






 本文探讨了基于Transformer的DeepSC在文本传输中的应用,解决了语义通信中的定义含义、衡量误差和联合编码设计问题。同时提及BERT、RNN、CNN和FCN在NLP中的作用,并指出信道编码中的训练疑点。
本文探讨了基于Transformer的DeepSC在文本传输中的应用,解决了语义通信中的定义含义、衡量误差和联合编码设计问题。同时提及BERT、RNN、CNN和FCN在NLP中的作用,并指出信道编码中的训练疑点。
DeepSC:用于文本传输。
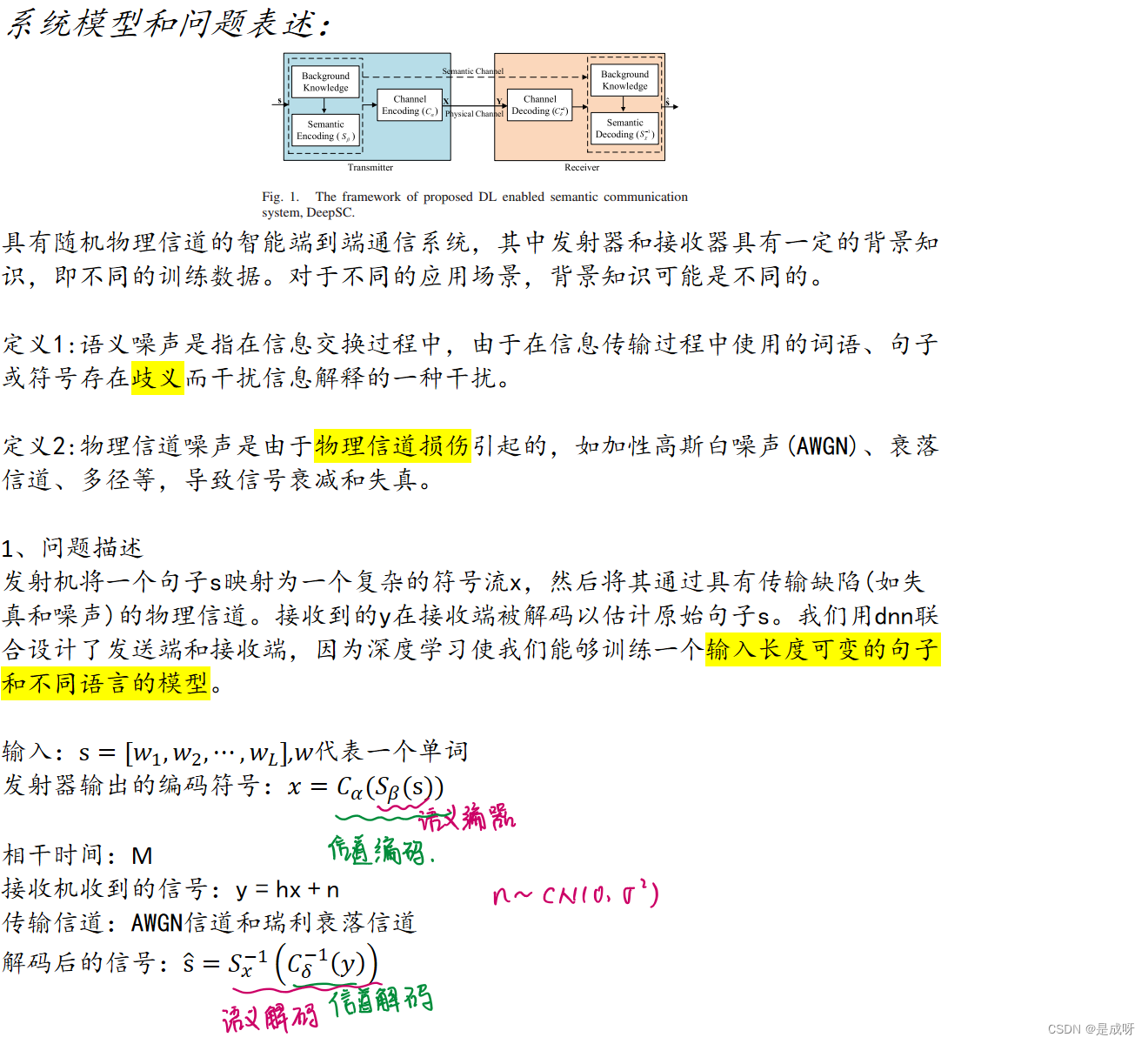
基于Transformer, DeepSC旨在通过恢复句子的含义来最大化系统容量并最小化语义错误,而不是传统通信中的比特或符号错误。
对于语义通信系统,我们面临以下问题:
| 问题1:如何定义比特背后的含义? | 自注意机制可以学习语义 |
| 问题2:如何衡量句子的语义错误? | 提出了一种新的度量标准来准确地反映DeepSC在语义层面的性能 |
| 问题3:如何联合设计语义编码和信道编码? | 在提出的DeepSC中,设计了一种联合语义信道编码来处理信道噪声和语义失真,在压缩数据时可以保留语义信息 |
由于硬件计算能力的提高,训练神经网络并在移动设备上运行成为可能。
一种通用的单词表示模型,称为来自变压器的双向编码器表示(BERT),用于为各种NLP任务提供单词向量,而无需重新设计单词表示。
RNN:语言模型可以学习整个句子并有效地捕获语法信息,然而,对于长句子,特别是主谓之间的距离超过10个单词时,rnn无法找到正确的主谓。
CNN:天生具有并行计算的能力。然而,即使cnn可以使用更深层的网络来提取长句子中的语义信息,其性能也不如rnn,因为cnn中的核尺寸较小,无法保证计算效率。
FCN:如Transformer,通过与注意机制相结合,更多地关注有用的语义信息,以提高各种NLP任务的性能。值得注意的是,Transformer同时具有rnn和cnn的优点。特别是采用了自注意机制,使模型能够理解句子,而不考虑句子的长度。

2、信道编码和解码设计
互信息可以为训练接收机提供额外的信息
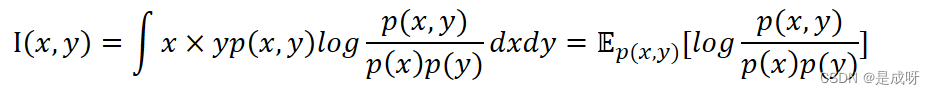
通过最大化互信息来优化编码器,其损失函数可以由式给出
![]()
![]()


   | |||
|
疑点: 网络训练考虑了前向传播中将channel layer作为网络中的一层 但是反向传播Y->X的算法中目前没有会应用加噪声的,所以似乎与实际信道不相符合? | |||

















 2456
2456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









