






1.数据集介绍
数据集是kaggle上的公开数据集,是从星巴克的调查问卷统计而来,其中包括了1. Your Gender 2. Your Age 3. Are you currently…? 4. What is your annual income? 5. How often do you visit Starbucks? 等等 21个问题。
导入数据集,并且查看缺失值
import numpy as np
import pandas as pd
import warnings
import missingno as miss
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
data=pd.read_csv('Starbucks satisfactory survey.csv')
miss.bar(data,figsize=(10,8),labels=False)


可以看得出基本没有缺失值
2.提出问题:喝星巴克的频率是否与性别有关?
2.1 数据预处理
第一步:
这里只探究性别与喝星巴克的频率所以去掉其他的特征,并且把原本的列名换成更简短的
data=data.iloc[:,[1,5]]
data.columns=[1,2]
data.head()

第二步:
data[2].value_counts()

为了简化问题,把weekly,monthly,daily 都归为 often,rarely和never 都归为 rarely
data[2]=data[2].replace(['Weekly','Daily','Monthly'],'Often')
data[2]=data[2].replace('Never','Rarely')
data[2].value_counts()

3.解决问题——卡方检验
什么是卡方检验
卡方检验
关于卡方检验的基本思想,统计学意义,使用条件等等这篇文章很详细,不再赘述
3.1建立假设和确定置信水平
H
0
H_0
H0:性别与喝星巴克的频率无关
H
1
H_1
H1:性别与喝星巴克的频率有关
α
\alpha
α=0.05
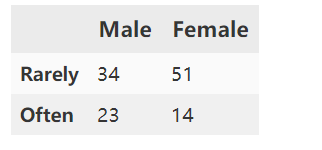
3.2统计对应变量的实际观测值矩阵
male_rarely=len(data[data[1]=='Male'][data[2]=='Rarely'])
female_rarely=len(data[data[1]=='Female'][data[2]=='Rarely'])
male_often=len(data[data[1]=='Male'][data[2]=='Often'])
female_often=len(data[data[1]=='Female'][data[2]=='Often'])
True_data=pd.DataFrame({'Male':{'Rarely':male_rarely,'Often':male_often},
'Female':{'Rarely':female_rarely,'Often':female_often}})
True_data
3.3算出在 H 0 H_0 H0假设下的不常光顾率
num_rarely=male_rarely+female_rarely
num_often=male_often+female_often
rate_of_rarely=num_rarely/(num_rarely+num_often)
print('理论上不常光顾率为{}'.format(rate_of_rarely))

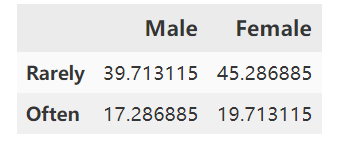
3.4根据算出的不常光顾率算出理论上的男女常光顾和不常光顾的人数
male=male_rarely+male_often
female=female_rarely+female_often
theory_data=pd.DataFrame({'Male':{'Rarely':male*rate_of_rarely,'Often':male*(1-rate_of_rarely)},
'Female':{'Rarely':female*rate_of_rarely,'Often':female*(1-rate_of_rarely)}})
theory_data
3.5根据公式算出 χ 2 \chi^2 χ2的值
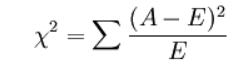
sum=0
for i in range(2):
j=0
sum+=(np.square(True_data.iloc[i,j]-theory_data.iloc[i,j])/theory_data.iloc[i,j])
j+=1
sum+=(np.square(True_data.iloc[i,j]-theory_data.iloc[i,j])/theory_data.iloc[i,j])
sum

自由度=(行数-1)(列数-1)=1x1=1
查分布表可知自由度为1且
α
=
0.05
\alpha=0.05
α=0.05的临界值为3.84而5.086470438049385>3.84 ,因此有95%的把握拒绝原假设
H
0
H_0
H0,
即95%的把握认为喝星巴克的频率与性别有关
3.6两种更简单的方法
1.
import scipy.stats as stats
kf=chi2_contingency(True_data.values,correction=False) #自由度为1的时候关闭修正
kf
使用chi2_contingency直接传入你的实际观测数据就可以

它会直接帮你计算出
χ
2
\chi^2
χ2,和对应P值,自由度和理论值矩阵
这里注意当自由度=1的时候,关闭函数自带的自动修正令correction=False,不然值可能与算出来有偏差
2.
stats.chisquare(f_obs=True_data.values.flatten(),f_exp=theory_data.values.flatten())
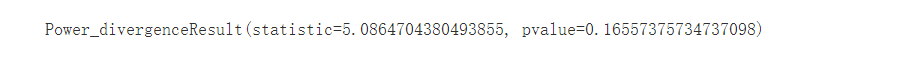
chisquare需要传入两个参数,分别是观测数据和理论数据
但是这里
χ
2
\chi^2
χ2没问题,可是P值算的有点问题。所以建议数据量小的话还是用chi2_contingency比较合适
4.小结
1.数据量比较小,并且只根据卡方检验是无法直接得出结论的,这里只是为了举个小栗子,想要得到更多的结论应当再做更多的分析:例如相关分析等等
2.chisquare算出来的P值为什么有问题,这个暂时还没有头绪,试了比较大的数据量下是没什么问题的,所以猜测可能是数据量小的问题,如果你知道为什么的话请告知我,感谢。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









