






MedVQA医学视觉问答论文通读1
1-10篇公开代码的论文
文章目录
- MedVQA医学视觉问答论文通读1
- 前言
- 一、[CLEF 2020 Working Notes] HCP-MIC at VQA-Med 2020 Effective visual representation for medical visual question answering
- 二、[CLEF 2020 Working Notes] TeamS at VQA-Med 2021 BBN-Orchestra for long-tailed medical visual question answering
- 三、[TMI 2020] A Question-Centric Model for Visual Question Answering in Medical Imaging
- 四、[MICCAI 2022] Consistency-preserving Visual Question Answering in Medical Imaging
- 五、[MICCAI 2022] Surgical-VQA Visual Question Answering in Surgical Scenes using Transformer
- 六、[ACM MM 2023] RAMM Retrieval-augmented Biomedical Visual Question Answering with Multi-modal Pre-training
- 六、[arXiv 2022] A Dual-Attention Learning Network with Word and Sentence Embedding for Medical Visual Question Answering
- 七、[arXiv 2023] Multimodal Prompt Retrieval for Generative Visual Question Answering
- 八、[ECCV 2022] Distilled Dual-Encoder Model for Vision-Language Understanding
- 九、SELF-SUPERVISED VISION-LANGUAGE PRETRAINING FOR MEDIAL VISUAL QUESTION ANSWERING
- 十、Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
- 总结
前言
初入MedVQA(医学视觉问答),泛读一些有代码的论文,记录一下每篇文章的梗概。
一、[CLEF 2020 Working Notes] HCP-MIC at VQA-Med 2020 Effective visual representation for medical visual question answering
“HCP-MIC at VQA-Med 2020: 为医学视觉问答提供有效的视觉表达”
0.备注
ImageCLEF 2020的医学视觉问答任务比赛排名第四名。
code
1.方法
根据对问题的观察,将问题句子分类为三个类别:开放式问题、封闭式异常问题和封闭式正常问题。并利用预训练的BioBERT 来对其进行分类。
至于视觉表达,将异常映射到医学图像,并发现了训练集中长尾分布的现象。因此,应用双分支网络和累积学习策略来获得有效的视觉表达。
此外,提出一种基于检索的候选答案选择算法,以进一步提高性能。
最后,为了缓解有限的训练数据问题,设计了一种利用Kullback-Leibler(KL)散度来扩展训练集的方法。
数据集:
在ImageCLEF 2020 VQA-Med任务中,数据集包括一个包含4000张放射学图像和4000个问题-答案(QA)对的训练集,一个包含500张放射学图像和500个QA对的验证集,以及一个包含500张放射学图像和500个QA对的测试集。
这些问题主要关注医学图像的异常情况,可以分为两种形式。一种是关于图片中是否存在异常的询问,另一种是关于异常类型的询问。图1展示了VQA-Med数据集中的三个示例。
VQA-Med-2019数据集用作额外的训练数据,其训练集包含3200张医学图像,关联着12792个QA对。
然而,与VQA-Med-2020数据集不同的是,它专注于四个主要类别的问题:模态、平面、器官系统和异常。在本文中仅利用其异常子集来扩展VQA-Med2020的训练集。
注:
- 异常问题更依赖于图像而不是问题的信息。因此,由于图像和问题之间的信息不平衡,放弃了复杂的跨模态融合策略,而集中关注如何获得有效的视觉表示。
- 不同于传统的BERT ,BioBERT是一种在大规模生物医学语料库上预训练的领域特定语言表示模型。
- 长尾分布是一种在统计学和概率论中常见的分布类型。在这种分布中,数据集中的大多数值都集中在分布的“头部”(即较小的值),而较大的值则相对较少,呈现出一个延伸的“尾部”。
- 双分支网络(BBN)有两个分支,一个称为“传统学习分支”,另一个称为“重新平衡分支”。传统学习分支用于表示学习,而重新平衡分支用于分类器学习。
- 累积学习策略,用于调整双边学习。
- 至于开放式问题,发现在训练过程中前五名的得分比前一名的得分高出约10%。为了缓解这个问题,采用了基于检索的前五名答案选择来进一步提高性能。这个进程分为三个步骤。第一步是基于训练集创建每个类别的特征字典。第二步是计算输入样本与属于前五名类别的所有训练样本之间的特征级余弦相似性。然后将最相似训练样本的答案视为最终预测。
- 用KL散度将额外数据集(clef2019)调整为所需的更关注异常的分布,扩展训练集
2.结构
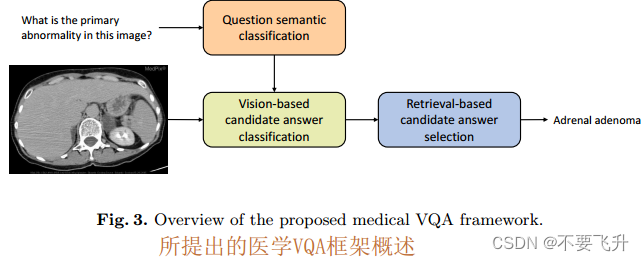
框架由三部分组成:问题语义分类、基于视觉的候选答案分类以及基于检索的候选答案选择。
分别训练前两部分,然后在推理阶段连接所有组件来预测最终答案。
3.结果

二、[CLEF 2020 Working Notes] TeamS at VQA-Med 2021 BBN-Orchestra for long-tailed medical visual question answering
“VQA-Med 2021: BBN-Orchestra用于长尾医学视觉问题回答 TeamS”
0.备注
ImageCLEF 2021的医学视觉问答任务比赛排名第三名。
code
1.方法
BBN-Orchestra是一个使用Bilateral-Branch Networks(BBNs)的集成深度学习解决方案。当分类具有长尾分布的数据时,即其中一些类别包含大多数数据,而大多数类别只有非常少的样本时,BBNs能够取得有效的结果。
数据集:
实验使用了VQA-Med 2021挑战中发布的数据集进行。训练、验证和测试数据集分别包括4,500、500和500张图像,以及问题-答案对。还利用了来自VQA-Med 2019挑战[13]的训练、验证和测试数据集,以增加可用于训练的数据量。
注:
- BBNs由三个主要组件组成:1. 用于有效表示学习的传统网络,2. 用于通过逆采样建模尾类别分布的重新平衡网络,3.一个自适应累积学习组件,它控制如何在不同的时期在两个前述组件之间移动注意力并通过最小化训练损失来训练分类器。
2.结构
3.结果


三、[TMI 2020] A Question-Centric Model for Visual Question Answering in Medical Imaging
一个以问题为中心的模型用于医学图像问答
code
0.备注
提出了一种新颖的视觉问答方法,允许通过书面问题来查询图像。
1.方法
(i)介绍了一种问题中心的多模态融合方案,强调了VQA任务中的问题特征;
(ii)提出了医学图像的VQA应用;
(iii)提出了一种生成特定医学领域的VQA基础真值对的方法,可以扩展到任何其他领域。
数据集:
- 印度糖尿病视网膜病变图像数据集(IDRiD)包含分辨率为4288 × 2848的彩色视网膜眼底图像
- 乳腺癌组织学数据集(BACH)包括400多张标记显微镜图像
- 工具检测和操作技能评估数据集(Tools)由10个真实的腹腔镜手术视频中的2,532帧的空间边界框组成。
- 医学领域视觉问答(Visual Question answer in The Medical Domain, VQA-Med)
共包含4200张图像和15292对对应的QA对 - (1)VQA-V1,包含204,721张MS-COCO图像,包含614,163个问题;(2) VQA-V2,包含265,016张MS-COCO图像和1,105,904个问题。
注:
- 为了高效地编码问题和图像之间的关系,利用由Xu等人提出的多窥视注意机制。多窥视注意机制的目的是允许VQA模型选择适当的图像区域来回答问题。为了做到这一点,首先将与图像特征相关的位置空间网格投影到语义问题空间,以计算与位置网格和输入问题相关的注意力地图的权重矩阵。然后不是学习单一的注意力图,而是使用多窥视方案,使每个窥视代表一个注意力图。
2.结构

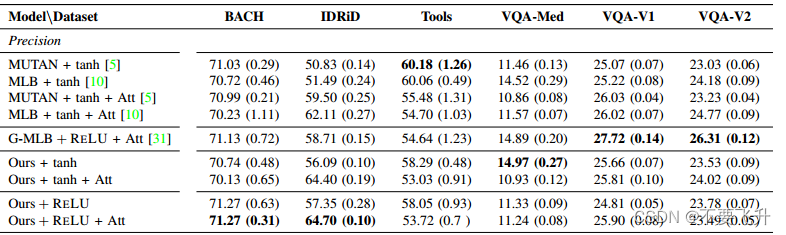
提出的QC-MLB模型以及注意机制。使用ResNet-152和Skip-thought向量分别提取图像v和问题特征q。然后使用注意机制将它们结合起来,以生成全局图像特征v,然后将其与全局问题特征q融合,以输出N个答案概率。在这里,J = 2400,K = 2048,G = 4分别表示图像特征的维度、问题特征的维度和窥视次数。
3.结果
四、[MICCAI 2022] Consistency-preserving Visual Question Answering in Medical Imaging
保持一致性的医学图像视觉问答
code
0.备注
提出了一种新的损失函数和相应的训练过程,允许将问题之间的关系纳入训练过程中
1.方法
一致性损失。目标是通过在训练时利用推理问题和感知问题之间的关系来提高VQA模型的质量。为此,将训练数据集增加了一个附加的二元关系≺,该关系作用在问题集合Q上。如果q(i)是与推理问题q(j)相关联的感知问题,则两个问题是相关的,即q(i) ≺ q(j)。将感知问题称为子问题,将推理问题称为主问题。
当VQA模型正确推断出主问题但子问题错误时会出现不一致性。使用熵作为不正确性的度量,提出在训练时通过对H(i) = H(p(i); a(i)) 高而H(j) = H(p(j); a(j)) 低的情况进行惩罚来强制实施一致性,其中q(i) ≺ q(j)。为了做到这一点,使用一种适应的铰链损失,在H(j)大于阈值γ > 0时禁用惩罚,但在其他情况下惩罚H(i)的大值。
数据集:
印度糖尿病视网膜病变图像数据集(IDRiD)和e-Ophta数据集
注:
- 一致性是指模型产生的答案不会自相矛盾
- 论文中举的例子:一张眼球的图片,问该眼球是否健康(主问题),回答是,再问该眼球是否有渗出物(子问题),回答是。出现不一致。
2.结构
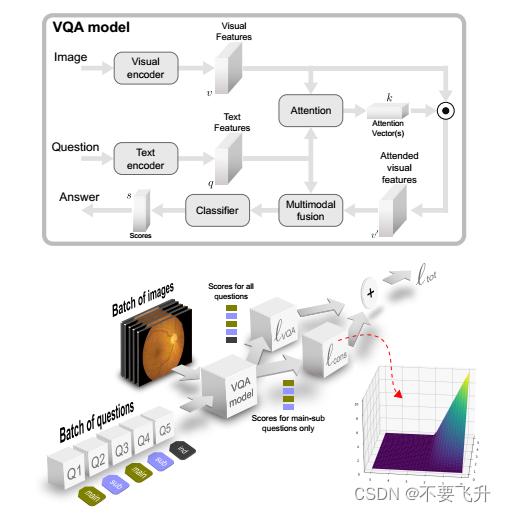
顶部:VQA模型架构。底部:使用提出的损失可视化的训练过程。总损失’tot基于两个项:传统的VQA损失’VQA和论文提出的一致性损失项’cons。后者仅针对主要(推理)和次要(感知)问题的配对计算。训练小批次同时包含主问题和子问题,其中子问题可以考虑图像的特定区域。无关的问题(用“ind”表示)也可以包含在训练批次中,但不会对’cons有贡献。
3.结果

不同模型的平均测试准确度和一致性值。显示的结果是在使用不同种子训练的10个模型上平均得出的。准确度值呈现了所有问题(总体)、主要问题(等级)和子问题(整体、黄斑和区域)的情况。同时也显示了两种一致性度量。
五、[MICCAI 2022] Surgical-VQA Visual Question Answering in Surgical Scenes using Transformer
外科手术视觉问题回答:使用Transformer进行外科手术场景的视觉问题回答
code
0.备注
采用视觉文本Transformer模型。引入了一种基于残差MLP的VisualBert编码器模型,强化了视觉和文本令牌之间的交互,从而提高了基于分类的回答性能。此外还研究了输入图像块数量和时间视觉特征对模型在分类和句子回答方面性能的影响
1.方法
受到残差MLP(ResMLP)的启发,VisualBERT模型的中间和输出模块被替换为交叉令牌和交叉通道模块,以进一步强化标记之间的交互。
单词和视觉标记分别在VisualBert ResMLP模型中通过文本和视觉嵌入层进行传播。嵌入的标记然后通过6个编码器层进行传播(包括自注意力和ResMLP模块),最后通过池化模块。
数据集:
Med-VQA:这是来自ImageCLEF 2019 Med-VQA挑战的一个公共数据集。
EndoVis-18-VQA:这是从MICCAI内窥镜视觉挑战2018 数据集的14个机器人肾切除手术视频序列生成的新数据集。
Cholec80-VQA:这是从Cholec80数据集[25]的40个视频序列生成的新数据集。
注:
2.结构

架构:给定输入的外科手术场景和问题,其文本和视觉特征通过视觉文本编码器(VisualBERT ResMLP)进行传播。
(i) 基于分类的答案:编码器输出通过一个用于答案分类的预测层进行传播。
(ii) 基于句子的答案:编码器与一个Transformer解码器相结合,逐词(逐渐)预测答案句子。
3.结果

基于VisualBERT ResMLP的模型与基于MedFuse和基于VisualBERT的分类应答模型的性能比较。

基于VisualBERT ResMLP的模型与基于VisualBERT的模型在EndoVis-18-VQA ©数据集上的k倍性能比较。
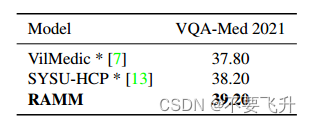
六、[ACM MM 2023] RAMM Retrieval-augmented Biomedical Visual Question Answering with Multi-modal Pre-training
RAMM:带检索增强的多模态生物医学视觉问答与多模态预训练
0.备注
通过对比相似度itc检索相似图片辅助训练
code
1.方法
提出了PMCPatients-Multi-modal(PMCPM),这是一个从PubMed Central筛选出的基于患者的图像文本数据集,它比ROCO和MIMIC-CXR更大,包含各种图像的模态和病况。
使用三个任务对生物医学多模态模型进行预训练:掩码语言建模、图像文本对比学习以及使用PMCPM数据集与先前广泛使用的ROCO和MIMIC-CXR数据集的图像文本匹配。由于预训练阶段中的图像文本对比目标旨在将视觉和文本表示对齐到相同的嵌入空间中,因此图像文本对比相似性可用于检索类似的对。
最后,检索与给定图像相关的图像文本对。为了充分利用检索到的对,论文提出了一种检索增强的微调方法,其中包括一个多模态编码器层中的新型检索-注意力模块,并将融合的表示应用于最终答案的预测。
数据集:在VQA- med 2019、VQA- med 2021、VQARAD和SLAKE(英文版)四个生物医学VQA数据集上进行实验。
注:
- 采用了三个预训练任务,包括图像-文本对比学习(ITC)、图像-文本匹配(ITM)和被屏蔽的语言建模(MLM)。RAMM的预训练目标函数由这三个任务的总和定义。
2.结构

用于生物医学VQA的检索增强范式RAMM的工作流程。原始图像来自VQA数据集,其他图像是检索得到的。蓝色线表示根据图像文本对比相似性从PMCPM、ROCO和MIMIC-CXR数据集中检索图像文本对。检索增强样本被送入单模态和多模态编码器。多模态编码器包括检索注意力以融合检索信息。多模态编码器获得的表示用于VQA分类。
3.结果

PubmedCLIP对CLIP与ROCO进行微调,以获得生物医学图像和文本表示。
MMBert用掩码令牌向CNN输入图像特征,应用掩码语言模型预训练。
MTPT提出了一种包含图像理解任务和问题-图像兼容任务的多任务预训练。
M3AE通过重建掩码令牌和图像对生物医学多模态模型进行预训练。
六、[arXiv 2022] A Dual-Attention Learning Network with Word and Sentence Embedding for Medical Visual Question Answering
保持一致性的医学图像视觉问答
code
0.备注
提出了一个具有单词和句子嵌入的双重关注学习网络(WSDAN)
1.方法
• 提出了用于MVQA的WSDAN,主要解决了提取的问题特征缺乏医学信息且无法完全理解特征的问题;
• 设计了TSE和DAL模块。TSE提取包含关键词和医学信息的问题特征。DAL通过学习自注意力和引导关注来建模单模态和多模态交互;
数据集:
VQA-RAD[43]是一个关于放射学的MVQA数据集,该数据集包含315张医学图像和11种类型的3515对问答(QA)。
VQA-MED 2019[44]在ImageCLEF 2019挑战赛中提出。
注:
TSE模块来获得问题的双重嵌入表示,确保提取的特征既丰富关键词信息又丰富医学信息。对于给定的问题MQ,单词表示如下。首先,使用WordPiece将其标记为多个单词,然后将其投影到嵌入层,以获得单词表示 。句子表示是通过直接提取句子嵌入来创建的,对于MQ使用预训练的句子BERT,
。句子表示是通过直接提取句子嵌入来创建的,对于MQ使用预训练的句子BERT, ,注意机制可以有效地融合不同层次的信息。
,注意机制可以有效地融合不同层次的信息。
DAL具有主要由自注意力和引导注意力组成的编码器-解码器架构。DAL能够同时学习图像引导和问题引导的注意力。
2.结构

WSDAN框架。ResNet-152用于提取图像特征V。利用TSE提取问题特征Q。
DALs构成融合模块,通过加权组合得到融合向量。分类器由MLP和softmax组成。
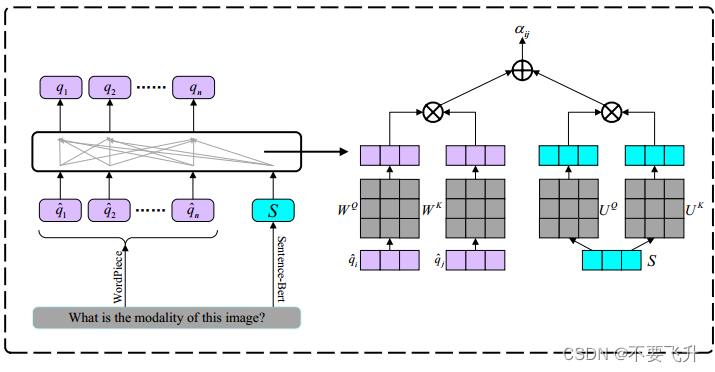
问题编码器:TSE融合词和句子嵌入来获得问题的双嵌入表示。
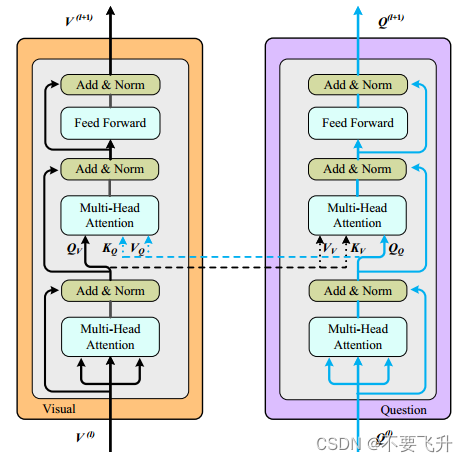
双注意学习(DAL)模块的细节。
第一层和第二层的多头注意分别用于学习自我注意和引导注意。
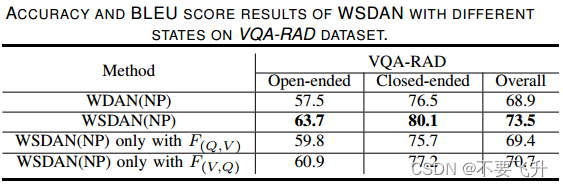
3.结果

七、[arXiv 2023] Multimodal Prompt Retrieval for Generative Visual Question Answering
多模态提示检索用于生成式视觉问答
code
0.备注
通过多模态提示检索(MPR)增强,将检索到的提示和多模态特征集成在一起,以自由文本的形式生成答案。
1.方法
• 引入了一个多模态提示检索模块,通过噪声合成数据和较小的检索数据集,提高了VQA在不同数据分布之间的泛化能力。
• 研究了医学VQA系统在不同数据集之间的零样本数据集适应设置,鼓励未来研究关于数据集适应中VQA系统的上下文预测。
• 提出了一种基于提示的新型生成式VQA模型,使答案输出更加灵活,同时通过多模态提示进行控制生成。
数据集:
SLAKE数据集包括642张图像和超过14,000个英语和中文的VQA对。
VQA-RAD是一个高质量的数据集,包括315个患者扫描和3515个问题。
Radiology Objects in Context(ROCO)ROCO数据集(Pelka等,2018)包含超过81,000个放射学图像字幕对,使其成为用于预训练视觉语言模型的热门医学数据集(Pelka等,2018)。每个图像-字幕对还包含了现有研究中用于突出显示跨度的掩码语言建模的关键字和语义类型(Khare等,2021)。
注:
- 使用多模态编码器来将图像-问题对编码成多模态特征,并执行K最近邻(KNN)搜索来在特征空间中找到最相似的VQA元组。
- 将图片字幕数据集通过模板扩展成图片问答数据集
2.结构
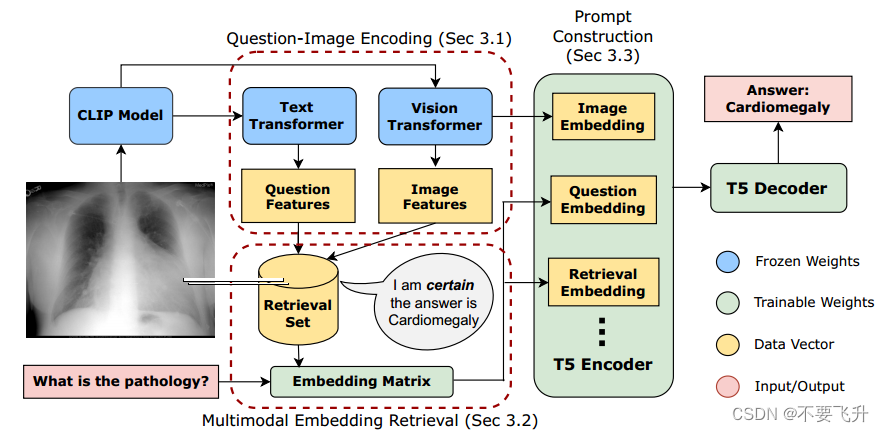
在T5编码器块中包含的三个黄色框表示的编码器提示符中,有三个主要组件。可以选择性地省略这些组件,也可以使用其他数据进一步扩展这些组件。
3.结果

本文提出的生成式提示方法在不同语境层次的域适应环境下的性能。当提供检索上下文时,模型查询k = 1个相关图像-问题对。

SLAKE和VQARAD数据集中前5个最常见问题类型的域适应精度。x轴上的百分比表示每个问题类型在数据集中的比例。MPRgen和MPRgen_PM对k = 1个相关图像问题对使用检索和查询。基于检索的模型优于我们的zero-short基线,并且使用PubMedCLIP检查点初始化MPR有所帮助。
八、[ECCV 2022] Distilled Dual-Encoder Model for Vision-Language Understanding
0.备注
借助蒸馏,在几乎不损失性能的前提下提升推理速度
1.方法
• 提出了DIDE,这是一个用于双编码模型的知识蒸馏框架,可以更好地学习来自融合编码模型的视觉语言理解的跨模态交互。
• 提出的跨模态注意力蒸馏是关键。
数据集:
COCO、Conceptual Captions、SBU Captions和Visual Genome,总共包含了400万张图像
注:
损失:Cross-Modal Contrastive Learning (CMC)跨模态对比学习
Image-Text Matching (ITM)图像-文本匹配(ITM)
Masked Language Modeling (MLM)掩码语言建模(MLM)
2.结构

框架DIDE概览,最好以彩色视图查看。除了软标签,还引入了跨模态注意力蒸馏来指导模型训练。双编码器模型(学生)的视觉到文本的注意力Av2t(蓝色)和文本到视觉的注意力At2v(橙色)与融合编码器模型(教师)对齐。其他注意力分布的部分(灰色)被省略了。
3.结果

视觉-语言理解任务的结果。结果是在4次运行中进行平均的。报告了VQA的vqascore,以及NLVR2和SNLI-VE的准确性。y是重新实现的微调,与DIDE相同。使用相同的超参数在NLVR2数据集上评估了双编码器模型和ViLT的推理速度。其他模型的推理速度提升来自Kim等(2021)的数据。

在三个VLU数据集上,学生模型和教师模型ViLT的平均推理和缓存时间(以秒为单位)。推理时间和缓存时间是在具有批处理大小为32的P100 GPU上评估的。
九、SELF-SUPERVISED VISION-LANGUAGE PRETRAINING FOR MEDIAL VISUAL QUESTION ANSWERING
自监督视觉语言预训练用于医学视觉问答
code
0.备注
遮蔽图像建模、遮蔽语言建模、图像文本匹配以及通过对比学习进行的图像文本对齐(M2I2)
注:在ALBEF上做了修改(些许)
1.方法
数据集:ImageCLEF2022,该数据集进一步分为83,275个训练样本和7,645个验证样本。
VQA-RAD[13]、Slake[15]和PathVQA [14]。在VQA-RAD中,总共有315张图像与3,064个问题-答案对(其中有451对用于测试)。Slake数据集被分成了训练(70%)、验证(15%)和测试(15%)样本,共有14,028个问答对。PathVQA是其中最大的数据集,包含32,799个问答对,分别用于训练、验证和测试,比例为50%、30%和20%。
注:
2.结构

图像由一个包含12层的视觉Transformer(ViT)编码,而文本特征则由一个6层Transformer提取,该Transformer由预训练的BERT模型的前6层初始化,而最后的6层BERT层用作学习多模态互动的多模态编码器。
3.结果

在VQA-RAD测试集上与最先进的方法进行比较。其中,“free”表示仅使用测试集中的“freeform”答案类型,而“free+para”表示同时使用两种答案类型。
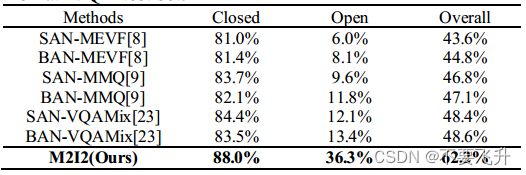
与PathVQA测试集上最先进方法的比较。

与Slake测试集上最先进方法的比较。
十、Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
专家知识感知的图像差异表示学习,用于差异感知的医学视觉问答
code
0.备注
提出了一个胸部X射线图像差异VQA数据集,MIMIC-Diff-VQA。
提出了一个系统,通过比较当前医学图像(主要图像)与过去就诊的医学图像(参考图像)来回答医生的问题。
1.方法
1)提出了医学图像差异视觉问答问题,并构建了第一个大规模医学图像差异视觉问答数据集,MIMIC-Diff-VQA。该数据集包括164,324对图像,其中包含700,703个问题-答案对,涉及各种属性,包括异常、存在、位置、级别、类型、视图和差异。
-
提出了一种解剖结构感知的图像差异模型,用于提取与疾病进展和干预相关的图像差异特征。我们从解剖结构中提取特征,并比较每个结构的变化,以减少由体位、视图和器官的非刚性变形引起的图像差异。
-
开发了一种多关系的图像差异图特征表示学习方法,利用了空间关系和语义关系(从专家知识图中提取)来计算图像差异图特征表示,生成答案并解释答案是如何在不同的图像区域生成的。
数据集:
注:
2.结构

3.结果

总结
自用笔记,随时修改















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









