






记录一下学习nvprof分析性能
实现一个二维卷积,并使用nvprof分析
卷积代码:
__global__
void conv(const float *src,const float *kernel,float *res,const int s_w,const int s_h,const int ker_size){
int col=blockIdx.x*blockDim.x+threadIdx.x;
int row=blockIdx.y*blockDim.y+threadIdx.y;
if(col<s_w-ker_size+1&&row<s_h-ker_size+1){
float sum=0;
for(int i=0;i<ker_size;i++){
for(int j=0;j<ker_size;j++){
sum+=src[(row+i)*s_w+(col+j)]*kernel[i*ker_size+j];
}
}
res[row*(s_w-ker_size+1)+col]=sum;
}
}
该卷积操作时最简单的卷积操作,没有实现padding,步长是1,没有使用共享内存优化。这个例子只是用来学习如何使用nvprof进行分析。
首先nvprof提供了很多指标来分析,其中主要是有三个:
achieved_occupancy:表示一个循环调度内sm上活跃的线程束与sm同时能够运行的最大线程束的比值。该指标越大,表示运行的warp越多,并行性越高。反之越小。
gld_thoughput:gld表示global load ,所以这个指标表示核函数的内存读取效率。也就是全局内存的读取的快慢。
gld_efficiency:这个表示全局加载效率,即被请求的全局加载吞吐量占所需的全局吞吐量的比值。其实,在加载数据时,可能并不是加载来的所有字节都是我们需要使用的,有的时候会出现带宽浪费,所以这个指标可以反映我们加载的数据中被用到的比例是否高。
为了检验不同线程配置对不同指标的影响,我们分别将线程块组织为(32,32)(16,32)(32,16)以及(16,16),来观察不同的线程配置带来的效率高低。该卷积操作使用的是3*3的卷积核,32*32的矩阵。使用平台位jetson nano。
(32,32)
Achieved Occupancy 0.448560
Global Load Throughput 107.62MB/s
Global Memory Load Efficiency 77.50%(16,32)
Achieved Occupancy 0.447311
Global Load Throughput 122.99MB/s
Global Memory Load Efficiency 68.38%(32,16)
Achieved Occupancy 0.444974
Global Load Throughput 108.49MB/s
Global Memory Load Efficiency 77.50% (16,16)
Achieved Occupancy 0.450525
Global Load Throughput 122.17MB/s
Global Memory Load Efficiency 68.38% 其实从上面四个对比很难看出造成他们之间的性能差距的因素是什么,但很容易看出的是,当block的最内层维度是32的倍数的时候是比较高效的,因为一个warp是32个线程,能够同时加载32个数据,更不容易造成带宽的浪费。
当然可以通过nvprof ./a.out来进行分析,这种方式能够直接得到内核函数的执行时间,直接看内核函数的执行时间就能够直接得到最优线程配置了。
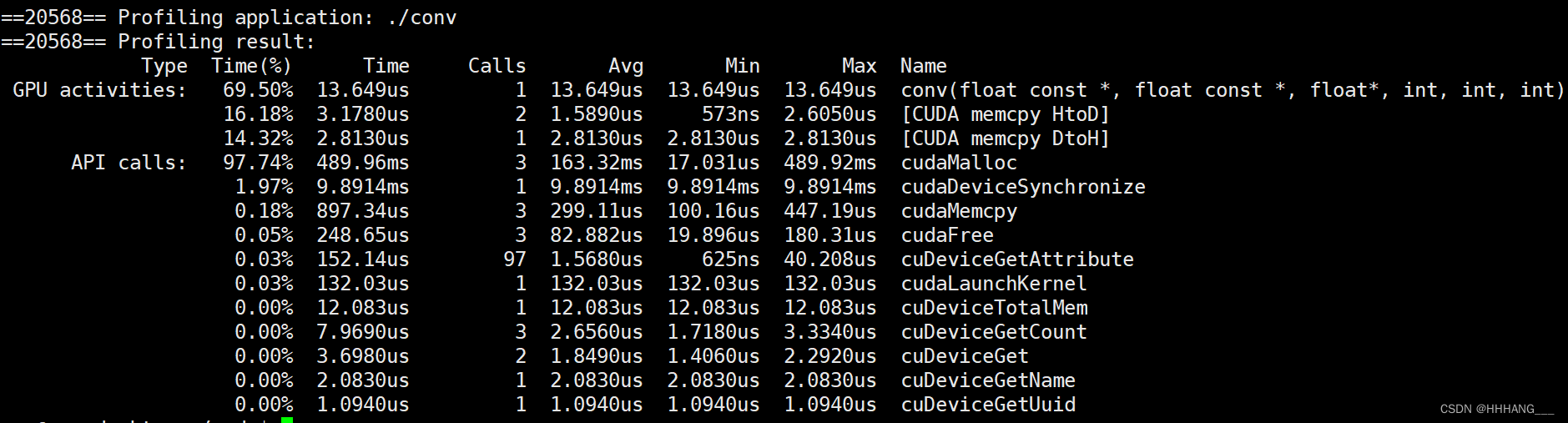
另外,nvprof提供了很多性能指标,具体查看参考链接。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









