






梯度下降作为常见的参数优化方式,更好的实现梯度下降可以得到更好的结果
学习率的设计
在梯度下降过程中,学习率的大小非常影响模型的训练效果与效率。如图:
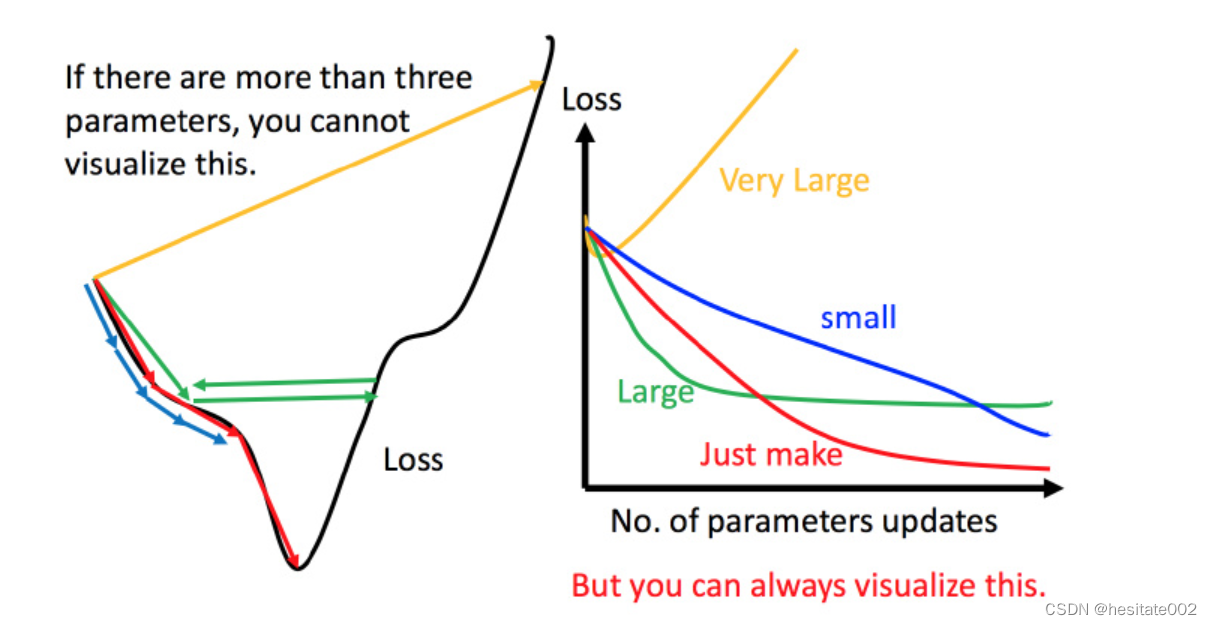
- 学习率过小,参数迭代速度很慢,虽然用足够的时间训练之后,也可以得到最优解,但是时间成本太大,参照蓝色线;
- 学习率过大,经过一段时间迭代后,最终可能在最优解左右反复横跳,参照绿色线;
- 学习率太大,效果更差,参照黄色线;
只有学习率选择恰当,才能高效的得到最优解。
自适应学习率
想法比较简单和朴素:
η
t
+
1
=
η
t
t
+
1
\eta_{t+1}=\frac{\eta_{t}}{\sqrt{t+1}}
ηt+1=t+1ηt
t为迭代次数,随着迭代次数增加,理论上离最优解越来越近,因此学习率随之减少。
但是不同的参数应当具有不同的学习率,因此这种方法还是比较局限的。
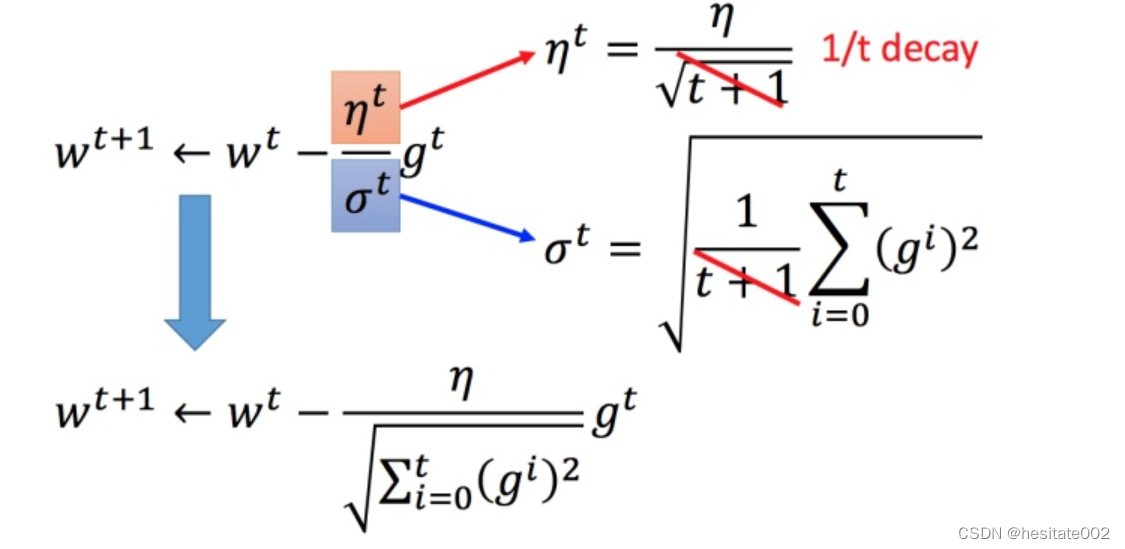
Adagrad算法
解释:每个参数的学习率都把他除以之前微分的均方根。

将Adagrad的式子化简:
随机梯度下降
-
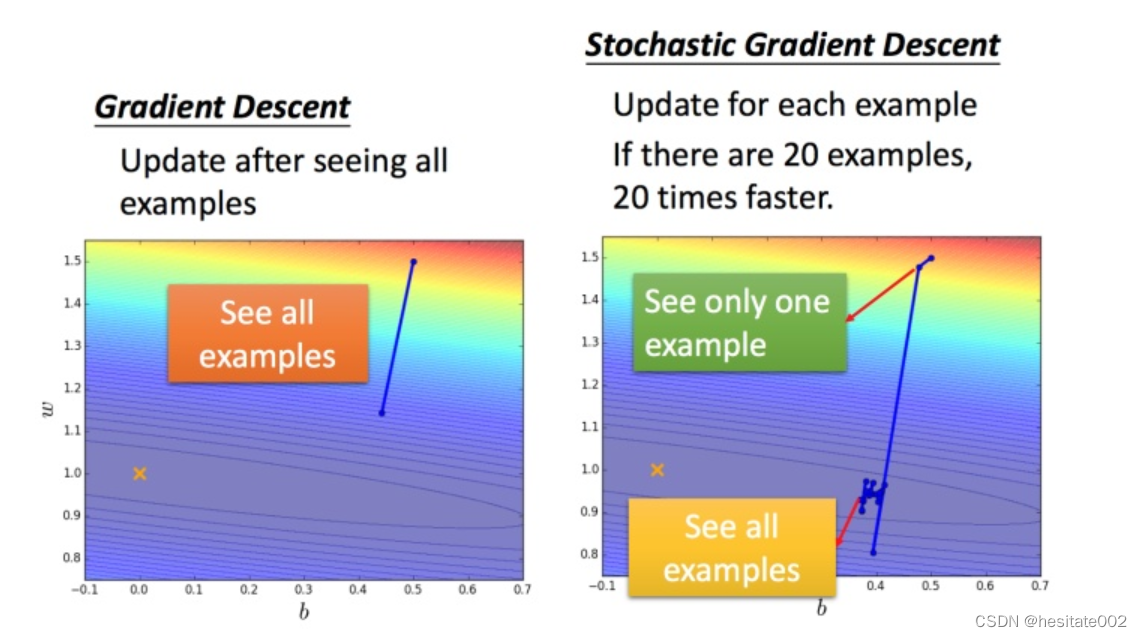
一般的梯度下降:
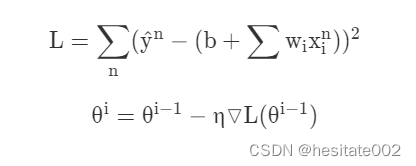
损失函数包含每一个数据样本; -
随机梯度下降:

特征缩放
想象如果两个变量的值得差异非常大:
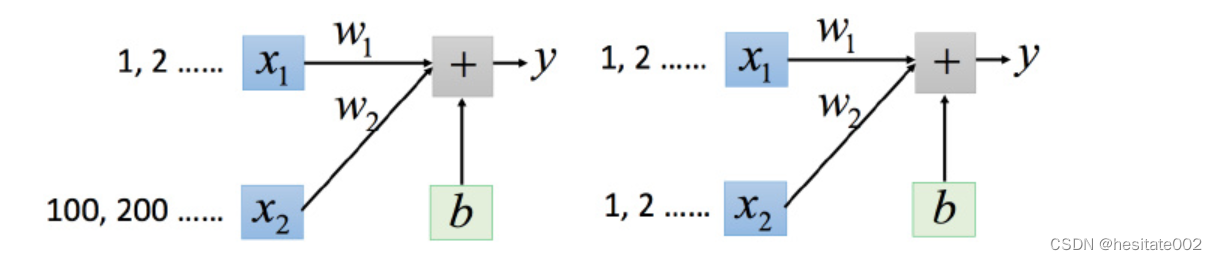
很明显,
w
1
w_{1}
w1的变化对y的影响远小于
w
2
w_{2}
w2。
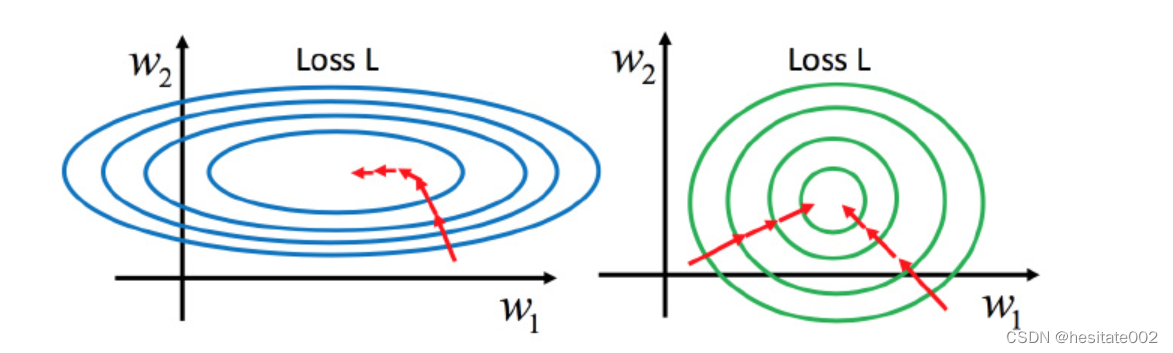
如果是左边的情况,就会出现梯度下降时走了很多弯路,而右边的情况,无论是从哪个方向开始梯度下降,迭代次数都是差不多的,无疑是更好的选择。
参数缩放的常见方法
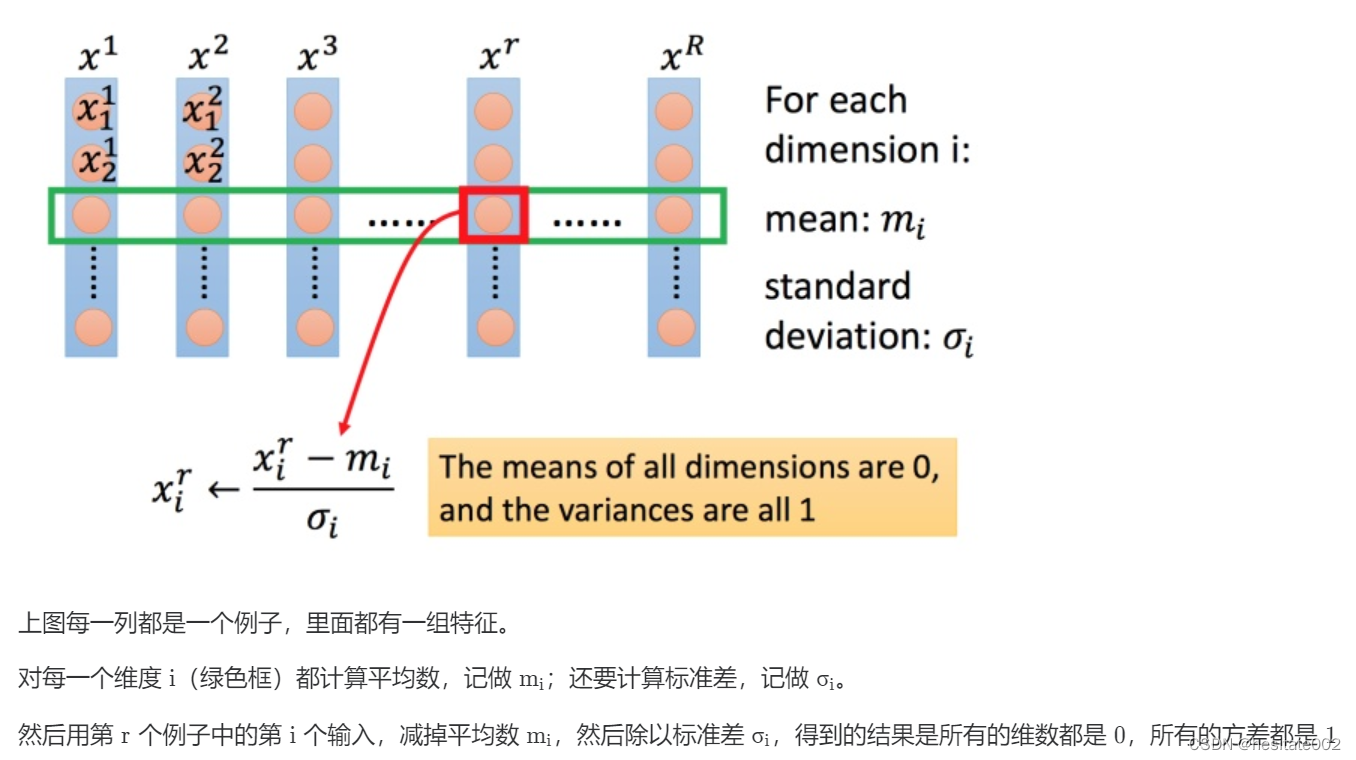
相当于是让每一种参数都落在正态分布。
注
文内相关图片均截图自datawhale组织的开源文档。















 3037
3037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









