






 本文详细探讨了如何通过优化CUDAGPU中的Reduce算子(如避免线程束分化、银行冲突和数据块展开)以及softmax实现(包括reduce_max、归一化和指数计算)来提高性能。通过使用共享内存、线程展开等技术,最终实现在处理特定规模数据时显著降低运行时间。
本文详细探讨了如何通过优化CUDAGPU中的Reduce算子(如避免线程束分化、银行冲突和数据块展开)以及softmax实现(包括reduce_max、归一化和指数计算)来提高性能。通过使用共享内存、线程展开等技术,最终实现在处理特定规模数据时显著降低运行时间。
一、Reduce算子
1.baseline
使用测试数据为1<<8量级的数组,使用线程块大小默认为256。
baseline实现主要思想是,让每一个线程去计算当前线程索引的数据和相邻的数据的和。具体实现如下:
__global__
void reduce_sum(float *input,float *output){
int tid=threadIdx.x;
int idx=blockIdx.x*blockDim.x+threadIdx.x;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx];
__syncthreads();
for(int i=1;i<blockDim.x;i*=2){
if(tid%(i*2)==0){
sdata[tid]+=sdata[tid+i];
}
__syncthreads();
}
if(tid==0){
output[blockIdx.x]=sdata[0];
}
}
运行时间为56.5us:
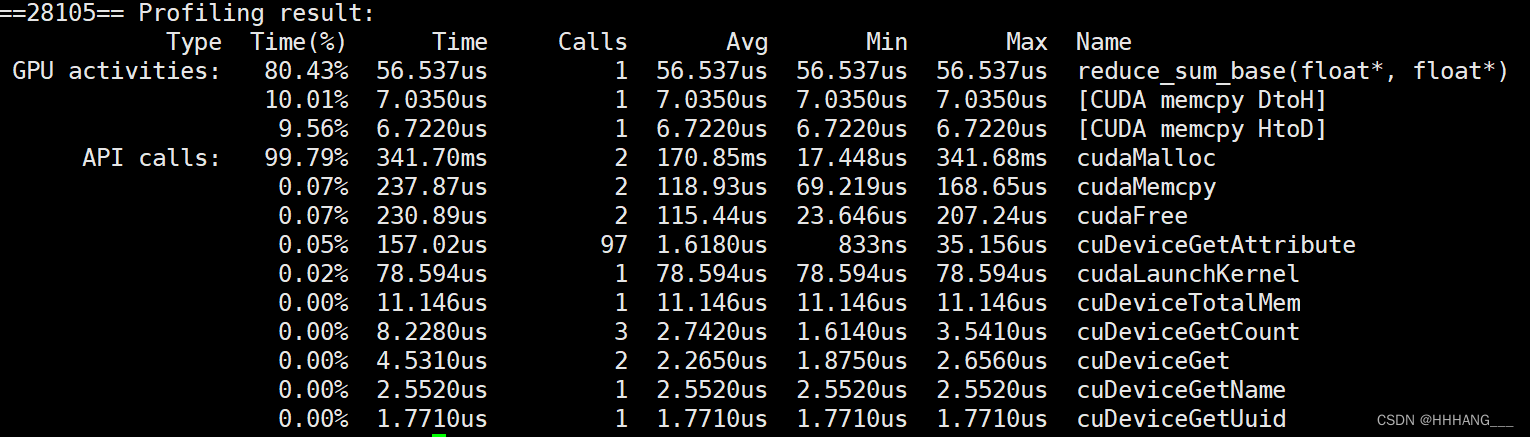
下面根据不同角度进行优化。
2.避免线程束分化
上述代码中仅仅使用了线程号为偶数的线程来进行计算,在每一个块内的所有奇数线程号都没有参与计算所以在一个warp内部的线程数分化非常严重。该问题主要出现在以下语句:
if(tid%(i*2)==0)
解决这个问题的一个有效方法是使用一个index来表示访问的数据,但是仍然使用连续的线程号来计算,具体修改语句如下:
index=2*i*tid
if(index<blockDim.x)
经过上述两个语句的修改,可以让连续的线程绑定到不连续的数据,这样做的话,和baseline处理数据的顺序和方法是一样的,但是每一轮使用的线程号都是连续的,有效避免了线程束分化的问题。
具体实现如下:
__global__
void reduce_sum(float *input,float *output){
int tid=threadIdx.x;
int idx=blockIdx.x*blockDim.x+threadIdx.x;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx];
__syncthreads();
for(int i=1;i<blockDim.x;i*=2){
int index=i*2*tid;
if(index<blockDim.x){
sdata[index]+=sdata[index+i];
}
__syncthreads();
}
if(tid==0){
output[blockIdx.x]=sdata[0];
}
}
运行时间为43.2us:
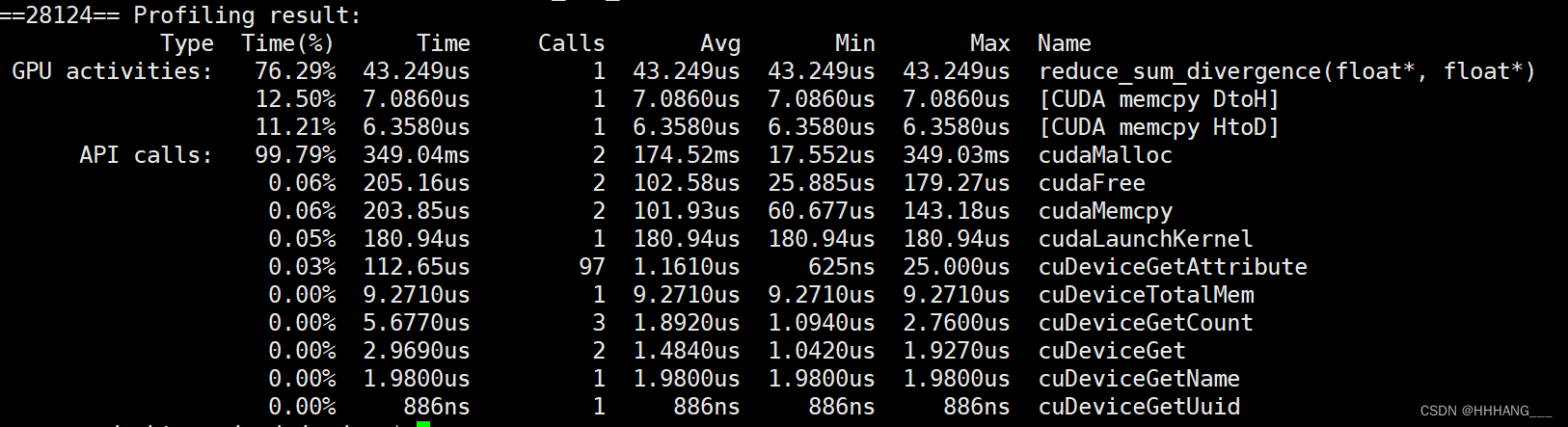
3.避免bank冲突
在上面实现来看,一个warp内有32个线程,每一个线程处理两个数据,那么总共就会是处理64个数据的求和,但是这样会造成bank冲突。
关注warp0中的线程0,第一轮会访问到sdata[0],sdata[1],而线程16会访问到sdata[32],sdata[33],sdata[0]和sdata[32]就会出现2路冲突。
在第二轮中,线程0会访问sdata[0],sdata[2],线程8会访问sdata[32],sdata[34],线程16会访问到sdata[64],sdata[66],线程32会访问到sdata[128],sdata[130],所以一个warp内,每一个bank会出现4路bank冲突。
解决这个问题的方法就是采用交错配对的方法进行归约。
这样交错配对的话,在一个warp内,如果共享内存是256的话,第一轮中的线程0访问到数据0和128,线程1访问1和129,线程21访问31和159,这样并没有bank冲突。
不管是在第几轮,warp内的数据在读取数据是刚好读取到共享内存当中的一行,所以不会产生bank冲突。
代码实现如下:
__global__
void reduce_sum(float *input,float *output){
int tid=threadIdx.x;
int idx=blockDim.x*blockIdx.x+threadIdx.x;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx];
__syncthreads();
int stride=blockDim.x/2;
while(stride>0){
if(tid<stride){
sdata[tid]+=sdata[tid+stride];
}
__syncthreads();
stride/=2;
}
if(tid==0){
output[blockIdx.x]=sdata[0];
}
}
运行时间为38.8us:
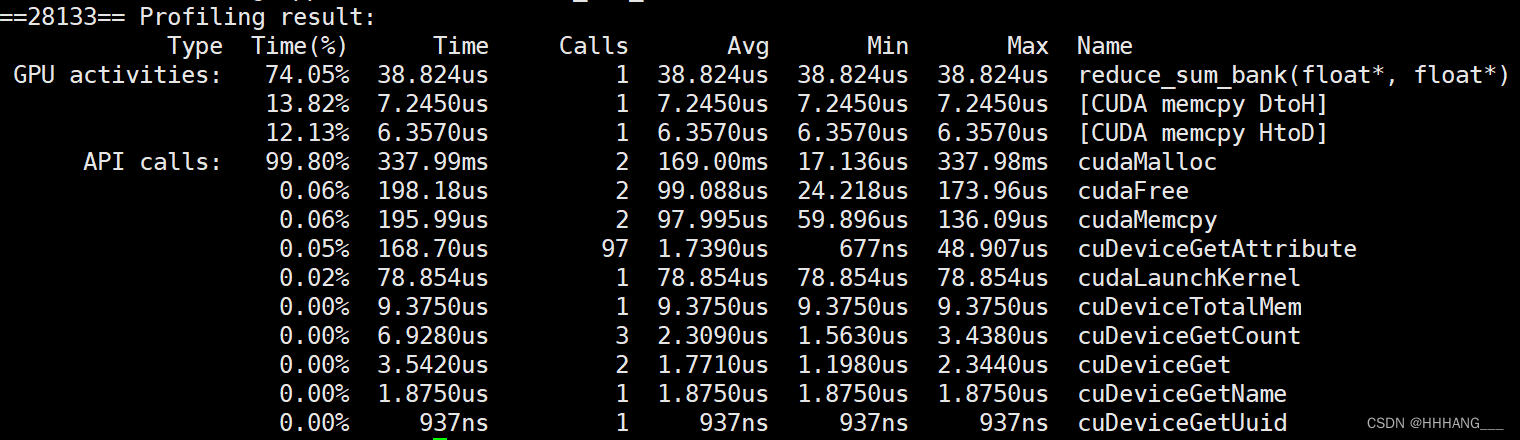
4.数据块展开优化
在将全局内存上的数据传输到共享内存上时,每一个线程都是指进行了读取指令,一共使用了256个线程。但在后面归约的时候,每一轮归约都是只使用了一半的线程(128,64,32,16,...)。所以线程利用率并不高。
可以在共享内存数据传输的时候,使用块内的256个线程处理进行传输以外,再将相邻两个块的数据进行对应求和,这样在后面归约的时候,块的数量是减半了的,能够提高效率。
具体代码如下:
__global__
void reduce_sum_idle(float *input,float *output){
int tid=threadIdx.x;
int idx=threadIdx.x+blockIdx.x*blockDim.x*2;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx]+input[idx+blockDim.x];
__syncthreads();
for(int stride=blockDim.x/2;stride>0;stride>>=1){
if(tid<stride){
sdata[tid]+=sdata[tid+stride];
}
__syncthreads();
}
if(tid==0){
output[blockIdx.x]=sdata[0];
}
}
运行时间为39.2us:
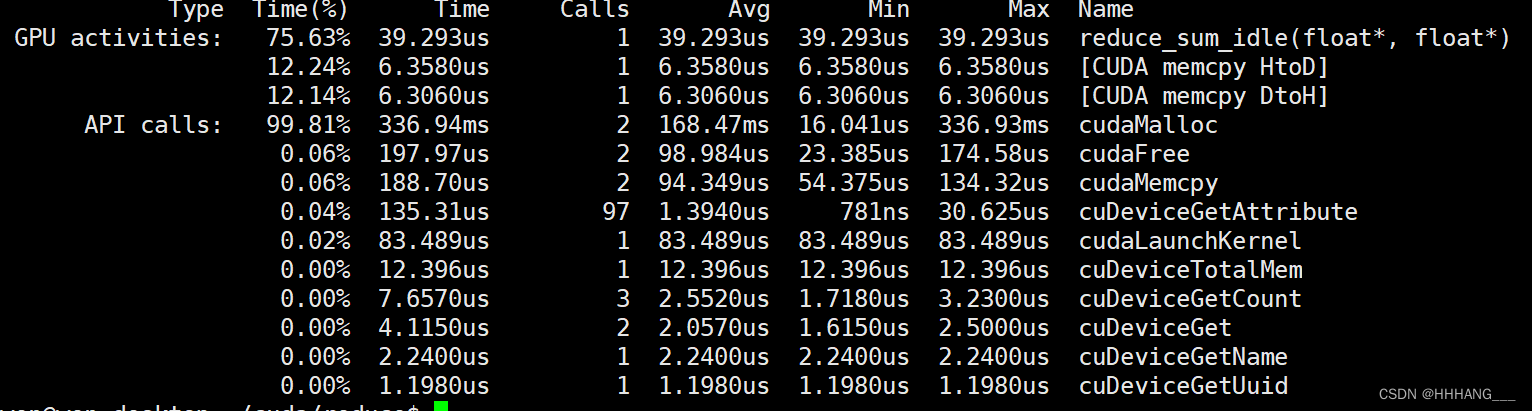
5.线程展开优化
除了上述的将数据进行展开以外,还可以对线程进行展开。我们知道,在结束一个warp内的指令时,不管该warp内部使用到的线程有多少,都会进行一个warp内的一个同步操作,所以当使用的线程等于一个warp的时候,可以使用线程展开来避免隐式的同步耗时。
具体实现如下:
__global__
void reduce_sum_idle(float *input,float *output){
int tid=threadIdx.x;
int idx=threadIdx.x+blockIdx.x*blockDim.x*2;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx]+input[idx+blockDim.x];
__syncthreads();
for(int stride=blockDim.x/2;stride>32;stride>>=1){
if(tid<stride){
sdata[tid]+=sdata[tid+stride];
}
__syncthreads();
}
if(tid<32){
volatile float *vmem=sdata;
vmem[tid]+=vmem[tid+32];
vmem[tid]+=vmem[tid+16];
vmem[tid]+=vmem[tid+8];
vmem[tid]+=vmem[tid+4];
vmem[tid]+=vmem[tid+2];
vmem[tid]+=vmem[tid+1];
}
if(tid==0){
output[blockIdx.x]=sdata[0];
}
}
运行时间为28.1us:
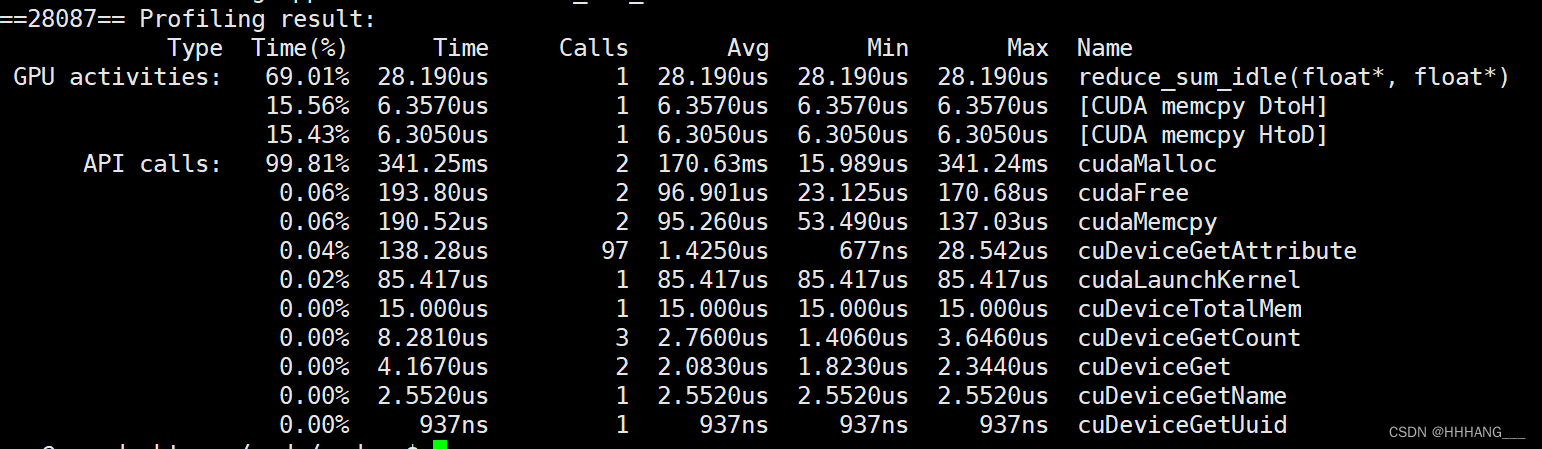
二、softmax实现
首先,softmax算子主要分为三个步骤:
(1)使用reduce_max求解出input中的最大值max_val;
(2)使用max_val对input中的元素进行归一化(防止计算指数以及指数和时数据溢出),再计算每一个元素的指数值;
(3)最后计算每一个元素对应指数的指数占比(概率);
具体涉及三个算子,reduce_max计算最大值,get_exp进行归一化和求解指数,reduce_sum计算指数和。具体代码实现如下:
__global__
void reduce_max(float *input,float *output){
int tid=threadIdx.x;
int idx=threadIdx.x+blockIdx.x*blockDim.x;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx];
__syncthreads();
for(int stride=blockDim.x/2;stride>32;stride>>=1){
if(tid<stride){
sdata[tid]=max(sdata[tid],sdata[tid+stride]);
}
__syncthreads();
}
if(tid<32){
volatile float *vmem=sdata;
vmem[tid]=max(vmem[tid],vmem[tid+32]);
vmem[tid]=max(vmem[tid],vmem[tid+16]);
vmem[tid]=max(vmem[tid],vmem[tid+8]);
vmem[tid]=max(vmem[tid],vmem[tid+4]);
vmem[tid]=max(vmem[tid],vmem[tid+2]);
vmem[tid]=max(vmem[tid],vmem[tid+1]);
}
if(tid==0){
output[blockIdx.x]=sdata[0];
printf("max_val=%f\n",sdata[0]);
}
}
__global__
void get_exp(float* input,const float *max_val){
int idx=threadIdx.x+blockIdx.x*blockDim.x;
if(idx<(IN_SIZE)){
float tmp=input[idx]/(*max_val);
tmp=__expf(tmp);
input[idx]=tmp;
}
__syncthreads();
}
__global__
void reduce_sum(const float *input,float *sum){
int tid=threadIdx.x;
int idx=threadIdx.x+blockIdx.x*blockDim.x;
__shared__ float sdata[BLOCK_SIZE];
sdata[tid]=input[idx];
__syncthreads();
for(int stride=blockDim.x/2;stride>32;stride>>=1){
if(tid<stride){
sdata[tid]+=sdata[tid+stride];
}
__syncthreads();
}
if(tid<32){
volatile float *vmem=sdata;
vmem[tid]+=vmem[tid+32];
vmem[tid]+=vmem[tid+16];
vmem[tid]+=vmem[tid+8];
vmem[tid]+=vmem[tid+4];
vmem[tid]+=vmem[tid+2];
vmem[tid]+=vmem[tid+1];
}
if(tid==0){
*sum=sdata[0];
}
}
对于两个reduce算子都使用了共享内存,避免bank冲突以及线程展开技术进行优化。
最后在主机端进行测试:
void kernel(float *input){
float *d_input,*d_max_val,*d_sum;
cudaMalloc(&d_input,sizeof(float)*(IN_SIZE));
cudaMalloc(&d_max_val,sizeof(float)*1);
cudaMalloc(&d_sum,sizeof(float)*1);
dim3 block(BLOCK_SIZE,1);
dim3 grid(((IN_SIZE)+BLOCK_SIZE-1)/BLOCK_SIZE);
cudaMemcpy(d_input,input,sizeof(float)*(IN_SIZE),cudaMemcpyHostToDevice);
reduce_max<<<grid,block>>>(d_input,d_max_val);
cudaDeviceSynchronize();
get_exp<<<grid,block>>>(d_input,d_max_val);
cudaDeviceSynchronize();
reduce_sum<<<grid,block>>>(d_input,d_sum);
cudaDeviceSynchronize();
softmax<<<grid,block>>>(d_input,d_sum);
cudaDeviceSynchronize();
cudaMemcpy(input,d_input,sizeof(float)*(IN_SIZE),cudaMemcpyDeviceToHost);
print_array(input,(IN_SIZE));
cudaFree(d_input);
cudaFree(d_max_val);
cudaFree(d_sum);
}
测试数据为了方便,进使用了刚好一个块的数据进行测试(块大小为256),具体运行时间如下:
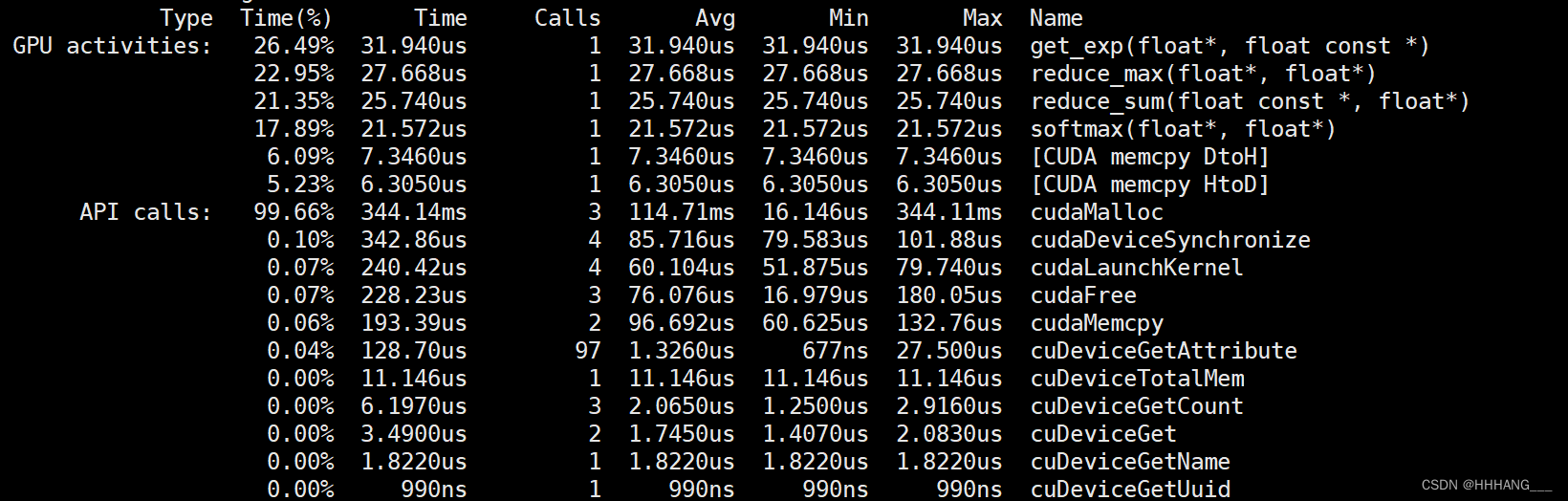















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









