







基本简介
Fair Resource Allocation in Federated Learning一文中针对普通的FedAvg算法对于单纯最小化聚合损失函数可能会对某些设备带来优势或者劣势。q-FFL它能使联邦网络中的设备分布更加公平(均匀)、准确。目标是确保培训过程不会过拟合模型任何一个设备。目标过于严格,只优化性能最差的设备,并且只在两三个设备网络中测试。
核心思想
由目标函数可知,为了更加公平需要调整表现贡献差的设备的权重,来减小准确度分布的方差。这个调整权重需要是动态的,因为设备的表现取决于被训练的模型,这个不能被先验评估。
对于损失函数更改为:
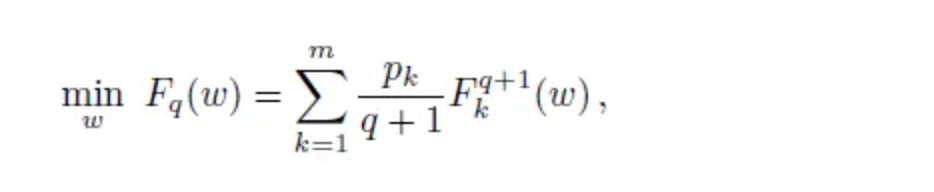
q=0,即为经典目标函数,大的q表示 我们强调具有较高局部经验损失的设备,即Fk(w),从而减少了训练精度分布的方差,并可能根据定义诱导公平性。
足够大的q就变成了max-min fairness(AFL), 而从而性能最差的设备将主导目标。
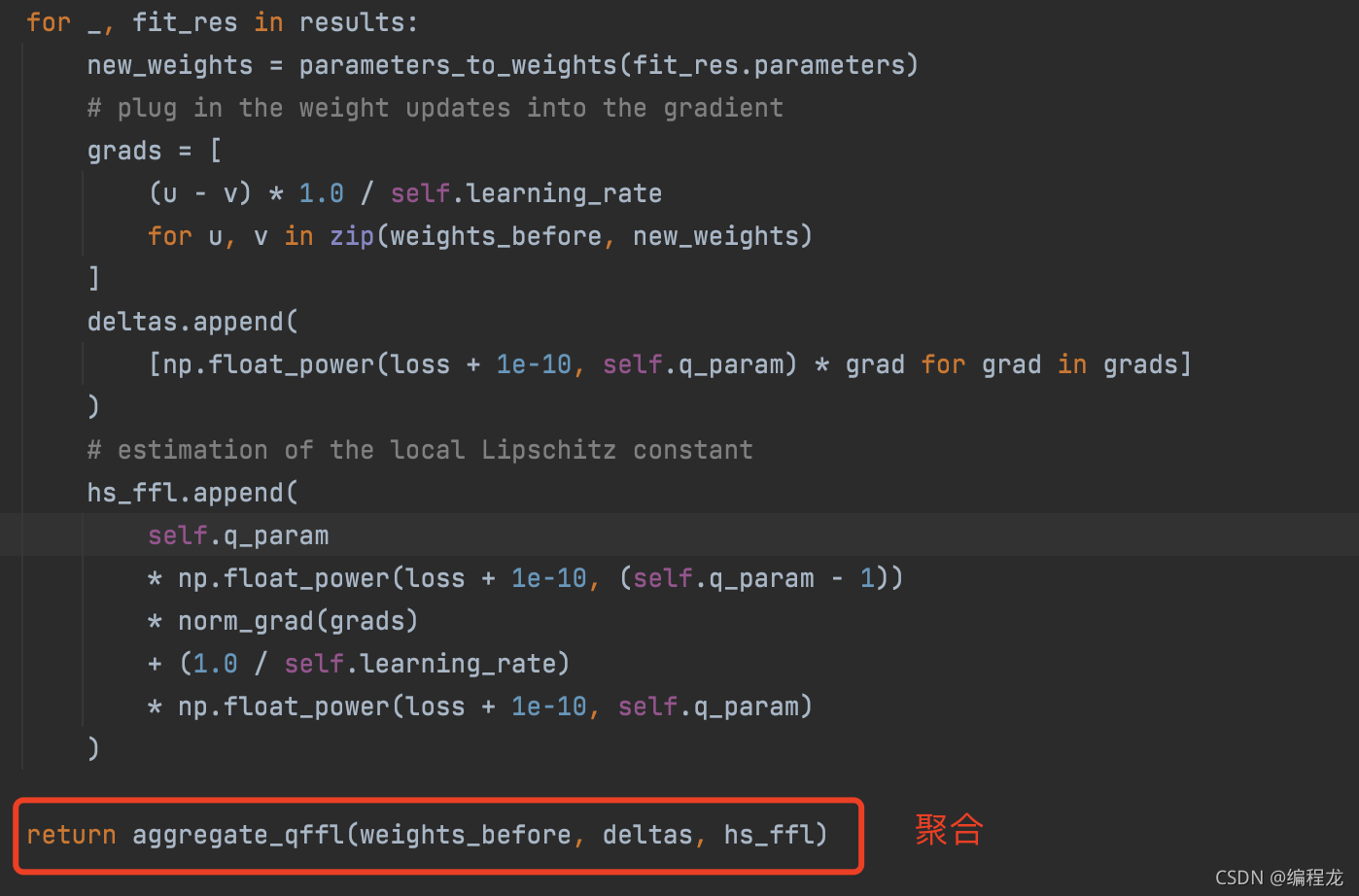
算法实现

代码实现
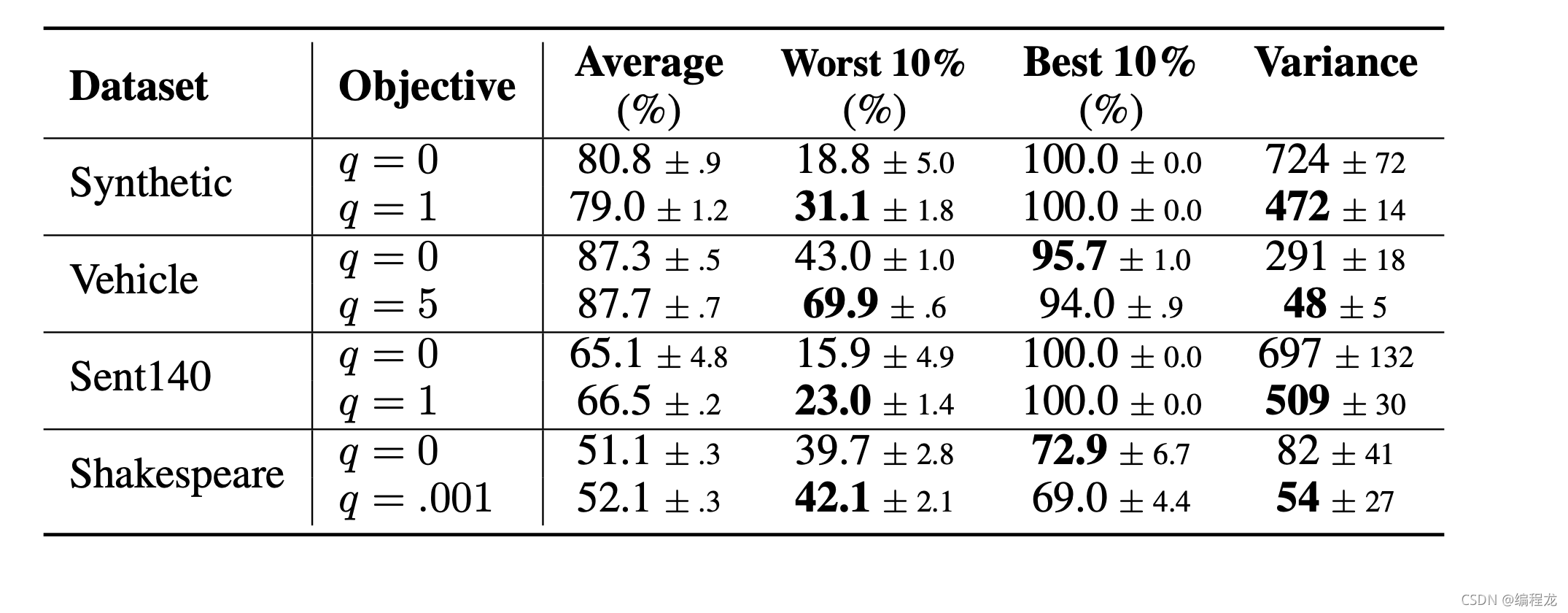
实验结果















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









