







梯度下降
为什么需要引入梯度下降?
通过之前通过线性回归已经求出了目标函数(现在需要使得目标函数越小越好)这里又求解过程,总之现在目标函数长这个样子:
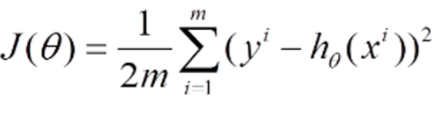
1. 为什么要除了m这个样本总数呢?
因为假设10万份样本和5万份样本,显而易见10万份的样本损失一定更大,而在这里我们是为了得到一个与样本数量无关的泛值。
2. 那么为什么要引入梯度下降呢?直接求偏导数找到极值点不就可以了吗?
因为求偏导的过程有很多要求,比如再求导过程中假设了X矩阵是可逆的,所以通常并不能直接求出极值点
通过梯度下降如何求求解?
首先要了解何为梯度下降,想象有这样一个山谷。
如何能到底山谷的最低点?
办法就是每时每刻都沿着当前最陡的方向前进,但是我们又无法真正的保证每时每刻因此退而求其次引入 步长也就是学习率的概念,在每一步都保证走的是最陡的方向,这就是梯度下降
到现在问题都解决了,只剩下如何求解的问题了,求解的过程可分为:
- 找到合适的方向
- 根据步长和方向前进
- 更新方向参数,重复2,3
梯度下降的方式选择
1.批量梯度下降
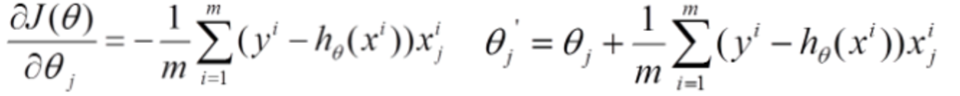
顾名思义,即对所有样本求解,在求均值。速度慢,但是准确性很高
2.随机梯度下降
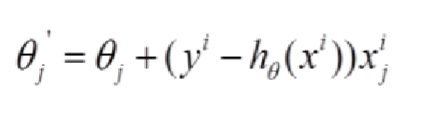
可以看出与批量梯度下降的区别,只对一个样本进行求解就进行参数更新,迭代速度是很快,但是准确率可想而知很低。万一取到某个离群样本,那么最后拟合的结果就会很离谱
3.小批量梯度下降
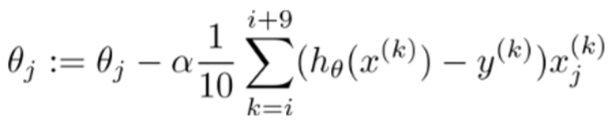
图中的例子是一次取了10个样本的均值进行下降方向更新,考虑到时间和机器性能的问题通常采用这种方式
总而言之根据自己对拟合度,时间等综合考虑进行选择
学习率的选择
学习率对结果的影响很大,因此一般设置要尽量小,也可以一开始设置一个稍大的学习率,再慢慢逐步减小,这样既考虑了时间又考虑到了准确性。通常设置0.01开始,若没有收敛则继续减小
迭代次数的选择
迭代次数越大越好,通常一个小的学习率配一个大的迭代次数会得到一个好的结果。根据数据量选择10000到1000000都可以。
批处理数量的选择
根据电脑的性能选择,越大越好。
学习笔记















 3271
3271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









