






一、简介
朴素贝叶斯是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立,即给定目标值时,一个特征出现的概率不影响其他特征的出现概率。这种算法通过计算每个类别的后验概率来预测新数据点的类别。具体来说,朴素贝叶斯首先计算每个类别的先验概率,然后对每个类别,计算给定特征值的条件概率,并将这些概率相乘。最后,选择具有最高后验概率的类别作为预测结果。朴素贝叶斯算法简单、易于实现,且在处理大量特征的数据集时表现良好,尤其适用于文本分类等任务。
朴素贝叶斯分类器的基本步骤如下:
-
数据预处理:对输入数据进行清洗、转换和归一化等操作。
-
特征选择:选择与分类目标相关的特征。
-
计算先验概率:统计训练集中各个类别出现的概率。
-
计算条件概率:对于每个特征,计算在给定类别的条件下该特征的概率。
-
应用贝叶斯定理:通过乘积法则计算给定特征的条件下各类别的概率。
-
分类决策:选择概率最大的类别作为分类结果。
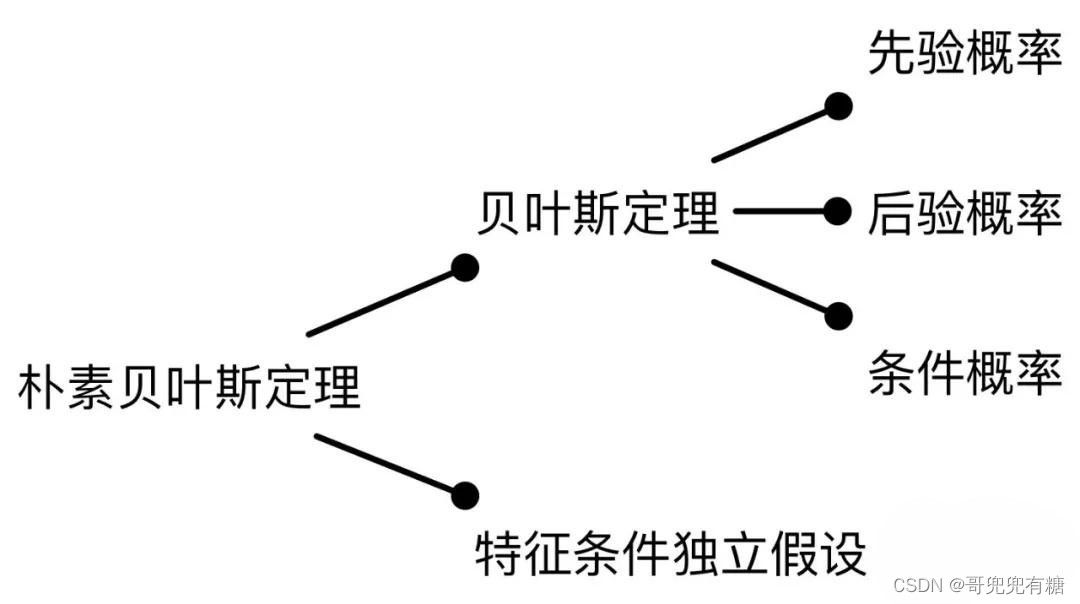
二、贝叶斯定理
要想学习朴素贝叶斯分类器,要先搞懂贝叶斯定理,贝叶斯定理是概率论中一个重要的定理,用于根据已知的条件概率来计算逆条件概率。
贝叶斯定理可以用以下公式表示:
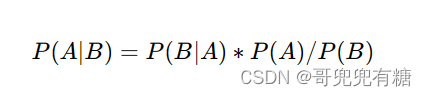
其中,P(A|B)表示事件A在事件B发生的条件下发生的概率,P(B|A)表示事件B在事件A发生的条件下发生的概率,P(A)和P(B)分别表示事件A和事件B发生的概率。
贝叶斯定理的应用范围非常广泛,包括机器学习、数据分析、模式识别等领域。它可以用于根据已知的先验概率和观测数据来更新概率的估计。
贝叶斯定理的核心思想是通过先验概率和观测数据的关系,来计算后验概率。先验概率是在没有观测数据的情况下对事件发生概率的估计,而后验概率是在观测到数据之后对事件发生概率的修正。
贝叶斯定理的应用可以帮助我们在面对不完全信息和不确定性的情况下,通过观测数据来更新和修正我们的概率估计,从而做出更准确的推断和决策。
三、代码实现
这个例子使用sklearn库中的load_iris数据集作为示例数据。对数据集进行分割,80%为训练集,20%为测试集。然后创建一个GaussianNB的朴素贝叶斯分类器,并对训练集进行训练。最后使用训练好的模型预测测试集,并计算准确率。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建朴素贝叶斯分类器
clf = GaussianNB()
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率: {:.2f}".format(accuracy))



















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











