






标题:Asynchronous federated learning on heterogeneous devices: A survey
来源:Redirecting
cite:Xu C, Qu Y, Xiang Y, et al. Asynchronous federated learning on heterogeneous devices: A survey[J]. Computer Science Review, 2023, 50: 100595.
背景引言总结:
随着计算能力的快速增长促进了机器学习的蓬勃发展,ML需要大量的高质量数据,但是由于竞争、隐私等因素,行业之间在共享本地数据方面表现出犹豫,导致了数据孤岛的情况,并且从可靠来源收集数据还伴随着高昂的成本。----> FL
FL优势:
(1) 通过基于梯度的全局模型聚合,增强了对本地数据隐私的保护;
(2) 减少了网络传输延迟,因为训练数据保持本地化,而不是传输到云服务器;
(3) 由于结合了其他设备的学习特征,提高了模型质量。因此,FL可以作为跨异构设备的协作ML模型训练的催化剂,这一现象在许多研究出版物中都有很好的记录。
在资源有限的设备上使用经典FL的缺点:
(1)设备不可靠性----以一定概率掉线。
(2) 聚合效率降低----掉队者的存在,这种延迟是由设备异构性(设备之间的资源变化)和数据异构性(跨设备的训练数据分布不均匀)的双重因素造成的。
(3) 资源利用率低----当前节点选择算法中的低效率通常导致很少选择多个有能力的设备来参与。
(4) 安全和隐私漏洞----经典的FL方法容易受到各种安全威胁的影响,例如中毒和后门攻击。
为了解决设备不可靠性、聚合效率降低和资源利用率低的挑战,异步联合学习(AFL)成为一种很有前途的解决方案。在AFL中,中央服务器在接收到本地模型后立即启动全局模型聚合。
(1)减轻了对设备不可靠性的影响,由于设备意外离线对AFL来说是可忽略的。
(2)提高了聚合效率。通过消除在聚合之前等待慢速设备进行本地模型上传的必要性。
(3)提高了异构设备对计算资源的利用率。允许具有不同操作效率的设备以自己的速度训练各自的本地模型。
论文贡献总结:
(1)综合调查回顾和分析了2019年至2022年的125篇研究论文,其中包括7篇相关调查论文。
(2)创新性地从设备异构性、数据异构性、隐私与安全性以及应用场景等角度对AFL的现有论文进行了分类和总结。
(3)调查确定了一些有前景的研究主题.
背景知识
FL、block chain、Differential privacy(后面两个我目前不怎么涉及,所以不太懂,不进行归纳总结,需要的可以原文阅读)
FL
FL是一种ML框架,旨在消除数据竖井的障碍,这主要归因于其对每个节点内的本地训练数据的私有保留特性。传统FL流程包括以下关键步骤:
(1)初始化:服务器初始化全局模型
、学习率、批量大小、迭代次数等训练参数。在选择过程之后将
(2)本地模型培训:假设𝑡 代表当前迭代次数。基于全球模型
, 每个节点训练其各自的本地模型
,随后传送回聚合服务器。
(3)全局模型聚合:假设节点上的训练样本𝑘 总计
, 并且训练样本的总数表示为𝑛, 服务器通过取局部模型的加权平均值来生成新的全局模型。
现实中节点收集数据通常是non-IID的,这对经典FL和AFL都提出了挑战。此外,跨节点的不一致数据大小在每个节点上训练所需的时间上引入了显著的差异。这通常会导致在较慢的节点(掉队者)上生成过时的局部模型,从而降低聚合后全局模型的准确性。
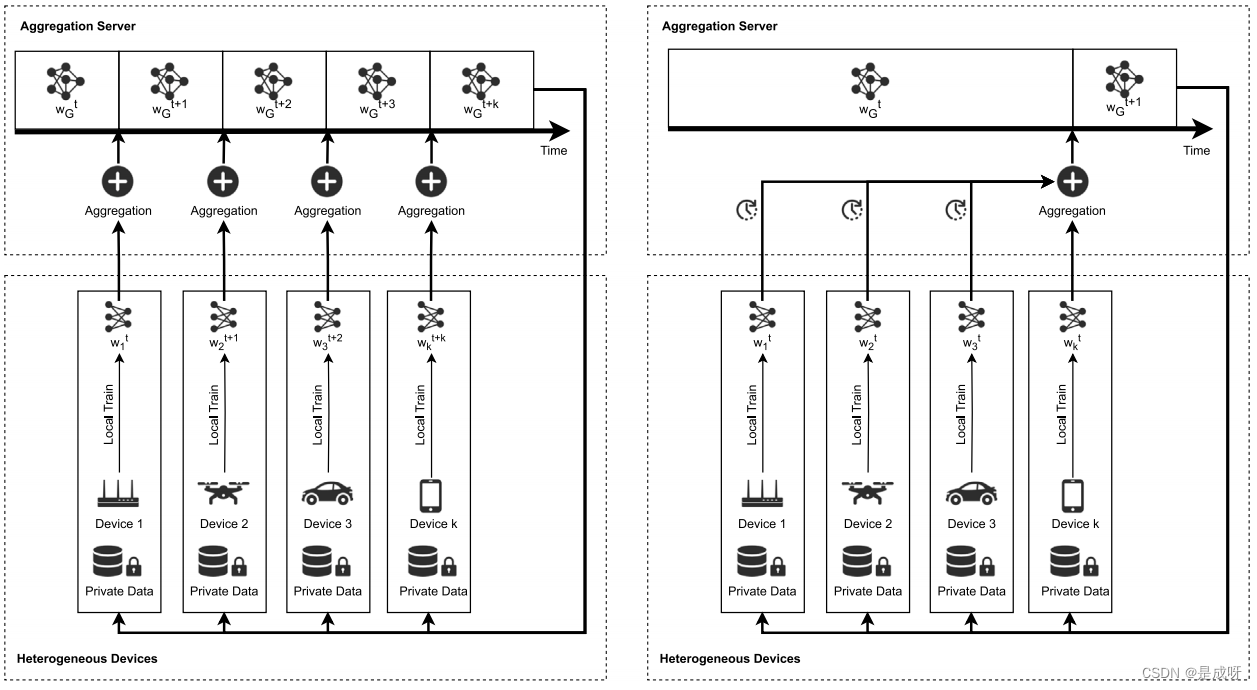
AFL是为了减轻陈旧节点的影响,提高FL的效率而提出的。在AFL框架内,一旦聚合服务器接收到新的本地模型,就会立即进行全局模型聚合。异构设备上异步和同步FL的工作流比较如图所示。
AFL的主要步骤概述如下:
(1)初始化:与经典FL类似,服务器广播初始全局模型
(2)本地模型训练:节点根据最新的全局模型对各自的本地模型进行训练。
由于设备之间计算能力的异质性,本地模型训练的[
,
,
,......,
]完成不会同时发生。然后将本地模型分别发送回聚合服务器。----->以依次到达?
(3)全局模型聚合:服务器将新收集的本地模型与最新的全局模型聚合


分类总结:
Device heterogeneity:
AFL的主要障碍是优化异构设备的资源利用率,以提高训练效率。同时,由于设备异构性,存在过时的局部模型的障碍,这是一个不利于全局模型性能的因素。
Node selection:
与经典的FL选择具有更多训练数据的节点相比,AFL倾向于优先考虑具有更高弹性和计算能力的节点。然而,在全局模型的稳健性和过拟合之间取得平衡是一项挑战。
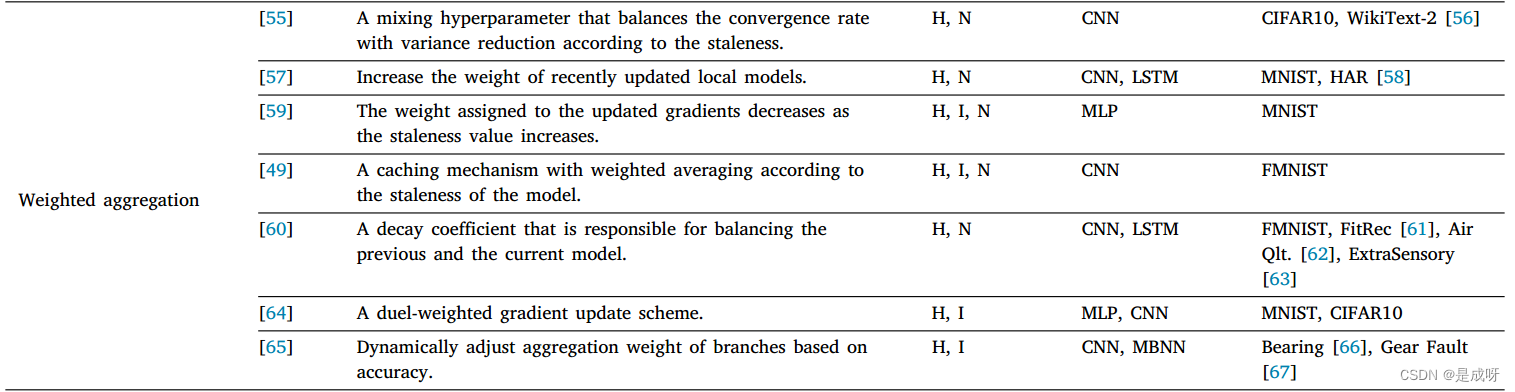
weight aggregation:
在传统的FL中,加权聚合旨在放大用更多数据训练的局部模型的影响。然而,在AFL中,目标转向减轻陈旧的局部模型的影响,这在经典FL中是不存在的。
Gradient compression:
梯度压缩是一种广泛适用的提高FL效率的策略,因此将其纳入AFL通常旨在额外减少通信费用。
AFL给梯度压缩带来了新的挑战,主要是在边缘和物联网设备的资源受限计算环境中,以及更高频率的聚合操作中。具体而言,节点之间计算能力的差异要显著得多。此外,与经典FL相比,由于聚合和压缩操作的频率增加,AFL在服务器端产生了更大的计算需求。
Semi-asynchronous FL:
半异步FL是一种混合方法,它结合了经典FL和AFL的元素,其中聚合服务器捕获并存储较早到达的本地模型,随后在特定的时间段内聚合它们。根据老化程度的不同,随后到达的本地模型要么参加接下来的训练轮,要么被丢弃。值得注意的是,半异步FL的聚合频率介于AFL和经典FL之间。与经典FL类似,训练轮被定义为从一个全局聚合到下一个全局集合的过程。
Cluster FL:
集群FL是一种旨在通过形成包括表现出类似性能、功能或数据集的设备的集群来提高训练效率的方法。异步更新策略有可能对组内更新、组间更新或两者都有利。
Model splitting
模型分割策略减少了传输所需的参数数量,从而提高了通信效率。在将模型分割策略集成到AFL中时,节点绕过了等待其他节点的需要,并充分利用它们的计算资源来训练模型以用于后续回合。因此,模型分裂策略在一定程度上加速了全局模型的收敛
Data heterogeneity
现实中,跨节点的数据通常是非IID的。此外,分布在每个节点上的数据量总是不平衡的。因此,在特定节点上频繁上传模型有可能吸引全局模型的分歧,并导致对特定数据集的过度拟合。
Non-independent and identically distributed data
节点之间非IID数据的存在往往会导致AFL中的全局模型有偏差。解决该问题的研究主要有聚合的约束项、聚类FL、分布式验证策略和数学优化参数。
Vertical distributed data:
与水平FL相比,垂直FL侧重于不同特征子集分布在不同节点上的数据集。鉴于全局模型的创建取决于局部模型的聚合,因此需要对这些局部模型进行协作更新。这种扭曲的特征分布和增强的模型相互依赖性因此对垂直AFL提出了挑战。为了应对这些挑战,最先进的计划主要侧重于提高沟通和培训效率。
Privacy and security on heterogeneous devices(自己暂未涉及研究):






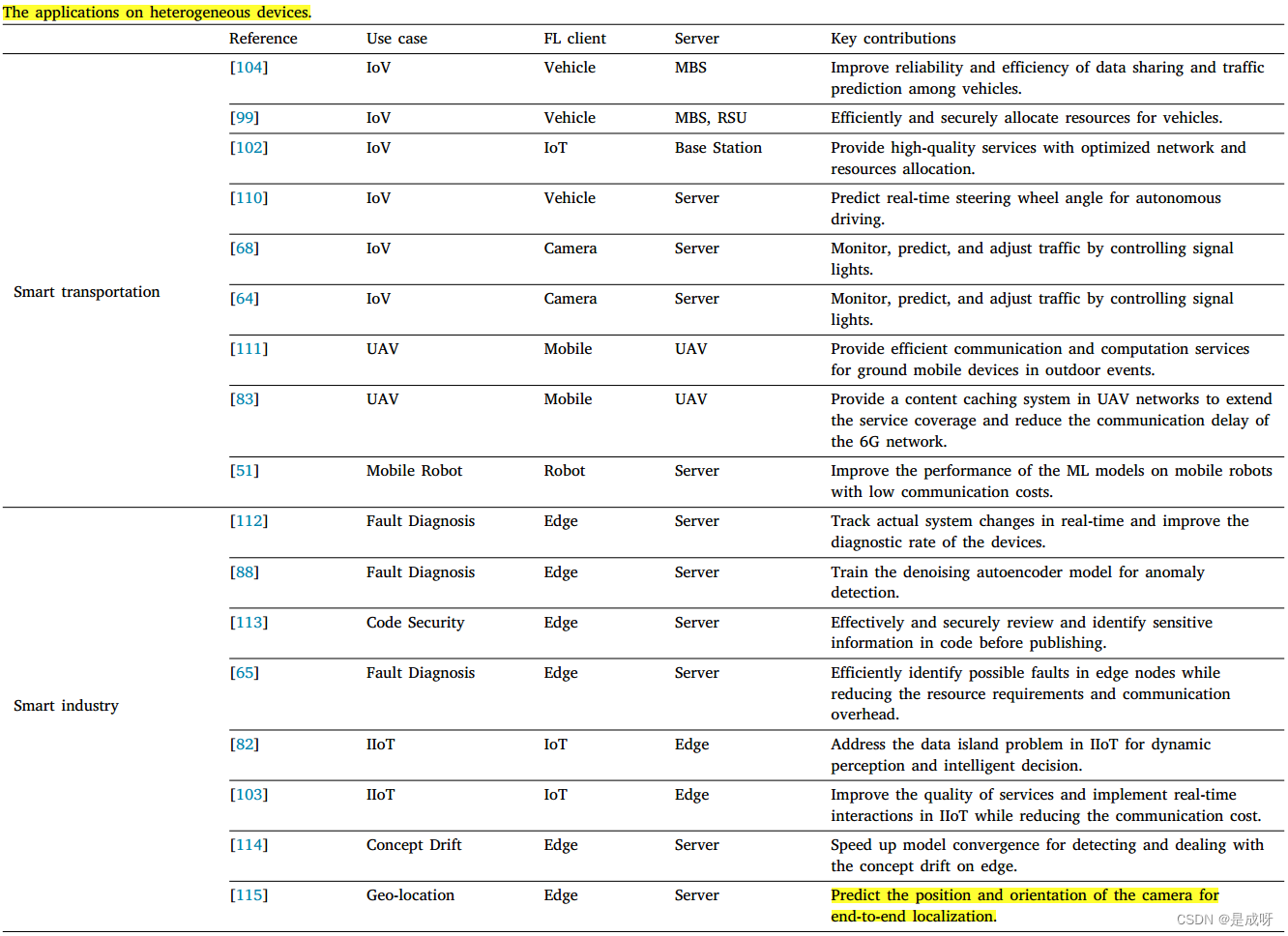
Applications on heterogeneous devices:
Research challenges and future directions:
Device heterogeneity:
1)平衡时间成本与性能改进:对于AFL,异构设备上现有的性能改进策略,如节点选择、加权聚合和集群FL,在各种方面都是有效的。一些工作甚至同时采用几种策略来提高AFL的效率。然而,在AFL中使用过多的策略在一定程度上会导致效率下降。例如,如果选择一系列节点,然后在资源有限的设备上压缩梯度比上传本地梯度花费更长的时间,则最好跳过其中一个。到目前为止,还没有全面分析多种绩效改进策略与时间消耗之间的平衡,这是一个潜在的研究方向。
2)针对广义AFL解决方案的优化:通常,不同的性能改进策略有不同的应用场景。为不同的应用场景设计一个通用且灵活的AFL优化框架是一个可行的研究领域。预计将通过最低限度地集成现有技术和未来技术来实现这一目标。
3)优化动态资源分配:由于更多的全局模型聚合操作,与经典FL相比,AFL需要更多的通信资源。因此,期望考虑动态资源分配算法,包括发射功率、模型训练的计算频率和模型选择策略,以在LTA能耗约束下最大化长期时间平均(LTA)训练数据大小。
Data heterogeneity:
1)针对异构数据分布的优化:基于数据分布相似性的聚类训练是一个潜在的研究课题,但它需要开发适当的相似性评估算法。此外,基于迁移学习或元学习,异步个性化局部模型训练是一种有效而准确的解决方案。
2)基于局部数据集大小的加权聚合策略是一种可能的解决方案,但如何在每个节点上验证数据集大小是否有效是另一个安全问题。
3)垂直数据分布优化:垂直数据分布在经济场景中很普遍,每个节点都拥有不同的数据集特征。滞后的局部模型在垂直AFL中是不可忽视的。一个可能的研究方向是半异步FL。通过服务器端缓存,可以存储过时的本地模型并提高其有效性,同时保持其他本地模型的最新状态。此外,另一个潜在的研究方向是模型分割,它根据节点上的特征分布来分割全局模型,并转换为聚类的水平AFL。然而,在不知道每个节点上的局部数据集的情况下,很难通过局部模型来识别特征在节点之间的分布。
PS:隐私与安全这里未写,原文有
Applications on heterogeneous devices:
1)扩展真实世界的应用:例如,在智能医院中,AFL基于电子医疗记录(EHR)训练的ML模型可以预测患者的情况。在智能电网中,AFL在异构设备上训练ML模型,以预测各个领域的能源消耗,并实现智能电力调度。在智能农场中,在AFL训练的ML模型的帮助下,物联网可以很好地监测、诊断和预测植物的生长情况。
2)开发真实世界的评估试验台:AFL的大多数实验都是在模拟模式下进行的,没有证明ALF在现实世界中的可行性。预计将在物联网或边缘设备上进行更多实验,以评估AFL方案的效率、安全性和隐私性。因此,开发部署在异构设备上并可从标准化接口访问的可扩展和灵活的试验台将是一个很有前途的研究方向。测试台的开发包括架构设计、异构设备的包容性、结构效率和性能微调等问题。
原文非常详细,我这是缩略版,感兴趣的可以看原文~

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









