









前言
在上一篇文章(单链表的定义)中我们已经了解了单链表的含义和简单的实现。那么在这篇文章中,我们将要来讲解单链表的插入和删除操作。
按位序插入(带头结点)
我们在上篇文章中已经讲解过,如果想要在表L中的第i个位置上插入指定元素e,我们需要找到第i-1的结点,在其后插入新的结点。大致步骤如下:
- 使用
malloc()函数申请一个新的结点 - 往新的结点存入新的元素e
- 将i-1位的元素指针指向新结点
- 将新结点的指针指向原先第i个元素
当然当我们想在第一位插入新结点时,对于带头结点的链表的好处就是,在头部插入数据和其他任意一个位置插入数据的操作是一样的,非常方便。
代码实现
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool ListInsert(LinkList &L,int i,ElemType e){
if(i<i)
return false;
LNode *p; // 指针p指向当前扫描到的结点
int j = 0; // 当前p指针指向的是第几个结点
p = L; // L指向头结点,头结点时第0个结点(不存放数据)
while(p!=NULL && j<i-1){
p = p->next;
j++;
}
if(p=NULL) // i值不合法
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s; // 将结点s连接到p之后
return true; // 插入成功
}
代码分析(在第一个位置插入结点)
若 i = 1
我们直接看ListInsert()函数的内部
-
在进入时首先会判断,i的合法性(i小于1是不合法的)
- 位序是从1开始,不可能会比开头的还要小。如果小的话那就不属于链表中的元素。
-
声明一个p指针,声明一个j变量用来表示p指针指向第几个结点
-
紧接着将p指针指向头结点L
-
这时候由于j = 0;i = 0不满足循环条件,所以直接不进行循环。
-
判断i值是否合法
-
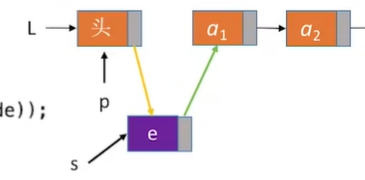
创建一个新的结点,并且将结点的指针返回给
*s -
s->data:将e赋值给s的数据域(将e装入s) -
s->next=p->next:将s的指针指向p指针指向的位置。- 由于p指针在上面已经指向头结点了,所以p指针的next就跟头节点一样指向a1
-
p->next=s:将p指针的指针指向s- 由于在第一个位置插入结点,所以链表中的第一个结点不再是a1,而是s了,所以需要将p的指针指向s。
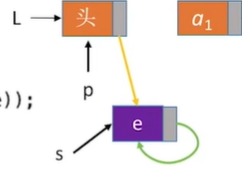
注意:
s->next=p->next和p->next=s的代码顺序不能颠倒。如果颠倒则会出现一下状况:
- p先将指针指向s
- s再将指针指向p指向的(也就是s)
就会形成一种“我指我自己”的尴尬局面。
代码分析(在第三个位置插入结点)
若 i = 3
我们直接从不同的地方说起:
-
这时候则会进入while循环
-
while循环的作用,其实就是将p指针指向下一个结点,直至指向想要插入的位置-1——i - 1为止。
-
未执行while循环

-
执行1次while循环

-
以此类推,直至到想要的位置-1(这里是到第二个位置)
-
-
紧接着下述的结点如何插入,与在第一个位置插入结点的操作相同,所以不多赘述
代码分析(在第六个位置插入结点)
由于该链表中只有4个结点(头结点不算),所以while循环最多只能循环5次——也就是当p指针指向a4结点的next——NULL时就会推出循环。
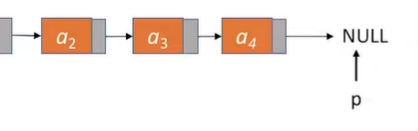
并且在if判断的时候由于P==NULL所以会直接退出函数,并且返回false。
时间复杂度
最好情况:在第一个位置插入新结点,时间复杂度为O(1)
最坏情况:在最后一个位置+1插入新结点,时间复杂度为O(n)
平均情况:假设在每一个位置插入新结点是等可能事件,时间复杂度为O(n)
按位序插入(不带头结点)
其实不带头结点的插入原理和带头结点是一样的,都是先找到i-1位置上的结点,再进行插入。但是不带头结点的单链表在第一个位置插入元素时需要特殊处理。
代码实现
bool ListInsert(LinkList &L, int i, ELemType e){
if(i<1)
return false;
if(i==1){ // 在第一个位置插入结点
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
s->next = L;
L = s;
return true;
}
LNode *p; // 指针p指向当前扫描到的结点
int j = 1; // 当前p指针指向的时第几个结点
p = L; // p指针指向第一个结点(注意:不是头结点)
while(p!=NULL && j<i-1){ // 循环找到第i-1个结点
p = p->next;
j++;
}
if(p==NULL) // 检测i合法性(是否超出链表长度)
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s;
return true; // 插入成功
}
代码分析(在第一个位置插入结点)
若 i = 1
- 判断I的合法性,i是否是小于1(起始值)
- 判断是否要在第一个位置插入节点
- 使用
malloc()函数创建一个新的结点 - 将e的值存入新结点中
- 将新结点的指针指向原先链表中的第一个结点(头指针L在不带头结点的链表中代表的就是第一个结点)
- 由于在第一个位置插入了新的结点,所以应该将头指针L(指向第一个位置结点的指针)指向s
- 插入成功,返回true
- 使用
从上述我们可以看出,如果是不带头结点的单链表的话,在第一个位置插入元素,需要改变头指针L指向新插入的结点。而在带头结点的单链表中,头指针始终都是指向头结点的,只需要改变头结点的指针指向新插入的元素,其实和在任意位置插入一个新的结点的操作是相同的,并不用专门写一段代码来对在第一个位置插入元素进行特殊处理。
从这里我们就可以看出带头结点的链表的代码便捷性。
代码分析(i>1)
不带头结点的链表,在除了第一个位置外的其他位置插入新结点,跟带头结点的链表是一样的,维度有一个不同就是在j的赋值上:
- 带头结点:是因为p指针刚开始指向的是头结点(头结点在链表中不算一个真正的结点,所以我们将其记为0),故将j赋值为0
- 不带头结点:由于p指针直接就是指向链表中的第一个结点,故直接将J赋值为1
指定结点的后插操作
后插的操作和按位序操作的区别就是:前者是给你一个结点的地址,你直接在该结点后插入一个结点,而后者是给你要插入结点的位序,你在该位序插入结点。
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InsertNextNode(LNode *p,ElemType e){
if(P==NULL)
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
if(s==NULL) // 内存分配失败
return false;
s->data = e; // 将e存入新结点
s->next = p->next;
p->next = s; // 将结点s连接到p之后
return true;
}
由于我们已经知道了i-1的地址,所以不需要再进行遍历去找到i-1的结点的位置。所以可以直接创建一个新的结点,进行存入数据和指针重指的操作(插入新指针的操作同上,不再赘述)
注意:if(s==NULL)是用来判断内存分配是否成功,若失败则退出并返回false
由于链表中插入结点的代码是一样的,那么再按位序插入的代码中,我们可以将插入结点的代码删去,直接改为调用InsertNextNode()函数
- 按位序插入和后插操作就是多了遍历和判断,后插操作只有插入结点的操作,所以我们可以在按位序插入的函数中直接调用后插操作,减少代码的冗余性
指定结点的前插操作
在单链表中我们知道,给定一个结点(p)后,我们可以知道这个结点后面的所有元素,但是无法知道前面的元素。如果给定一个地址,需要在该节点的前方插入结点的话,我们就需要头指针。通过头指针找到给定地址的结点(p)的前驱,在前驱后插入结点即可。
- 如何找到前驱:前驱的指针应该是指向给定地址的结点(p),当指针的地址和给定地址的结点的地址相等时,则代表当前结点为前驱
但是这样子的操作,时间复杂度为O(n),那么还有没有另一种方法呢?
有的!
我们换一个思路,我们虽然不能将结点直接在前驱后插入,但是我们可以将数据对换。
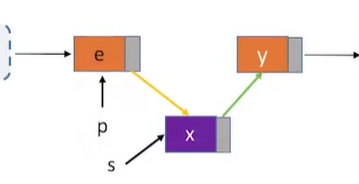
-
在给定地址的结点(p)后面插入一个结点
-
这时候重点来了,我们将结点p的数据值和新插入的结点的值对调
虽然我们无法找到p结点的前驱结点,但是在逻辑上,我们实现了前插操作,并且时间复杂度为O(1)
代码实现
bool InsertPriorNode(LNode *p,ElemType e){
if(p==NULL)
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
if(s==NULL) // 内存分配失败
return false;
s->next = p->next;
p->next = s; // 新结点s连接到p之后
s->data = p->data; // 将p中元素赋值到s中
p->data = e; // p中元素覆盖为e
return true;
}
因为我们进行的前插操作,也是要先将新结点插在p结点后,最后调换数据域,所以为了减少代码的冗余性,又由于我们知道插入新结点的操作已经可以由InsertNextNode()实现,那么我们调用该函数先创建一个新的结点,然后再将新的结点传入前插操作的函数。
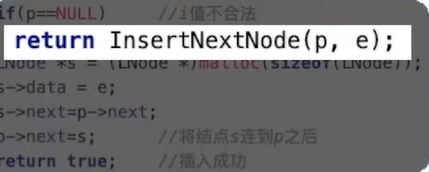
bool InsertPriorNode(LNode *p,LNode *s){
if(p==NULL || s==NULL)
return false;
s->next = p->next;
p->next = s // 将结点s连接到p之后
ElemType temp = p->data // 交换数据域部分
p->data = s->data;
s->data = temp;
return true;
}
上述的新代码中*p是要在哪个结点前插入,*s是要插入的新结点。
按位序删除(带头结点)
代码实现
bool ListDelete(LinkList &L,int i,ElemType &e){
if(i<1)
return false;
LNode *p;
int j = 0;
p = L;
while(p!=NULL && j<i-1){
p = p->next;
j++;
}
if(p==NULL)
return false;
if(p->next==NULL)
return false;
LNode *q = p->next;
e = q->data;
p->next = q->next;
free(q);
return true;
}
由于,在if(p==NULL)的代码前面的部分,和按位序插入的操作一样,就是找到要删除的结点的前驱结点,所以在这里不再赘述。
重点我们看到LNode *q = p->next;及之后的代码。
- 创建一个q指针,指向p的后继结点
- p指针在经过上述的操作后,已经指向要删除的结点的前驱结点,也就是将q指针指向要删除的结点
- 使用e变量将要删除的值带回
- 注意:这里e是引用型变量
- 将p的指针指向,q的后继
- 使用
free()释放q指针
时间复杂度
最坏、平均时间复杂度:O(n)
最好时间复杂度:O(1)
指定结点的删除
经过了上面前插操作,我们可以知道指定结点的删除也有两种方法:
p结点为要删除的结点,q指针为指向要删除的结点的指针
- 方法一:传入头之间,遍历找到前驱结点
- 方法二:将q指针,指向p结点的后继结点。将p结点的后继结点的数据域复制给p结点,并且将p结点的next指针指向p结点的后继节点的next,再使用
free(q)释放结点
代码实现
bool DeleteNode(LNode *p){
if(p==NULL)
return false;
LNode *q = p->next; // 令q指向*p的后继结点
p->data = p->next->data; // 和后继结点交换数据域
p->next = q->next; // 将*q结点从链中“断开”
free(q); // 释放后继结点的存储空间
}
上述这种方法的时间复杂度为:O(1)
但是如果当我们要删除的结点是最后一个时,就会出现问题。如果真的遇到这种情况,那么就只能使用头指针的方式遍历找到前继结点再删除,所以上述的代码其实是有一些bug的,但是可以这么写大概会扣个1分。
单链表的局限性
从上述可以看出单链表的局限性:无法逆向检索,有时候不太方便。
结束语
已同步更新至个人博客:https://www.hibugs.net/index.php/linklistinsdel
本人菜鸟一枚,仅分享学习笔记和经验。若有错误欢迎指出!共同学习、共同进步 😃
如果您觉得我的文章对您有所帮助,希望可以点个赞和关注,支持一下!十分感谢~(若您不想也没关系,只要文章能够对您有所帮助就是我最大的动力!)
下一篇文章传送门:正在更新,敬请期待…















 2717
2717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









