








前言
你好,我是
GISer Liu,一名热爱AI技术的GIS开发者,上一篇文章中,作者通过QA对生成模型介绍了详细介绍了LLM微调数据的处理过程;而在本文中,作者将深入模型数据集增强以及模型自动打分功能;
一、数据增强
1. 准备工作
在开始数据准备之前,我们需要进行以下准备工作:
-
数据增强:星火大模型API 1亿Token申请
-
API调用: 基于星火Max模型的API进行代码调用测试
具体过程如下:
① Token申请
登录网址星火大模型Max api领取地址-点击跳转😃
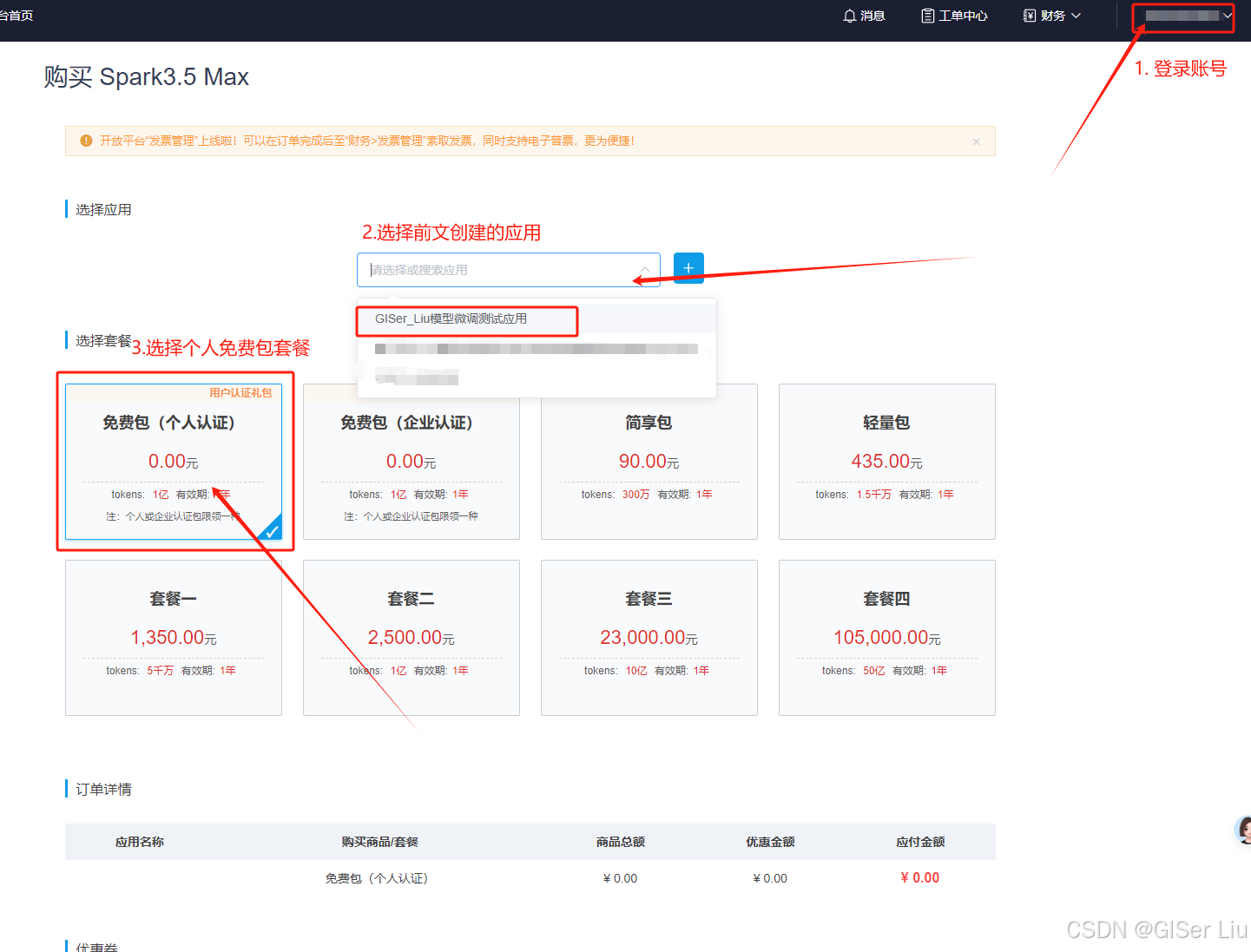
按照图上流程进行即可;
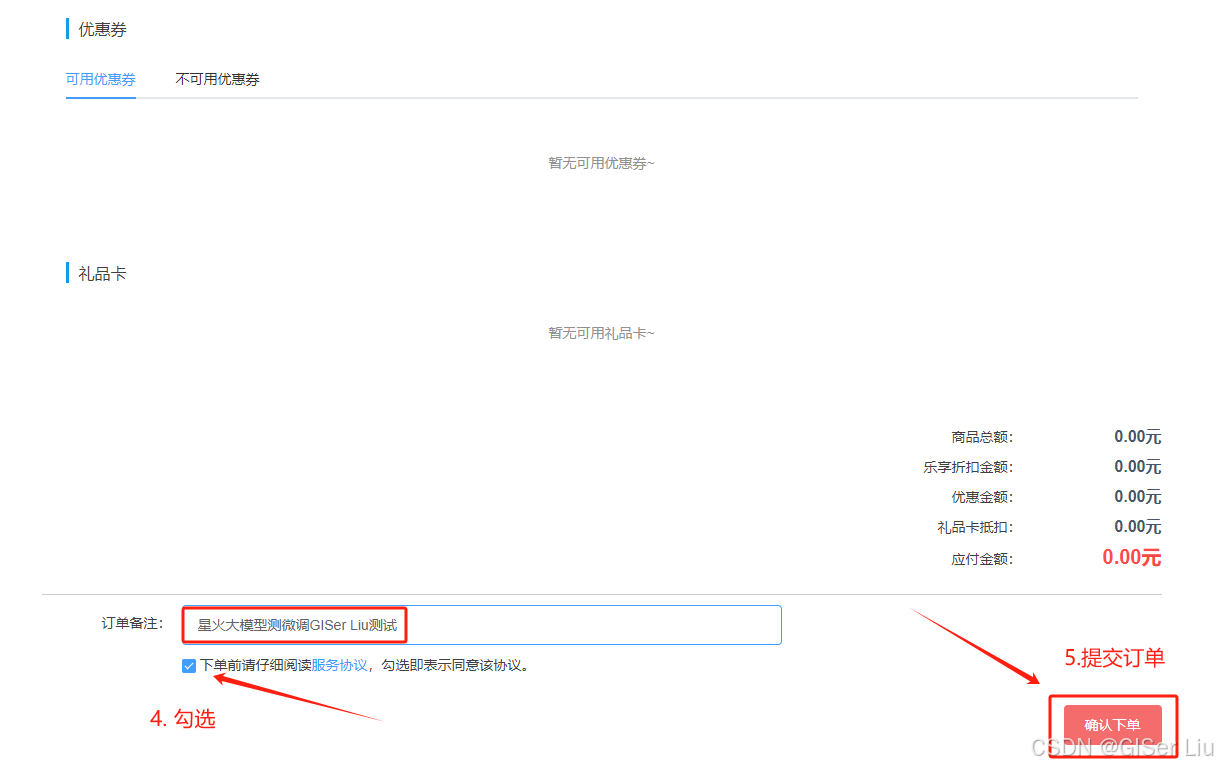
成功后可以看到如下订单:
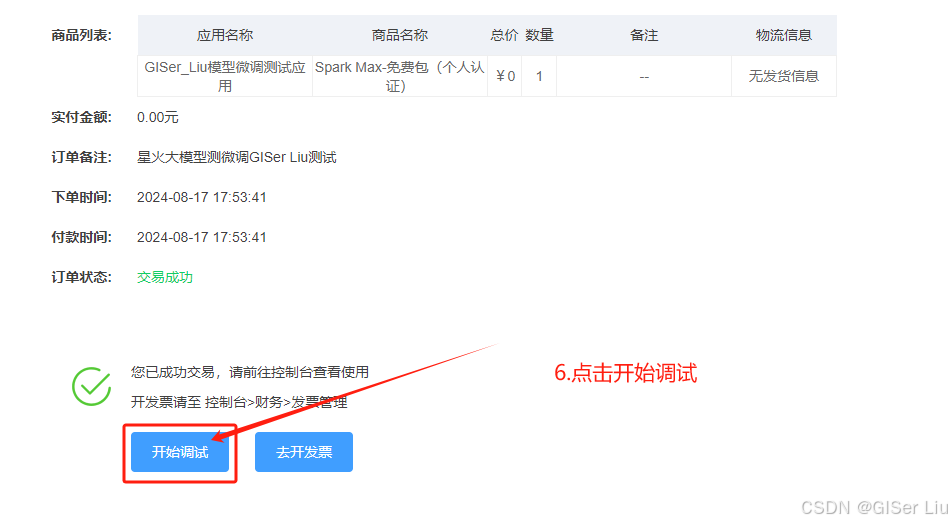
点击开始调试,进入控制台,选择Spark Max模型,并且记录接口参数信息:
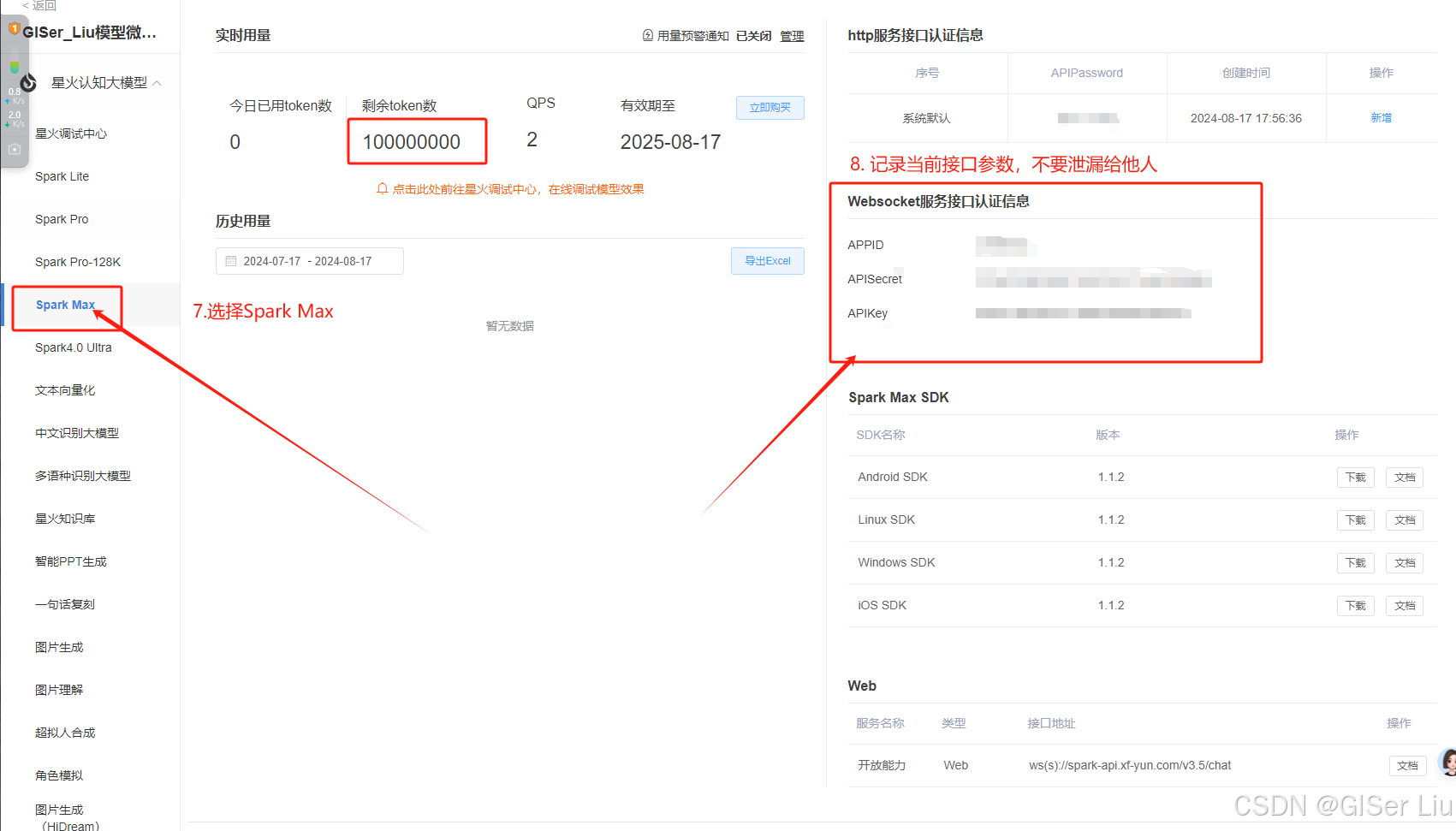
- 记录好服务参数,用于我们下一步API进行调用
- 不要将你的参数透露给他人,避免恶意调用;
② API调用
- 环境安装:首先,确保环境中安装了
spark_ai_python库:
pip install --upgrade spark_ai_python
- API调用脚本:以下是测试代码,只需填入之前保存的相应参数,运行即可:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
# 星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
# 星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
# 星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
def call_sparkai(prompt):
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content=prompt
)]
handler = ChunkPrintHandler()
response = spark.generate([messages], callbacks=[handler])
return response.generations[0][0].text
- 测试可以通过调用
call_sparkai函数来使用3.5模型:
result = call_sparkai("你对大模型微调怎么看")
print(result)
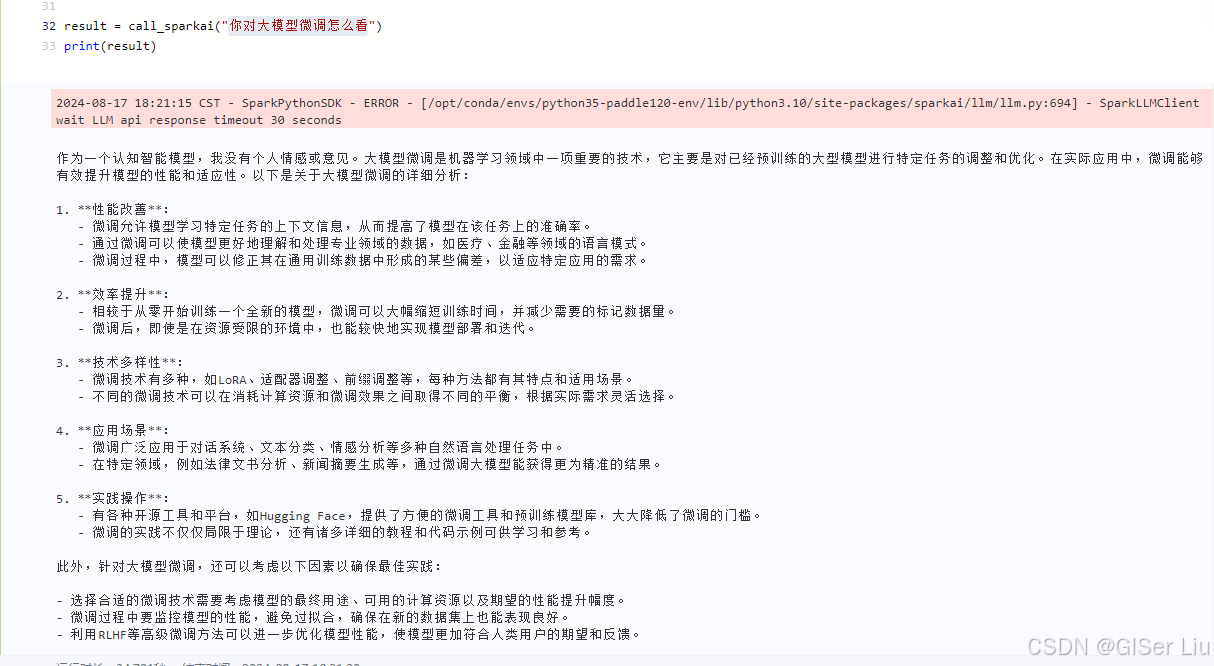
OK😁没问题!🏆🥇
- 3.5模型不仅适用于本次比赛,日常开发中也可以调用这1亿tokens进行其他开发。
- 请确保填入的
SPARKAI_APP_ID,SPARKAI_API_SECRET,SPARKAI_API_KEY等参数正确无误。
2. 数据增强思路
① 概念
数据增强是提高模型性能的重要手段之一,尤其是在数据量不足的情况下。数据增强可以通过优化现有数据或生成新的数据来实现。
在作者的上一篇文章中,我们详细了解了本次赛题数据的构成,训练数据主要由三部分构成:
- 阅读文本
- 选项
- 答案
但是我们发现比赛提供的数据存在两个问题:
-
数据量比较少
-
数据质量不佳,有些题目缺少选项和答案
这里我们就尝试使用大模型构建提示词(Prompt)工程,来生成高质量格式的训练数据,以及使用大模型来完善缺失的内容!
② 设计提示词
prompt = f'''你是一个高考英语阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
---
###阅读材料
{reading}
---
###要求
1.需要将序号对应的题目与答案做匹配。
2.匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个。
4.题目中不能出现任何不合理的词汇、语法错误。
5.如果有简答题目与答案请忽略这部分内容,只处理选择题目。
---
###输出案例
{example}
---
###题目
{question}
---
###答案
{answer}
'''
- 构建参考案例
example = '''
1. 以下哪个选项是“具身认知”的定义?
A. 认知在功能上的独立性、离身性构成了两种理论的基础。
B. 认知在很大程度上是依赖于身体的。
C. 认知的本质就是计算。
D. 认知和心智根本就不存在。
答案:B
2. 以下哪个实验支持了“具身认知”的假设?
A. 一个关于耳机舒适度的测试。
B. 一个关于眼睛疲劳程度的测试。
C. 一个关于人类感知能力的实验。
D. 一个关于人类记忆力的实验。
答案:A
3. 以下哪个选项是“离身认知”的教育观的特点?
A. 教育仅仅是心智能力的培养和训练,思维、记忆和学习等心智过程同身体无关。
B. 教育观认为身体仅仅是一个“容器”,是一个把心智带到课堂的“载体”。
C. 教育观认为知识经验的获得在很大程度上依赖于我们身体的体验性。
D. 教育观认为知识经验的获得在很大程度上依赖于我们大脑的记忆能力。
答案:A
4. 以下哪个选项是“具身认知”带来的教育理念和学习理念的变化?
A. 更强调全身心投入的主动体验式学习。
B. 更注重操作性的体验课堂,在教学过程中将学生的身体充分调动起来,这在教授抽象的概念知识时尤为重要。
C. 更强调教师的教学方法和学生的学习方法。
D. 更注重教师的教学技巧和学生的学习技巧。
答案:A'''
这里我们设计提示词对内容 进行划分,并且提供输出案例
example,为大模型提供输出案例;
这也被称做LLM的One-Shot Learning策略,具体内容可以参考本篇论文:
然后我们来设计提示词打包函数:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
# 星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
# 星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
# 星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
def get_adddata_prompt_zero(reading, cankao_content, question, answer):
prompt = f'''你是一个高考英语阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
###阅读材料
{reading}
###要求
1.需要将序号对应的题目与答案做匹配。
2.匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个。
4.题目中不能出现任何不合理的词汇、语法错误。
5.如果有简答题目与答案请忽略这部分内容,只处理选择题目。
###参考内容
{example}
###题目
{question}
###答案
{answer}
'''
return prompt
def call_sparkai(prompt):
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content=prompt
)]
handler = ChunkPrintHandler()
response = spark.generate([messages], callbacks=[handler])
return response.generations[0][0].text
- 调用代码进行测试
reading = '''
给儿子
陈村
你总会长大的,儿子,你总会进入大学,把童年撤得远远的。你会和时髦青年一样,热表于旅游。等到署假,你的第一个署假,儿子,你就去买票。火车430公里,一直坐到芜湖。你背着包爬上江堤,看力看长江。再没有比长江更亲切的河了。它宽,它长,它黄得恰如其分,不失尊严地走向东海。你走下江堤,花一毛钱去打票,坐上渡船。船上无疑会有许多人。他们挑着担子,扛着被子,或许还有板车。他们说话的声音很高,看人从来都是正视。也许会有人和你搭话,你就老老实实说话。他们没有坏意。你从跳板走上岸,顺着被鞋底和脚板踩硬踩白的大路,7走半个小时。你能看到村子了。狗总是最先跳出来的。你可以在任何一家的门口坐下,要口水喝。主人总是热情的,而狗却时刻警惕着。也许会引来它的朋友们,纷纷表示出对你的兴趣。你要沉住气。你谢过主人,再别理狗的讹诈,去河边寻找滩船。如果你运气好,船上只有一两个客,你就能躺在舱里,将头枕着船帮,河水拍击船底的声音频时变得很重。船在浆声中不紧不慢地走。双桨"吱呀吱呀"的,古人说是欸乃",也对。怎么说怎么像。板桥就在太阳落下去的地方。你沿着大埂走,右边是漕河,它连接着巢湖和长江。河滩如没被淹,一定有放牛的。你走过窑场就不远了。可以问问人,谁都愿意回答你,也许还会领你走一段,把己咄咄逼人的狗子赶开。走到你的腿有点酸了,那就差不多到了。走下大梗,沿着水渠边的路走。你走过一座小桥,只有一条石板的桥就是进村了。我曾写过它。这时,你抬起头,会发觉许多眼睛在看着你...你对他们说,你叫杨子,你是我的儿子。儿子,你得找和你父亲差不多年纪的人,他们才记得。他们会记得那五个"上海佬",记得那个戴近视眼镜的的下放学生。他们会说他的好话和坏话。不管他们说什么,你都听着,不许还嘴,他们会告诉你一些细节,比如插不齐秧,比如一口气吃了个12斤的西瓜。你跟他们一起笑吧,确实值得笑上一场。你们谈到黑了,会有人请你吃饭。不必客气,谁先请就跟谁去。能喝多少喝多少,能吃多少吃多少,这才像客人。天黑了,个他们会留你住宿。他们非常好客。儿子,你去找找那间草屋。它在村子的东头,通往晒场的路边,三面环水。你比着照片,看它还像不像当年。也许那草屋已经不在了,当年它就晃晃的,想必支撑不到你去。也许,那里又成了一片和稻田晚上,你到田间小路上走走。你边走边读"稻花香里说丰年,听取蛙声一片",感受会深深的。风吹来暖暖的热气,稻穗在风中作响。一路上,有萤火虫为你照着假如你有胆量,就到村东头的大坟茔去。多半会碰上"鬼火",也就是磷火。你别跑,你坐在坟堆上,体会一下死的庄重和兄默。地下的那些人也曾生活在这块土地上,劳动,繁殖。他们也曾理葬过他们的祖先。1你会捉摸到一点历史感的,这比任何教科书都有效。住上几天,你就熟悉村子了。男人爱理干干净净的发式,两边的头发一刀推净,这样头便显得长了。顶上则是长长的头毛,能披到眼睛,时而这么一甩,甩得很有点味道。我喜欢见他们光着上身光着脚的样子。皮肤晒成了栗色色,黑得发亮发光,连麦芒都刺不透它。他们不是生来这样的。和他们一起下河,你就知道,他们原先比你还白。现在,他们和你的祖先一样黑了。和你父亲当年一样黑。你要是下田,就和你一样黑。下田去吧,儿子。让太阳也把你烤透。你弯下腰,从清晨弯到天黑,你恨不得把腰扔了。你的肩膀不是生来只能背背书包的。你挑起担子,肩上的肌肉会在扁担下鼓起。也许会掉层皮,那不算什么。你去揍获,插秧锄草,脱粒。你会知道自己并非什么都行。你去握一握大锻,它啥时候都不会被取代。工具越原始就越扔不了,像锤子,像刀,总要的。你得认识麦子,稻子,玉米,高粱,红薯。它们也是扔不了的。你干累了,坐在门边,看着猪在四处漫游,看着鸡上房,鸭下河,鹅窜进秧田美餐一顿真。你听着杵声,感觉着太阳渐渐收起它的热力。你心平气和地想想,该说大地是仁慈的。它在无止无息地输出。我们因为这输出,7才能存活,才得以延续那一层层茅草铺就的屋顶,那一条条小河分割的田野,那土黄色的土墙,那牛,那狗。那威力无比的太阳。2你会爱的。你就这样住着,看着,干着。你去过了,你就会懂得父亲,懂得父亲笔下的漕河。当然,这实在不算什么,应当珍视的是你董了自己。3你得不让自己飘了,你得有块东西镇住自己。也许,借父亲的还不行,你得自已去找。当你离开板桥的时候,人们会送你。你是不配的,儿子。你得在晚上告别,半夜就走。夜间的漕河微微发亮,你独自在河滩坐上一会,听听它的流动。要是凑巧,你可以带条狗崽子回来。找条有主见的。开始,也许它有点想家。日子长了,你们能处好。你会发觉,为它吃点辛苦是值得的。也就是这些话了,儿子。你得去,在大学的第一个暑假就去。④我不知.道究竟会怎样。要是你的船走进漕河,看见的只是一排烟囱,一排厂房,儿子,你该替我痛哭一场才是。虽然我为乡亲们高兴。
1984. 8.5
(有删改)
'''
examlpe = '''
1. 以下哪个选项是“具身认知”的定义?
A. 认知在功能上的独立性、离身性构成了两种理论的基础。
B. 认知在很大程度上是依赖于身体的。
C. 认知的本质就是计算。
D. 认知和心智根本就不存在。
答案:B
2. 以下哪个实验支持了“具身认知”的假设?
A. 一个关于耳机舒适度的测试。
B. 一个关于眼睛疲劳程度的测试。
C. 一个关于人类感知能力的实验。
D. 一个关于人类记忆力的实验。
答案:A
3. 以下哪个选项是“离身认知”的教育观的特点?
A. 教育仅仅是心智能力的培养和训练,思维、记忆和学习等心智过程同身体无关。
B. 教育观认为身体仅仅是一个“容器”,是一个把心智带到课堂的“载体”。
C. 教育观认为知识经验的获得在很大程度上依赖于我们身体的体验性。
D. 教育观认为知识经验的获得在很大程度上依赖于我们大脑的记忆能力。
答案:A
4. 以下哪个选项是“具身认知”带来的教育理念和学习理念的变化?
A. 更强调全身心投入的主动体验式学习。
B. 更注重操作性的体验课堂,在教学过程中将学生的身体充分调动起来,这在教授抽象的概念知识时尤为重要。
C. 更强调教师的教学方法和学生的学习方法。
D. 更注重教师的教学技巧和学生的学习技巧。
答案:A
'''
question = '''
6.下列对文本相关内容的理解,不正确的一项是(3分)
A.文章开头部分,父亲想象儿子上大学后会像时髦青年一样爱
旅游,由此切人长大成人和出门旅行这两个关联话题。
B.儿子在渡船上会邂近许多陌生人,父亲教给儿子,如何通过
看他们的神情、听他们的言语来判断他们是否心存善意.
C.父亲设想儿子- -路上常会遇到狗,并建议儿子离开时带走一
条狗,可见狗应是父亲当年乡村生活中难忘的一-部分。
D.儿子的板桥之旅除了坐车乘船,还需步行走过许多路,如江
堤、大路、大埂、渠边小路、石桥等,带有较浓的寻访意味。
7.对文中画线句子的分析与鉴赏,不正确的一项是(3分)
A.句子①中“你会捉摸到”的那种“历史感”,也正是“我”当
年的经验和感悟.
B.句子②语义上与上段文字紧密相连,但单独成段,语气和表达
的感情就更强烈。
C.句子③中的“飘”,是年轻人的一种心理状态,因脱离了父辈.
压制而感到飘然自在.
D.旬子④表达出的不确定,与前文多处“你会”“你得”表现出
的笃定形成了张力。
8.“下田去吧,儿子”这个段落,写出了多重的身心感受。请加以
梳理概括。(4 分)
9.读书小组要为此文写- -则文学短评。经讨论,甲组提出一组关键
词:未来●回忆.成长;乙组提出一个关键词:河流。请任选一
个小组加人,围绕关键词写出你的短评思路。(6 分)
'''
answer ='''
6. B
7. C
8.①写出干农活的劳累和辛苦,感悟到我们有可以干很多事的潜能,人生要能承受生活之重;
②由有些农活可能干不了,体悟到我们的局限,我们并非全能:
③写出了生活中有些东西是不能丢的,需要一直传 承和延续;
④感悟生活的美好和大地的仁慈,感悟到对生活的热爱.
9.甲组答案示例:
①本文表面上是关于未来的想象,即父亲想象儿子长大后的一次旅行.
②其实是父亲对过去的回忆,
③为何交叠未来与过去?指向关于成长的主题,即父亲带儿子重温自己的成长,并期待儿子也能够在其中
找到自我。
乙组答案示例:
①文章有很多打情的意象,河流是其中最重要的一个.
②其表现就是,从爬上江堤到独坐河滩,儿子的板桥之旅始终与河流相伴.
③那么河流究竞意味着什么?河流既是环境与风景,也代表若空间的延展和时间的流逝,并承载着人的思
索。
'''
prompt = get_adddata_prompt_zero(reading, cankao_content, question, answer)
result = call_sparkai(prompt)
print(result)
经过测试,输出如下:

可以看到效果是蛮不错的😂😁;
③ 补充缺失选项及答案
由于之前生成的数据不一定满足四个选项和答案,这里我们需要将缺失的选项和答案进行补全,我们的要求如下:
- 补充缺失选项:如果选择题目不足四个,模块会根据参考内容自动生成新的选择题,确保每个问题都有四个选项。
- 格式标准化:生成的题目和选项将按照固定的格式输出,即问题、ABCD四个选项顺序、答案的结构组合。
- 题目数量保证:如果题目数量不够四个,模块会根据阅读材料及出题思路再生成题目,确保总题目达到四个。
- 语法和词汇检查:生成的题目中不会出现任何不合理的词汇或语法错误。
使用新的提示词重新进行生成测试:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
# 星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
# 星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
# 星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
def get_adddata_prompt_zero(reading, example, question, answer):
prompt = f'''你是一个高考英语阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
---
###阅读材料
{reading}
---
###要求
1.如果选择题目不足四个需要根据参考内容出选择题补充。
2.匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个,如果够四个则不做多余补充。
4.题目中不能出现任何不合理的词汇、语法错误。
5.如果有简答题目与答案请忽略这部分内容,只处理选择题。
---
###参考内容
{example}
---
###题目
{question}
---
###答案
{answer}
'''
return prompt
def call_sparkai(prompt):
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content=prompt
)]
handler = ChunkPrintHandler()
response = spark.generate([messages], callbacks=[handler])
return response.generations[0][0].text
reading = '''
给儿子
陈村
你总会长大的,儿子,你总会进入大学,把童年撤得远远的。你会和时髦青年一样,热表于旅游。等到署假,你的第一个署假,儿子,你就去买票。火车430公里,一直坐到芜湖。你背着包爬上江堤,看力看长江。再没有比长江更亲切的河了。它宽,它长,它黄得恰如其分,不失尊严地走向东海。你走下江堤,花一毛钱去打票,坐上渡船。船上无疑会有许多人。他们挑着担子,扛着被子,或许还有板车。他们说话的声音很高,看人从来都是正视。也许会有人和你搭话,你就老老实实说话。他们没有坏意。你从跳板走上岸,顺着被鞋底和脚板踩硬踩白的大路,7走半个小时。你能看到村子了。狗总是最先跳出来的。你可以在任何一家的门口坐下,要口水喝。主人总是热情的,而狗却时刻警惕着。也许会引来它的朋友们,纷纷表示出对你的兴趣。你要沉住气。你谢过主人,再别理狗的讹诈,去河边寻找滩船。如果你运气好,船上只有一两个客,你就能躺在舱里,将头枕着船帮,河水拍击船底的声音频时变得很重。船在浆声中不紧不慢地走。双桨"吱呀吱呀"的,古人说是欸乃",也对。怎么说怎么像。板桥就在太阳落下去的地方。你沿着大埂走,右边是漕河,它连接着巢湖和长江。河滩如没被淹,一定有放牛的。你走过窑场就不远了。可以问问人,谁都愿意回答你,也许还会领你走一段,把己咄咄逼人的狗子赶开。走到你的腿有点酸了,那就差不多到了。走下大梗,沿着水渠边的路走。你走过一座小桥,只有一条石板的桥就是进村了。我曾写过它。这时,你抬起头,会发觉许多眼睛在看着你...你对他们说,你叫杨子,你是我的儿子。儿子,你得找和你父亲差不多年纪的人,他们才记得。他们会记得那五个"上海佬",记得那个戴近视眼镜的的下放学生。他们会说他的好话和坏话。不管他们说什么,你都听着,不许还嘴,他们会告诉你一些细节,比如插不齐秧,比如一口气吃了个12斤的西瓜。你跟他们一起笑吧,确实值得笑上一场。你们谈到黑了,会有人请你吃饭。不必客气,谁先请就跟谁去。能喝多少喝多少,能吃多少吃多少,这才像客人。天黑了,个他们会留你住宿。他们非常好客。儿子,你去找找那间草屋。它在村子的东头,通往晒场的路边,三面环水。你比着照片,看它还像不像当年。也许那草屋已经不在了,当年它就晃晃的,想必支撑不到你去。也许,那里又成了一片和稻田晚上,你到田间小路上走走。你边走边读"稻花香里说丰年,听取蛙声一片",感受会深深的。风吹来暖暖的热气,稻穗在风中作响。一路上,有萤火虫为你照着假如你有胆量,就到村东头的大坟茔去。多半会碰上"鬼火",也就是磷火。你别跑,你坐在坟堆上,体会一下死的庄重和兄默。地下的那些人也曾生活在这块土地上,劳动,繁殖。他们也曾理葬过他们的祖先。1你会捉摸到一点历史感的,这比任何教科书都有效。住上几天,你就熟悉村子了。男人爱理干干净净的发式,两边的头发一刀推净,这样头便显得长了。顶上则是长长的头毛,能披到眼睛,时而这么一甩,甩得很有点味道。我喜欢见他们光着上身光着脚的样子。皮肤晒成了栗色色,黑得发亮发光,连麦芒都刺不透它。他们不是生来这样的。和他们一起下河,你就知道,他们原先比你还白。现在,他们和你的祖先一样黑了。和你父亲当年一样黑。你要是下田,就和你一样黑。下田去吧,儿子。让太阳也把你烤透。你弯下腰,从清晨弯到天黑,你恨不得把腰扔了。你的肩膀不是生来只能背背书包的。你挑起担子,肩上的肌肉会在扁担下鼓起。也许会掉层皮,那不算什么。你去揍获,插秧锄草,脱粒。你会知道自己并非什么都行。你去握一握大锻,它啥时候都不会被取代。工具越原始就越扔不了,像锤子,像刀,总要的。你得认识麦子,稻子,玉米,高粱,红薯。它们也是扔不了的。你干累了,坐在门边,看着猪在四处漫游,看着鸡上房,鸭下河,鹅窜进秧田美餐一顿真。你听着杵声,感觉着太阳渐渐收起它的热力。你心平气和地想想,该说大地是仁慈的。它在无止无息地输出。我们因为这输出,7才能存活,才得以延续那一层层茅草铺就的屋顶,那一条条小河分割的田野,那土黄色的土墙,那牛,那狗。那威力无比的太阳。2你会爱的。你就这样住着,看着,干着。你去过了,你就会懂得父亲,懂得父亲笔下的漕河。当然,这实在不算什么,应当珍视的是你董了自己。3你得不让自己飘了,你得有块东西镇住自己。也许,借父亲的还不行,你得自已去找。当你离开板桥的时候,人们会送你。你是不配的,儿子。你得在晚上告别,半夜就走。夜间的漕河微微发亮,你独自在河滩坐上一会,听听它的流动。要是凑巧,你可以带条狗崽子回来。找条有主见的。开始,也许它有点想家。日子长了,你们能处好。你会发觉,为它吃点辛苦是值得的。也就是这些话了,儿子。你得去,在大学的第一个暑假就去。④我不知.道究竟会怎样。要是你的船走进漕河,看见的只是一排烟囱,一排厂房,儿子,你该替我痛哭一场才是。虽然我为乡亲们高兴。
1984. 8.5
(有删改)
'''
examlpe = '''
1. 以下哪个选项是“具身认知”的定义?
A. 认知在功能上的独立性、离身性构成了两种理论的基础。
B. 认知在很大程度上是依赖于身体的。
C. 认知的本质就是计算。
D. 认知和心智根本就不存在。
答案:B
...
'''
question = '''
6.下列对文本相关内容的理解,不正确的一项是(3分)
A.文章开头部分,父亲想象儿子上大学后会像时髦青年一样爱
旅游,由此切人长大成人和出门旅行这两个关联话题。
B.儿子在渡船上会邂近许多陌生人,父亲教给儿子,如何通过
看他们的神情、听他们的言语来判断他们是否心存善意.
C.父亲设想儿子- -路上常会遇到狗,并建议儿子离开时带走一
条狗,可见狗应是父亲当年乡村生活中难忘的一-部分。
D.儿子的板桥之旅除了坐车乘船,还需步行走过许多路,如江
堤、大路、大埂、渠边小路、石桥等,带有较浓的寻访意味。
7.对文中画线句子的分析与鉴赏,不正确的一项是(3分)
A.句子①中“你会捉摸到”的那种“历史感”,也正是“我”当
年的经验和感悟.
B.句子②语义上与上段文字紧密相连,但单独成段,语气和表达
的感情就更强烈。
C.句子③中的“飘”,是年轻人的一种心理状态,因脱离了父辈.
压制而感到飘然自在.
D.旬子④表达出的不确定,与前文多处“你会”“你得”表现出
的笃定形成了张力。
8.“下田去吧,儿子”这个段落,写出了多重的身心感受。请加以
梳理概括。(4 分)
9.读书小组要为此文写- -则文学短评。经讨论,甲组提出一组关键
词:未来●回忆.成长;乙组提出一个关键词:河流。请任选一
个小组加人,围绕关键词写出你的短评思路。(6 分)
'''
answer ='''
6. B
7. C
8.①写出干农活的劳累和辛苦,感悟到我们有可以干很多事的潜能,人生要能承受生活之重;
②由有些农活可能干不了,体悟到我们的局限,我们并非全能:
③写出了生活中有些东西是不能丢的,需要一直传 承和延续;
④感悟生活的美好和大地的仁慈,感悟到对生活的热爱.
9.甲组答案示例:
①本文表面上是关于未来的想象,即父亲想象儿子长大后的一次旅行.
②其实是父亲对过去的回忆,
③为何交叠未来与过去?指向关于成长的主题,即父亲带儿子重温自己的成长,并期待儿子也能够在其中
找到自我。
乙组答案示例:
①文章有很多打情的意象,河流是其中最重要的一个.
②其表现就是,从爬上江堤到独坐河滩,儿子的板桥之旅始终与河流相伴.
③那么河流究竞意味着什么?河流既是环境与风景,也代表若空间的延展和时间的流逝,并承载着人的思
索。
'''
prompt = get_adddata_prompt_zero(reading, cankao_contentexample, question, answer)
result = call_sparkai(prompt)
print(result)
输出结果如下:

Over! 🏆问题解决~
这里作者在提示词中加入了分隔符号 — ,其可以帮助大模型在文本量较大的情况下进行内容区分,避免混淆错误;
④ 数据扩展
为了进一步提升数据集的多样性和丰富性,我们采用了基于已有阅读题目的数据扩展策略。具体来说,我们通过生成多组新的问答对(QA对)来扩充数据集,这种方法在样本量较少的情况下尤为有效。通过这种方式,我们不仅能够增加数据集的规模,还能提高模型的泛化能力,使其在面对新问题时表现更为稳健。
相关代码如下:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
# 星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
# 星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
# 星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
def get_adddata_prompt_zero(reading, example, question, answer):
prompt = f'''你是一个高考语文阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
---
###阅读材料
{reading}
---
###题目
{question}
---
###答案
{answer}
---
###要求
1.如果选择题目不足四个需要根据参考内容出选择题补充。
2.匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个,如果够四个则不做多余补充。
4.题目中不能出现任何不合理的词汇、语法错误。
5.如果有简答题目与答案请忽略这部分内容,只处理选择题。
6.生成的问题前无需增加 问题 二字,只需要增加序号。
7. 生成问题要符合高考的要求,要保证难度符合高考难度,难度足够大。
---
### 输出案例
{example}
'''
return prompt
def call_sparkai(prompt):
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content=prompt
)]
handler = ChunkPrintHandler()
response = spark.generate([messages], callbacks=[handler])
return response.generations[0][0].text
def generate_new_qa_pairs(reading, example, question, answer, num_pairs=2):
qa_pairs = []
for _ in range(num_pairs):
prompt = get_adddata_prompt_zero(reading, example, question, answer)
result = call_sparkai(prompt)
qa_pairs.append(result)
return qa_pairs
# 示例阅读材料和参考内容
reading = '''
给儿子
陈村
你总会长大的,儿子,你总会进入大学,把童年撤得远远的。你会和时髦青年一样,热表于旅游。等到署假,你的第一个署假,儿子,你就去买票。火车430公里,一直坐到芜湖。你背着包爬上江堤,看力看长江。再没有比长江更亲切的河了。它宽,它长,它黄得恰如其分,不失尊严地走向东海。你走下江堤,花一毛钱去打票,坐上渡船。船上无疑会有许多人。他们挑着担子,扛着被子,或许还有板车。他们说话的声音很高,看人从来都是正视。也许会有人和你搭话,你就老老实实说话。他们没有坏意。你从跳板走上岸,顺着被鞋底和脚板踩硬踩白的大路,7走半个小时。你能看到村子了。狗总是最先跳出来的。你可以在任何一家的门口坐下,要口水喝。主人总是热情的,而狗却时刻警惕着。也许会引来它的朋友们,纷纷表示出对你的兴趣。你要沉住气。你谢过主人,再别理狗的讹诈,去河边寻找滩船。如果你运气好,船上只有一两个客,你就能躺在舱里,将头枕着船帮,河水拍击船底的声音频时变得很重。船在浆声中不紧不慢地走。双桨"吱呀吱呀"的,古人说是欸乃",也对。怎么说怎么像。板桥就在太阳落下去的地方。你沿着大埂走,右边是漕河,它连接着巢湖和长江。河滩如没被淹,一定有放牛的。你走过窑场就不远了。可以问问人,谁都愿意回答你,也许还会领你走一段,把己咄咄逼人的狗子赶开。走到你的腿有点酸了,那就差不多到了。走下大梗,沿着水渠边的路走。你走过一座小桥,只有一条石板的桥就是进村了。我曾写过它。这时,你抬起头,会发觉许多眼睛在看着你...你对他们说,你叫杨子,你是我的儿子。儿子,你得找和你父亲差不多年纪的人,他们才记得。他们会记得那五个"上海佬",记得那个戴近视眼镜的的下放学生。他们会说他的好话和坏话。不管他们说什么,你都听着,不许还嘴,他们会告诉你一些细节,比如插不齐秧,比如一口气吃了个12斤的西瓜。你跟他们一起笑吧,确实值得笑上一场。你们谈到黑了,会有人请你吃饭。不必客气,谁先请就跟谁去。能喝多少喝多少,能吃多少吃多少,这才像客人。天黑了,个他们会留你住宿。他们非常好客。儿子,你去找找那间草屋。它在村子的东头,通往晒场的路边,三面环水。你比着照片,看它还像不像当年。也许那草屋已经不在了,当年它就晃晃的,想必支撑不到你去。也许,那里又成了一片和稻田晚上,你到田间小路上走走。你边走边读"稻花香里说丰年,听取蛙声一片",感受会深深的。风吹来暖暖的热气,稻穗在风中作响。一路上,有萤火虫为你照着假如你有胆量,就到村东头的大坟茔去。多半会碰上"鬼火",也就是磷火。你别跑,你坐在坟堆上,体会一下死的庄重和兄默。地下的那些人也曾生活在这块土地上,劳动,繁殖。他们也曾理葬过他们的祖先。1你会捉摸到一点历史感的,这比任何教科书都有效。住上几天,你就熟悉村子了。男人爱理干干净净的发式,两边的头发一刀推净,这样头便显得长了。顶上则是长长的头毛,能披到眼睛,时而这么一甩,甩得很有点味道。我喜欢见他们光着上身光着脚的样子。皮肤晒成了栗色色,黑得发亮发光,连麦芒都刺不透它。他们不是生来这样的。和他们一起下河,你就知道,他们原先比你还白。现在,他们和你的祖先一样黑了。和你父亲当年一样黑。你要是下田,就和你一样黑。下田去吧,儿子。让太阳也把你烤透。你弯下腰,从清晨弯到天黑,你恨不得把腰扔了。你的肩膀不是生来只能背背书包的。你挑起担子,肩上的肌肉会在扁担下鼓起。也许会掉层皮,那不算什么。你去揍获,插秧锄草,脱粒。你会知道自己并非什么都行。你去握一握大锻,它啥时候都不会被取代。工具越原始就越扔不了,像锤子,像刀,总要的。你得认识麦子,稻子,玉米,高粱,红薯。它们也是扔不了的。你干累了,坐在门边,看着猪在四处漫游,看着鸡上房,鸭下河,鹅窜进秧田美餐一顿真。你听着杵声,感觉着太阳渐渐收起它的热力。你心平气和地想想,该说大地是仁慈的。它在无止无息地输出。我们因为这输出,7才能存活,才得以延续那一层层茅草铺就的屋顶,那一条条小河分割的田野,那土黄色的土墙,那牛,那狗。那威力无比的太阳。2你会爱的。你就这样住着,看着,干着。你去过了,你就会懂得父亲,懂得父亲笔下的漕河。当然,这实在不算什么,应当珍视的是你董了自己。3你得不让自己飘了,你得有块东西镇住自己。也许,借父亲的还不行,你得自已去找。当你离开板桥的时候,人们会送你。你是不配的,儿子。你得在晚上告别,半夜就走。夜间的漕河微微发亮,你独自在河滩坐上一会,听听它的流动。要是凑巧,你可以带条狗崽子回来。找条有主见的。开始,也许它有点想家。日子长了,你们能处好。你会发觉,为它吃点辛苦是值得的。也就是这些话了,儿子。你得去,在大学的第一个暑假就去。④我不知.道究竟会怎样。要是你的船走进漕河,看见的只是一排烟囱,一排厂房,儿子,你该替我痛哭一场才是。虽然我为乡亲们高兴。
1984. 8.5
(有删改)
'''
example = '''
1. 在文中,老董为什么不同意将古籍的书皮整体替换?
A. 他认为自己有责任保留书籍的原始状态。
B. 他认为只有通过传统工艺才能修复这本书。
C. 他认为专家们的提议太昂贵。
D. 他想证明自己的修复技术比现代技术更优。
答案:B
2. 老董用什么方法成功染出了接近原书皮颜色的蓝绢?
A. 使用了一种失传的传统染蓝工艺。
B. 用现代科技合成了颜色。
C. 从市场上购买了现成的蓝色染料。
D. 通过多次实验调配出合适的颜色。
答案:A
3. 老董和作者去捡橡碗的目的是什么?
A. 制作天然的染料用于修复古书。
B. 作为中秋节的一种传统活动。
C. 为了研究橡树的生长环境。
D. 作为一种休闲娱乐活动。
答案:A
4. 关于老董修复雍正国子监刊本《论语》的结果,以下哪个描述是正确的?
A. 老董最终没有完成修复工作。
B. 修复后的书籍与原书皮相似度达到近90%。
C. 修复工作引起了负面反响。
D. 老董因此离开了修书行业。
答案:B
'''
question = '''
6.下列对文本相关内容的理解,不正确的一项是(3分)
A.文章开头部分,父亲想象儿子上大学后会像时髦青年一样爱
旅游,由此切人长大成人和出门旅行这两个关联话题。
B.儿子在渡船上会邂近许多陌生人,父亲教给儿子,如何通过
看他们的神情、听他们的言语来判断他们是否心存善意.
C.父亲设想儿子- -路上常会遇到狗,并建议儿子离开时带走一
条狗,可见狗应是父亲当年乡村生活中难忘的一-部分。
D.儿子的板桥之旅除了坐车乘船,还需步行走过许多路,如江
堤、大路、大埂、渠边小路、石桥等,带有较浓的寻访意味。
7.对文中画线句子的分析与鉴赏,不正确的一项是(3分)
A.句子①中“你会捉摸到”的那种“历史感”,也正是“我”当
年的经验和感悟.
B.句子②语义上与上段文字紧密相连,但单独成段,语气和表达
的感情就更强烈。
C.句子③中的“飘”,是年轻人的一种心理状态,因脱离了父辈.
压制而感到飘然自在.
D.旬子④表达出的不确定,与前文多处“你会”“你得”表现出
的笃定形成了张力。
8.“下田去吧,儿子”这个段落,写出了多重的身心感受。请加以
梳理概括。(4 分)
9.读书小组要为此文写- -则文学短评。经讨论,甲组提出一组关键
词:未来●回忆.成长;乙组提出一个关键词:河流。请任选一
个小组加人,围绕关键词写出你的短评思路。(6 分)
'''
answer ='''
6. B
7. C
8.①写出干农活的劳累和辛苦,感悟到我们有可以干很多事的潜能,人生要能承受生活之重;
②由有些农活可能干不了,体悟到我们的局限,我们并非全能:
③写出了生活中有些东西是不能丢的,需要一直传 承和延续;
④感悟生活的美好和大地的仁慈,感悟到对生活的热爱.
9.甲组答案示例:
①本文表面上是关于未来的想象,即父亲想象儿子长大后的一次旅行.
②其实是父亲对过去的回忆,
③为何交叠未来与过去?指向关于成长的主题,即父亲带儿子重温自己的成长,并期待儿子也能够在其中
找到自我。
乙组答案示例:
①文章有很多打情的意象,河流是其中最重要的一个.
②其表现就是,从爬上江堤到独坐河滩,儿子的板桥之旅始终与河流相伴.
③那么河流究竞意味着什么?河流既是环境与风景,也代表若空间的延展和时间的流逝,并承载着人的思
索。
'''
# 生成新的QA对
new_qa_pairs = generate_new_qa_pairs(reading, example, question, answer,num_pairs=2)
for idx, qa_pair in enumerate(new_qa_pairs):
print(f"QA Pair {idx + 1}:\n{qa_pair}\n")
输出如下:

这里我们可以对一个案例进行两次扩展;从而扩展数据集规模;
二、模型评分
1. 模型评分概念
模型评分模块是基于人工智能技术,特别是大型语言模型(LLMs),开发的一种自动化评分系统。该系统旨在解决传统人工评分中存在的一些痛点,并提供更高效、一致和客观的评分方法。通过集成这一模块,我们能够显著提升评分效率,同时确保评分的准确性和公平性。
2. 人工评分与模型评分的优缺点对比
| 特点 | 人工评分 | 模型评分 |
|---|---|---|
| 灵活性 | 能够根据具体情况灵活调整评分标准 | 难以适应评分标准的变化或新需求 |
| 理解深度 | 能够理解文本的深层含义和情感 | 可能无法完全理解文本的深层含义 |
| 人际互动 | 能够提供额外的指导和建议 | 无法提供人类评分者的额外指导 |
| 一致性 | 不同评分者可能评分不一致 | 通过训练确保评分的一致性 |
| 效率 | 耗时且需要大量人力资源 | 能快速处理大量数据,提高效率 |
| 客观性 | 易受主观性和偏见影响 | 减少人类主观性和偏见,促进公平 |
| 反馈细致性 | 难以提供针对绩效特定方面的反馈 | 提供针对绩效各方面的详细反馈 |
| 数据依赖性 | 评分效果依赖于训练数据的质量 |
3. 设计思路
我们的思路是基于LLM构建提示词工程,为LLM增加评分人设,并设定评分标准,来对生成的结果进行打分;下面是我们整理的打分标准:
① 评分标准
首先满足题目数量及含有对应答案。
接着对给出的答案匹配情况做打分设定。
对选项和文章匹配程度做打分设定。
对选项和高考考试要求做打分设定。
对输出情况做设定。
② 代码实现
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
# 星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
# 星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
# 星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
reading = '''
给儿子
陈村
你总会长大的,儿子,你总会进入大学,把童年撤得远远的。你会和时髦青年一样,热表于旅游。等到署假,你的第一个署假,儿子,你就去买票。火车430公里,一直坐到芜湖。你背着包爬上江堤,看力看长江。再没有比长江更亲切的河了。它宽,它长,它黄得恰如其分,不失尊严地走向东海。你走下江堤,花一毛钱去打票,坐上渡船。船上无疑会有许多人。他们挑着担子,扛着被子,或许还有板车。他们说话的声音很高,看人从来都是正视。也许会有人和你搭话,你就老老实实说话。他们没有坏意。你从跳板走上岸,顺着被鞋底和脚板踩硬踩白的大路,7走半个小时。你能看到村子了。狗总是最先跳出来的。你可以在任何一家的门口坐下,要口水喝。主人总是热情的,而狗却时刻警惕着。也许会引来它的朋友们,纷纷表示出对你的兴趣。你要沉住气。你谢过主人,再别理狗的讹诈,去河边寻找滩船。如果你运气好,船上只有一两个客,你就能躺在舱里,将头枕着船帮,河水拍击船底的声音频时变得很重。船在浆声中不紧不慢地走。双桨"吱呀吱呀"的,古人说是欸乃",也对。怎么说怎么像。板桥就在太阳落下去的地方。你沿着大埂走,右边是漕河,它连接着巢湖和长江。河滩如没被淹,一定有放牛的。你走过窑场就不远了。可以问问人,谁都愿意回答你,也许还会领你走一段,把己咄咄逼人的狗子赶开。走到你的腿有点酸了,那就差不多到了。走下大梗,沿着水渠边的路走。你走过一座小桥,只有一条石板的桥就是进村了。我曾写过它。这时,你抬起头,会发觉许多眼睛在看着你...你对他们说,你叫杨子,你是我的儿子。儿子,你得找和你父亲差不多年纪的人,他们才记得。他们会记得那五个"上海佬",记得那个戴近视眼镜的的下放学生。他们会说他的好话和坏话。不管他们说什么,你都听着,不许还嘴,他们会告诉你一些细节,比如插不齐秧,比如一口气吃了个12斤的西瓜。你跟他们一起笑吧,确实值得笑上一场。你们谈到黑了,会有人请你吃饭。不必客气,谁先请就跟谁去。能喝多少喝多少,能吃多少吃多少,这才像客人。天黑了,个他们会留你住宿。他们非常好客。儿子,你去找找那间草屋。它在村子的东头,通往晒场的路边,三面环水。你比着照片,看它还像不像当年。也许那草屋已经不在了,当年它就晃晃的,想必支撑不到你去。也许,那里又成了一片和稻田晚上,你到田间小路上走走。你边走边读"稻花香里说丰年,听取蛙声一片",感受会深深的。风吹来暖暖的热气,稻穗在风中作响。一路上,有萤火虫为你照着假如你有胆量,就到村东头的大坟茔去。多半会碰上"鬼火",也就是磷火。你别跑,你坐在坟堆上,体会一下死的庄重和兄默。地下的那些人也曾生活在这块土地上,劳动,繁殖。他们也曾理葬过他们的祖先。1你会捉摸到一点历史感的,这比任何教科书都有效。住上几天,你就熟悉村子了。男人爱理干干净净的发式,两边的头发一刀推净,这样头便显得长了。顶上则是长长的头毛,能披到眼睛,时而这么一甩,甩得很有点味道。我喜欢见他们光着上身光着脚的样子。皮肤晒成了栗色色,黑得发亮发光,连麦芒都刺不透它。他们不是生来这样的。和他们一起下河,你就知道,他们原先比你还白。现在,他们和你的祖先一样黑了。和你父亲当年一样黑。你要是下田,就和你一样黑。下田去吧,儿子。让太阳也把你烤透。你弯下腰,从清晨弯到天黑,你恨不得把腰扔了。你的肩膀不是生来只能背背书包的。你挑起担子,肩上的肌肉会在扁担下鼓起。也许会掉层皮,那不算什么。你去揍获,插秧锄草,脱粒。你会知道自己并非什么都行。你去握一握大锻,它啥时候都不会被取代。工具越原始就越扔不了,像锤子,像刀,总要的。你得认识麦子,稻子,玉米,高粱,红薯。它们也是扔不了的。你干累了,坐在门边,看着猪在四处漫游,看着鸡上房,鸭下河,鹅窜进秧田美餐一顿真。你听着杵声,感觉着太阳渐渐收起它的热力。你心平气和地想想,该说大地是仁慈的。它在无止无息地输出。我们因为这输出,7才能存活,才得以延续那一层层茅草铺就的屋顶,那一条条小河分割的田野,那土黄色的土墙,那牛,那狗。那威力无比的太阳。2你会爱的。你就这样住着,看着,干着。你去过了,你就会懂得父亲,懂得父亲笔下的漕河。当然,这实在不算什么,应当珍视的是你董了自己。3你得不让自己飘了,你得有块东西镇住自己。也许,借父亲的还不行,你得自已去找。当你离开板桥的时候,人们会送你。你是不配的,儿子。你得在晚上告别,半夜就走。夜间的漕河微微发亮,你独自在河滩坐上一会,听听它的流动。要是凑巧,你可以带条狗崽子回来。找条有主见的。开始,也许它有点想家。日子长了,你们能处好。你会发觉,为它吃点辛苦是值得的。也就是这些话了,儿子。你得去,在大学的第一个暑假就去。④我不知.道究竟会怎样。要是你的船走进漕河,看见的只是一排烟囱,一排厂房,儿子,你该替我痛哭一场才是。虽然我为乡亲们高兴。
1984. 8.5
(有删改)
'''
QA = '''
1. 在文中,作者建议儿子去板桥的原因是什么?
A. 因为那里有美丽的风景。
B. 因为那里是父亲过去生活过的地方。
C. 因为那里有很多时尚的青年。
D. 因为那里可以体验到真正的农村生活。
答案:B
2. 根据文本,以下哪项不是作者期望儿子在旅行中体验的活动?
A. 和当地人一起吃饭。
B. 独自坐在河滩上听河水流动。
C. 在田里干活,感受劳动的辛苦。
D. 参加当地的节日庆典。
答案:D
3. 文中提到“你得让自己不飘了”,这句话的含义是什么?
A. 需要保持身体上的稳定。
B. 需要保持心理上的稳重。
C. 需要避免过度消费。
D. 需要保持与家人的联系。
答案:B
4. 关于作者对河流的描述,以下哪个选项是正确的?
A. 河流仅是旅途中的一个自然景观。
B. 河流象征着生活的连续性和变迁。
C. 河流代表了年轻人的浮躁和不定。
D. 河流暗示着未来的不确定性。
答案:B
'''
judgement = f'''
你是一个高考阅读题目出题专家,你需要根据下面要求结合阅读文章对题目及答案这样的出题情况进行打分,根据要求一步一步打分,得到有效分数后你将得到100万元的报酬,给出最终得分情况,以“总分:XX分”的形式返回。
### 阅读文章
{reading}
### 题目及答案
{QA}
### 要求
1. 判断给出的题目及答案,题目是否为四道,如果不满足四道,少一道题扣10分,如果每个题目没有答案,少一个答案扣5分。
1. 给出题目选项与答案匹配正确度给分,通过阅读文章每分析道题目正确,则给5分,如果错误给0分。四道题满分20分。
2. 给出题目与选项在阅读文章中的匹配程度给分,每道题目符合阅读文章且选择答案复合题目并可用通过阅读文章分析得到,完全符合给3分,完全不符合给0分。四道题满分12分。
3. 给出题目与选项是否符合高考难度,每道题目与答案是否符合高考的难度,完全符合给3分,完全不符合给0分。四道题满分12分。
4. 给出最终得分情况,对上面三个分数进行求和得到总分,以“总分:XX分”的形式返回,三个问题满分共44分。
'''
def call_sparkai(prompt):
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content=prompt
)]
handler = ChunkPrintHandler()
response = spark.generate([messages], callbacks=[handler])
return response.generations[0][0].text
score = call_sparkai(judgement)
score
打分如下:

看起来挺高,这说明我们前面生成的结果很不错,这可以帮助各位开发者对自己模型的测评做一个快速的打分;
如果想要提取分数,也可以补充下面代码:
import re
text= score.replace(' ', '')
# 使用正则表达式匹配阅读文本后的内容
match = re.search(r'总分:(\d+)分', text)
if match:
content = match.group(1)
print(int(content))
else:
print("未找到匹配的内容")
42
三、完整代码
现在我们将上述的所有代码进行打包,基于之前文章的代码构建数据集;这里废话不多数,代码如下:
import pandas as pd
import re
import json
from openai import OpenAI
Deepseek_API_KEY = ''
# 通用函数:删除空格和换行符
def remove_whitespace_and_newlines(input_string):
result = input_string.replace(" ", "").replace("\n", "").replace(".", "")
return result
# 通用函数:提取答案
def get_answers(text):
text = remove_whitespace_and_newlines(text)
pattern = re.compile(r'(\d)\s*([A-D])')
matches = pattern.findall(text)
res = []
for match in matches:
number_dot, first_letter = match
res.append(first_letter)
return res
# 通用函数:提取问题和选项
def get_questions(text):
text = text.replace('\n', ' ') + ' '
pattern = re.compile(r'(\d+\..*?)(A\..*?\s{2})([B-D]\..*?\s{2})([B-D]\..*?\s{2})(D\..*?\s{2})', re.DOTALL)
matches = pattern.findall(text)
questions_dict_list = []
for match in matches:
question, option1, option2, option3, option4 = match
pattern_question = re.compile(r'(\d+)\.(.*)')
question_text = pattern_question.findall(question.strip())[0][1]
options = {option1[0]: option1, option2[0]: option2, option3[0]: option3, option4[0]: option4}
question_dict = {
'question': question_text,
'options': {
'A': options.get('A', '').strip(),
'B': options.get('B', '').strip(),
'C': options.get('C', '').strip(),
'D': options.get('D', '').strip()
}
}
questions_dict_list.append(question_dict)
return questions_dict_list
# 生成英文提示文本
def get_prompt_en(text):
prompt = f'''
你是⼀个⾼考选择题出题专家,你出的题有⼀定深度,你将根据阅读文本,出4道单项选择题,包含题目选项,以及对应的答案,注意:不⽤给出原文,每道题由1个问题和4个选项组成,仅存在1个正确答案,请严格按照要求执行。
The reading text is mainly in English. The questions and answers you raised need to be completed in English for at least the following points:
### 回答要求
(1)Understanding the main idea of the main idea.
(2)Understand the specific information in the text.
(3)infering the meaning of words and phrases from the context
### 阅读文本
{text}
'''
return prompt
# 生成中文提示文本
def get_prompt_cn(text):
prompt = f'''
你是⼀个⾼考选择题出题专家,你出的题有⼀定深度,你将根据阅读文本,出4道单项选择题,包含题目选项,以及对应的答案,注意:不⽤给出原文,每道题由1个问题和4个选项组成,仅存在1个正确答案,请严格按照要求执行。
The reading text is mainly in Chinese. The questions and answers you raised need to be completed in Chinese for at least the following points:
### 回答要求
(1)理解文章的主要意思。
(2)理解文章中的具体信息。
(3)根据上下文推断词语和短语的含义。
### 阅读文本
{text}
'''
return prompt
# 补全数据的提示模板
def get_adddata_prompt(reading, example, question, answer):
prompt = f'''你是一个高考选择题出题专家,请阅读材料,参考以下内容,将题目、选项、答案补充完整。
---
###阅读材料
{reading}
---
###参考内容
{example}
---
###题目
{question}
---
###答案
{answer}
---
###要求
1. 如果选择题目不足四个需要根据参考内容出选择题补充。
2. 匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3. 如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个,如果够四个则不做多余补充。
4. 题目中不能出现任何不合理的词汇、语法错误。
5. 如果有简答题目与答案请忽略这部分内容,只处理选择题。
6. 生成的问题前无需增加"问题"二字,只需要增加序号。
7. 生成问题要符合高考的要求,要保证难度符合高考难度,难度足够大。
'''
return prompt
# 扩展数据的提示模板
def get_expanddata_prompt(reading, example, question, answer):
prompt = f'''你是一个高考选择题出题专家,请阅读材料,参考以下内容,扩展出新的题目和答案。
---
###阅读材料
{reading}
---
###参考内容
{example}
---
###题目
{question}
---
###答案
{answer}
---
###要求
1. 根据参考内容生成新的选择题,确保每道题目有4个选项。
2. 匹配后格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3. 总题目数量达到四个,请根据阅读材料及出题思路生成新题目,确保题目难度符合高考要求。
4. 题目中不能出现任何不合理的词汇、语法错误。
5. 生成的问题前无需增加"问题"二字,只需要增加序号。
6. 生成的问题要符合高考的要求,要保证难度符合高考难度,难度足够大。
7. 扩展的题目不能有分数
'''
return prompt
# 调用星火认知大模型进行生成
def call_sparkai(prompt):
client = OpenAI(api_key=Deepseek_API_KEY, base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
res = response.choices[0].message.content
return res
# 处理数据集:数据补全
def complete_data(df, get_prompt, example, num_pairs=2):
res_input = []
res_output = []
for id in range(len(df)):
data_options = df.loc[id, '选项']
data_answers = df.loc[id, '答案']
data_prompt = df.loc[id, '阅读文本']
data_options = get_questions(data_options)
data_answers = get_answers(data_answers)
data_prompt = get_prompt(data_prompt)
if len(data_answers) < 4 or len(data_options) < 4:
prompt = get_adddata_prompt(df.loc[id, '阅读文本'], example, data_options, data_answers)
completion = call_sparkai(prompt)
print(prompt,'\n',completion)
# 假设大模型返回的结果结构正确
res_output.append(completion)
res_input.append(data_prompt)
else:
res = ''
for id, question in enumerate(data_options):
res += f'''
{id+1}.{question['question']}
{question['options']['A']}
{question['options']['B']}
{question['options']['C']}
{question['options']['D']}
answer:{data_answers[id]}
''' + '\n'
res_output.append(res)
res_input.append(data_prompt)
return res_input, res_output
# 处理数据集:数据扩展
# 扩展数据集:为每个条目生成更多数据
def expand_data(df, get_prompt, example, num_expansions=2):
res_input = []
res_output = []
for id in range(len(df)):
reading_text = df.loc[id, '阅读文本']
original_prompt = get_prompt(reading_text)
original_output = {
'选项': df.loc[id, '选项'],
'答案': df.loc[id, '答案']
}
# 将原始数据添加到扩展数据集中
res_input.append(original_prompt)
res_output.append(original_output)
# 生成扩展数据
for _ in range(num_expansions):
prompt = get_expanddata_prompt(reading_text, example,df.loc[id, '选项'],df.loc[id, '答案'])
expanded_output = call_sparkai(prompt)
print(prompt,expanded_output)
res_input.append(prompt)
res_output.append(expanded_output)
return res_input,res_output
example_cn = '''
1. 以下哪个选项是“具身认知”的定义?
A. 认知在功能上的独立性、离身性构成了两种理论的基础。
B. 认知在很大程度上是依赖于身体的。
C. 认知的本质就是计算。
D. 认知和心智根本就不存在。
答案:B
2. 以下哪个实验支持了“具身认知”的假设?
A. 一个关于耳机舒适度的测试。
B. 一个关于眼睛疲劳程度的测试。
C. 一个关于人类感知能力的实验。
D. 一个关于人类记忆力的实验。
答案:A
3 以下哪个选项是“具身认知”带来的教育理念和学习理念的变化?
A. 更强调全身心投入的主动体验式学习。
B. 更注重操作性的体验课堂,在教学过程中将学生的身体充分调动起来,这在教授抽象的概念知识时尤为重要。
C. 更强调教师的教学方法和学生的学习方法。
D. 更注重教师的教学技巧和学生的学习技巧。
答案:A
4. 以下哪个选项是“离身认知”的教育观的特点?
A. 教育仅仅是心智能力的培养和训练,思维、记忆和学习等心智过程同身体无关。
B. 教育观认为身体仅仅是一个“容器”,是一个把心智带到课堂的“载体”。
C. 教育观认为知识经验的获得在很大程度上依赖于我们身体的体验性。
D. 教育观认为知识经验的获得在很大程度上依赖于我们大脑的记忆能力。
答案:A
'''
example_en = '''
1. What is the definition of "embodied cognition"?
A. Cognition is functionally independent and disembodied, forming the basis of two theories.
B. Cognition is largely dependent on the body.
C. The essence of cognition is computation.
D. Cognition and mind do not exist.
Answer: B
2. Which experiment supports the hypothesis of "embodied cognition"?
A. A test on headphone comfort.
B. A test on eye fatigue.
C. An experiment on human perception.
D. An experiment on human memory.
Answer: A
3. What is a characteristic of the educational view of "disembodied cognition"?
A. Education is merely the cultivation and training of mental abilities, with mental processes such as thinking, memory, and learning being unrelated to the body.
B. The educational view considers the body merely a "container," a "carrier" that brings the mind to the classroom.
C. The educational view believes that the acquisition of knowledge and experience largely depends on our bodily experiences.
D. The educational view believes that the acquisition of knowledge and experience largely depends on our brain's memory capacity.
Answer: A
4. What change does "embodied cognition" bring to educational and learning philosophies?
A. Emphasizes active, immersive experiential learning.
B. Focuses on operational experiential classrooms, fully engaging students' bodies in the teaching process, which is especially important when teaching abstract conceptual knowledge.
C. Emphasizes the teaching methods of teachers and the learning methods of students.
D. Focuses on the teaching techniques of teachers and the learning techniques of students.
Answer: A
'''
# 示例运行
if __name__ == "__main__":
# 读取中文数据集
df_chinese = pd.read_excel('训练集-语文.xlsx')
df_chinese = df_chinese.replace('.', '.', regex=True)
df_chinese = df_chinese.replace('(', '(', regex=True)
# 读取英文数据集
df_english = pd.read_excel('训练集-英语.xlsx')
df_english = df_english.replace('.', '.', regex=True)
df_english = df_english.replace('(', '(', regex=True)
# 补全中文数据集
res_input_cn, res_output_cn = complete_data(df_chinese, get_prompt_cn, example_cn)
# 扩展中文数据集
res_input_cn_exp, res_output_cn_exp = expand_data(df_chinese, get_prompt_cn, example_cn)
# 补全英文数据集
res_input_en, res_output_en = complete_data(df_english, get_prompt_en, example_en)
# 扩展英文数据集
res_input_en_exp, res_output_en_exp = expand_data(df_english, get_prompt_en, example_en)
# 合并中英文数据集
all_input = res_input_cn + res_input_cn_exp + res_input_en + res_input_en_exp
all_output = res_output_cn + res_output_cn_exp + res_output_en + res_output_en_exp
# 合并中英文数据集
df_new = pd.DataFrame({'input': all_input, 'output': all_output})
# 打开一个文件用于写入 JSONL,并设置编码为 UTF-8
with open('output.jsonl', 'w', encoding='utf-8') as f:
# 遍历每一行并将其转换为 JSON
for index, row in df_new.iterrows():
row_dict = row.to_dict()
row_json = json.dumps(row_dict, ensure_ascii=False,)
# 将 JSON 字符串写入文件,并添加换行符
f.write(row_json + '\n')
# 打印确认信息
print("JSONL 文件已生成")
这里因为星火大模型的审核机制判断到数据集可能存在违禁词,不能正常生成;作者改用了Deepseek进行生成,两者思路是一致的;
到此,本文内容结束!希望作者的文章对各位读者学习大模型微调有帮助!😀
参考链接

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











