







小罗碎碎念
这篇文章是一篇系统综述,标题为“Artificial Intelligence for predictive biomarker discovery in immuno-oncology: a systematic review”,旨在探讨人工智能(AI)技术在免疫肿瘤学领域预测生物标志物方面的应用和潜力。

本文重点介绍了机器学习和深度学习技术在分析免疫肿瘤学中的基因组和蛋白质组学数据中的应用,以确定个性化免疫治疗的新生物标志物。

要点速览
背景与挑战:
- 免疫检查点抑制剂(ICI)的使用已经革新了多种癌症的治疗方式,但预测哪些患者可能从ICI治疗中受益仍然是一个挑战。
AI技术的应用:
- 人工智能方法允许研究者利用高维度的肿瘤学数据,推动精准免疫肿瘤学的发展。
研究方法:
- 文章通过系统文献回顾,分析了使用AI预测癌症患者ICI疗效的研究,涵盖了
基因组学、放射组学、数字病理学(病理组学)、现实世界数据和多模态数据五个数据模态。
研究结果:
- 综述包括了90项研究,其中80%在2021年至2022年发表。
- 研究使用了不同的AI算法,包括标准机器学习(ML)方法、深度学习(DL)方法,以及两者结合的方法。
非小细胞肺癌(NSCLC)是最常研究的癌症类型。
结论:
- AI方法在生物标志物发现方面展现了潜力,特别是在整合多模态数据集以发现新的元生物标志物方面。
- 尽管多数研究显示了AI在预测免疫疗法效益方面的前景,但目前还没有足够的高级别证据支持立即改变临床实践。
- 需要预先计划的前瞻性试验设计,以涵盖这些软件生物标志物从开发、验证到整合到临床实践的所有生命周期步骤。
未来方向:
- 文章强调了需要进一步的研究和AI算法的验证,以便将研究成果转化为临床应用,并强调了可信赖的可解释AI在提供算法解释和生物标志物发现方面的潜在效用。
这篇综述为临床肿瘤学家和研究人员提供了AI在免疫肿瘤学预测生物标志物方面的使用原则和系统性视图,旨在提高对这一快速发展领域的理解,并突出了新的潜在元生物标志物,以供临床考虑。
一、引言
免疫治疗(IO),特别是免疫检查点抑制剂(ICI)在癌症治疗中的应用,改变了包括黑色素瘤1、头颈部癌(HNC)2、膀胱癌3,4、肾癌5以及晚期非小细胞肺癌(NSCLC)6-9等多种癌症的管理。
然而,该方法存在局限性:只有部分患者能从治疗中获益,临床实践采纳存在诸多挑战,经验丰富的医生报告了治疗效力的差异,这种差异根据肿瘤类型而变化10。准确选择特定疗法的患者群体仍然是未满足的临床需求。
目前只有少数生物标志物被验证可用于临床,大多数仅适用于某些癌症,如程序性死亡配体1(PD-L1)11和小卫星不稳定(MSI)12分别在肺癌和结直肠癌中。在其他癌症中,患者目前符合ICI治疗的资格,但没有生物标志物来预测反应,这意味着许多患者承受了毒性而没有获益。
鉴于肿瘤微环境(TME)和免疫系统(先天性和适应性)的复杂性,很难确定一个单一的生物标志物来稳健地预测预后和疗效13。相反,基于AI的方法有望通过整合目前肿瘤学中可用的多组学数据集(基因组学、病理组学、影像组学、肿瘤微环境异质性以及更多的真实世界数据(RWD)生成),定义新的元生物标志物,这些数据集对于标准分析工具来说过于庞大和复杂14。
本研究系统回顾了利用AI预测不同癌症类型ICI治疗疗效的已发表研究,重点在于基因组学、转录组学、表观遗传学、影像组学、病理组学、RWD和多模态数据。目的是为执业肿瘤学家和临床研究者提供关于AI使用原则的描述,以及基于系统文献回顾的AI为基础的免疫治疗预测生物标志物的概览,从而增强对这一快速发展领域的理解。同时,也旨在强调新的潜在元生物标志物,供临床考虑。
本文中使用的AI相关术语在词汇表1中呈现。

人工智能的一个子集,机器学习(ML)是一系列从数据中学习并迭代改进性能以解决特定任务的技巧,使用关于现象或过程的数据。
如果数据由图像组成,标准的ML模型会从数据中提取一组预定义的特征(例如肿瘤形状、肿瘤大小)作为输入,而不是数据本身。在这种情况下,特征提取不是学习过程的一部分,因此依赖于人类专业知识。然而,拥有一组预定义的手工特征代表了标准ML技术的重大局限性。
为了克服这一问题,如果有足够大量的数据,可以使用深度学习(DL),这是ML的一个分支,它利用原始格式的数据(即,DL可以直接处理非结构化数据集,参见词汇表1)来发现和识别模式。DL使用多层神经网络算法进行预测,这些算法受到大脑神经结构的启发。在其他应用领域,已经证明使用DL技术可以在手工特征无法提供满意结果的问题中实现超越人类的性能18。在分析医学图像中最常用的DL方法是卷积神经网络(CNN)。最近,视觉变换器(ViT)16,一种使用自注意力机制处理图像的模型,作为CNN的替代品出现,并在肿瘤学分类任务中受到越来越多的关注19-21。
AI方法(标准ML和DL)可以大致分为(1)监督式,(2)半监督式,和(3)非监督式学习。
(1)监督式
在监督式学习中,模型从标记数据中学习,即具有已知结果的数据。监督式学习的两种主要类型是分类和回归。分类用于预测分类变量(例如患者是否会响应治疗),而回归用于估计连续变量,如无进展生存期。
在癌症研究中,常用的ML监督式算法包括随机森林(RF)22和支持向量机(SVM)23。
(2)半监督式
半监督式学习模型处理部分标记的数据集,因此在获取标记数据耗时(例如,注释大量医学图像)的情况下非常有用。
最常见的半监督式方法包括多实例学习(MIL)24和图卷积网络(GCNs)25。
(3)非监督式
非监督式学习用于从数据中发现新模式,它转向使用主成分分析(PCA)和k-means聚类等算法进行聚类和降维。
在肿瘤学中,使用Cox比例风险模型进行生存分析26是常用的方法,以识别对病人复发或生存有影响的预后因素。最近,几种能够考虑特征之间交互效应的AI技术已适应这一任务27,28。这些模型的主要优点是它们在处理肿瘤学中经常出现的删失数据方面的成功。生存分析中常用的AI算法是随机生存森林(RSF)29。
尽管DL方法在癌症研究中最近变得流行,但在结构化数据(参见词汇表)的背景下,标准ML方法仍然首选。它们的主要优点是简单性,这使得它们更容易解释和透明。相比之下,DL模型架构复杂,包含数百层和数百万个参数。这样的人工智能架构的内部机制不容易被人类解释,因此训练和预测阶段通常被称为‘黑箱’方法17。
解释模型的决策策略提供了生物学洞见,并具有科学发现的潜力。重要的是,它建立了模型的信任度,这对于高效部署给最终用户——临床医生和病人本身至关重要30。用于解释AI模型及其预测的AI技术被称为可解释AI(XAI)方法17。
简而言之,XAI方法可以分为两大类:基于模型的和后验的17,31。基于模型的解释性算法提供了模型参数与它们学习到的结果之间关系的洞见(例如,逻辑回归),例如使用数学方法。后验可解释性针对的是设计上不可解释的更复杂模型,并试图从模型实现中提取,例如通过示例,模型提供的输入数据与最终输出之间的关系(例如,显著性映射32)。
在这篇综述中,我们专注于将AI方法应用于预测接受ICI治疗的患者积极结果的发生,遵循在累积大数据上训练模型的先前步骤。
Figure 1 描述了开发用于预测免疫治疗(IO)疗效的模型的一般步骤,并展示了不同数据类型常用的方法论。
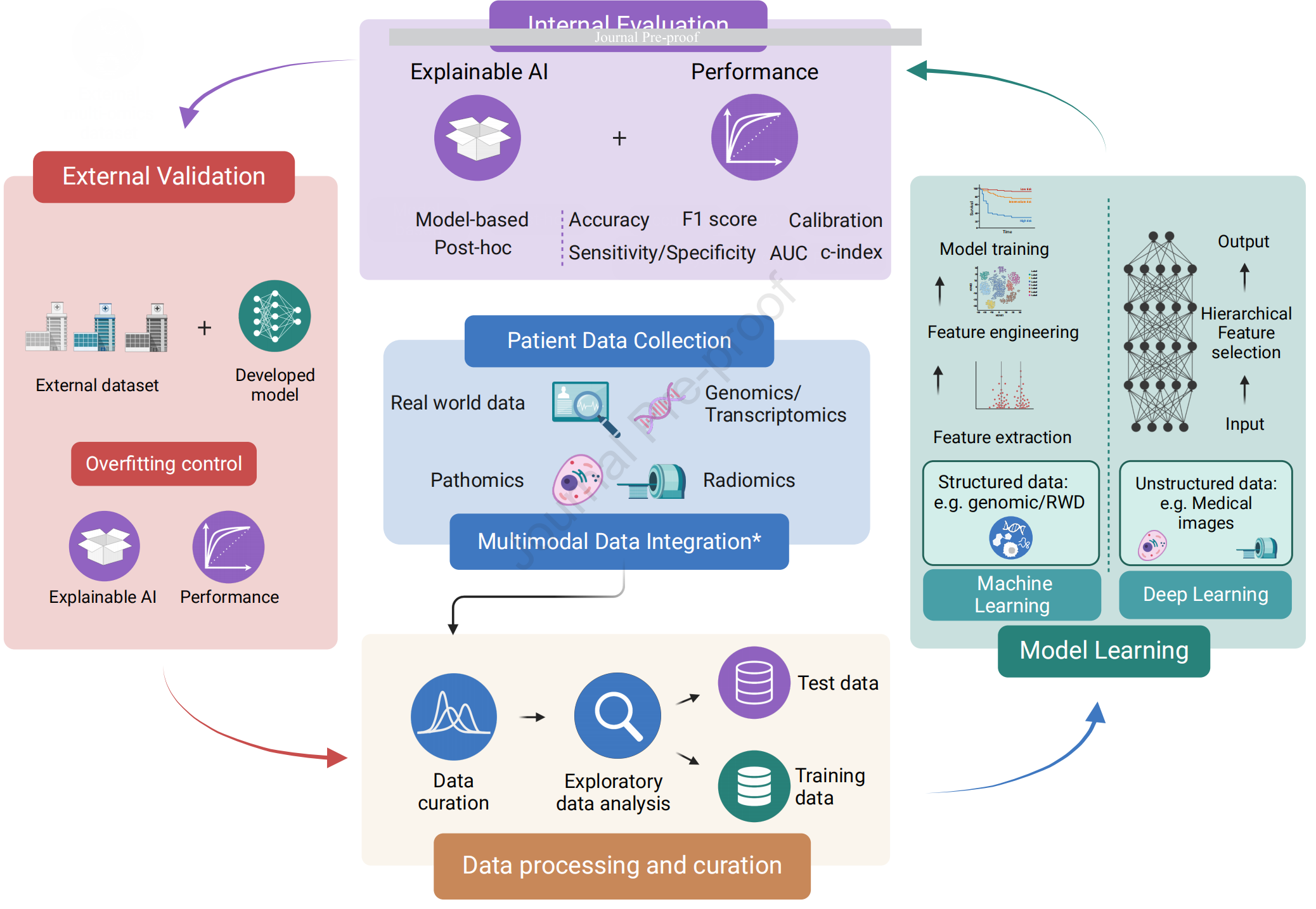
整个工作流程包含三个主要步骤:
-
数据处理与整合(Data processing and curation):
- 在这一步中,相关的组学数据(如基因组学、转录组学、蛋白质组学等,统称为“omics data”)、临床数据或图像数据被适当地收集、存储,并在适用的情况下进行预处理和整合。
- 预处理后的数据被划分为训练集和测试集,以便后续用于模型的训练和评估。
- 多模态数据整合可以在流程的不同阶段进行,这意味着可以将不同来源和类型的数据结合起来,以提供更全面的信息。
-
模型学习(Model learning):
- 在训练集上应用不同的技术让模型学习。如果数据类型是结构化的(例如,现实世界数据和基因组数据),则标准机器学习(ML)是合适的选择。
- 对于图像数据(如数字病理学和放射组学图像),主要使用深度学习(DL)技术。
- 学习的方法(监督学习、半监督学习、无监督学习)由最终目标和标记数据的可用性决定。
监督学习通常用于分类和回归任务,半监督学习适用于部分标记的数据集,而无监督学习则用于发现数据中的新模式。
-
内部和外部验证(Internal and External validation):
- 训练好的模型在测试集上进行性能评估,测试集包含了“真实情况”(ground truth)。
- 同时,解释模型是如何产生预测的,即通过可解释的人工智能(XAI)技术来阐明模型的决策过程。
- 模型的预测能力和可解释性在外部数据集上进行验证,以评估模型在未见数据(例如,来自不同医疗中心的数据)上的鲁棒性和泛化能力。
- 根据内部和外部评估的结果,可以提出新的假设,以完善数据收集并训练改进的模型。
这个流程强调了从数据收集到模型训练、评估和验证的全面方法,确保了模型的准确性和可靠性,这对于将AI技术应用于临床实践以预测免疫治疗的反应至关重要。
二、方法
2-1:文献检索
在2022年10月,进行了一项系统性的搜索(EA),搜索范围为以下电子文献数据库:
- PubMed
- Scopus
- Web of Science
- Cochrane Library
搜索时使用的关键词分为四类:
-
(1)数据类型
-
(2)治疗方法
-
(3)疾病状况
-
(4)用于分析的方法论
关键词通过布尔运算符(AND/OR)组合,如下所示:(1 OR 2 OR … 13) AND (14 OR 15 OR … 26) AND (27 OR 28 OR … 31) AND (32 OR 33 OR … 37)。
研究范围限定在1991年至2022年10月1日之间发表的论文,且语言为英语。
2-2:数据筛选和分析
在数据选择和分析部分,所有识别的研究都通过使用Mendeley参考文献管理和Excel软件进行管理(补充信息2)。
删除了重复的研究,并通过Mendeley软件和手动搜索了文章的全文。两位独立的研究者(AP, VM)在删除标题和摘要层面的重复项后,根据纳入和排除标准评估记录,最后在全文层面进行评估。
简而言之,该综述包括:
- 在期刊上发表的原创同行评审研究
- 使用机器学习(ML)和深度学习(DL)算法预测癌症患者免疫检查点抑制剂(ICI)疗效的研究
- 使用免疫治疗(IO)队列作为训练和/或测试和/或验证集的研究
- 对于基因组学和影像组学数据,研究中的患者数超过100例
2-3:数据提取
在数据提取部分,数据由两位独立的研究者(一位具有临床背景,另一位具有技术背景)根据所选研究的分类进行提取,这些分类包括:
- (1)基因组学、转录组学和表观遗传学(GV, LP)
- (2)影像组学(SER and MF)
- (3)病理组学(CG, MG)
- (4)真实世界数据和多模态数据(LM, MZ)
最后,另外两位独立的研究者(AP, VM)审查了所有提取的数据。
整合三种或以上数据模态的数据视为多模态数据,而任何包含两种模态且其中一种是真实世界数据的研究不被视为多模态。为了对识别的研究提供全面的总结,我们调查了包括研究的以下部分:
- (1)研究类型(回顾性/前瞻性)
- (2)数据来源(公共数据库/临床试验/机构)
- (3)癌症类型
- (4)患者数量
- (5)治疗类型
- (6)显著生物标志物
- (7)特征选择方法(如适用)
- (8)开发的模型
- (9)实现的结果
每个部分的结果以表格形式呈现。如果研究包括了除ICI队列以外的队列,表格将仅报告与ICI队列相关的结果。
2-4:研究目标
在本研究的第三部分,我们旨在识别和评估在四大类数据模态(基因组学/转录组学/表观遗传学、放射学、组织病理学图像以及真实世界数据/多模态数据)中用于预测对免疫检查点抑制剂(ICI)治疗反应的最先进的人工智能(AI)方法。
其次,我们旨在分析AI方法的价值,以识别作为ICI疗效预测的生物标志物或元生物标志物,横跨不同类型的癌症。
三、
3-1:确认的研究
图2总结了研究选择过程。总共有90项研究符合最终分析的条件;然而,还有另外40项研究(尽管它们不符合最终标准,但因其质量)被选入补充信息3的表S3中,原因如下:
- 标准1:作者认为使用机器学习(ML)方法和经典统计学混合方法的研究,例如只使用LASSO或Cox分析(n=9)而未使用经典ML的研究;
- 标准2:影像组学或基因组学研究中包含少于100名患者的研究(n=14);
- 标准3:没有ICI队列的研究(n=2);
- 标准4:研究未预测ICI疗效,而是预测两种不同数据模态创建的两个不同模型之间的相关性,例如影像组学特征预测肿瘤浸润淋巴细胞(TILs)(n=8);
- 标准5:使用ML或DL进行特征选择但未用于疗效预测的研究(n=7)。
几乎所有(98%)识别的AI分析都是对来自回顾性或前瞻性观察研究队列或随机临床试验患者队列的数据进行回顾性分析。通常,数据并非是为了使用AI方法进行分析而预先收集和设计的。
Figure 2 展示了一个PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analyses)流程图,它是一种用于系统综述和元分析的标准流程图,用于说明研究选择和排除的过程。
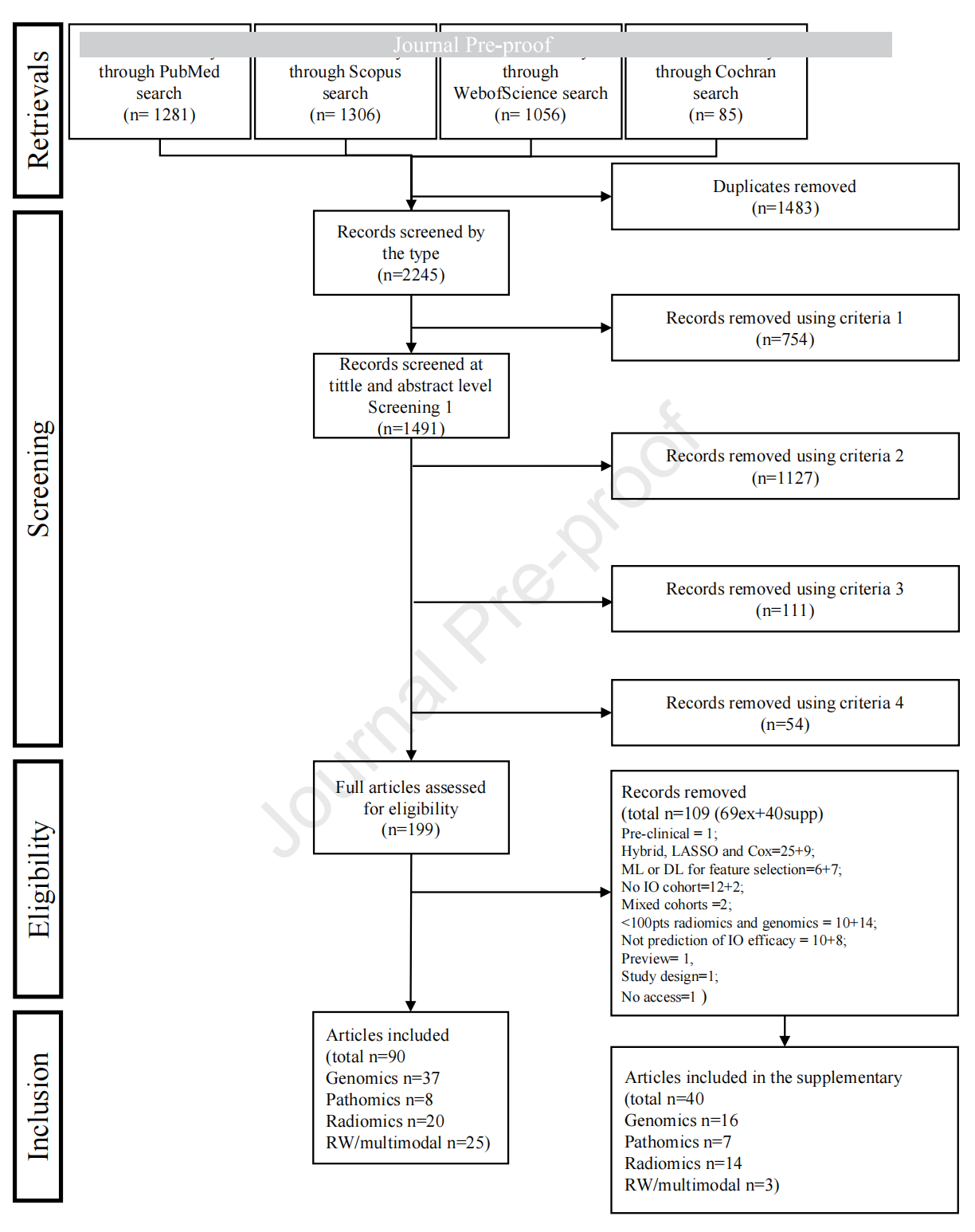
以下是对图中描述的步骤的分析:
-
初始搜索结果:
- 从数据库搜索中总共识别出3728条记录。
-
去除重复记录:
- 在筛选记录类型后,移除了重复的记录,这一步骤是为了确保评估的独立性和避免偏倚。
-
筛选记录类型:
- 完成了1491条记录的标题和摘要筛选。这个步骤是为了确定哪些研究可能符合综述的纳入标准。
-
全文筛选:
- 对199条记录进行了全文筛选,这是一个更深入的评估阶段,研究者将检查全文以确定其是否满足纳入综述的具体标准。
-
排除不符合条件的研究:
- 在全文筛选过程中,有110条记录因为不符合纳入标准而被排除。
-
最终纳入的研究:
- 共有90项研究被纳入最终的系统综述分析中。
- 这些研究根据数据类型的不同被分为几个类别:
- 基因组学(Genomics)相关的研究有37项,占41%;
- 数字病理学(Pathomics)相关的研究有8项,占9%;
- 放射组学(Radiomics)相关的研究有20项,占22%;
- 现实世界数据和多模态数据(Real-world and multimodal data)相关的研究有25项,占28%。
这个流程图提供了一个清晰的视角,展示了系统综述中研究选择的严谨性,确保了最终纳入的研究是高质量和相关的,从而为读者提供了可靠的证据基础。通过这种方式,研究者能够评估不同AI方法在预测免疫治疗疗效方面的有效性,并为未来的研究方向提供依据。
3-2:不同数据类型中的生物标志物
人工智能技术可以从多种不同的癌症类型中提取大量与免疫治疗(IO)疗效相关的生物标志物,这展示了模型的普遍适用性。生物标志物可以根据提取它们的数据进行分组,如下面的图3所描述。
Figure 3 通过一个分层的球形模型展示了从基于人工智能(AI)的预测算法中识别出的相关生物标志物。这些生物标志物根据使用机器学习(ML)方法分析的多种数据来源标准进行了分组。
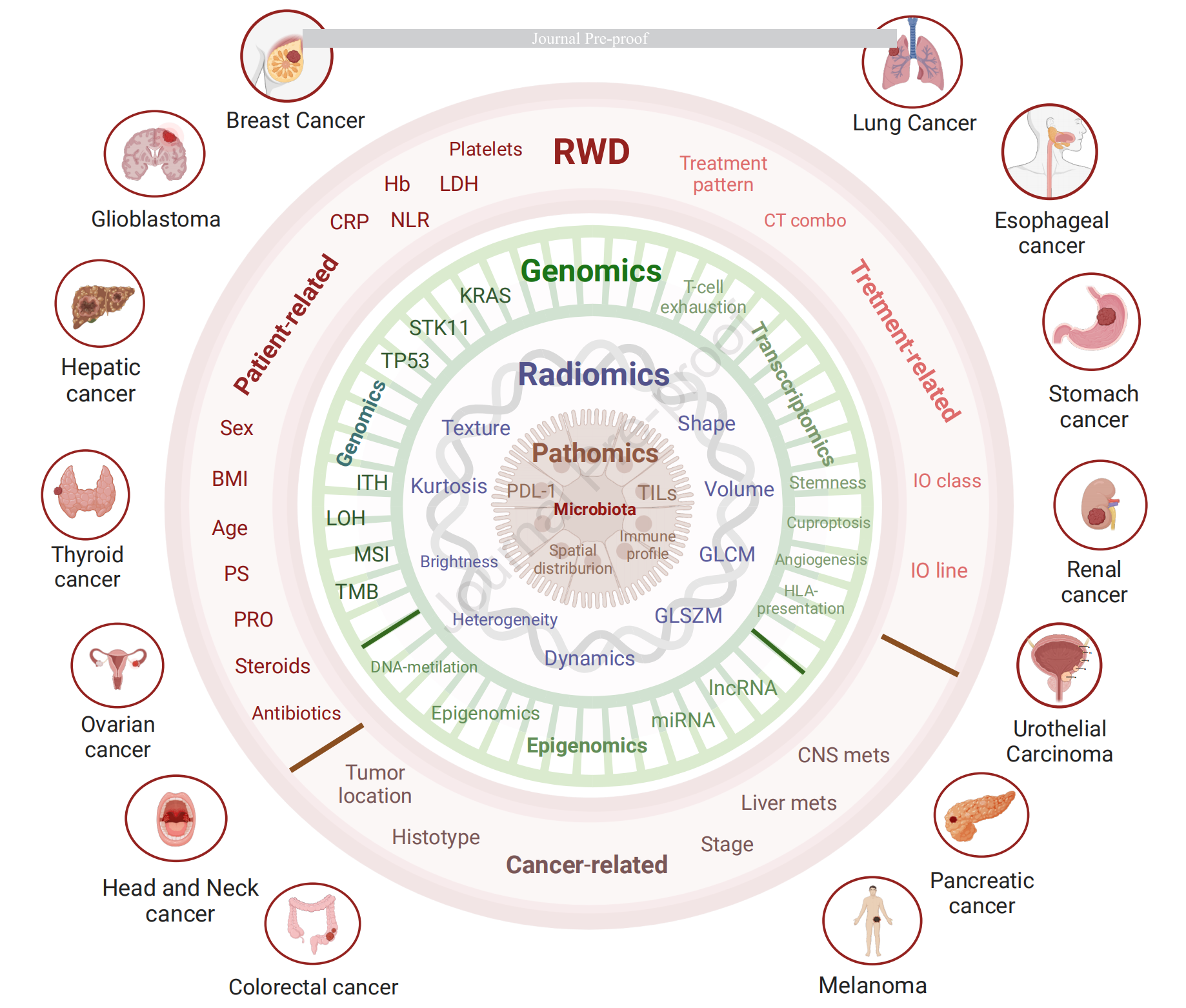
以下是对图中描述的分层和生物标志物的分析:
-
最外层 - 现实世界数据(Real World Data, RWD):
- 这一层包含了与患者、癌症和治疗相关的特征。
- 举例的生物标志物包括
乳酸脱氢酶(LDH)、中性粒细胞与淋巴细胞比率(NLR)、C反应蛋白(CRP)、体重指数(BMI)、患者表现状态(PS)、中枢神经系统(CNS)受累情况、化疗(CT)和免疫治疗(IO)的使用。
-
基因组学层(Genomics):
- 包含了
基因组学、表观基因组学和转录组学的数据。 - 举例的生物标志物包括
肿瘤内异质性(ITH)、杂合性丧失(LOH)、微卫星不稳定性(MSI)、肿瘤突变负荷(TMB)、微小RNA(miRNA)和长非编码RNA(lncRNA)。
- 包含了
-
放射组学层(Radiomics):
- 包括了基于影像的第一阶统计、形状基础统计、矩阵和delta放射组学特征。
- 举例的特征包括
灰度共生矩阵(GLCM)和灰度大小区域矩阵(GLSZM)。
-
核心层 - 数字病理学(Pathomics)和微生物组(Microbiota):
- 核心层包含了从病理图像分析得到的生物标志物,如
PD-L1的表达和肿瘤浸润性淋巴细胞(TILs)的空间分布。 - 微生物组数据可能与肠道微生物群等相关。
- 核心层包含了从病理图像分析得到的生物标志物,如
这个球形模型的展示方式有助于理解不同数据类型和来源的生物标志物是如何通过AI算法被整合和分析的。通过这种多层次的分析,研究者可以更全面地理解肿瘤的生物学特性,以及如何利用这些信息来预测免疫治疗的反应。这种综合性的方法可能有助于发现新的生物标志物,从而为癌症患者提供更个性化的治疗方案。
3-3:遗传学
本研究提供了37项使用基因组学、转录组学和表观遗传学数据的已识别研究的概览,见表1。
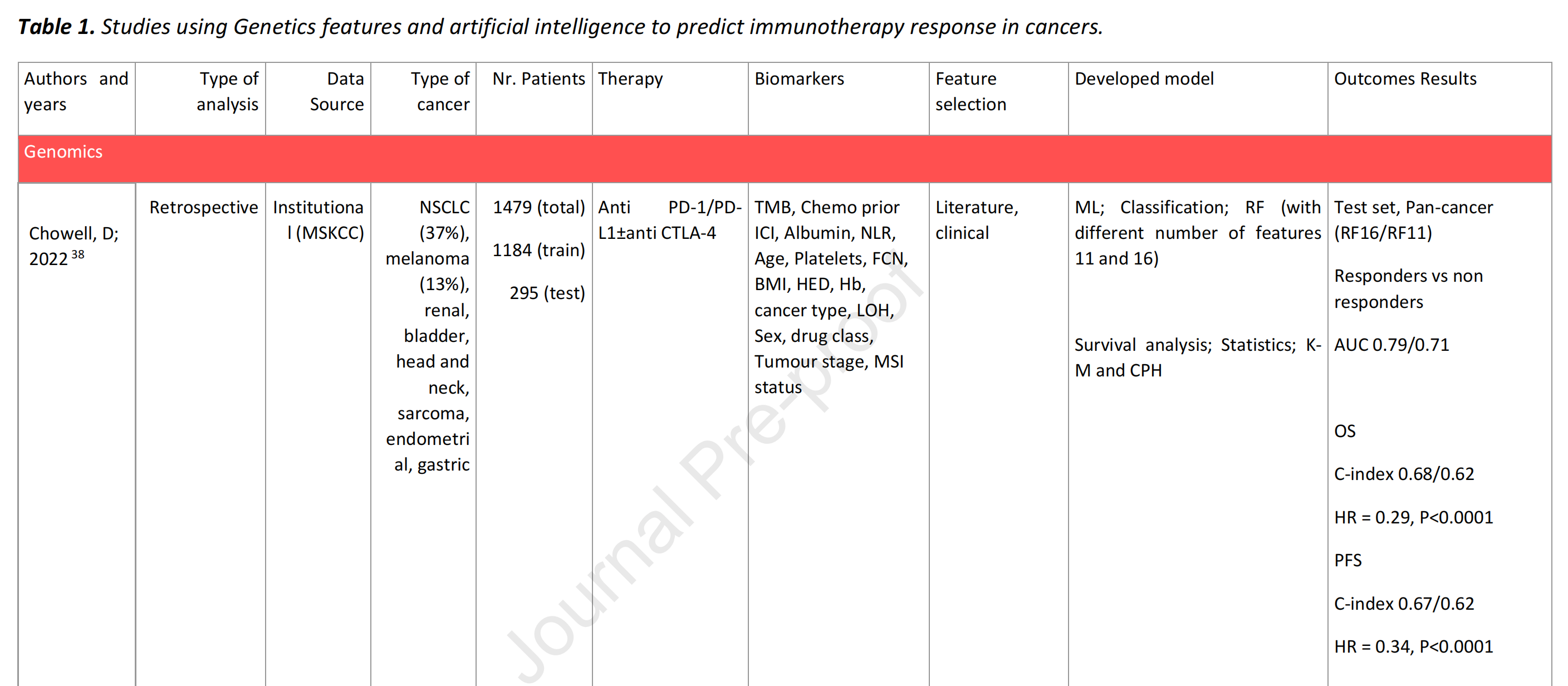
其中,24%(n=9)使用基因组学数据,60%(n=22)使用转录组学数据,16%(n=6)使用表观遗传学数据,且有65%(n=24)的选定文章发表于2022年。
最常研究的单一癌症类型是非小细胞肺癌(NSCLC,22%,n=8),其次是黑色素瘤(11%,n=4)和膀胱癌(8%,n=3)。然而,大多数研究(35%,n=13)使用了多个癌症队列。
在选定的研究中,我们确定了构建预测性AI模型的两种场景:
- (1)标准ML或DL模型直接预测患者结果(48%),
- (2)标准ML或DL模型创建基因组特征,通过统计分析验证,将患者分层为低风险和高风险组(52%)。
73%(n=27)的研究使用了来自公共数据平台的数据集,如癌症基因组图谱计划(TCGA)34、基因表达综合数据库(GEO)35和cbioportal36,37。
3.3.a:基因组学
为了成功实施AI方法,35%(n=13)的研究使用了多种癌症类型来开发模型。例如,Chowell等人38使用16个基因组特征和16种癌症类型开发了一个随机森林分类器,以预测IO的响应。该模型在预测总生存期(OS)和无进展生存期(PFS)方面区分响应者(R)和非响应者(NR),AUC分别为0.79,明显优于用于此目的的FDA批准的生物标志物TMB(总突变负担),在预测OS(P < 0.0001)和PFS(P < 0.0001)方面表现显著。
处理高维数据的方法各不相同——大多数研究(92%,n=34)使用了特征选择方法,主要分为:
- 由临床医生驱动的假设(临床专业知识、可用文献,18%,n=6)
- 经典统计学(特征相关性、单变量分析,15%,n=5)
- 自动和数据驱动的特征选择ML技术(基因集富集分析(GSEA)、LASSO、单变量Cox分析、随机森林、支持向量机、mRMR和其他ML模型,68%,n=23)
此外,基于网络的计算方法40显示了解决这一问题的潜力。例如,Kong等人42使用该方法结合逻辑回归,在三个不同的外部数据集中创建了一个ICI治疗生物标志物,实现了对响应者和非响应者分类的稳健预测(AUC 0.69-0.79)。
只有14%(n=5)的研究使用了DL技术。Fang等人43开发了一个深度患者图卷积网络(DeePaN),将100个电子健康记录(EHR)和基因组数据特征整合起来,将患者分为五个亚组,这些亚组在总生存期(OS)上显示出显著差异(P值<0.0001)。35%(n=13)的研究代码是公开可用的。
一些研究使用AI工具显示了比标准ICI生物标志物更好的性能。结果确认了TMB、KRAS、TP53、STK11和MSI在整合额外生物标志物(例如,临床特征、NLR、LDH、白蛋白、疾病负担、PD-L1)时,是预测AI算法中最相关的。再次,与TMB相关的LASSO评分用于预测尿路上皮癌患者对ICI的响应,有助于将治疗分层为ICI。最后,这些AI工具发现了新的候选生物标志物,例如HLA-LOH和基因组内肿瘤异质性(ITH)。
3.3.b:转录组学
使用转录组学数据的研究主要报告了基于基因签名的模型,这些模型在不同癌症类型中优于传统的生物标志物,如PD-L1。45-47
此外,AI工具的使用允许发现以前未知的生物标志物。例如,Charoentong等人48使用ML来识别肿瘤免疫原性的决定因素,从而开发了免疫表型评分。Zheng等人49开发了一个包含生物标志物的预测模型,在ccRCC治疗中实现了AUC为93%,表明AI算法可以识别更精确和有效的生物标志物。
此外,AI-转录组学生成了新的RNA基生物标志物,例如癌症干细胞性、铜蛋白氧化、AGR(血管生成)、HLA展示、T细胞耗竭和趋化因子信号的生物标志物。
3.3.c:表观遗传学
AI在发现表观遗传学生物标志物方面显示了显著的潜力。
首先,发现了许多基于长非编码RNA(IncRNA)的签名:一个与肿瘤浸润免疫细胞相关的lncRNA(TIIClncRNA)、免疫相关lncRNA签名(IRLS)和肿瘤浸润B淋巴细胞Inc签名(TILBlncSig),以及低级别胶质瘤、结直肠癌和不同类型癌症中ML模型,用于预测ICI疗效或作为独立的危险因素。
此外,AI驱动的方法已被应用于DNA甲基化数据的分析
- Filipski等人50揭示了基于潜伏甲基化组件(LMC)的签名对于预测转移性黑色素瘤患者的ICI具有预测性。
- Xu等人51展示了DNA甲基化概况在预测不同癌症中的ICI响应方面的潜力,使用了一个高性能的支持向量机(SVM)模型。
- Pan等人52在一个与免疫表型相关的甲基化签名(iPMS)中识别了五个CpG位点,提供了免疫异质性信息,并为肺腺癌提供了潜在的临床治疗指导。
3-4:影像组学
纳入标准筛选了20项使用影像组学特征的研究(表2)。
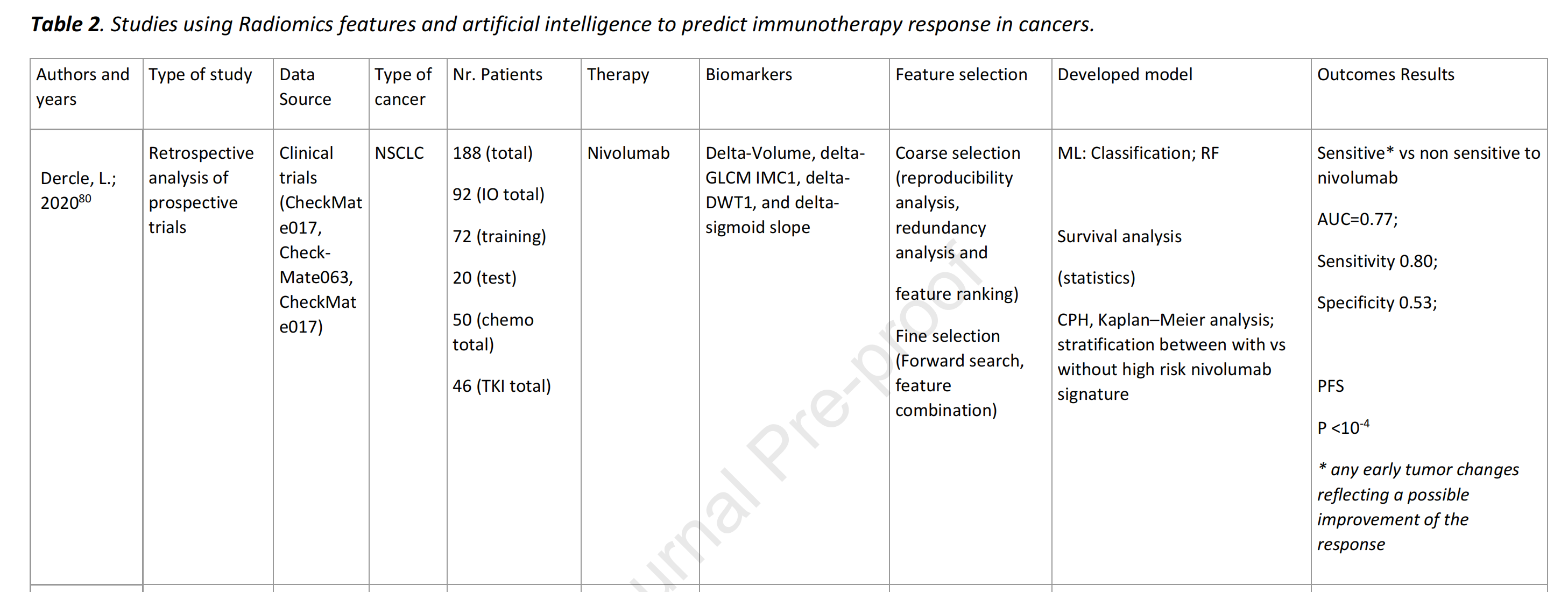
由于许多论文使用了少于100名患者(在补充信息3的表S3中),我们包括了最初因这一标准而被排除的11项研究。大多数研究(60%,n=12)是在非小细胞肺癌(NSCLC)患者中进行的,其次是黑色素瘤(20%,n=4)的研究。只有3项研究(15%)的代码是公开可用的。
总的来说,在选定的研究中,存在两种典型的工作流程。
- 第一种包括手动或半自动图像分割,然后是特征提取,这是学习过程的一部分,接着是特征选择,最后是ML预测(75%的研究,n=15)。
- 第二种方法包括使用DL模型(25%的研究,n=5),主要是CNN模型,其中分割可以整合到DL架构中,特征不是手动定义和选择的,而是模型从原始数据中学习。
使用第一种基于ML的方法的最大且最近的研究是由Dercle等人进行的,分析了575名在KEYNOTE-002和KEYNOTE-006试验中接受ICI治疗的黑色素瘤患者。使用随机森林算法,一个结合了4个成像特征的放射组学签名(2个与肿瘤大小相关,2个反映肿瘤成像表型的变化)被识别出来,并与标准方法(RECIST标准)相比,在估计总生存期(OS)方面表现更佳(AUC 0.92 vs 0.80)。
在第二种基于DL的方法的研究中,Tian等人使用DL CNN提取DL特征和一个完全连接的网络,该网络结合了DL特征、预定义的放射组学特征和临床特征,以创建一个PD-L1表达签名。这个签名进一步被验证用于预测无进展生存期(PFS),使用高和低风险的Kaplan-Meier组分层(p=0.01)。
元生物标志物
关于元生物标志物的发现,不同特征的重要性直接反映在开发的算法中,因此很难总是得出关于单个生物标志物值和哪个生物标志物对ICI预测起作用的结论。
一些显著的生物标志物包括预测NSCLC对nivolumab、docetaxel和gefitinib敏感性的放射组学签名80;一个基于TMB的放射组学生物标志物81;以及一个用于预测程序性死亡配体1(PD-L1)表达的深度学习分数(DLS)82。
此外,研究还确定了潜在的放射组学标志物,用于预测PD83,84、生存结果85,86以及在NSCLC和黑色素瘤患者中预测免疫治疗反应87,88。放射组学签名已被开发出来,用于预测接受ICI治疗的患者的肿瘤免疫表型和临床结果89,90。有趣的是,一些论文(10%)也关注了肿瘤周围纹理85,91,探索肿瘤微环境。
最后,一些放射组学特征似乎在大多数算法中都是重复出现的,例如:纹理、形状、体积、峰度、异质性、亮度、动态、GLCM和GLSZM(图2)。
3-5:病理组学
表3总结了8项使用病理组学数据的研究,其中50%(n=4)发表于2022年。
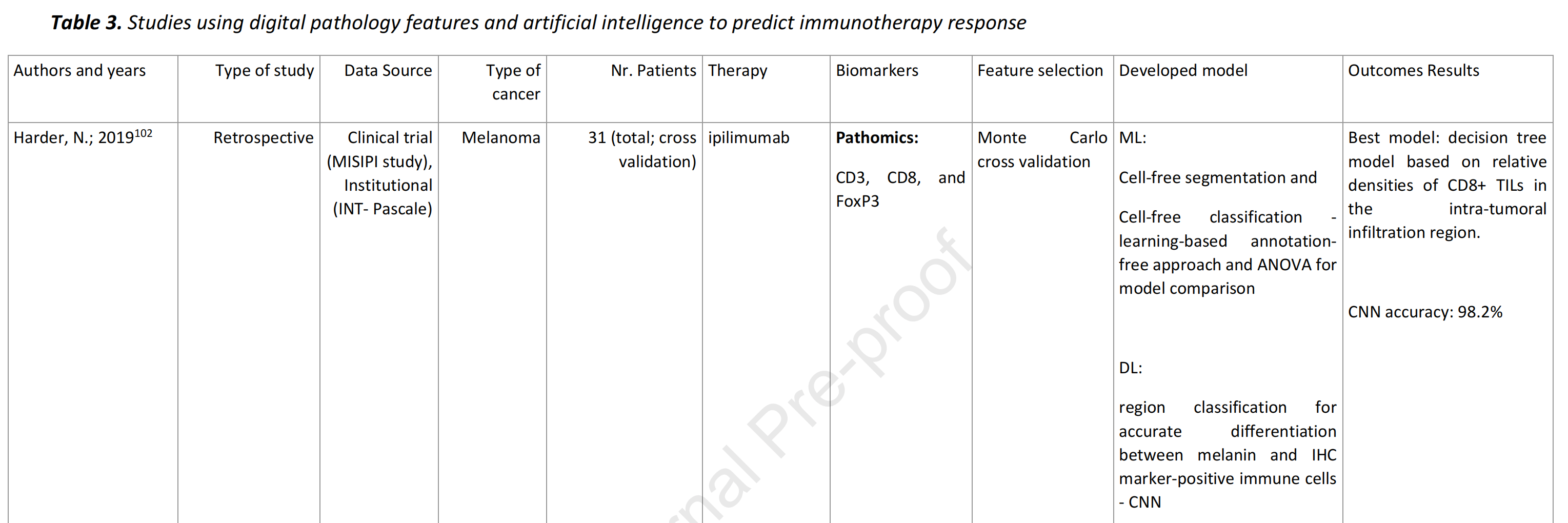
87%的研究是在非小细胞肺癌(NSCLC)上进行的(n=3),黑色素瘤(n=2),或包括其他癌症类型的队列(n=2)。(75%,n=6)使用了DL方法,主要是CNN。代码可供38%(n=3)的研究使用。
在病理组学中,标准ML方法用于(1)执行分割和分类,(2)创建一个预后评分,(3)验证一个已开发的签名。例如,Johannet等人100使用了一个两阶段的Inception-V3 CNN进行分割和多变量分类,将CNN预测和临床数据整合起来,以预测黑色素瘤患者的客观缓解率(ORR,AUC=0.8)并将患者分为高风险和低风险进展(P=0.003)。
至于第三种方法,Chen等人101使用了一个图像分析系统(inForm)来创建一个多维肿瘤浸润免疫细胞(TIICs)签名,用于胃癌。开发的签名用于不同的ML模型中,以识别对ICI有反应的患者,表现最佳的模型(AdaBoost)实现了AUC为0.85,揭示了单一生物标志物的不足。
表3和图3总结了从组织学图像构建的最频繁的生物标志物。在这些中,
PD-L1和TILs是最常探索的DL方法(表3)。
- Harder等人102在恶性
黑色素瘤中发现了基于CD8+肿瘤浸润淋巴细胞的决策树模型,这可能作为诊断工具用于ipilimumab。 - Park等人103揭示了三种免疫表型(炎症、免疫排斥和免疫沙漠)作为预测晚期NSCLC对ICI反应的潜在生物标志物。
- 关于PD-L1,Hu等人104展示了CNN在预测黑色素瘤和肺癌患者对PD-1抑制剂的响应方面的潜力。
- Choi等人105展示了AI驱动的TPS分析仪减少病理学家之间观察者变异并提高对NSCLC治疗反应预测的准确性的有效性。
最后,在一部分研究中,与匹配的分子数据配对的数字病理学数据集允许探索从苏木精和伊红(H&E)图像预测分子生物标志物(例如驱动基因突变106,107)。
3-6:真实世界数据
应用于RWD分析的标准ML方法,在20项研究中得到体现。
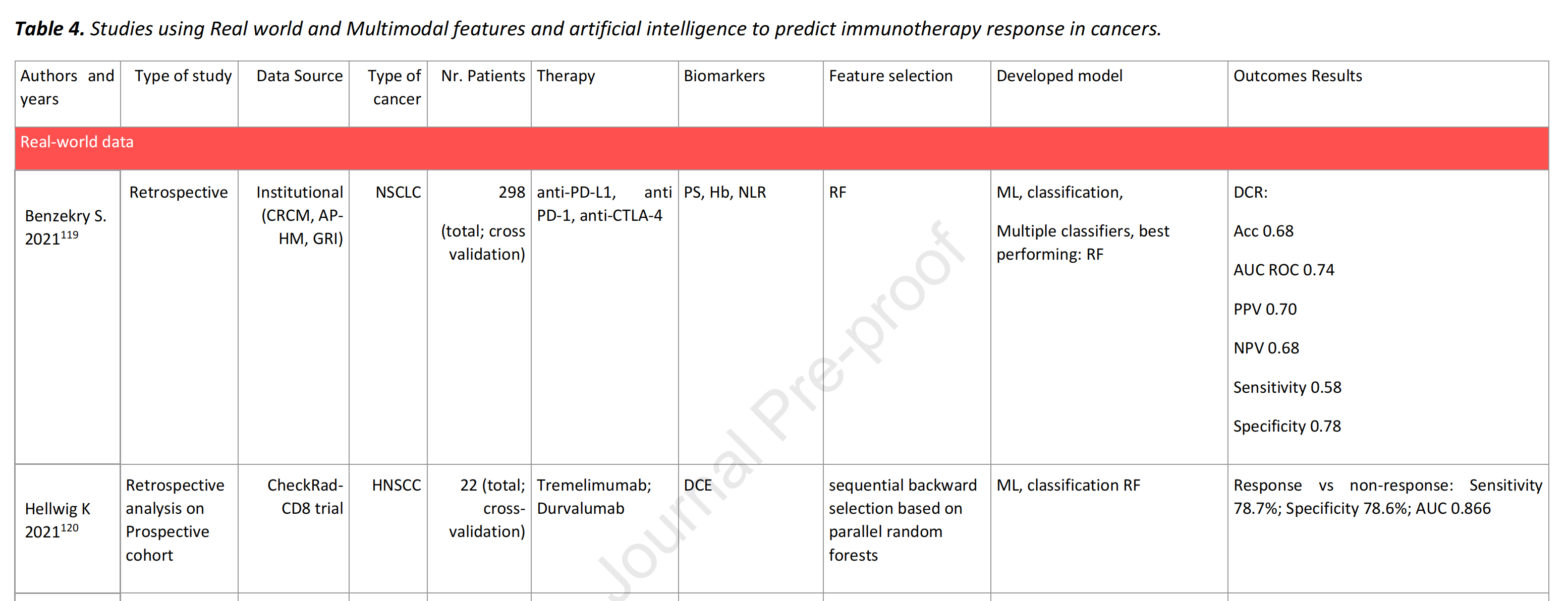
20%的研究集中在非小细胞肺癌(NSCLC)患者,20%集中在黑色素瘤患者,15%集中在多癌症患者队列。大多数研究(表5中的16项,占80%)使用了监督式分类(75%的标准ML,12.5%的DL,12.5%的标准ML和DL)来预测响应者与非响应者。两项(10%)研究使用了ML生存分析,利用连续结果(OS和PFS)。实施ML方法的主要目标是利用这些数据,通过捕捉使用的特征之间的非线性交互作用,以实现对ICI疗效的更准确预测,同时使用易于获取且成本效益高的数据。例如,Gupta等人110开发了一个贝叶斯网络模型,利用社会人口统计特征、肿瘤特征和先前的治疗类型来预测接受nivolumab治疗的RCC患者的OS。他们的模型在外部验证队列中优于IMDC风险评分111,这是一个广泛用于RCC靶向治疗的预后模型,实现了12个月OS的平均AUC为0.76,而IMDC的AUC为0.69。例如112,一项研究使用全连接的DL来估计RECIST定义的结果和PFS。开发的模型仅使用文本报告的数据作为输入,在82%的情况下正确预测了RECIST PFS数据,时间跨度为2个月。他们进一步将模型的预测与经过培训的医学肿瘤学家的人工审查进行了比较,并取得了类似的结果。基于RWD的AI算法识别的生物标志物(图2)可以分为三类:(1)患者相关的,(2)治疗相关的,(3)癌症相关的。在患者相关的RW生物标志物中:NLR、LDH、Hb、CRP、PS状态、血小板、BMI、PRO、抗生素、类固醇、年龄、性别和肠道微生物被识别。治疗信息(例如,ICI类别的类型、线和IO为基础的治疗类型(与CT结合或不结合))被用来喂养算法。最后,最常见的癌症相关生物标志物是肿瘤位置、组织类型、阶段、肿瘤负担、肝脏和CNS转移。
3-7:多模态数据
该部分包含5项回顾性研究,这些研究整合了多模态数据(至少3种模态)以预测ICI疗效。它们都采用了两步算法开发方法:首先,基于不同的数据组合创建了一个签名,然后提供了一种预测患者生存的方法。
其中,四项研究(占80%,n=4)使用DL来整合数据。NSCLC研究113展示了多模态整合在预测ICI疗效方面的价值。使用多模态数据,通过中间融合114整合的模型在同一数据集上优于所有单模态模型,包括TMB、放射组学和病理组学,即使某些患者的数据不可用,其AUC仍达到0.80。同样,Yang等人115提出的整合DL模型,该模型整合了晚期NSCLC患者的序列放射组学、实验室数据和临床信息,显示出令人印象深刻的预测能力,超越了传统的RECIST评估。
此外,AI驱动的发现工具进一步帮助识别了新的免疫表型,例如由Shen等人116描述的免疫检查点阻断治疗患者的LAG-3+CD8+ T细胞群体。这种独特的表型在黑色素瘤和尿路上皮癌患者中作为预后标志物,表明了较差的预后。
Park等人117开发了利用医学影像数据的复杂AI模型,该模型使用了来自FDG-PET的定量流式细胞术和RNA-seq免疫概况,有效地预测了肺腺癌的CytAct评分。同样,Mu等人118在不同队列中结合了基因组学、PET放射组学和临床数据,并在149名ICI患者的队列中验证了算法。然而,所有选定的研究都具有小规模数据集(<900名患者),尽管具有高维度,并且只有使用外部数据集验证了结果。代码可供2项研究(占40%)使用。
四、讨论
我们对在泛癌环境中预测ICI治疗疗效的数据驱动生物标志物的最新AI方法(ML和DL)进行了批判性评估。据我们所知,这是首次对应用于免疫肿瘤学的AI方法进行系统性回顾,涵盖了所有癌症类型的不同数据模态。
我们对90项识别的研究进行了评估,这些研究涵盖了癌症的四大数据模态:基因组学(包括转录组学和表观遗传学)、病理学(病理组学)、放射学(放射组学)、真实世界和多模态数据。我们报告称,用于ICI疗效预测的新型AI方法的使用正在增加,其中80%(n=72)的纳入文章发表于2021年至2022年,其中大多数(85%,n=84)是回顾性的。
生物标志物的发现通常涉及分析潜在的信息性定性特征(如组织形态学)或定量特征(如基因组学、血液检查)及其与临床结果的关系。137 AI/ML/DL方法允许探索高通量数据,以及变量之间的非线性关系,以更好地选择独立影响预后的特征(例如LASSO分析);这可能导致重新考虑以前被丢弃的生物标志物。在本综述中,我们识别了这些“新技术”在所有数据类别中的潜力。
确定与ICI响应相关的基因具有挑战性,因为多组学数据集的维度越来越高,这是由于测序技术的改进。ML提供了解决高维数据问题的方案,包括基于监督的ML基因选择、无监督聚类和DL模型。一些研究开发了使用非ICI治疗的非ICI治疗方案,并使用ICI治疗的病人队列进行了验证,这表明其具有预后而非预测的性质。此外,为了开发和验证AI,需要结构化的公共数据存储。
现有的公共平台,如癌症成像档案(TCIA)138、TCGA34和GEO35,是癌症开放数据存储的良好示例,研究人员可以访问进行研究所需的大量数据,而Cbioportal36,37提供了一个开源资源,用于交互式探索基因组数据集。实际上,许多基因组学(表1)文章都是基于这些公共平台。尽管它们具有优势,但这些平台通常只包含具有多种数据模态的小患者队列,且没有完整的结局信息,因此具有高维度的删失数据。最后,几何网络分析可以利用基因通路信息,而不是上述方法。
放射学是预测癌症对ICI疗效的领域之一,这得益于利用放射学图像喂养新兴AI技术。已经进行了两项系统回顾/元分析140,141,专注于接受抗PD-(L)-1治疗的NSCLC患者140和所有癌症类型但排除使用DL方法的研究141。
数字化的组织学玻璃载玻片转换为全玻片图像(WSI)的进步使病理学迅速发展。计算分析数字化的组织学载玻片可以提取有价值的信息,以改善癌症免疫治疗中的临床决策(即组织学、PD-L1 TPS图像)。然而,免疫病理学相对未被探索,大多数研究集中在诊断或识别可能与ICI受益相关的生物标志物(例如MSI142、PD-L1状态143和炎症基因144)。DL在直接从载玻片提取生物标志物方面显示出巨大的潜力,并允许进行预测性生物标志物的发现,但是,由于数字数据集的稀少,验证和将这些模型纳入临床实践是具有挑战性的。因此,数字能力建设和将它们引入常规组织病理学工作流程是必要的。
在真实世界环境中,ML模型可以处理通常未处理的大量信息,例如电子健康记录(EHR)。与其他数据模态相比,RWD易于获取、常规收集,并且更容易处理,因为它不需要专家特定的注释或图像预处理。
此外,神经语言处理(NLP)或文本挖掘可以用来从EHR中提取更多信息,但数据准确性的控制是必要的,以完全信任来自自动化过程的结果,例如使用ChatGPT。RWD的整理对于算法验证和广泛使用至关重要,因为它比其他数据类型更容易原始不准确。
来自RWD的AI生物标志物与传统统计方法一致,确认了诸如ECOG PS、NLR和LDH等因素的重要性(表4)。这加强了在适当开发、验证和解释时对AI算法的信心。145整合多模态数据仍然是“锦上添花”,AI因其能够提取和结合不同模态的互补上下文信息而受到认可,从而改善了肿瘤学中的决策制定。13,114,137,146
最近,有三种不同的多模态数据整合方法被报道:
- 1)早期融合——在将数据或特征输入模型之前,从原始数据或特征级别创建一个联合表示
- 2)晚期融合——为每个模态训练一个单独的模型,并在决策级别聚合单个模型的预测
- 3)中间融合——首先分别处理单模态特征,然后进行融合步骤和后续分析融合表示。114
与传统统计方法和单模态模型相比,整合多模态数据可以通过合并已知的单个/原始生物标志物和从不同来源发现新的生物标志物,从而创建元生物标志物。多模态模型已显示出提高性能的潜力,与单模态模型相比,在同一数据集上的AUC从0.65增加到0.80。113
数据整合也提供了许多优势,包括通过考虑表型、基因型和暴露组(例如,使用可穿戴设备监测的新类型行为数据)来开发个性化医学的机会,未来将导致更深入的AI表型分析。
为确保多模态模型最终可以被转化为临床应用,重要的是这些模型应该在临床环境中可用的数据上进行训练;临床特征、成像和简单的分子测试。重要的是,该领域不应该产生依赖于昂贵且技术上困难的数据源(例如全基因组测序)的多模态模型,这些模型在临床中不太可能用于预测。构建依赖于简单数据类型的多模态模型增加了在临床环境中部署的可能性,允许大规模交付精准医学。
尽管我们的研究具有系统性设计,但仍存在一些局限性,例如排除与ICI治疗直接相关的研究、样本量小的出版物(<100)和仅使用AI进行特征选择的研究。为了解决这个问题,补充表S3被添加以包括一些符合这些标准的排除出版物。
尽管具有前景和潜力,但在将AI整合到免疫肿瘤学临床实践中的生物标志物发现和实施之前,仍有一些持续的挑战需要解决:数据稀缺性和结构问题:开发ML方法的主要限制之一是对大量高质量数据的需求。肿瘤学数据本质上是复杂的,通常高维、不完整、有偏见、异质和有噪声。146
为了实现良好的算法性能,需要大量高质量的数据,这需要耗时的整理和大量的预处理。模型异质性:目前存在许多不同的基于ML的模型,这给研究人员选择使用哪种方法带来了困难。当选择模型时,研究人员应考虑可用的数据(在数量和多样性方面),并意识到在低体积结构化数据的情况下,经典的ML方法是足够的。147
在研究和结果报告的标准化、协议和指导方针方面,医学AI系统必须通过随机对照试验进行评估,这是当前的标准。148
报告指南,如CONSORT-AI149和SPIRIT-AI150,现在包括AI特定的建议,而ML-CLAIM151清单旨在提高透明度。然而,许多研究缺乏对训练、测试和验证队列选择、方法论发展、验证、与标准方法的比较及其临床整合计划的清晰记录。ESMO-GROW等倡议可能为包括新ML方法在内的肿瘤学RW证据研究提供更新的指导。随着该领域的进步,越来越多的ML方法在临床试验中得到测试,遵循这些指南是强制性的。
生物标志物需要通过监管机构的批准程序,这是重要的一步,但需要标准化。同样,为了将基于AI模型及其构建的工具整合为医疗软件设备,需要开发一个通用的认证流程。这对于负责任地在临床中部署AI至关重要,并且是符合良好医疗实践标准的要求。
模型的可解释性和预测的可解释性
最后,医学中ML采用的主要障碍之一是对模型的缺乏信任。147,148,152
算法复杂性可以通过XAI方法照亮,这些方法以直观的方式展示结果,使没有AI经验的临床医生和患者易于理解。XAI还允许我们询问模型的设计和预测决策策略,以增强生物学发现,例如揭示免疫治疗原发性抵抗的分子机制
目前的大多数研究,以及本综述中包括的研究,都没有在其工作中包括对模型及其预测的解释或解释。这一关键步骤,XAI,应在任何ML管道中是必要的。对于DL模型,例如从图像预测生物标志物,XAI更具挑战性,但例如使用显著性映射技术等持续的方法创新提供了解决方案,如果此类工具要在临床中实施,必须得到支持。
模型的泛化性和稳健性
临床实践中的ML模型需要接触来自多个医疗中心的不同数据源,以防止由于数据结构、染色强度、患者人口统计学、性别等差异引起的算法偏差。在研究中越来越多地报告了模型的外部验证(本综述中包括的研究中有50%),主要是那些使用公共数据源的研究,即基因组学研究。
研究设计
本综述中的研究缺乏对预测算法立即纳入临床实践的清晰预定义终点和管道。为了推进,未来的研究应设计为前瞻性临床试验,具有准确的预计划的AI方法,例如I3LUNG试验(NCT05537922)。需要更多的数据驱动的观察性研究,特别是对于基于生物标志物的发现,例如APOLLO 11试验(NCT0555096)。
五、总结
本系统回顾证实了AI在发现各种癌症中ICI疗效的预测性生物标志物方面的日益增长的应用,这种方法可以扩展到其他领域,如化疗或靶向治疗的效率。
AI方法提供了从复杂数据中获得的新见解,但基于AI的“软件生物标志物”的发展受到回顾性数据集、多样的AI方法和不透明的决策过程的限制。尽管这些研究提供了一些假设生成性的见解,但直接临床实施受到限制。
为了创建可解释和负责任的AI工具,需要进行大规模的前瞻性验证研究。这样的工具对于IO至关重要,其中需要新的元生物标志物来预测反应。


















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









