







在传统的参数服务器架构下,模型的传递通信耗时巨大,作者提出了一种新的架构:TSEngine,该架构能直接应用到已有的参数服务器架构下,作者已将代码开源。
原文链接:TSEngine: Enable Efficient Communication Overlay in Distributed Machine Learning in WANs
ABS
提出TSEngine解决广域网下分布式机器学习参数服务器的通信问题。
TSENgine:一个在广域网分布式机器学习下应用于参数服务器的自适应通信调度器,可以提供高效的通信覆盖。
核心思想:根据主动网络感知,动态的调整参数服务器和工作结点之间的通信逻辑。
实现了能应用于主流参数服务器系统的TSEngine,证明了其高效性。
1 INTRO
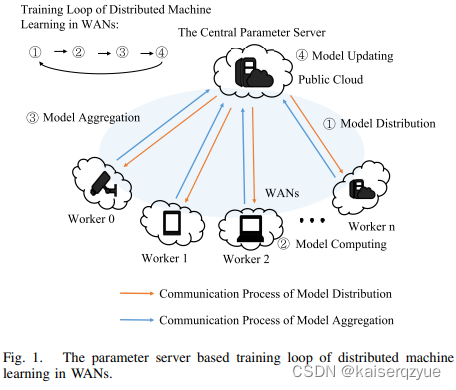
在之前提出的联邦学习中的模型如Fig. 1所示,这种模型存在一个内在的问题,在模型下发以及模型聚合过程中,存在一对多的通信模型(中心服务器一次性下发参数给多个工作者,多个工作者可能同时上传参数给中心服务器),在服务器带宽受限的情况下,容易造成网络严重拥堵。
TSEngine和没有该功能的网络相比能够大幅度的减少训练耗时:
- 在 12 12 12个工作方的时候,Alexnet的训练时间减少 58 % 58\% 58%,Mobilenet减少 34 % 34\% 34%;
- 在 128 128 128个工作者的时候,能减少 95 % 95\% 95%的模型分发时间, 90 % 90\% 90%的模型聚合时间。
同时TSEngine的扩展性非常好。
本文的贡献:
- 指出显存的参数服务器的通信架构有着明显的性能不足,提出并实现TSEngine;
- 指定了TSEngine的全新协议适用于模型分发和模型聚合;
- 在一个广泛应用的参数服务器上构建了TSEngine的原型,演示了其高效性。
2 BACKGROUND AND MOTIVATIONS
2.1 Distributed Machine Learning in WANs (DML-WANs)
收集数据到数据中心进行训练不仅需要大量的带宽,同时违背了用户隐私管制条例。
参数服务器系统架构虽然解决了用户隐私相关的问题,但是这种方式需要进行成千上万次的模型分发和模型聚合,这就导致了需要进行多次通信,而通信的效率受到带宽的限制,这导致整个训练过程速度非常缓慢。
2.2 Motivation: Dynamic Communication Scheduling for Efficient Communication Overlay
一个好的参数服务器应该具备的三个特点:
- 能够根据工作结点之间的地理差异构建不同的通信逻辑;
- 能够在实际任务的过程中进一步调整构建的通信逻辑;
- 除了选择最优的通信路径,还应该能够调整通信的顺序以进一步提升通信的效率。
首先进行不同模型分发算法的对比:

如Fig. 2所示,(a)表示的传统的参数服务器模型分发,(b)表示树形分发,(c)表示动态调整的分发(TSEngine)。下面进行详细说明:
- (a):对于该结构的模型分发,每条线路占用服务器带宽的 1 6 \frac 1 6 61因此如果每个模型收到数据均需要等待 6 s 6s 6s(假设带宽为:模型大小);
- (b):对于该模型来说:1,2会等待 2 s 2s 2s获得模型,之后3,4,5,6同样需要等待 2 s 2s 2s,总共等待了 4 s 4s 4s(假设每个节点的带宽相同),平均为 3.3 s 3.3s 3.3s;
- (c):根据模型动态调整,得到了如图所示的传播方案,1需要等待 1 s 1s 1s之后同服务器一起传播,2,4等待 1 s 1s 1s之后,3,5,6等待 1 s 1s 1s(各节点等待时间可以从右图看到),平均等待 2.3 s 2.3s 2.3s。
按照同样的比较方法可以得出模型聚合的耗时,如Fig. 3所示:

(分析过程同上,只是从自顶向下变成了自底向上)
3 Problem Formulation
3.1 Dynamic Communication Scheduling for Model Distribution
Integer Linear Programming(ILP):
m
i
n
i
m
i
z
e
∑
j
∈
D
t
j
s
.
t
.
t
j
=
∑
i
,
j
,
k
x
i
,
j
,
k
×
(
t
i
,
j
s
e
n
d
+
V
b
i
,
j
,
k
)
,
∀
j
∈
D
,
i
∈
{
s
}
∪
D
,
i
≠
j
t
i
,
j
s
e
n
d
≥
t
i
≥
0
,
∀
i
∈
D
,
j
∈
D
,
i
≠
j
∑
i
,
j
,
k
x
i
,
j
,
k
=
1
,
∀
j
∈
D
∑
i
,
j
,
k
x
i
,
j
,
k
×
b
i
,
j
,
k
≤
c
e
,
∀
e
∈
p
i
,
j
,
k
t
j
:
结点
j
收到模型的时刻
x
i
,
j
,
k
:
值为
0
或
1
,表示结点
i
,
j
之间的传输是否通过第
k
条路径
t
i
,
j
s
e
n
d
:
结点
i
向结点
j
发送模型的时刻
V
:
模型大小
b
i
,
j
,
k
:
结点
i
,
j
之间的第
k
条路径的带宽
D
:
所有工作结点的集合
c
e
:
某条边的带宽
p
i
,
j
,
k
:
结点
i
,
j
的第
k
条路径的边集
\begin{aligned} &minimize \sum_{j\in D}t_j \\ s.t. \\ &t_j=\sum_{i,j,k}x_{i,j,k}\times(t^{send}_{i,j} + \frac V {b_{i,j,k}}), \forall j\in D,i\in\{s\}\cup D, i\ne j \\ & t_{i,j}^{send} \ge t_i \ge 0, \forall i \in D,j\in D, i\ne j\\ &\sum_{i,j,k}x_{i,j,k}=1,\forall j\in D\\ &\sum_{i,j,k}x_{i,j,k} \times b_{i,j,k} \le c_e, \forall e \in p_{i,j,k}\\ \\ &t_j:结点j收到模型的时刻\\ &x_{i,j,k}:值为0或1,表示结点i,j之间的传输是否通过第k条路径\\ &t_{i,j}^{send}:结点i向结点j发送模型的时刻\\ &V:模型大小\\ &b_{i,j,k}:结点i,j之间的第k条路径的带宽\\ &D:所有工作结点的集合\\ &c_e:某条边的带宽\\ &p_{i,j,k}:结点i,j的第k条路径的边集\\ \end{aligned}
s.t.minimizej∈D∑tjtj=i,j,k∑xi,j,k×(ti,jsend+bi,j,kV),∀j∈D,i∈{s}∪D,i=jti,jsend≥ti≥0,∀i∈D,j∈D,i=ji,j,k∑xi,j,k=1,∀j∈Di,j,k∑xi,j,k×bi,j,k≤ce,∀e∈pi,j,ktj:结点j收到模型的时刻xi,j,k:值为0或1,表示结点i,j之间的传输是否通过第k条路径ti,jsend:结点i向结点j发送模型的时刻V:模型大小bi,j,k:结点i,j之间的第k条路径的带宽D:所有工作结点的集合ce:某条边的带宽pi,j,k:结点i,j的第k条路径的边集
离线ILP算法存在的问题:
- 获取整个网络的带宽是耗费巨大的;
- 解决ILP的耗时是巨大的,该问题是一个NP-Hard问题;
- 过时的解决方案(离线意味着假设网络不会发生变动,但是在实际中网络不发生变动是不可能的)。
正是因为存在这些问题,作者后面提出了在线的算法。
3.2 Dynamic Communication Scheduling for Model Aggregation
Integer Linear Programming(ILP):
m
i
n
i
m
i
z
e
t
s
s
.
t
.
t
j
=
m
a
x
{
x
i
,
j
,
k
×
(
t
i
,
j
s
e
n
d
+
V
b
i
,
j
,
k
)
}
,
∀
j
∈
D
,
i
∈
{
s
}
∪
D
,
i
≠
j
t
i
,
j
s
e
n
d
≥
t
i
≥
0
,
∀
i
∈
D
,
j
∈
{
s
}
∪
D
,
i
≠
j
∑
i
,
j
,
k
x
i
,
j
,
k
=
1
,
∀
j
∈
D
∑
i
,
j
,
k
x
i
,
j
,
k
×
b
i
,
j
,
k
≤
c
e
,
∀
e
∈
p
i
,
j
,
k
t
s
:
服务器收到整个模型的时刻
t
j
:
结点
j
收到整个模型的时刻
x
i
,
j
,
k
:
值为
0
或
1
,表示结点
i
,
j
之间的传输是否通过第
k
条路径
t
i
,
j
s
e
n
d
:
结点
i
向结点
j
发送模型的时刻
V
:
模型大小
b
i
,
j
,
k
:
结点
i
,
j
之间的第
k
条路径的带宽
D
:
所有工作结点的集合
c
e
:
某条边的带宽
p
i
,
j
,
k
:
结点
i
,
j
的第
k
条路径的边集
\begin{aligned} &minimize\ t_s \\ s.t. \\ &t_j=max\{x_{i,j,k}\times(t^{send}_{i,j} + \frac V {b_{i,j,k}})\}, \forall j\in D,i\in\{s\}\cup D, i\ne j \\ & t_{i,j}^{send} \ge t_i \ge 0, \forall i \in D,j\in \{s\}\cup D, i\ne j\\ &\sum_{i,j,k}x_{i,j,k}=1,\forall j\in D\\ &\sum_{i,j,k}x_{i,j,k} \times b_{i,j,k} \le c_e, \forall e \in p_{i,j,k}\\ \\ &t_s:服务器收到整个模型的时刻\\ &t_j:结点j收到整个模型的时刻\\ &x_{i,j,k}:值为0或1,表示结点i,j之间的传输是否通过第k条路径\\ &t_{i,j}^{send}:结点i向结点j发送模型的时刻\\ &V:模型大小\\ &b_{i,j,k}:结点i,j之间的第k条路径的带宽\\ &D:所有工作结点的集合\\ &c_e:某条边的带宽\\ &p_{i,j,k}:结点i,j的第k条路径的边集\\ \end{aligned}
s.t.minimize tstj=max{xi,j,k×(ti,jsend+bi,j,kV)},∀j∈D,i∈{s}∪D,i=jti,jsend≥ti≥0,∀i∈D,j∈{s}∪D,i=ji,j,k∑xi,j,k=1,∀j∈Di,j,k∑xi,j,k×bi,j,k≤ce,∀e∈pi,j,kts:服务器收到整个模型的时刻tj:结点j收到整个模型的时刻xi,j,k:值为0或1,表示结点i,j之间的传输是否通过第k条路径ti,jsend:结点i向结点j发送模型的时刻V:模型大小bi,j,k:结点i,j之间的第k条路径的带宽D:所有工作结点的集合ce:某条边的带宽pi,j,k:结点i,j的第k条路径的边集
该部分的离线算法存在的问题域模型分发离线算法相似,此处不在赘述。同时离线算法还需要考虑不同服务器的性能指标。
4 TSEngine
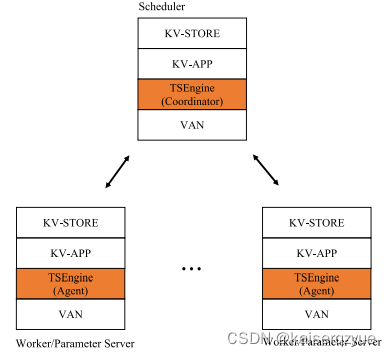
4.1 Design Overview and Architecture
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nQWVjDj3-1669097664288)(毕业设计.assets/image-20221121103710117.png)]](https://img-blog.csdnimg.cn/7c12598b67ab4f248a280a8576f79f60.png)
如Fig. 4所示,每个结点部署一个本地代理(不需要多余的服务器),同时整个系统拥有一个全局协作者(需要一个单独的服务器):
- 在模型分发的阶段,当一个工作者收到模型后,会向中心协作者发送消息请求成为一个新的发送者。全局协作者会为请求返回一个接收结点;
- 在模型聚合的阶段,当一个本地代理训练好一个模型,会发送通知给全局协作者,通知其自己已经训练完成,全局协作者会选择一对节点进行局部聚合。
(在整个上述的过程中,假设缓冲区足够大能够缓存所有的到来的数据)
4.2 Auto-Learning Communication Scheduling Protocol (AL-CSP) for Model Distribution
AL-CSP有五个基本操作:
- NS_REQUEST:请求获取一个结点,用于向该结点发送模型,包含两个参数:req_node表示请求的节点,prev_throughput表示之前的带宽;
- NS_UPDATE:用于更新矩阵A(存储的是两个结点之间的带宽);
- NS_INQUIRY:计算产生一个需要获取模型的结点;
- NS_REPLY:回应NS_REQUEST包含一个参数:ds_recv_表示生成的结点,如果ds_recv_=-1代表所有节点都已完成模型的分发;
- NS_TRAN:向指定的节点发送模型。
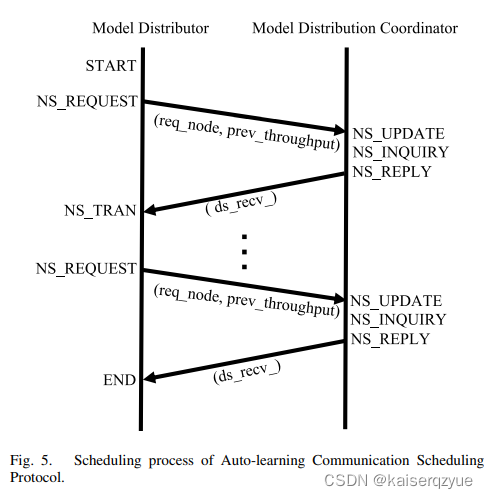
协议过程如Fig. 5所示:
- 当一个结点收到模型的时候,会执行NS_REQUEST企图获得一个结点编号,将模型发送给该结点;
- 对于全局协调者来说,当收到NS_REQUEST时,如果该请求携带throught_put则需要限制性NS_UPDATE更新矩阵A(矩阵保存着结点之间的带宽,如果为-1表示暂时不知道带宽);接着执行NS_INQUIRY获取一个需要发送模型的结点;
- 全局协调者通过NS_REPLY将获取的结点编号发送给请求方;
- 请求方检查ds_recv_是否有效。如果有效,则通过NS_TRAN将模型发送给该结点,若无效则表明所有结点均已收到模型,不进行任何操作,同时计算throughput用于下一次发送NS_REQUEST。
NS_INQUIRY的详细过程如Algorithm 1所示:

(B为一个一维数组,B[i]表示节点i是否获得模型,为1表示获得,为0表示还未获得)
说明:以 p = m i n { S N T O T s , p m a x } p=min\{\frac {SN} {TOTs}, p_{max}\} p=min{TOTsSN,pmax}的概率向带宽最大的结点发送意味着,即使所有结点的带宽已知,仍然有 1 − p m a x 1-p_{max} 1−pmax的概率随机进行发送,这样可以进行带宽的动态更新。
4.3 Minimal-Waiting-delay Communication Scheduling Protocol (MWD-CSP) for Model Aggregation
MWD-CSP有六个基本操作:
- AG_READY:一个结点发送AG_READY表明自己完成了局部的计算,可以进行聚合操作,req_node表明请求聚合的节点;
- AG-UPDATE:更新矩阵A;
- AG_INQUIRY:通过计算产生一个聚合对(ag_send_,ag_recv_)表明发送方和接收方的结点编号;
- AG_REPLY:将产生的聚合对发送给请求方;
- AG_TRAN:ag_send_向ag_recv_发送模型
- AG_FIN:发送方计算吞吐量,并发送给全局协调者。
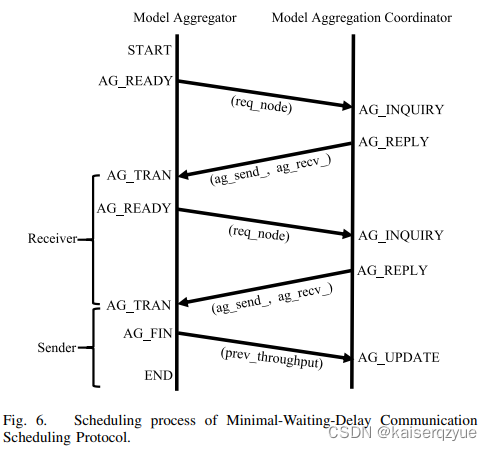
协议过程如Fig. 6所示:
- 当一个结点完成了局部的计算之后,发送AG_READY给全局协调者;
- 协调者执行AG_INQUIRY获取聚合对;
- 协调者执行AG_REPLY将聚合对发送给ag_send_和ag_recv_(其中有一个是请求方);
- ag_send_将自己的模型通过AG_TRAN操作发送给ag_recv_,并根据完成时间计算throughput并发送AG_FIN给协调者,而ag_recv_在收到模型完成计算后,会向发送方返回时间,同时该结点继续执行AG_READY。
模型聚合什么时候会结束呢?可以知道的时参数服务器是知道自己是参数服务器的,所以当参数服务器作为接收模型的结点的时候,参数服务器此时不在进行AG_READY操作,模型即可结束。(此处查看代码实际上是根据已经发送工作结点的数量来确定,而参数服务器实际上会参与多次聚合)。
AG_INQUIRY的详细过程如Algorithm 2所示:

5 Implementation and Deployment of TSEngine on MXNet
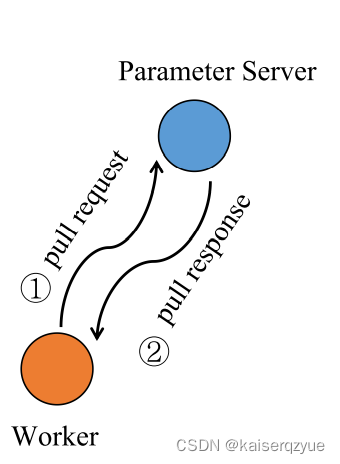
PS-LITE:一个参数服务器架构的实现,位于MXNet包含两种基本操作:
-
Pull(key)表示获取模型(从参数服务器获取,需要所有节点聚合之后才能获取)即只有工作结点获得push response后才能通过Pull获取模型;
-
Push(key, model)表示放入模型(向参数服务器投放模型)。
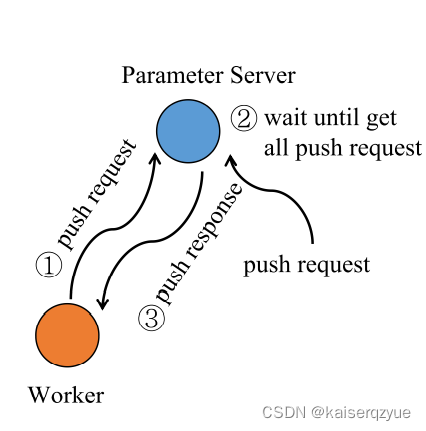
TSEngine在PS-LITE中的位置如下图所示:
TSEngine实现了两个操作: -
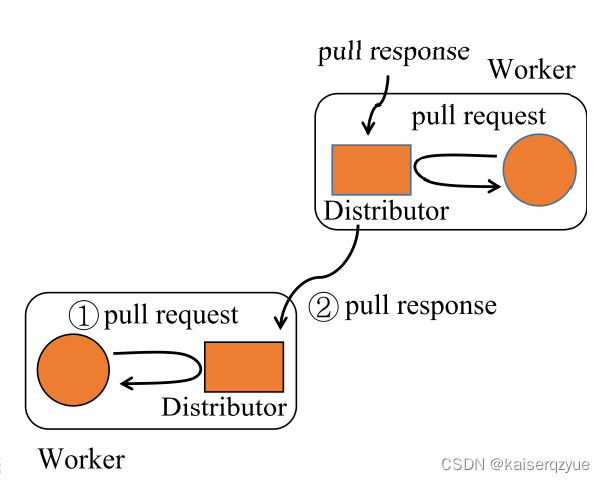
TSPull(key):当一个结点执行TSPull操作之后,该结点只是将请求发送给了Distributor,此时该结点会阻塞,直到该结点收到一个pull response同时该结点会将继续向某个结点发送pull response(如上一部分的协议所示);
-
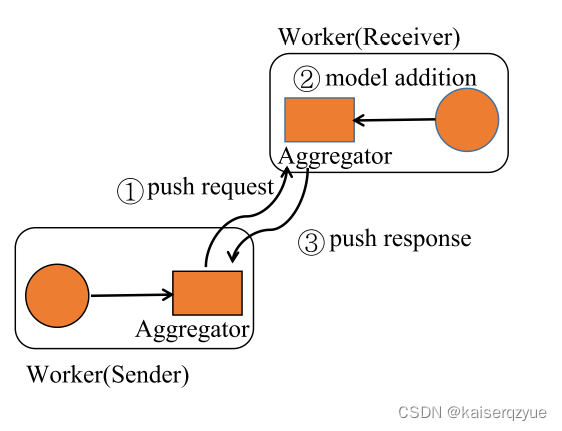
TSPush(key, model):当执行TSPush操作时,结点根据自己被定义成发送方还是接收方执行不同的操作,如果被定义成发送方,那么结点向介绍方发送模型参数;如果被定义成接收方,那么该结点等待发送方发送数据,并且进行局部的模型聚合,完成聚合后向发送方发送push response,之后(完成局部聚合的一方)继续执行TSPush。
在MXNet上的实现,可以不用改动代码,只需要添加环境变量ENABLE_TS=1即可,代码位置:github.com/zhouhuaman/TSEngine。
6 Evaluation
6.1 Overall Training Efficiency of TSEngine
实验:
- 实验环境:一个全局协调者(Docker 0),一个参数服务器(Docker 1),十二个工作者(Docker 2 - Docker 13),每个Docker的CPU拥有八个核心,12GB的内存。Docker 2 - Docker 7共用一个GTX 1080Ti,Docker 8 - Docker 13共用一个GTX 1080Ti,使用流量控制工具控制结点(Docker)之前的带宽;随机的设置带宽在155Mbps和455Mbps之间(需要注意的是,这里即使是随机的,但是仍然要保证对比实验的任意两个Docker之间的带宽是相同的,所以这里使用的是伪随机,当随机种子确定是,不同的实验可以随机生成相同的带宽);
- 实验方法:进行对比实验,包含原始的参数服务器方法、二叉树方法、RACK以及TSEngine,每个实验包含相同的训练次数(780次迭代)使用了AlexNet和MobileNet两种模型,使用Fashion-MNIST进行模型的训练,模型的超参数设置都相同,初始化参数的设置也相同,这也表示模型最终的结果会一样,同时模型的计算时间是相同的,所以可以用训练结束的时间的高低来比较通信方法的效率。
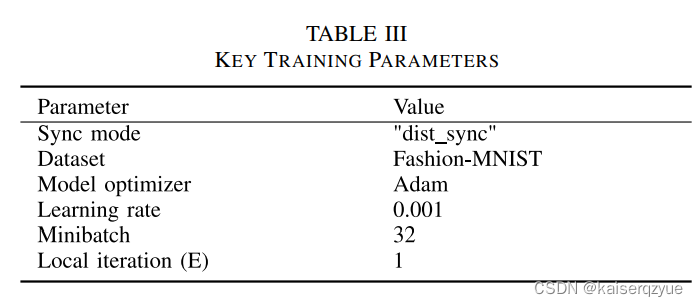
Table 3是模型使用的参数。
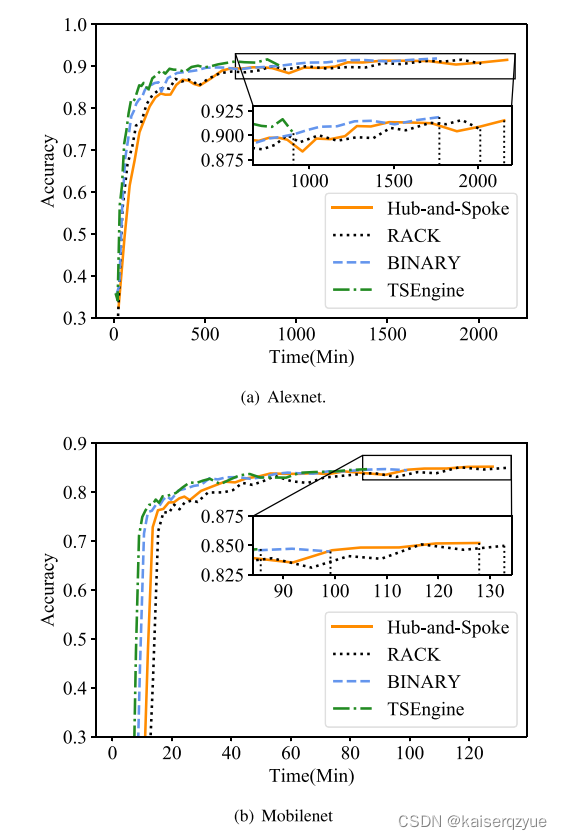
实验结果如上图所示,可以看到详细的时间关系。
6.2 Efficiency of Auto-Learning Communication Scheduling Protocol (AL-CSP)
这一部分完全用于苹果通信效率,而没有模型计算,模型的计算时间被一个随机休眠时间给代替(需要保证不同实验下,该时间相同),这样做是因为模型的计算不在耗费计算机资源,可以设置更加庞大的网络结构。
如何定义通信时间?
C
=
1
r
n
∑
i
=
1
r
∑
j
=
1
n
t
i
j
C = \frac 1 {rn} \sum_{i=1}^r\sum_{j=1}^n t_{ij}
C=rn1i=1∑rj=1∑ntij
其中
r
r
r表示通信轮数,
n
n
n表示节点个数
t
i
j
t_{ij}
tij表示第
i
i
i轮节点
j
j
j收到模型的时间。
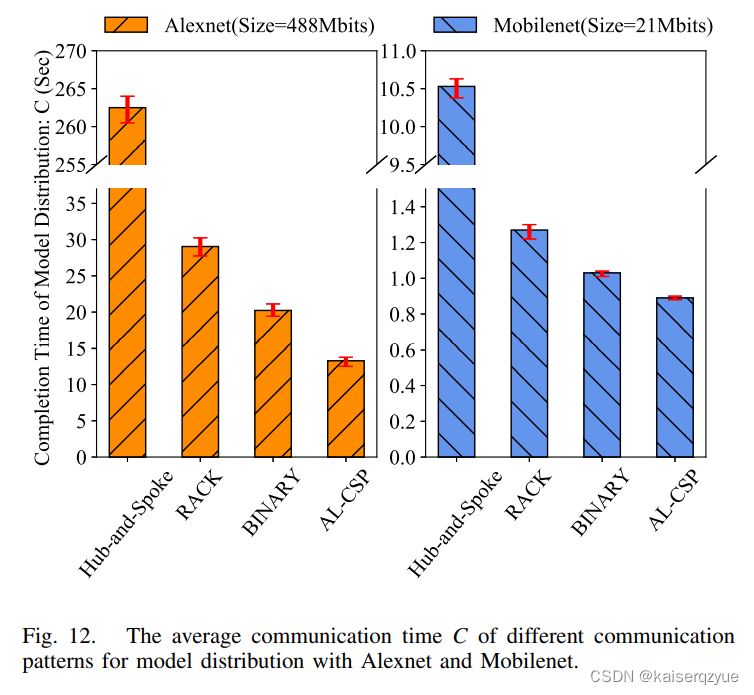
Fig. 12展示了不同的架构在不同的模型下的
C
C
C值。
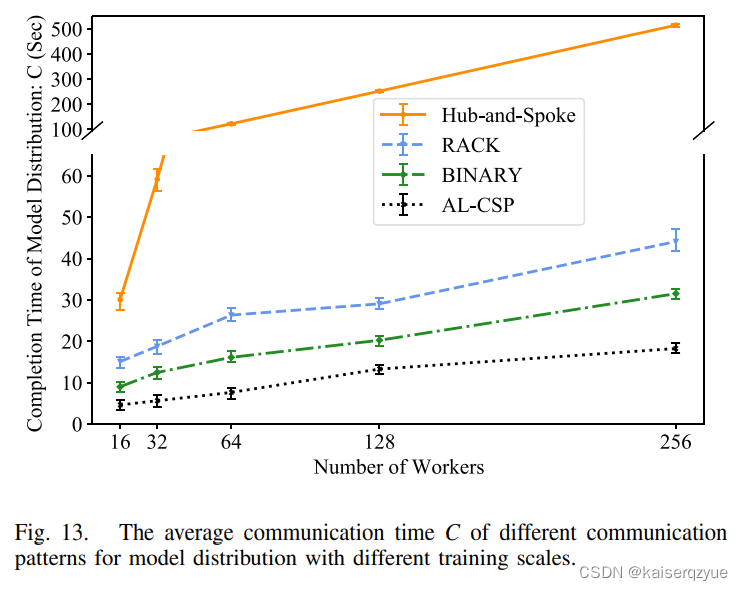
Fig. 13展示了当增加工作者数量时,各个通信架构下的
C
C
C值变化。
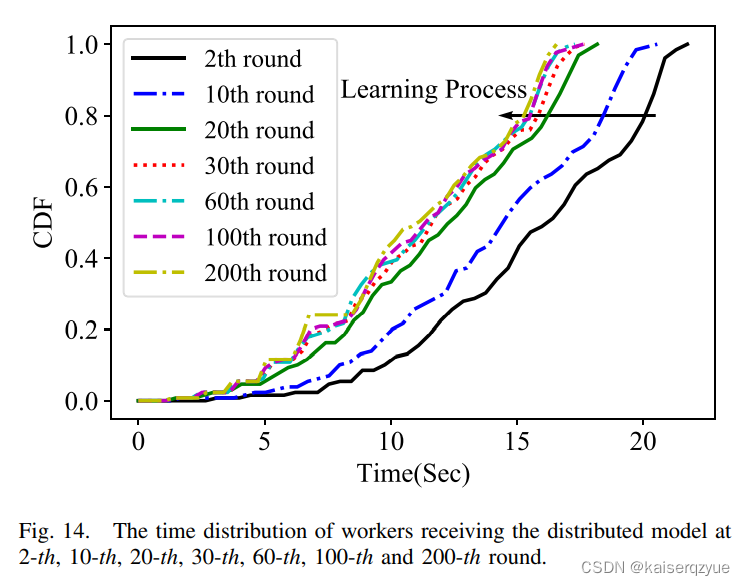
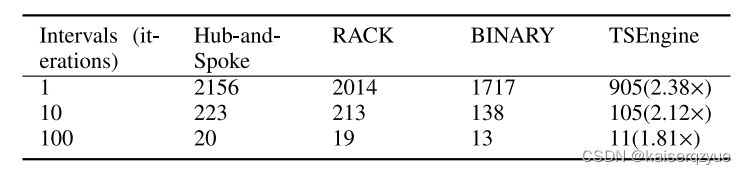
Fig. 14展示了不同轮数时TSEngine的时间花费,从图中可以看出,当轮数增大时,时间花费会减小(图中曲线左移),这是因为在一开始TSEngine关于带宽的信息知道很少,随着通信的进行,模型动态地获得了网络的带宽,从而提升了通信的效率(图中的CDF表示概率分布函数)。
6.3 Efficiency of Minimal-Waiting-Delay Communication Scheduling Protocol (MWD-CSP)
如何定义聚合的通信效率?
G
=
1
r
∑
i
=
1
r
m
a
x
(
t
i
j
)
,
j
=
1
,
2
,
.
.
.
,
n
G = \frac 1 r \sum_{i = 1} ^ r max(t_{ij}), j = 1, 2, ..., n
G=r1i=1∑rmax(tij),j=1,2,...,n
其中的
r
r
r表示轮数,
t
i
j
t_{ij}
tij第
i
i
i轮参数服务器从工作结点
j
j
j收到模型的时间(参数服务器从哪个结点收到模型并不确定,
t
i
j
t_{ij}
tij即表示的是第
i
i
i轮参数服务器获得模型的时间,也就是第
i
i
i轮的聚合时间)。
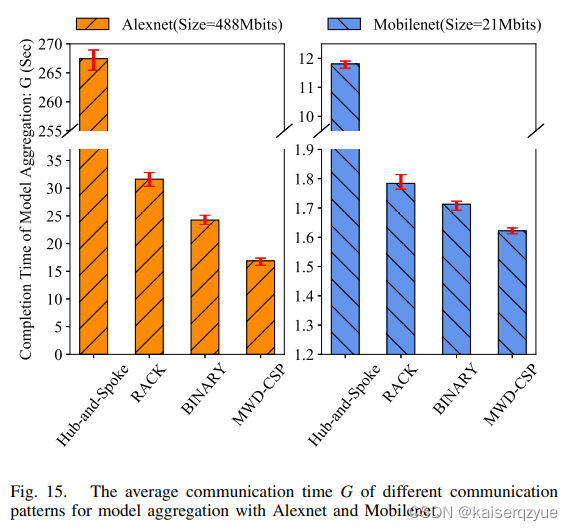
Fig. 15展示了在工作结点128的情况下各个架构的聚合时间。
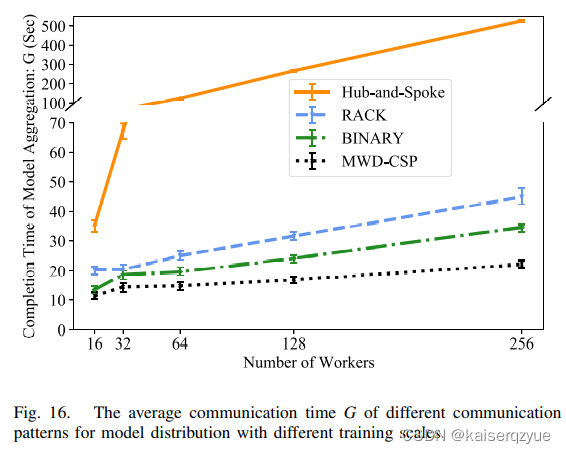
Fig. 16展示了
G
G
G随着工作结点的增多的变化。
7 Related Work
高效通信的算法:致力于实现同样的效果下,模型拥有尽可能少的参数,这样通信时间能够得到减少。
高效通信的架构:指的是在相同的模型下,使用不同架构的通信模型来达到高校通信的目的。
高效通信的网络:致力于设计应用定制化的网络(指的是不同的应用网络条件不同),通过该方式也可以提升通信效率。
8 Conclusion and Future Work
结论:TSEngine的效果超群,提升非常大,而且TSEngine的实现使得原有的代码可以直接运行只需要简单的添加一个环境变量。
未来的工作:连接失败、单点故障、伪造信息攻击等问题的解决,提升TSEngine的鲁棒性。















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









