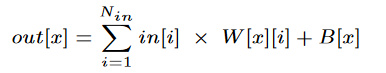
这里大部分计算是向量矩阵乘,所以不需要转换。
Other layers
RNN:循环层(不使用LSTM)实际上是通过在全连接层中添加循环连接来构造的
激活层:应用于特定元素相关函数,直接执行激活函数,不将它们映射到MM
池化层:选择滑动窗口平均值或最大值作为输出,计算量小,不需要映射到MM,在输出卸载到DRAM之前,采用池化操作。
(不映射到MM的激活和池化,怎么计算呢?)
Communication Optimization
增加DRAM的突发访问的长度可以提高有效的DRAM带宽,对DRAM的不连续访问将导致有限的突发长度,这将降低已实现的带宽至~ 1GB/s。而对DRAM进行连续访问将提高已实现的带宽到~ 8GB/s。为了防止I/O成为整体性能的严重瓶颈,我们提出了几种针对不同层优化有效DRAM带宽的方法:
Convolutional layers
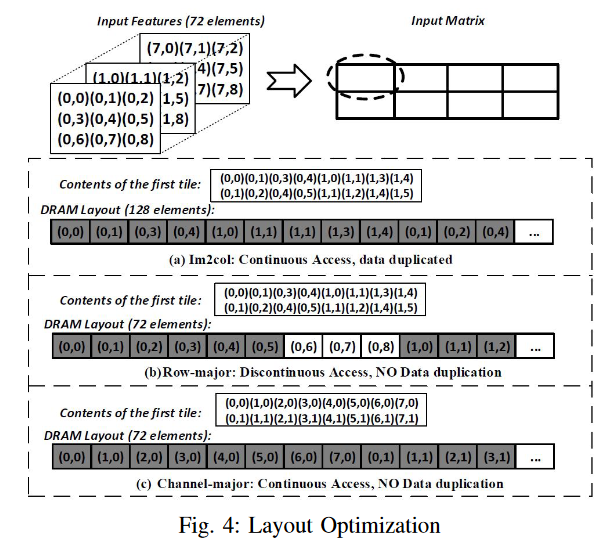
输入通道的数量设置为8,每个通道有3×3个元素,因此我们总共得到72个输入元素。卷积核大小为2×2,滑动步幅为1
我们把这个矩阵分成4×2相等的瓷砖(这句话似乎没啥作用)
LSTM Layers & Fully-Conneted Layers
LSTM层和全连通层的计算密集型部分主要包括矩阵向量乘,矩阵向量乘数据局域性方面效率很低,从DRAM提取的每个权重元素只用于单个计算一次,大部分推理时间都花在数据通信上。这说明直接用MM内核进行模型推理会带来很大的性能损失。将输入向量一起批量处理。在这种批处理方式中,权重矩阵的每个元素都被重用。(SIMD)
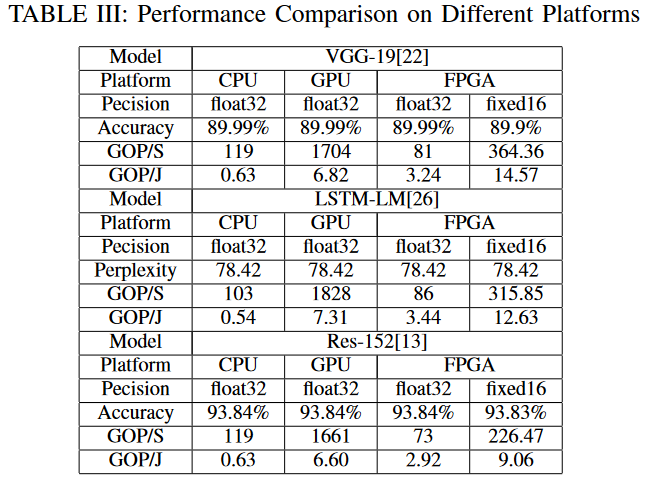
Data Quantization
dnn的准确性在数据精度下降的情况下足够精确和稳定,使用定点参数来提高性能和节省资源,这种优化称为数据量化。使用FP-DNN框架的设计人员可以通过简单地使用符号编译器中的“定点”编译选项来指定定点精度。在实际应用中,数据量化是离线进行的,数据量化带来的精度损失需要提前由FP-DNN的用户进行估计和测试。
EVALUATION
Symbolic Compiler编译器是用c++和OpenCL编写的
HLS代码由Altera OpenCL离线编译器(AOC) [1] (v16.0)合成。
hls合成的RTL代码与手工编写的RTL代码结合起来,然后提供给Quartus 16.0。
运行在主机上的代码是用c++编写的,用Visual Studio 2013编译
FPGA:Altera Stratix-V GSMD5
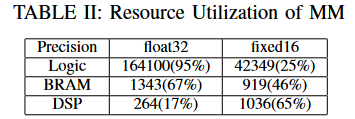
MM Performance
Intel MKL[24]和Altera示例为图5中的矩阵乘法设计。我们的实现和Altera示例设计运行在同一个FPGA板上,Intel MKL运行在CPU上,其中所有16个物理核都被完全占用。
正方形矩阵乘法(a)
正方形矩阵和长方形矩阵相乘(b)
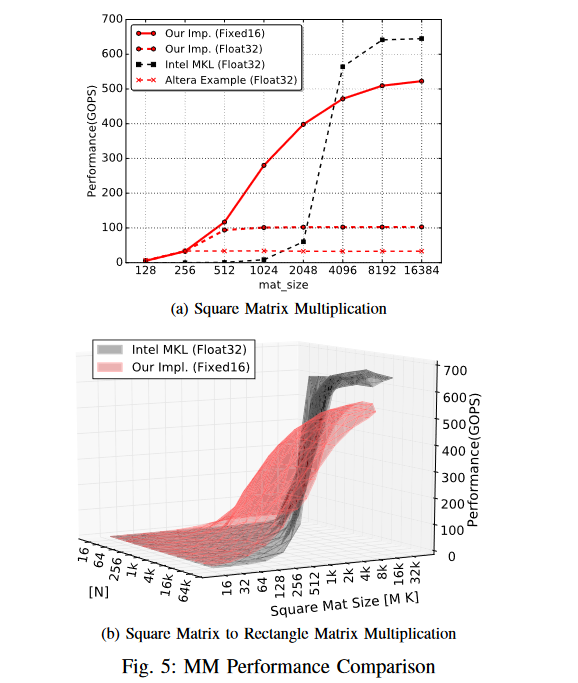
DNN Performance
展示FP-DNN框架在一个完整模型上的性能,将我们的CNN实现与之前的加速器进行比较
model使用VGG-19 : 16 convolution layers, 3 fully connected layers and 5 max pooling layer
[23]中基于opencl;[19]和[27]中基于C/ c++
[23]使用现有的矩阵乘法内核(Altera示例设计)执行卷积。
[19]为卷积层设计定制卷积核。
[27]为卷积层和全连通层设计了统一的卷积核。
FP-DNN使用广义MM内核进行卷积,生成的实现即使与针对特定模型优化的手工编码加速器相比,也能实现最先进的性能;考虑了DSP的使用,更有效地使用硬件资源。
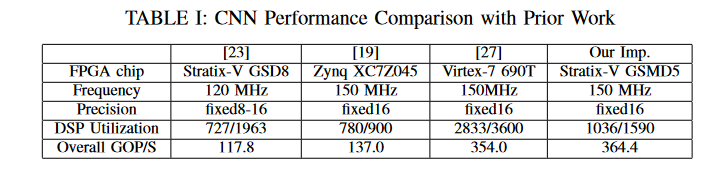
Cross-Platform Comparison
框架与CPU和GPU上的实现进行比较。我们使用TensorFlow(r0.9)来运行CPU和GPU实现。实现了几个dnn作为基准:VGG-19,LSTM-LM,Res-152















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









