







小罗碎碎念
推文速览
第一篇文章通过整合三个机构的 6172 例激素受体阳性早期乳腺癌病例数据,开发出多模态深度学习工具 Orpheus,能从 H&E 全切片图像推断 Oncotype DX 复发评分,在识别高风险病例和预测远处转移复发风险方面表现优异,为乳腺癌精准治疗决策提供了新依据 。
第二篇文章通过对 435 例来自癌症基因组图谱(TCGA)的结肠腺癌全切片图像进行自监督学习,构建 47 个组织形态表型簇(HPCs),在独立临床试验中验证其可重复性和预测能力,揭示其与患者生存、治疗反应、免疫景观及致癌通路的关系,为结肠癌治疗策略提供依据。
第三篇文章提出基于自监督学习的 BEPH 基础模型,利用 1100 万张未标记组织病理学图像预训练,在多种癌症检测任务(包括补丁级分类、WSI 级分类和生存预测)中性能卓越,且具有良好的可解释性,同时探讨了模型的优势、挑战及未来发展方向。
背景补充
- 早期激素受体阳性/人表皮生长因子受体2阴性(HR+/HER2-)乳腺癌的研究流程
- 乳腺癌病理分析及建模预测复发评分的过程
- 利用自监督学习算法Barlow Twins从癌症基因组图谱(TCGA)结肠腺癌数据集中提取特征的流程
- 基于 TCGA 训练集、AVANT 临床试验集的结肠腺癌图像分析流程
- 基于组织病理学图像的癌症相关模型流程
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量52,000+,交流群总成员1100+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
一、Orpheus:基于 H&E 图像预测乳腺癌复发评分的新利器

一作&通讯
| 作者类型 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Kevin M. Boehm Omar S. M. El Nahhas Antonio Marra | 1. 计算肿瘤学服务部,纪念斯隆凯特琳癌症中心,美国纽约州纽约市东61街323号 2. 放射肿瘤学系,纪念斯隆凯特琳癌症中心,美国纽约州纽约市约克大道1275号 3. 德国德累斯顿工业大学卡尔·古斯塔夫·卡鲁斯医学院,Else Kroener Fresenius数字健康中心,德国德累斯顿费切尔大街74号,邮编01307 |
| 通讯作者 | Sarat Chandarlapaty Sohrab P. Shah Jakob Nikolas Kather | 1. 计算肿瘤学服务部,纪念斯隆凯特琳癌症中心,美国纽约州纽约市东61街323号 2. 人类肿瘤学和发病机制项目,纪念斯隆凯特琳癌症中心,美国纽约州纽约市约克大道1275号 3. Marie-Josée和Henry R. Kravis分子肿瘤学中心,纪念斯隆凯特琳癌症中心,美国纽约州纽约市约克大道1275号 4. 德国德累斯顿工业大学卡尔·古斯塔夫·卡鲁斯医学院,Else Kroener Fresenius数字健康中心,德国德累斯顿费切尔大街74号,邮编01307 5. 德国海德堡大学医院国家肿瘤疾病中心(NCT),医学肿瘤学,德国海德堡新海德堡菲尔德460号,邮编69120 |
文献概述
“Multimodal histopathologic models stratify hormone receptor - positive early breast cancer”发表于Nature Communications,通过开发多模态深度学习工具Orpheus,利用苏木精和伊红(H&E)全切片图像推断Oncotype DX复发评分(RS),为激素受体阳性早期乳腺癌的风险分层和治疗决策提供了新方法。
- 研究背景:激素受体阳性、HER2阴性(HR + /HER2-)的早期乳腺癌是最常见亚型,Oncotype DX®复发评分(RS)在预测和预后评估方面价值显著,但成本高、检测周期长限制其应用。已有基于临床病理特征的预测模型效果不佳,因此研究旨在用深度学习算法分析H&E全切片图像预测RS。
- 研究方法
- 数据组装:收集三个机构6172例HR + /HER2-早期乳腺癌患者数据,包括H&E染色、免疫组化分析、RS计算及部分基因组数据,分为训练验证集和外部验证集。
- 模型训练:构建基于transformer的模型,通过自监督学习和适应transformer架构训练,预测RS。分别训练视觉、语言和多模态模型,多模态模型融合图像和文本信息。
- 模型评估:用Pearson相关系数、一致性相关系数等评估模型预测RS的能力,对比Orpheus与临床病理列线图及RS识别远处转移复发的能力。
- 研究结果
- 模型性能良好:视觉模型在不同队列稳健推断RS并识别高风险疾病;语言模型有一定预测能力;多模态模型性能最优,识别高风险疾病(RS > 25)的AUC达0.89,优于列线图(0.73)。
- 预测复发优势明显:对于RS ≤25的患者,Orpheus + 模型预测远处转移复发的能力强于RS,MSK - BRCA队列中,Orpheus + 的平均时间依赖性AUC为0.75,RS仅为0.49。
- 可解释性与生物学一致:通过注意力机制可视化,发现模型关注肿瘤相关区域和关键病理信息。高风险疾病肿瘤微环境有显著特征,与基因特征相关。
- 临床应用有潜力:Orpheus识别低风险患者敏感性高,识别高风险患者有一定特异性,可减少基因检测,指导辅助化疗决策。
- 研究结论:Orpheus可从常规H&E全切片图像近似RS,多模态方法优势明显,为乳腺癌精准医疗提供支持,有助于扩大精准医学覆盖范围、优化治疗和随访策略。
早期激素受体阳性/人表皮生长因子受体2阴性(HR+/HER2-)乳腺癌的研究流程
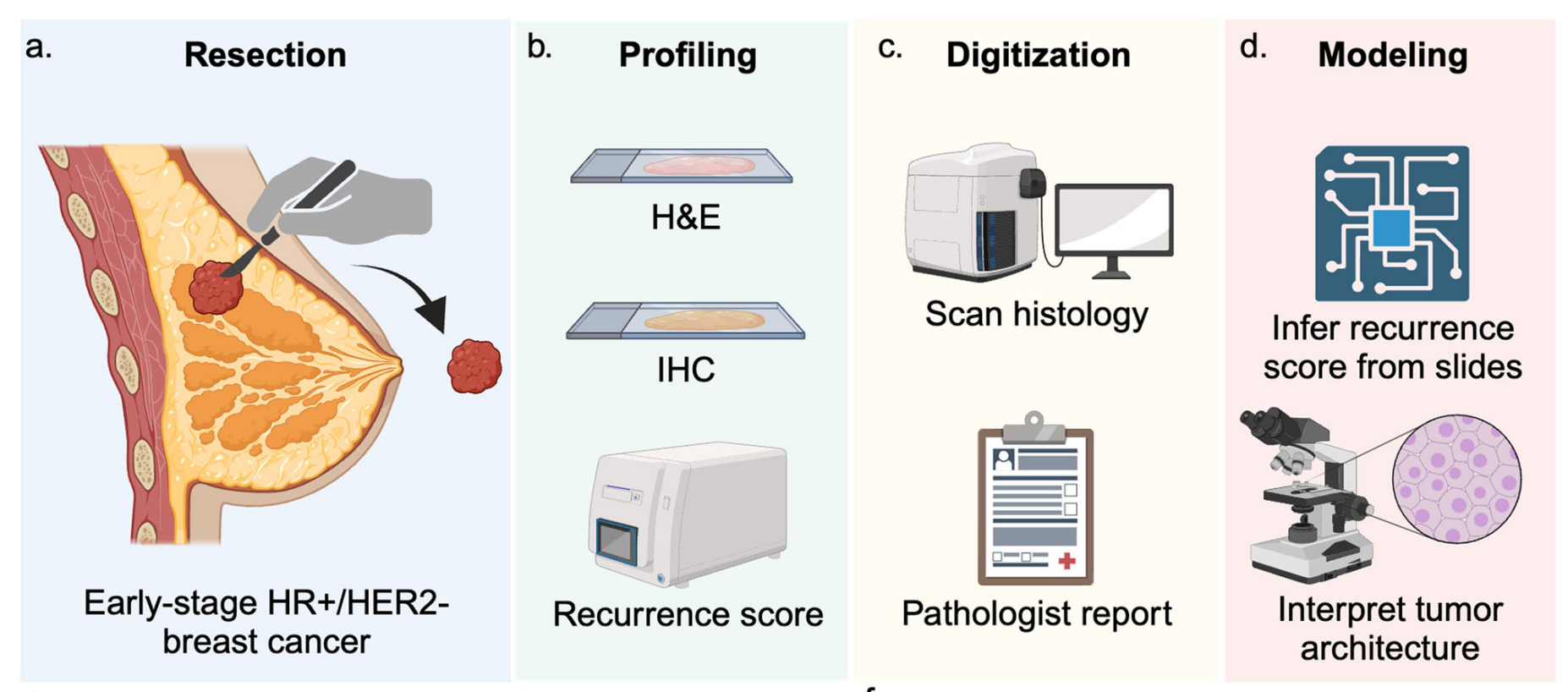
共分为4个步骤:
- a. 切除(Resection):切除早期HR+/HER2-乳腺癌组织样本。
- b. 分析(Profiling):对样本进行苏木精 - 伊红(H&E)染色和免疫组织化学(IHC)分析,计算复发评分。
- c. 数字化(Digitization):对组织学切片进行扫描,并生成病理报告。
- d. 建模(Modeling):通过切片推断复发评分,并解读肿瘤结构。
乳腺癌病理分析及建模预测复发评分的过程
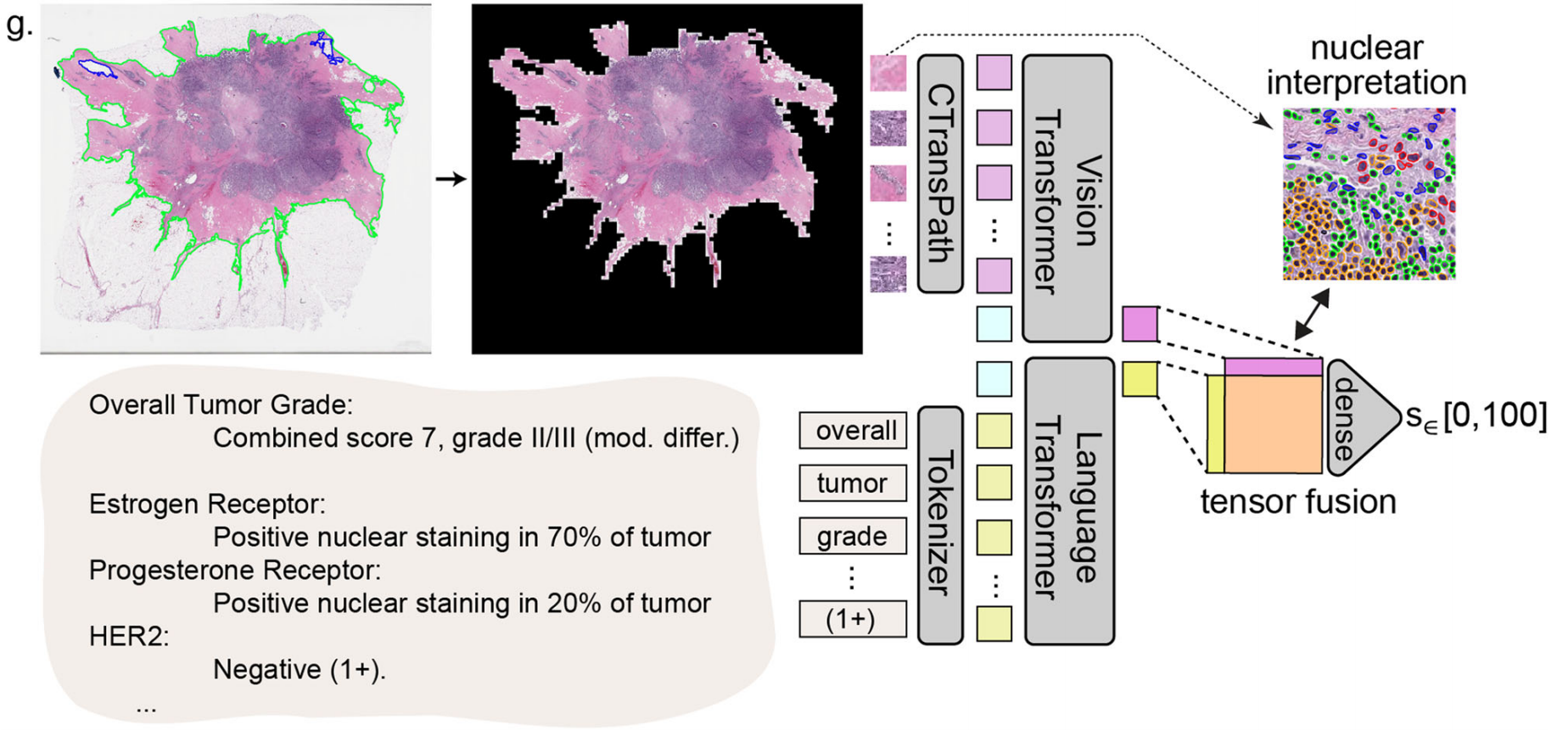
- 病理信息:肿瘤综合评分7,等级II/III(中度分化);雌激素受体在70%的肿瘤细胞核中呈阳性染色;孕激素受体在20%的肿瘤细胞核中呈阳性染色;HER2为阴性(1+)。
- 分析流程:左侧是苏木精 - 伊红(H&E)染色的组织切片图像,经处理后提取图像特征(CTransPath)进入视觉Transformer模型进行细胞核解读;同时,病理文本信息经标记器(Tokenizer)处理后进入语言Transformer模型,最后将视觉和语言模型的输出通过张量融合(tensor fusion)得到一个在0到100之间的分数(s),用于预测复发评分。
二、自监督学习挖掘结肠癌治疗相关的组织形态学模式

一作&通讯
| 作者身份 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Bojing Liu、Meaghan Polack | Bojing Liu:1. 卡罗林斯卡学院医学流行病学与生物统计学系;2. 纽约大学格罗斯曼医学院应用生物信息学实验室 Meaghan Polack:1. 莱顿大学医学中心外科;3. 纽约大学格罗斯曼医学院病理学系 |
| 通讯作者 | Aristotelis Tsirigos | 2. 纽约大学格罗斯曼医学院应用生物信息学实验室;6. 纽约大学格罗斯曼医学院病理学系 |
文献概述
文章《Self-supervised learning reveals clinically relevant histomorphological patterns for therapeutic strategies in colon cancer》发表于Nature Communications,利用自监督学习(SSL)从结直肠癌苏木精 - 伊红染色全切片图像(WSIs)中提取和分析组织形态学特征,构建了与临床治疗及预后相关的组织形态表型簇(HPCs),为结直肠癌个性化治疗提供依据。
- 研究背景:传统结直肠癌诊断依赖病理学家镜检,且预后预测复杂。深度学习(DL)虽有帮助,但存在可解释性难题。SSL可自动从无标注数据提取图像特征,本研究旨在用SSL从WSIs提取临床相关组织学模式并探究其与患者结局及分子表型的关联。
- 研究方法
- 数据处理与特征提取:用TCGA结肠腺癌(TCGA - COAD)数据集训练SSL Barlow Twins算法,将WSIs处理为小图像补丁(图块),提取128维特征向量。
- 构建HPCs:运用Leiden社区检测算法对特征向量聚类,构建HPCs,并在AVANT试验数据集验证。
- 评估与分析:对HPCs进行组织病理学评估和特征描述,从定性和定量评估其一致性和稳健性。用Cox回归构建HPCs与总生存期(OS)的预测模型,结合SHAP值分析重要HPCs。通过计算Spearman相关性和基因集富集分析(GSEA),探究HPCs与免疫特征、致癌通路的联系。
- 研究结果
- HPCs构建与验证:成功构建47个HPCs,可分为8个超级簇,在TCGA和AVANT队列中表现出良好的一致性和稳健性。
- HPCs与OS的关系:HPCs分类器在预测OS方面表现出色,是独立预后因素,不同治疗组中与OS相关的HPCs具有不同组织学特征。
- HPCs与免疫及致癌通路的关联:与OS相关的HPCs与肿瘤微环境免疫特征相关,AVANT - 实验组中,HPCs与致癌通路联系紧密,部分HPCs与贝伐单抗治疗反应相关。
- 研究结论:研究识别并验证了结直肠癌中与预后相关的组织病理学特征,强调肿瘤微环境重要性,提出影响患者治疗敏感性的机制。HPCs有临床应用前景,但研究存在局限性,未来需提高预测准确性并验证相关机制。
利用自监督学习算法Barlow Twins从癌症基因组图谱(TCGA)结肠腺癌数据集中提取特征的流程
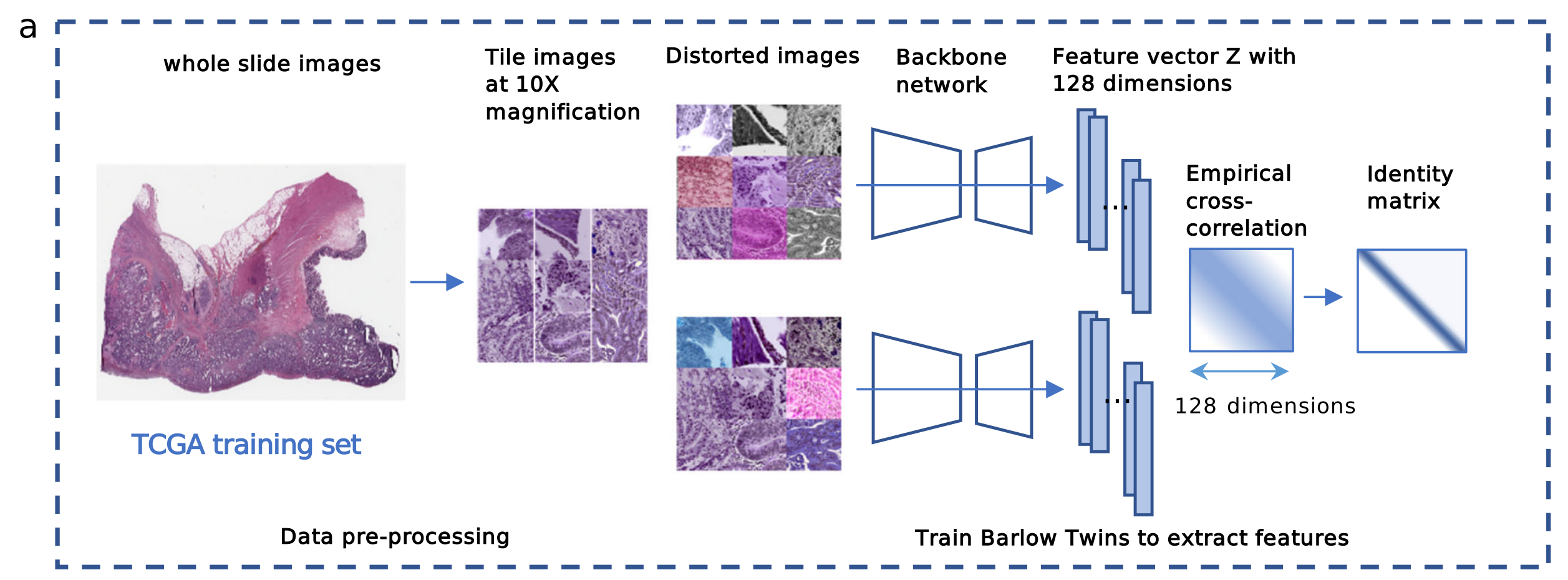
- 数据预处理:以TCGA训练集的全切片图像(whole slide images)为起始数据,将其处理成10倍放大的图块图像(Tile images at 10X magnification),然后生成畸变图像(Distorted images )。
- 特征提取:将畸变图像输入主干网络(Backbone network),得到128维的特征向量(Feature vector Z with 128 dimensions),计算经验互相关(Empirical cross-correlation),并与单位矩阵(Identity matrix)对比,训练Barlow Twins算法来提取图像特征。
基于 TCGA 训练集、AVANT 临床试验集的结肠腺癌图像分析流程
这张图展示了基于TCGA训练集和独立的AVANT临床试验数据集,利用训练好的主干网络对结肠腺癌组织图像进行处理和分析的流程:
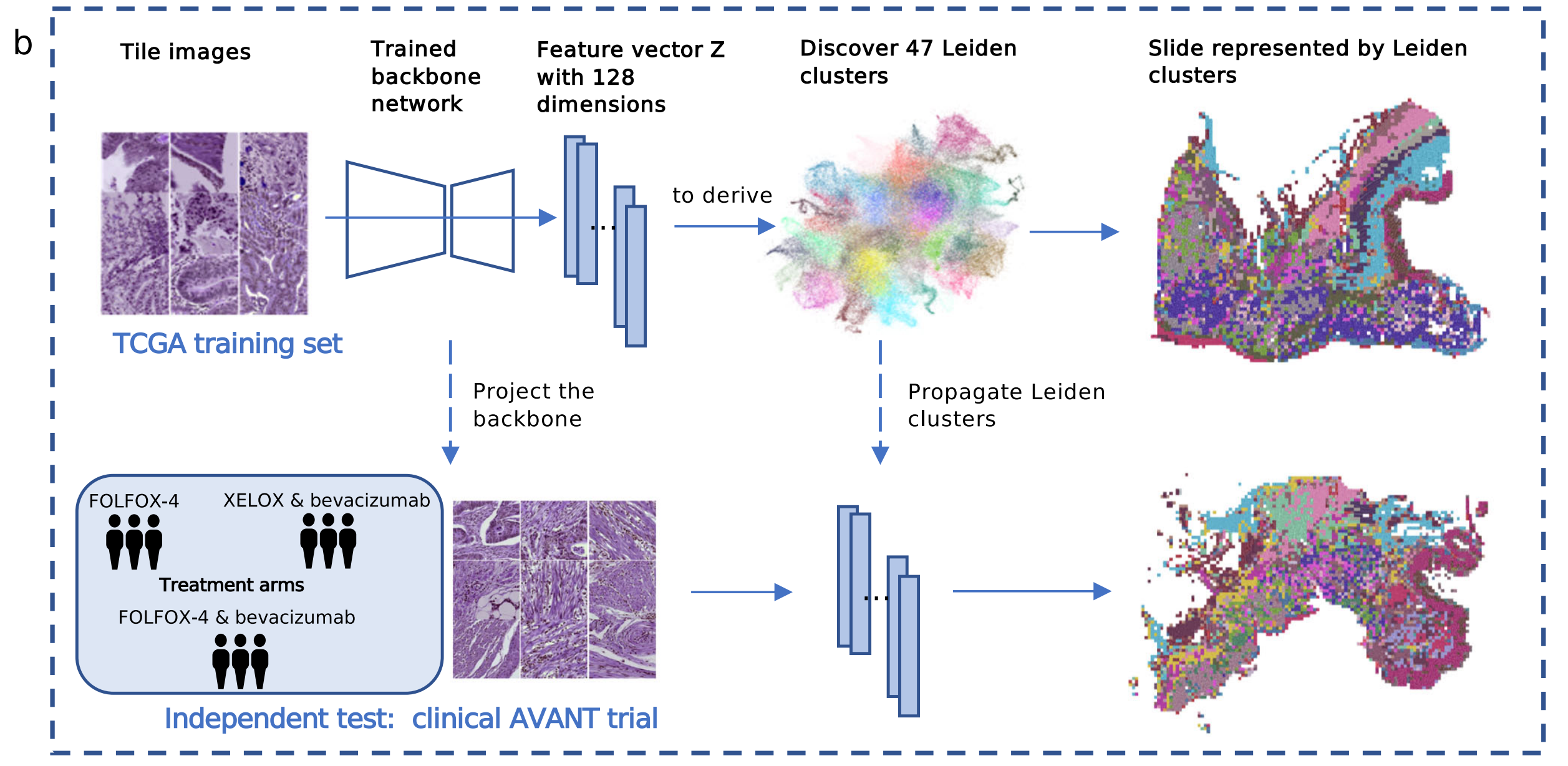
- TCGA训练集处理:将图块图像(Tile images)输入训练好的主干网络(Trained backbone network),生成128维的特征向量(Feature vector Z with 128 dimensions),通过这些特征向量发现47个莱顿簇(Leiden clusters),并将全切片用莱顿簇表示。
- 独立测试(AVANT临床试验):该试验有FOLFOX - 4、XELOX & 贝伐单抗(bevacizumab)、FOLFOX - 4 & 贝伐单抗等治疗组(Treatment arms)。对试验中的图像同样经过主干网络投影(Project the backbone),再利用莱顿簇分析,得到相应的图像表示结果,以此验证相关分析结果的有效性 。
三、BEPH 模型:从组织病理图像实现癌症诊断与生存预测的新基础模型

一作&通讯
| 姓名 | 身份 | 单位(中文) |
|---|---|---|
| Zhaochang Yang | 第一作者 | 上海交通大学生命科学与生物技术学院生物信息学与生物统计学系 |
| Yue Zhang、Zhangsheng Yu | 通讯作者 | 1. 上海交通大学生命科学与生物技术学院生物信息学与生物统计学系 2. 上海交通大学 - 耶鲁大学生物统计学与数据科学联合中心 3. 上海交通大学医学院转化科学研究所生物医学数据科学中心(Yue Zhang、Zhangsheng Yu) 4. 上海交通大学数学科学学院(Zhangsheng Yu) 5. 上海交通大学医学院临床研究院(Zhangsheng Yu) |
文献概述
研究提出基于自监督学习的基础模型BEPH,利用1100万张未标记的组织病理学图像进行预训练,在多种癌症检测任务中表现出色,为癌症诊断和生存预测提供了有效工具,推动了计算病理学在临床和研究中的应用。
- 研究背景:计算病理学利用全切片图像进行病理诊断,但现有方法受标注数据稀缺和组织学差异限制。基础模型通过对大量无监督数字病理图像预训练,学习图像潜在结构和关系,有监督学习和自监督学习是主要训练策略。
- BEPH模型构建:从TCGA收集32种癌症的11760张病理图像,构建1177万个224×224像素的预训练补丁数据集。基于BEiTv2,利用自监督学习技术在自然图像和病理图像上预训练,学习病理图像的通用表示,再针对不同任务微调 。
- 实验结果
- 补丁级分类:在BreakHis数据集上,BEPH的患者级和图像级平均准确率比最新CNN和弱监督模型高5 - 10%;在LC25000数据集上,对肺癌亚型分类准确率达99.99%±0.03,优于其他模型,表明其泛化能力强。
- WSI级分类:在肾细胞癌、非小细胞肺癌和乳腺癌亚型分类任务中,BEPH的10折宏观平均测试AUC表现优异,虽在部分结果上略逊于UNI和GigaPath,但整体稳定性和泛化能力强,且零样本能力出色。
- 标签效率:训练数据减少时,BEPH性能仍优于多数模型,使用约50%训练数据时,性能与其他用大量数据训练的模型相当,能有效应对数据稀缺问题。
- 生存预测:在六种癌症类型的生存预测中,BEPH的C指数最高,在区分高风险和低风险患者方面表现出色,且无需病理图像注释或额外基因组信息。
- 模型可解释性:通过UMAP降维分析和注意力热图可视化,发现BEPH能有效提取特征,注意力热图与病理学家注释高度一致,消融实验证明病理图像预训练和MIM的重要性。
- 研究展望:未来计划构建更大规模、更多样化的预训练数据集,探索多模态基础模型整合多领域数据的价值,以推动病理学人工智能发展。
基于组织病理学图像的癌症相关模型流程
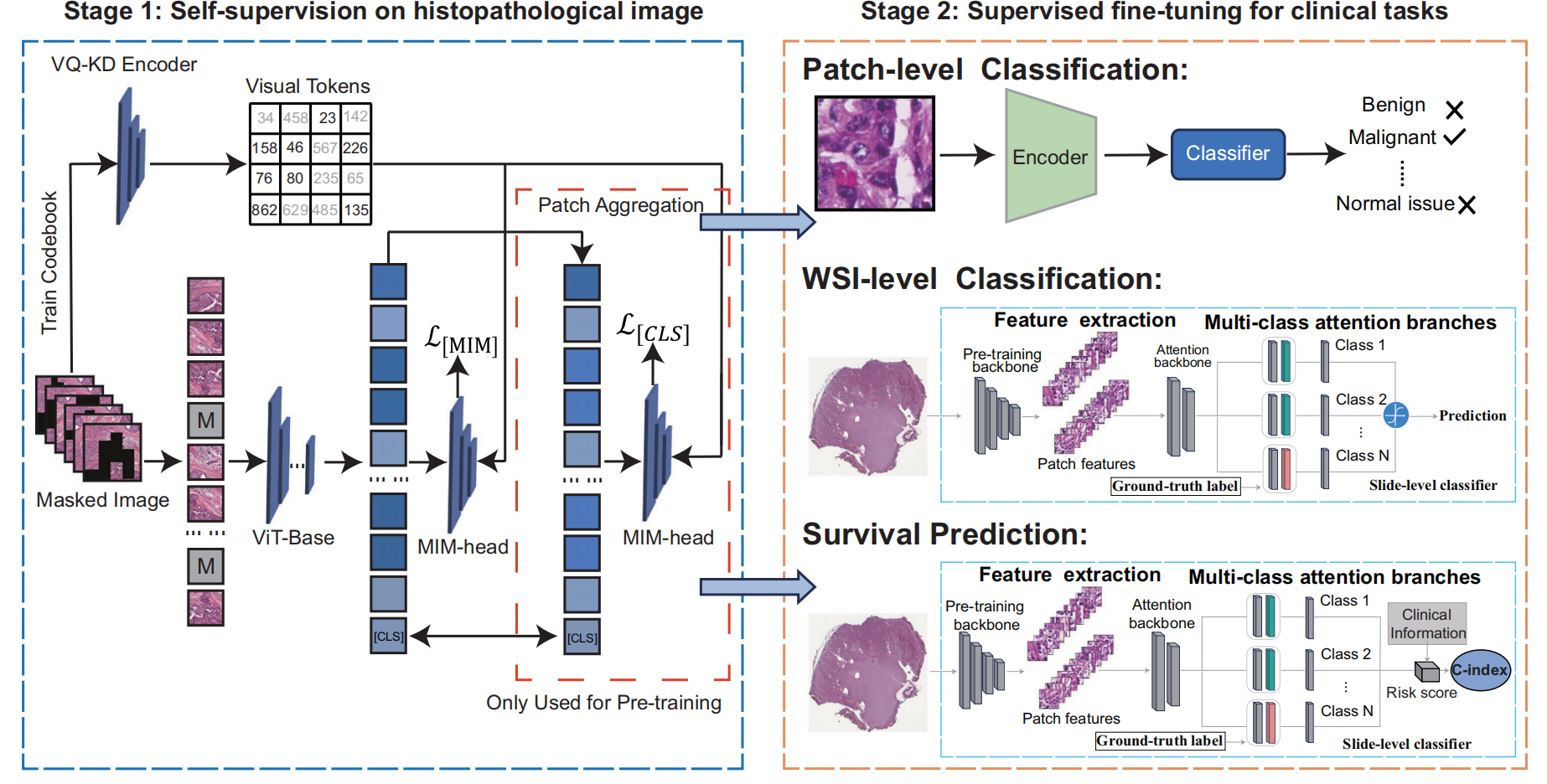
第一阶段(Stage 1: Self-supervision on histopathological image)
对组织病理学图像进行自监督学习。
使用VQ-KD编码器将图像转换为视觉标记,通过掩码图像(Masked Image)输入到ViT-Base模型中,利用MIM-head(Masked Image Modeling head)计算损失函数 L [ M I M ] L_{[MIM]} L[MIM]和 L [ C L S ] L_{[CLS]} L[CLS],进行预训练。
此阶段的一些组件如Patch Aggregation等用于处理图像块。
第二阶段(Stage 2: Supervised fine-tuning for clinical tasks)
针对临床任务进行有监督的微调,包含三个任务:
- Patch-level Classification(图像块级别分类):将图像块输入编码器,再经过分类器,判断图像块对应的组织是良性、恶性还是正常组织。
- WSI-level Classification(全切片图像级别分类):先进行特征提取,通过预训练的主干网络得到图像块特征,再经过多类注意力分支和切片级分类器,结合真实标签进行预测。
- Survival Prediction(生存预测):与全切片图像级别分类类似,先提取特征,然后通过多类注意力分支和切片级分类器,结合临床信息计算C-index和风险分数,预测患者生存情况 。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









