






前言
本周阅读文献《Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia》,文献主要提出了基于注意力(AT-LSTM)的模型,以实现水质预测。由于注意力机制通过对每个时间步的隐含层元素进行加权,有效地捕获更远的关键信息,增强重要特征对预测模型的影响。注意力机制在时间序列分析和预测领域也被广泛采用。所以引入了注意力机制,并基于LSTM模型开发了AT-LSTM模型,能够更好地捕获水质变量。另外,主要阅读了6篇应用机器学习方法对水质进行预测的文献,总结这6篇文献用到的机器学习方法,它们都是通过修改模型来提高预测的性能。
This week,I read an article which aims to develop a long short-term memory (LSTM) network and its attention-based (AT-LSTM) model to achieve the prediction of water quality. We have applied the attention mechanism to effectively capture the more distant critical information and enhance the influence of the important characteristics on the prediction model by weighting the hidden layer elements at each timestep. Attention mechanisms have also been widely adopted in the field of time series analysis and forecasting.we introduced the attention mechanism and developed an AT-LSTM model based on the LSTM model, focusing on better capturing the water quality variables. In addition, I mainly read six literatures on water quality prediction using machine learning methods.I summarize the machine learning methods used in the 6 literatures.They all modify the model to improve the performance of the prediction.
文献阅读
题目:Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia
作者:Honglei Chen 1,2ORCID,Junbo Yang 1,2,Xiaohua Fu 1,2,,Qingxing Zheng 1,2,Xinyu Song 1,2,Zeding Fu 3,Jiacheng Wang 1,2,Yingqi Liang 1,2,Hailong Yin 1,2,Zhiming Liu 4,,Jie Jiang 1,2,He Wang 1,2 andXinxin Yang 1,2
摘要
水质预测是水污染控制和预防的一个重要方面。利用从水质监测和水环境管理中收集的历史数据,可以预测水质趋势。本研究旨在开发长短期记忆(LSTM)网络及其基于注意力(AT-LSTM)的模型,以实现澳大利亚伯内特河水质的预测。本研究建立的模型在特征提取后引入了一种注意力机制,考虑序列在不同时刻对预测结果的影响,增强关键特征对预测结果的影响。本研究利用LSTM和AT-LSTM模型对伯内特河溶解氧(DO)进行了单步提前预测和多步提前预测,并进行了结果的比较。研究结果表明,注意力机制的加入提高了LSTM模型的预测性能。因此,本研究开发的基于AT-LSTM的水质预报模型比LSTM模型更能准确预测伯内特河水质。
简介
水质预测是使用长期收集的水质数据来预测未来一段时间内可能的水质趋势。为提前评估水环境、防止水污染问题大规模发生提供了科学决策依据。河流水质参数不仅受外部因素影响,还受自变量和随机扰动的历史值影响,滞后项和相关变量的选择是影响预测精度的因素之一。溶解氧(有机污染物在河水污染中占很大比例。河流的有机污染,由于污染物分解产生的氧气消耗,导致水中溶解氧迅速减少,从而导致水质恶化。河水体自净能力下降,对生态系统造成严重破坏)是河水污染的关键参数,也是河水是否具有自净能力的重要指标。在水环境中,水生动植物的生长离不开适量的溶解氧。本研究以水质评价中溶解氧的关键参数为模型构建和预测评价的目标。目前,大多数水质数据属于长相关序列数据,在相应的时间序列中可能存在一些延迟和间隔较长的重要事件。传统的机器学习方法很难充分利用具有长期历史观察的可用信息。RNN在处理时间序列和捕获非线性关系方面非常灵活,由于梯度消失,传统的RNN模型很难保留变量之间的长期依赖性。长短期记忆(LSTM)是RNN的一种变体,可以通过实现门控[23]有效缓解RNN网络时间延迟和梯度消失。LSTM缺乏对子窗口特征不同程度关注的能力,可能导致部分相关信息被忽略,时间序列的重要特征无法估价。近年来,注意力机制已被部署在自然语言处理的各种任务中。应用注意力机制,通过对每个时间步的隐含层元素进行加权,有效地捕获更远的关键信息,增强重要特征对预测模型的影响。注意力机制在时间序列分析和预测领域也被广泛采用。我们引入了注意力机制,并基于LSTM模型开发了AT-LSTM模型,专注于更好地捕获水质变量。
数据源和预处理
数据
本研究使用的数据是来自伯内特河自动监测站点的水质数据,使用了2015年2020月至39年752月采集的伯内特河水质监测数据。数据每半小时收集一次,包括五个特征:水温(温度),pH,溶解氧(DO),电导率(EC),叶绿素-a(Chl-a)和浊度(NTU)。本实验中使用的溶解氧是水有机污染的关键指标,可以反映水污染的程度。
缺失值处理
数据的缺失值有两种处理方式:(1)如果一次监测中只缺少一个指标,则通过线性插值填充数据;(2)如果连续缺少一个监测值,则删除监测时刻的数据,避免人为填充造成较大误差。
缺失值(x,y),存在坐标(x0,y0)和(x1,y1)之间,

最终得:
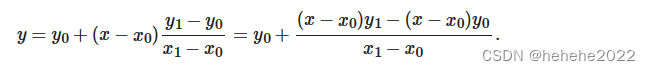
插值后,数据集将成为时间间隔相等的连续时间序列。
水质相关性分析
多变量时间序列通过分析历史时间序列数据和各个因素之间的相关性来构建预测模型。对于多元素水质时间序列数据,不同元素特征对水质预测的影响不同。需要选择多个特征,特征选择可以减少模型训练时间,提高模型效率,使其泛化能力更强。皮尔逊相关检验[49]用于确定不同特征与需要预测的时间序列特征的相关性。
公式:
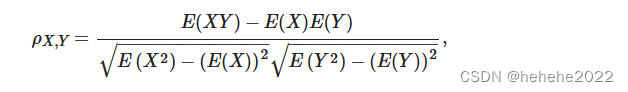
异常值检测
水质监测站在数据采集过程中经常受到环境变化和仪器故障的影响,导致数据缺失和数据异常,对后续模型预测产生严重影响。在此实验中,检测到的异常值被视为缺失值,并使用线性插值来完成数据。通常,可以在图形方法(箱线图和正态分布图)和建模方法(线性回归、聚类算法和 K 最近邻算法)的帮助下识别异常值。该实验使用箱线图方法来识别异常值。箱线图技术[50]实际上使用数据的分位数来识别其中的异常值。
数据规范化
对于联合多因素水质时间序列数据预测,不同的水质指标往往具有不同的水平。在随后的水质时间序列预测过程中,不同层次的元素严重影响了模型预测的准确性。此外,在模型训练过程中,输入数据过大或过小都可能导致模型不收敛等问题。为了解决这个问题,本文使用异常值归一化(最小-最大归一化)[51]来归一化数据。异常值归一化根据最大值和最小值之间的差值之比对数据进行缩放,以使水质数据的变化范围保持在 0 到 1 之间。归一化可以减轻不同尺度对模型训练的影响。归一化公式如公式(4)所示:
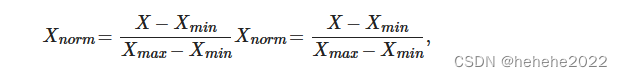
时间序列转换为监督数据
在使用时间序列预测模型进行预测之前,需要将时间序列数据从非监督数据转换为监督数据,以便通过比较真实值和预测值之间的差距来促进模型。时间序列数据到监督数据的转换依赖于特征输入值和目标值的滑动窗口拦截来构建监督数据。
理论基础与模型构建
LSTM
注意力机制

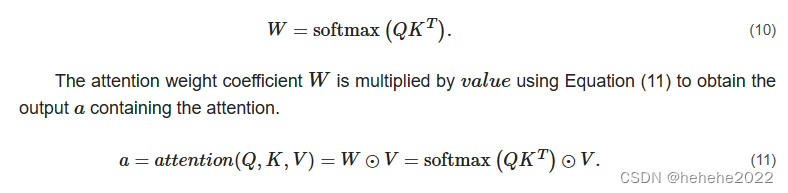
模型建立
本研究介绍了LSTM网络的注意力机制,并提出了AT-LSTM网络模型来处理多变量时间序列数据。该模型的主要思想是通过自适应加权神经网络的隐含层元素来降低不相关因素对结果的影响,突出相关因素的影响,从而提高预测精度。模型框架如图 7 所示,主要组件是 LSTM 层和注意力层。
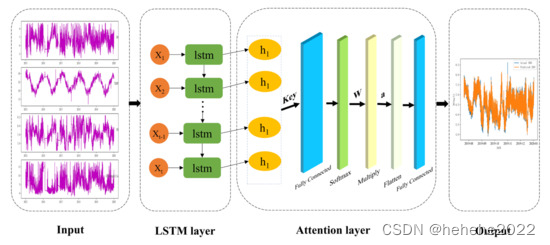
性能标准
水质预测本质上是一个回归问题。本研究对平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2)用于定量评估模型预测效果。
结果和讨论
使用 LSTM 和 AT-LSTM 模型的提前一步预测比较
本研究旨在分析AT-LSTM和LSTM模型在多元时间序列预测中的差异。AT-LSTM 和 LSTM 模型在执行超前多步预测之前,使用多元时间序列的过去值进行提前一步预测。这些模型使用相同的输入数据来预测下一个小时的 DO。显示了在测试集上进行预测时 LSTM 模型和 AT-LSTM 模型之间的比较。可以看到 AT-LSTM 模型在伯内特河测试集的水质预测方面优于 LSTM 模型。标准LSTM方法表现不佳,RMSE为0.171,R2的 0.918。引入注意力机制后,RMSE和R型2分别显示减少和增加。这是因为模型中的注意力层对神经网络不同时刻的隐含层元素进行加权,去除时间序列数据中的冗余信息和噪声,突出相关特征对预测效果的影响,从而提高预测精度。
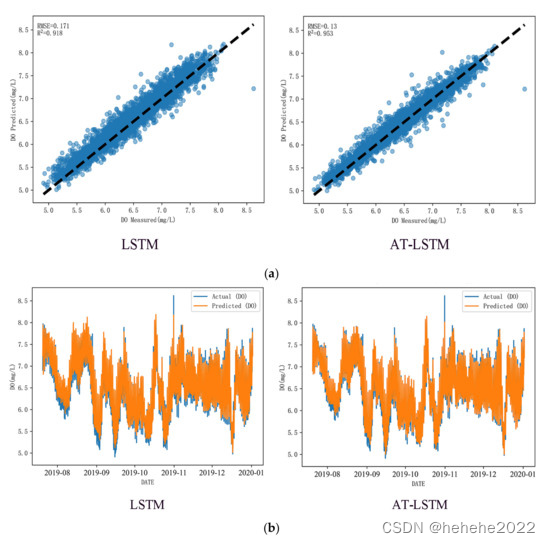
使用 LSTM 和 AT-LSTM 模型的多步预测比较
为验证AT-LSTM模型的预测性能和泛化能力,本研究进行了不同步长的溶氧水质预测实验。滑动窗口宽度仍设置为 100。预测步骤为4-48步,即过去100 h的数据预测未来4-48 h的水质。预测误差 MAE、RMSE 和 R 的比较2测试集的LSTM和AT-LSTM模型如表5所示。显然,AT-LSTM模型的MAE和RMSE值在每一步上都小于LSTM模型,并且R2AT-LSTM模型的每一步均高于LSTM模型。总模型的MAE和RMSE平均值分别比LSTM下降了14.6%和12.2%,但平均R2增长10.8%。在总体趋势方面,随着预测步长的增加,模型预测误差也随之增大,不如对未来1 h的预测。
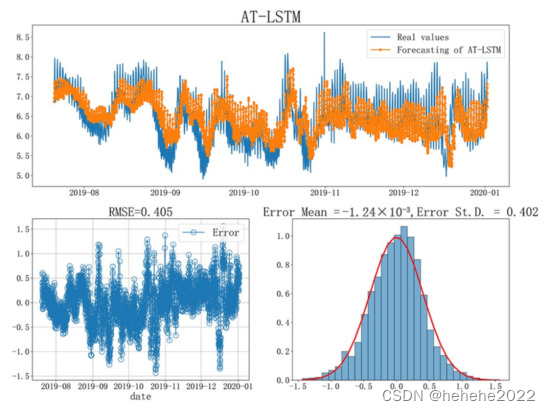
在测试数据集上使用 AT-LSTM 模型提前 48 小时预测的折线图、残差直方图和误差图。
结论和未来工作
本研究提出的AT-LSTM模型融合了LSTM神经网络的非线性映射能力和注意力机制的特征加权函数,高效提取了水质数据的特征信息,预测了伯内特河的溶解氧含量,预测精度明显高于LSTM模型。与标准LSTM模型相比,AT-LSTM水质预测模型的RMSE和MAE分别降低了23.9%和27.7%,并且R含量更高。295.3%,泛化性能更好。在实际应用中,AT-LSTM模型可用于建立伯内特河水质预测预警平台,提前感知河水潜在污染风险,发送预警报告,进行污染检索。该AT-LSTM模型可以显著提高相关部门对水环境风险的预测能力,将被动水环境风险应急处理升级为自动预测,并提供预警和主动预防,从而保护伯内特河和大堡礁的水生环境。此外,本研究提出的模型可为其他地区地表水体水质预测模型的构建提供参考。显然,AT-LSTM模型具有重要的应用价值和现实意义。
本研究采用的特征筛选方法是一种相对简单的皮尔逊相关检验算法,是一种线性特征筛选算法。对于未来的研究,我们将尝试数据预处理和特征工程方法,例如使用非线性特征筛选方法,寻找影响预测指标作为更有效的因素,希望模型的预测精度能够进一步提高。
时间序列预测
本周主要找寻一些水质预测的相关文献,学习总结文献用到的方法,以及未来可以继续研究的方向。
Machine learning methods for better water quality prediction (2019)
摘要
在任何水生系统分析中,模拟水质参数都具有相当重要的意义。传统的建模方法依赖于涉及大量未知或未指定输入数据的数据集,并且通常由耗时的过程组成。人工智能 (AI) 的实施带来了灵活的数学结构,能够识别输入和输出数据之间的非线性和复杂关系。由于一些发展和人类活动,柔佛河流域已经严重退化。因此,建立水质预测模型以改善水资源管理至关重要,并将成为一个强有力的工具。已经实施的不同建模方法包括:自适应神经模糊推理系统(ANFIS),径向基函数神经网络(RBF-ANN)和多层感知器神经网络(MLP-ANN)。然而,由于随机和系统误差,从监测站和实验中获得的数据可能会受到噪声信号的污染。由于数据中存在噪声,因此做出准确的预测相对困难。因此,建议使用基于神经模糊推理系统(WDT-ANFIS)的增强小波去噪技术,该技术依赖于水质参数的历史数据。在感兴趣的领域,水质参数主要包括氨氮(AN),悬浮固体(SS)和pH值。为了评估对模型的影响,使用了三种评估技术或评估过程。第一个评估过程取决于神经网络连接权重的分区,以确定网络中每个输入参数的重要性。另一方面,第二和第三个评估过程确定最有效的输入,这些输入有可能分别使用单个参数和组合参数构建模型。在这些过程中,引入了两个方案:方案 1 和方案 2。情景1构建每个站点水质参数的预测模型,而场景2基于前一个站点(上游)相同参数的值开发预测模型。这两种方案都基于 2009 个输入参数的值。2010年至2年的现场数据用于验证WDT-ANFIS。WDT-ANFIS模型在所有水质参数的预测精度方面表现出显着提高,并且优于所有推荐模型。此外,情况1的表现比情景0更充分,所有站点的所有水质参数在5.5%至<>%的范围内都有实质性改善。通过验证推荐模型,发现模型对所有水质参数的预测效果令人满意(R2值等于或大于 0.9)。
方法论:多层感知器神经网络 (MLP-ANN),自适应神经模糊推理系统ANFIS,小波去噪
这篇论文主要是根据历史水质参数数据使用神经模糊推理系统(WDT-ANFIS)使用增强的小波去噪技术发现在预测水质参数方面效果很好。(通过修改水质模型来提高预测能力)超参数的优化一般通过元启发式优化算法来增强AI模型。
Evolutionary computational intelligence algorithm coupled with self-tuning predictive model for water quality index determination
摘要
人为活动影响水体,导致河流水质(WQ)急剧下降。开发用于评估水适宜性的可靠智能模型仍然是水环境工程师面临的一项具有挑战性的任务。本研究考察了极端梯度提升(XGB)和遗传编程(GP)在获取特征重要性方面的适用性,然后将抽象的输入变量放入预测模型(极限学习机(ELM))中,用于水质指数(WQI)的预测。将独立建模模式与所提出的混合模型进行比较,其中最佳变量被提供给GP,XGB,线性回归(LR),逐步线性回归(SWLR)和ELM模型。WQ数据来自环境部(DoE)(马来西亚),并根据决定系数(R2) 和均方根误差 (RMSE)。结果表明,GPELM和XGBELM混合模型在金塔河流域WQI预测中优于独立的GP、XGB和ELM模型。混合模型的比较表明,GPELM(RMSE = 3.441 训练和 RMSE = 3.484 测试)与 XGBELM 相比,通过分别将训练和测试的 RMSE 值降低 5% 和 9% 来提高准确性(RMSE = 3.606 训练和 RMSE = 3.816 测试)。尽管回归经常被提出作为参考模型(LR和SWLR),但当与计算智能相结合时,它们仍然在本研究中提供了令人满意的结果。所提出的GPELM和XGBELM混合模型以最少的输入变量提高了预测精度,可以作为金塔河流域WQI的可靠预测工具。
方法论:极端梯度提升 (XGB),极限学习机 (ELM),遗传编程 (GP),线性回归,逐步线性回归 (SWLR),
文献主要除了使用GP和XGB作为主要模型或预测模型外,该研究的模式是使用GP和XGB作为非线性选择工具。之后,将选定的输入输入到 ELM 和 LR 中,以评估其性能并将其与独立模型进行比较:GP、XGB、ELM 和 LR。探讨了两种演化非线性输入变量选择技术(GP和XGB)与非调谐数据智能模型(ELM)相结合对马来西亚金塔河流域WQI进行建模的能力。
Water quality prediction using SWAT-ANN coupled approach
摘要
由于影响其性质的复杂水文和环境过程,有效和准确地预测河流水质具有挑战性。在未监测的流域,挑战甚至更大。为此,使用基于过程和基于数据的方法,每种方法都有自己的优点和缺点。混合模型的开发可能会在这方面提供强大的解决方案。为了改善未监测流域的水质预测,我们通过将基于过程的流域模型和人工神经网络(ANN)相结合,开发了一个混合模型。将这两个模型结合起来有助于优化校准和验证过程,同时考虑复杂的水文和水质过程。将开发的模型应用于美国亚特兰大都会区的流域,以预测每月的硝酸盐、铵态氮和磷酸盐负荷。我们将流域视为未受监控,并相应地测试了混合模型的技能。混合模型在预测所有三个成分方面具有良好的技能。该模型对硝酸盐特别有效。事实上,它甚至超过了在每个站点校准的SWAT模型。这项工作强调了拟议的混合建模框架在预测未监测流域水质参数方面的潜在好处。
文献主要提出了混合建模框架通过将SWAT模型纳入ANN来考虑水文以及陆地和溪流中养分的归宿和运输,从而提高了水质预测的准确性。(将传统模型与机器学习方法相结合进行预测)
A new approach to predict the missing values of algae during water quality monitoring programs based on a hybrid moth search algorithm and the random vector functional link network
摘要
在这里,我们提出了一种新的替代机器学习方法,该方法结合了随机向量功能链接网络(RVFL)与飞蛾搜索算法(MSA)的优势,以预测在埃及法尤姆提供饮用水处理厂的地表水水质监测期间总藻类计数的缺失值。在2015个水样中共测量了2017个水质参数。MSA算法用于输入特征的优化选择,以提高RVFL的性能。通过提出的MSA-RVFL方法预测的总藻类计数缺失值与实际观测值密切相关。在不同规模的训练测试中,MSA-RVFL的结果优于支持向量机(SVM)和自适应神经模糊推理系统(ANFIS)模型。与GA-RVFL和PSO-RVFL方法相比,使用MSA-RVFL可以最小化输入变量并减少处理时间。MSA-RVFL模型可以将输入变量的数量从<>个减少到<>个,最终减少到<>个变量。MSA-RVFL选择的用于预测藻类总数的最重要变量是pH,NO。3基于这4个变量,藻类的预测值与实际观测值显著匹配(R2= 0.9594)。因此,这使得MSA-RVFL模型成为水质监测计划期间有用的具有成本效益的工具。最后,每当输入数量大或少时,MSA-RVFL都表现出更高的性能,这使我们建议的方法比传统的ANN模型更具优势。
方法论:随机向量功能链接网络RVFL,飞蛾搜索算法
MSA
文献主要通过建议一种适用方法(MSA-RVFL)来简化缺失值的问题。
Multi-step ahead modelling of river water quality parameters using ensemble artificial intelligence-based approach
摘要
本研究采用三种基于人工智能(AI)的模型,即反向传播神经网络(BPNN)、自适应神经模糊推理系统(ANFIS)、支持向量机(SVM)和线性自回归积分移动平均(ARIMA)模型,以及简单平均集成(SAE)、加权平均集成(WAE)和神经网络集成(NNE)三种不同的集成技术,用于溶解氧(DO)的单步和多步提前建模。 印度亚穆纳河。在这种情况下,使用了中央污染控制委员会记录的三个不同站点的DO,生物需氧量(BOD),化学需氧量(COD),排放(Q),pH,氨(NH3),水温(WT)数据,即Hathnikund(SL1),Nizamuddin(SL2)和Udi(SL3)。使用决定系数(DC)和均方根误差(RMSE)确定模型的性能精度。单模型结果表明,ANFIS模型的性能精度优于其他7种模型,SL19和SL1的性能精度分别提高了2%和3%,而SL16的SVM模型性能优于其他模型,平均性能提高了14%。在集成技术中,结果表明,对于所有三个站点,NNE在验证阶段都可以将单个模型的平均性能提高<>%。这证明了NNE在DO的多步提前建模中的可靠性和鲁棒性,因为它在求解非线性过程方面具有良好的能力。
方法:BPNN、ANFIS、SVR 和 ARIMA
文献主要使用基于AI的集成技术在印度亚穆纳河上的三个不同站点开发作为重要WQ参数的DO的单步和多步预测模型。DO由不同的AI模型(BPNN,ANFIS和SVM)和传统的线性模型(ARIMA)预测。
Ensemble machine learning paradigms in hydrology: A review
摘要
最近,在各种工程领域(如水文学)中采用集成学习方法进行模拟和预测的趋势明显。可用于水文科学实施的集成技术的多样性导致了在实施中开发和利用不同的策略。本文探讨并提到了集成方法的进步,包括重采样集成方法(例如, bagging, boosting, and dagging))、模型平均和堆叠,即广义堆叠,在水文的不同应用领域。本文的主要水文主题涵盖地表水文学、河道水质、降雨径流、泥石流、河流结冰、泥沙输运、地下水、洪水、干旱建模与预报等主题。这项调查的一般结果表明,在水文学中使用集成策略绝对优于常规(个体)模型学习。此外,增压技术(例如boosting、AdaBoost 和extreme gradient boosting)在水文问题中的应用比bagging, stacking, and dagging方法更频繁、更成功。
总结
本周主要阅读了几篇水质预测的文献,这6篇文献主要是用了机器学习的方法对水质进行预测,了解了一些预测水质所使用的机器学习方法,这几篇文献提高预测能力的主要思路都是通过修改模型,然后对比修改后的模型与常见模型,发现修改后的模型性能有所提高。下周,主要找在深度学习方面的水质预测文献,总结未来能改进的研究方向。

















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









