



 这篇博客介绍了多个用于异常检测研究的数据集,包括UCSD、AvenueDataset、shanghaiTech、UCF-Crime和MVTecAD等。这些数据集涵盖了各种场景和异常类型,如行人异常行为、室内室外环境、多视角和像素级异常标注等,旨在促进和评估异常检测算法的性能。同时,博客提到了数据集的挑战,如相机抖动、训练数据中的异常值和多样性的缺失等。
这篇博客介绍了多个用于异常检测研究的数据集,包括UCSD、AvenueDataset、shanghaiTech、UCF-Crime和MVTecAD等。这些数据集涵盖了各种场景和异常类型,如行人异常行为、室内室外环境、多视角和像素级异常标注等,旨在促进和评估异常检测算法的性能。同时,博客提到了数据集的挑战,如相机抖动、训练数据中的异常值和多样性的缺失等。
在计算机视觉的大研究领域内,有一个小方向叫做异常检测(Anomaly Detection),也叫做新颖性检测。在该方向下有以下的数据集作为大家所提出的新的研究方法的检测精度的测试。UCSD, Subway dataset , Avenue Dataset, shanghaiTech, UCF-Crime
UCSD异常检测数据集:视频–>图片
数据集链接地址:http://www.svcl.ucsd.edu/projects/anomaly/UCSD_Anomaly_Dataset.tar.gz
视频数据是通过学校中固定在较高位置上的摄像机获得的,俯瞰人行道。走道中的人群密度是变化的,从稀疏到非常拥挤。按照数据集的规定,正常的情况是视频仅包含行人。
异常的事件可以分为:
1)非人行道物体在人行道上的流通(如:车辆等非人的物体)
2)异常的行人运动模式(如:从草坪中穿过,跑步等人类非常规行走特点)
收录的数据被分成2个子集,每个子集对应于不同的场景。从每个场景记录的视频片段被分成大约200帧的各种片段。
1)Peds1:走向和远离相机的人群剪辑,以及一些透视失真。包含34个培训视频样本和36个测试视频样本。
2)Peds2:行人移动平行于相机平面的场景。包含16个培训视频样本和12个测试视频样本。
对于每个剪辑,地面实况注释包括每帧的二进制标记,指示在该帧处是否存在异常。此外,Peds1的10个剪辑和Peds2的12个剪辑的子集提供有手动生成的像素级二进制编码,其识别包含异常的区域。这旨在使得能够评估关于算法定位异常的能力的性能。


Avenue Dataset:视频–>图片
数据集下载链接:http://www.cse.cuhk.edu.hk/leojia/projects/detectabnormal/Avenue_Dataset.zip
详细介绍链接:
包含16个训练视频和21个测试视频,共有47个异常事件,视频总共包含30652帧。包括投掷物体、游荡和跑步。人的大小可能会因为相机的位置和角度而改变。训练视频包含正常情况下的视频。测试视频包含标准和异常事件视频。

我们的数据集包含以下挑战。
1)轻微的相机抖动(在测试视频2,帧1051 - 1100)出现。
2)训练数据中包含了一些异常值。
3)一些正常模式很少出现在训练数据中。
评估标准(空间位置)
1.我们的评估不仅是在框架层面,而且考虑空间位置。我们使用矩形标记异常事件。我们采用VOC Pascal风格的对象检测准则进行异常事件检测。
shanghaiTech数据集:图片
下载链接:https://svip-lab.github.io/dataset/campus_dataset.html
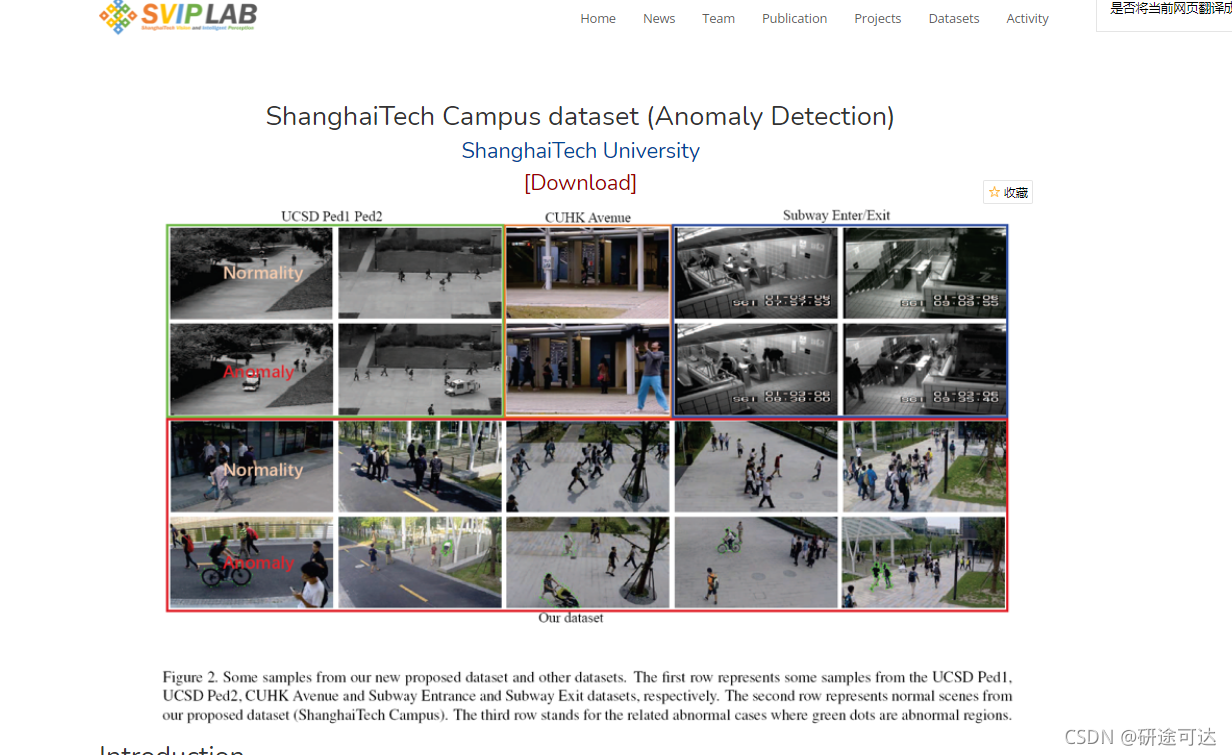
希望训练的异常检测模型能直接应用于多视角多场景。然而,现有的数据集几乎都只包含一个固定角度摄像机拍摄的视频,缺乏场景和视角的多样性。为了提高场景的多样性,我们建立了一个新的异常检测数据集。此外,我们还介绍了该数据集中由突然运动引起的异常,如在现有数据集中未包含的在数据集中的追逐和争吵等。这些特性使我们的数据集更适合实际场景。上海理工大学校园数据集有13个场景,具有复杂的光照条件和摄像机角度。它包含130个异常事件和27万多个训练框架。此外,我们的数据集还注释了异常事件的像素级地面真相。
shanghaiTech数据集包含了part_A_final,part_B_final两部分。
A部分训练集:300张图片,测试集:182张图片。
B部分训练集:400张图片,测试集:316张图片。
共1198张,330,165个注释头。
Subway dataset
该数据集下载链接还未找到……
总共有两个小时。有两类,即入口和出口。不寻常的事件包括走错方向和游荡。更重要的是,该数据集记录在室内环境中,而上述数据集则记录在室外环境中。
UCF-Crime (Weakly Supervised)
下载地址:文件很大100来个G
是一个真实世界监控视频的大规模数据集,包括13种异常事件和1900个长而未修剪的视频,其中1610个视频是训练视频,其他的是测试视频。

该数据集比较明显的缺点:(借鉴知乎大佬的话)
有些过短的视频通过重复播放来凑出时长!
有些视频并非是真实监控视频
有些异常视频竟然存在分镜切换!
有些视频中的异常行为,我作为人类难以判断
视频不全是彩色视频,存在夜视视频(灰度),且视频尺寸、缩放不统一
异常视频与正常视频在异常事件以外的差异非常明显(在镜头中异常事件未发生前,作为人类,我可以根据拍摄角度与视频质量直接猜出这个视频接下来是否有异常事件发生)
大部分异常视频片段的前面为正常片段,异常事件发生后才是异常片段,而标记将整段视频都标记为异常(弱监督),因此对算法提出了更高的要求。
MVTec
MVTec AD是MVtec公司提出的一个用于异常检测的数据集,发布于2019CVPR。与之前的异常检测数据集不同,该数据集模仿了工业实际生产场景,并且主要用于unsupervised anomaly detection。数据集为异常区域都提供了像素级标注,是一个全面的、包含多种物体、多种异常的数据集。
训练集中只包含正常样本,测试集中包含正常样本与缺陷样本,因此需要使用无监督方法学习正常样本的特征表示,并用其检测缺陷样本。这是符合现实的做法,因为异常情况不可预知并无法归纳。

数据集一共包含15个类别,其中3629张图片用于训练与验证,1725张用于测试,其中训练集只包含正常样本。其中5类为纹理类数据,包含规律的纹路(毛毯、网格)以及随机纹路(皮革、瓷砖、木材);剩下的10类为物体类数据,包含刚性的、特定外观的物体(瓶,金属螺母),可变形物体(电缆)或包括自然变化物体(榛子),并且某部分获取的物体处于大致对齐位置(e.g. 牙刷,胶囊和药丸),其他为随机摆放(e.g. 金属螺母,螺丝和榛子)。测试集中包含73种不同的异常,例如物体表面缺陷(e.g.划痕,凹痕)、结构缺陷(e.g.物体出现部分扭曲)或者由于缺少某些物体组成部件而表现出来的缺陷。
所有图像的尺寸在700x700 ~ 1024x1024之间,其中网格、拉链以及螺丝为灰度单通道图像。数据集为所有的缺陷区域均提供了像素级标注区域,总共包含接近1900个标注区域。
MNIST
MNIST: 这个数据集包括从“0”到“9”60000个手写数字。将这10类数字中的每一个都作为目标类(即插入值),我们通过从其他类别中随机抽取比例为10%到50%的图像来模拟异常值。这个实验对所有的十位数类别都要重复进行。
Caltech-256:
Caltech-256:该数据集包含256个对象类别,总共有30,607张图像。每个类别至少有80张图片。
Similar to previous works [50], we repeat the procedure three times and use images from n ∈ {1, 3, 5}randomly chosen categories as inliers (i.e., target). The first 150 images of each category are used, if that category has more than 150 images.A certain number of outliers are randomly selected from the “clutter” category, such that each experiment has exactly 50% outliers.
使用n∈{1,3,5}随机选取的图像作为inliers(即目标)。如果每个类别的图像超过150幅,则使用该类别的前150幅图像,从“杂类(clutter)类别中随机选取一定数量的异常值,使每个实验都有50%的离群值。

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









