







为了快速训练模型
Mini-batch 梯度下降法
把训练集分割为小一点的子训练集
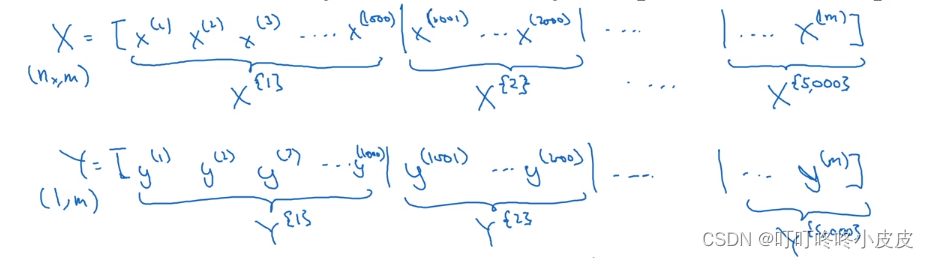
假设共5,000,000个样本,每1000个样本为一个batch,共有5000个batch,每个batch用花括号记为:X{1},X{2},X{3}… 尺寸为(n_x,1000)
之前是处理整个数据集,现在是单独处理单个的X{1},Y{1}…X{t},Y{t}
- batch 梯度下降法:指的就是前面讲的梯度下降法,每次需要同时处理整个训练集
- mini-batch梯度下降:每次处理的是单个的 mini-batch 训练子集
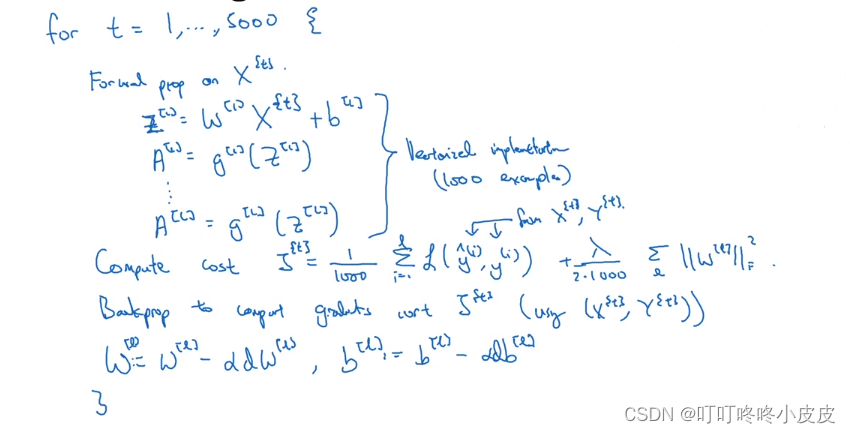
使用for循环,遍历5000个epoch,每次用X{t},并且记得进行向量化才能一次处理1000个样本。再加上正则化项来计算损失,然后进行反向传播,最后更新参数。
mini-batch梯度下降法:一次遍历(也就是一代epoch)可以做5000次梯度下降。
理解Mini-batch 梯度下降法
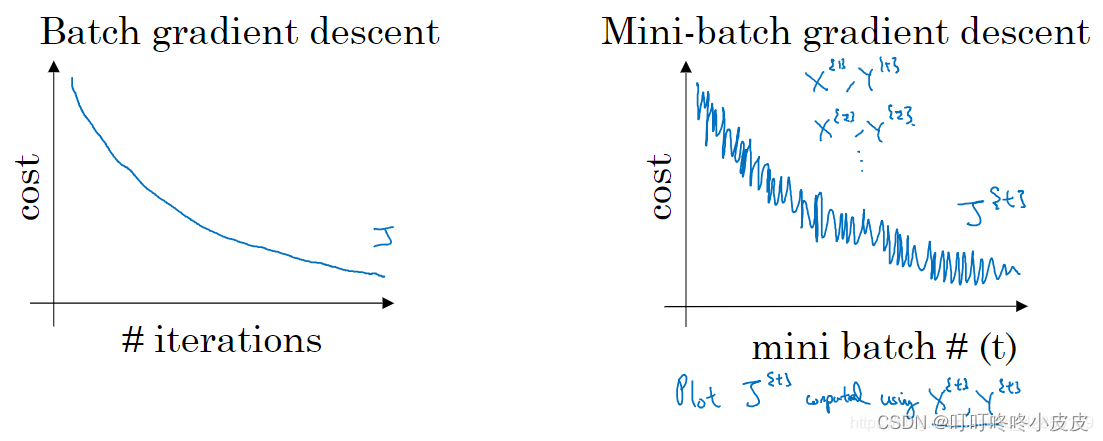
mini-batch 梯度下降,每次迭代后 cost 不一定是下降的,因为每次迭代都在训练不同的样本子集,但总体趋势应该是下降的。
选择mini-batch的尺寸
-
大小 = 1,每个样本都是一个mini-batch,成为随机梯度下降。优点:速度快。缺点:失去向量化优势,噪声大,方向不稳定
-
1 < 大小 < m,是合适的尺寸大小。优点:不需要每次处理整个训练集,更合适的学习率,具备向量化优势。
一般选用:64,128,256,512…这些2的次方 -
大小 = m,和之前一样,就是batch梯度下降法。优点:朝向目标不走弯路(噪声低,幅度大)。缺点:单次迭代时间长

指数加权平均
以伦敦气温为例,使用局部平均值来描述温度变化
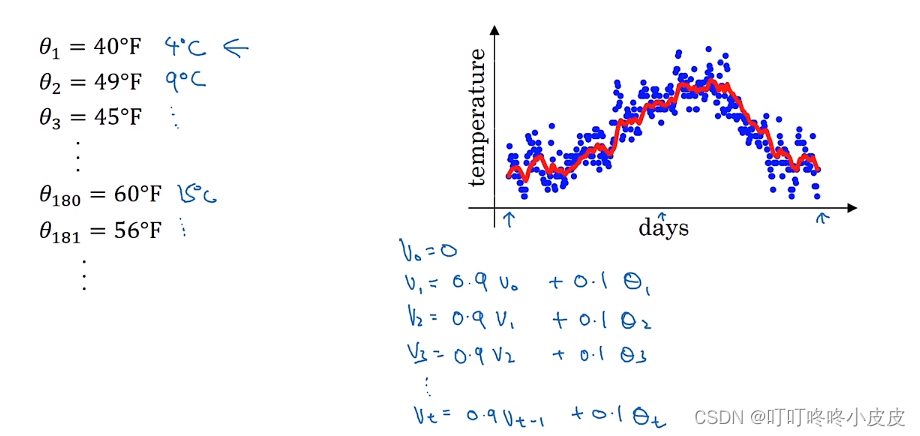
下面公式中,第一行是关键公式,v表示局部平均值,θt表示当天的温度。
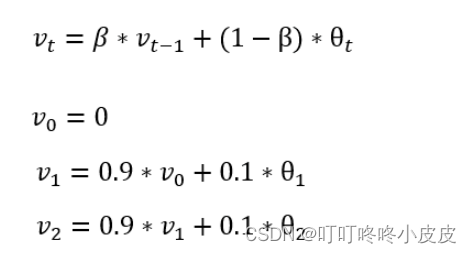
我们在伦敦气温例子中,将β设置为0.9,根据下图的公式,约等于求过去10天的平均气温。
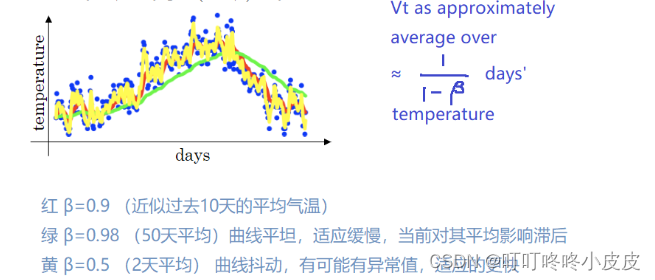
随着β值的增大,由于要平均的温度更多了,所以曲线会向右移动。
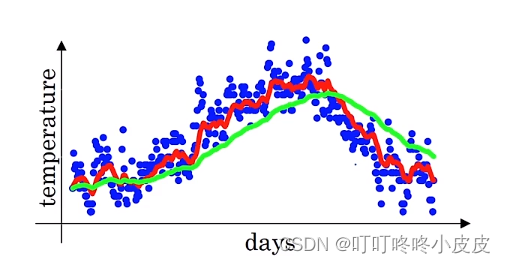
理解指数加权平均
首先达成一个共识,当权重小于1/e时,便不再考虑其影响。

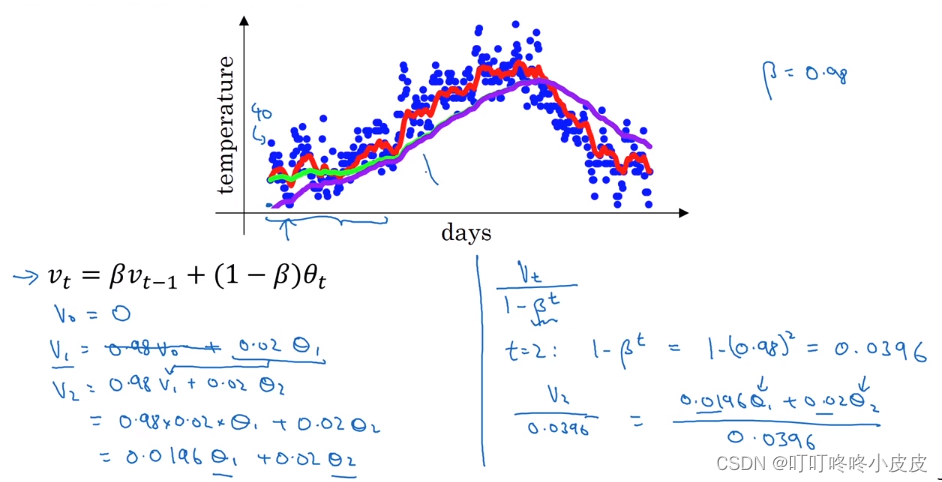
本张PPT中,我们知道v100展开式的结构,类似于上面两张图(上面是气温,下面是权重衰减)的乘积,其中权重图表示v为100时,权重为0.1,99天权重为0.1 x 0.9…,以第100天为例时间越早,权重越低,第90天的权重已经低到不用考虑影响。
我们选择β = 0.9,可知 ε = 0.1,得到权重为1/e时,(0.9)10 = 1/e ,所以平均了10天
如果你想要计算10天局部温度的平均值,你需要保存最近10的温度。而使用指数加权平均来计算局部平均值的时候,可以节省大量的空间,你只需要保存前一个加权平均值。相对于直接计算平均值而言,它的精确度没有那么高。
指数加权平均的偏差修正
由于v0初始化问题,导致最开始的几天会出现平均值远低于实际值的情况。但是,其实有时候,不太关注初始状态,所以也不太使用这个修正

动量momentum梯度下降法
通常的batch梯度下降中,为了防止偏离太多,所以学习率不能设置太大,因此学习并不快。

我们在梯度下降中使用加权平均,用“从碗里向碗底滚一颗球”来形似
Vdw = βVdw + (1 - β)Vdw
其中后面的项视为当前速度,因为 β<1(常用0.9),所以前面的项可以视为摩擦力。下面是循环中的代码:
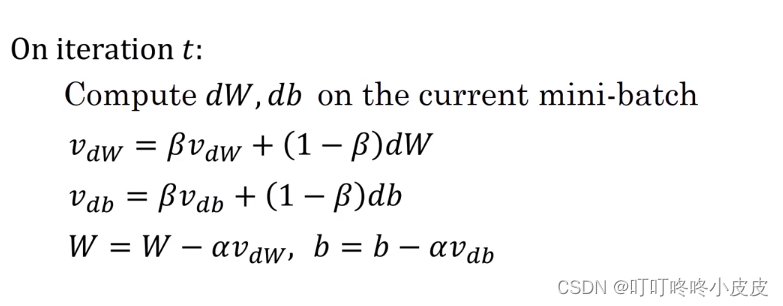
RMSprop算法
全称是 root mean square prop 算法,它也可以加速梯度下降。
这里用w和b较为形象的展示横轴和纵轴的期待更新速度,实际情况,我们需要调整的是W1,W2,W3…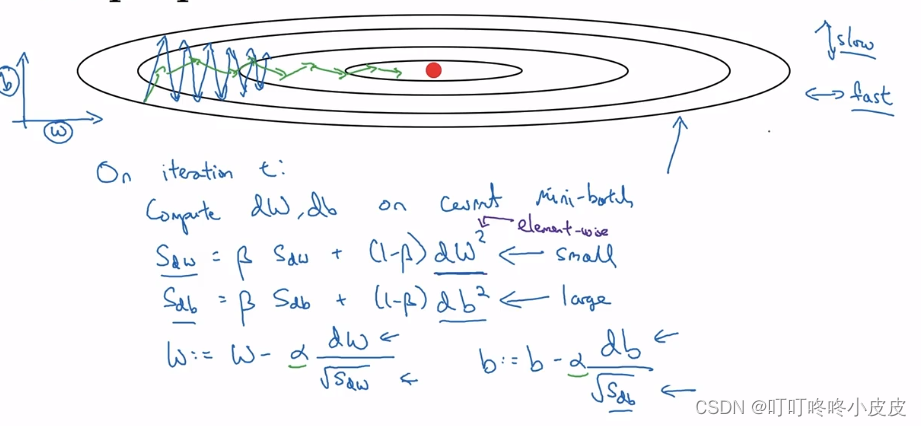
在t轮中,计算出mini-batch的dw和db后,使用加权平均,得到Sdw和Sdb,此外,希望dw更小,希望db更大,这样,以Sdw和Sdb为分母时,可以使w更新增快,b更新减慢
实际使用中的公式如下:
(分母添加epsilon,一般为ε = 10-8

RMSprop 跟 Momentum 有很相似的一点,可以消除梯度下降和mini-batch梯度下降中的摆动,并允许你使用一个更大的学习率,从而加快你的算法学习速度。
Adam算法
该方法结合了 Momentum 和 RMSprop两种更新参数的策略

以下是视频课的内容:
t循环中,计算好dw和db之后,分别用 Momentum 和 RMSprop计算加权值Vdw,Vdb,Sdw,Sdb,并进行偏差修正,最后用RMSprop进行更新
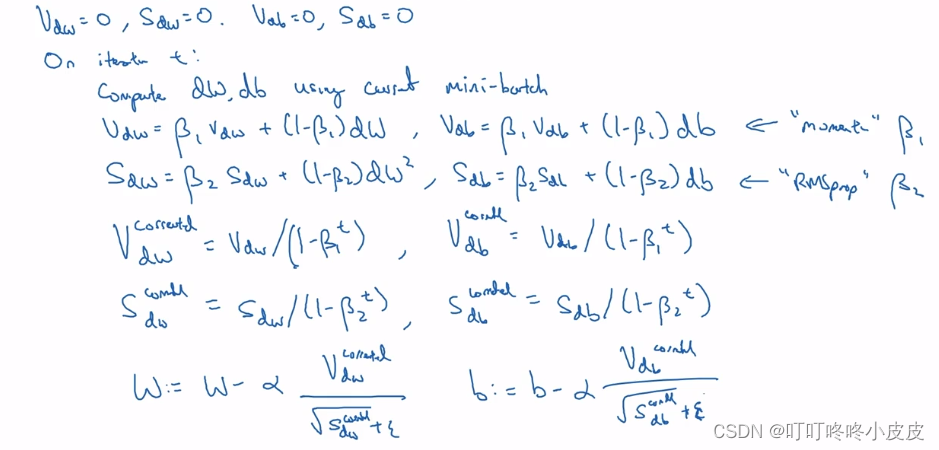
常用的超参数定值:

学习率衰减
如果使用固定学习率,在迭代次数较多时,收敛点附近会出现较大步伐。如果是衰减学习率,在收敛点附近步伐能小一点,最终收敛效果好。
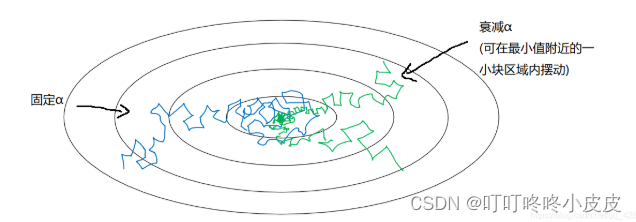
常用的学习率衰减公式:

局部最优问题
高维空间中,我们更可能遇到的是鞍点
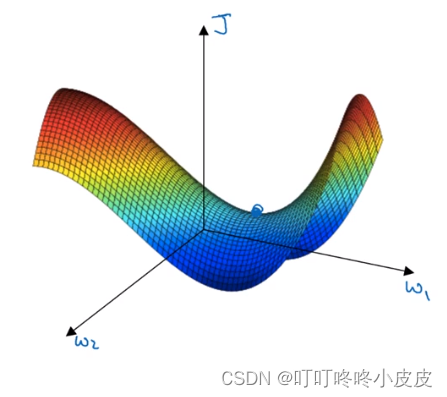
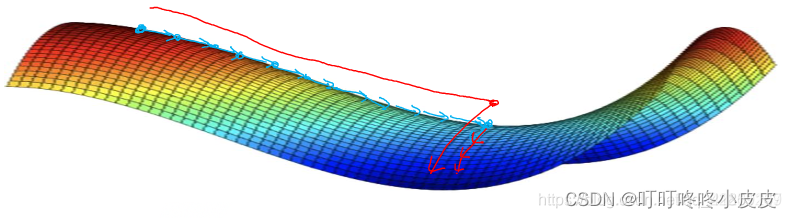
基本不会遇见局部最优问题,可能遇见的是平稳段减缓了学习速度,该区域梯度接近于 0 ,要很长时间才能走出去。Momentum 或 RMSprop,Adam 能够加快速度,让你尽早 走出平稳段。















 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









