







 论文提出了一种名为CREA-ICL的方法,通过跨语言检索和共享嵌入空间,利用高资源语言的样本帮助低资源语言模型(如孟加拉语)改善In-ContextLearning性能。通过计算相似度并检索相关文档,提供exemplars来指导LLMs处理低资源语言任务。
论文提出了一种名为CREA-ICL的方法,通过跨语言检索和共享嵌入空间,利用高资源语言的样本帮助低资源语言模型(如孟加拉语)改善In-ContextLearning性能。通过计算相似度并检索相关文档,提供exemplars来指导LLMs处理低资源语言任务。
论文:From Classification to Generation: Insights into Crosslingual Retrieval Augmented ICL
⭐⭐⭐⭐
NeurIPS 2023, arXiv:2311.06595
文章目录
- 论文速读
- 总结
论文速读
有很多外国语言因为其语言复杂性、标记数据集的缺乏以及数据重复等问题,LLM 在这些低资源语言上的 instruction-following 的能力会变差,进而限制它们的 In-Context Learning(ICL)的表现。
为了解决低资源语言(如孟加拉语)在大型语言模型(LLMs)的上下文学习(ICL)性能受限的问题,本文提出了跨语言检索增强的上下文学习(CREA-ICL),其思路是:对于一个低资源语言的 input test q q q,使用 embedding encoder 将其映射到一个 shared embedding space 中,然后利用 cosine similarity 计算它与高资源语言的 corpus 的文档相似度,从中检索出 top-k 个文档,然后利用 prompt 把这些高资源语言作为 ICL 的 exemplars,实现让 LLM 去解决 input test 的问题。
框架图示如下:
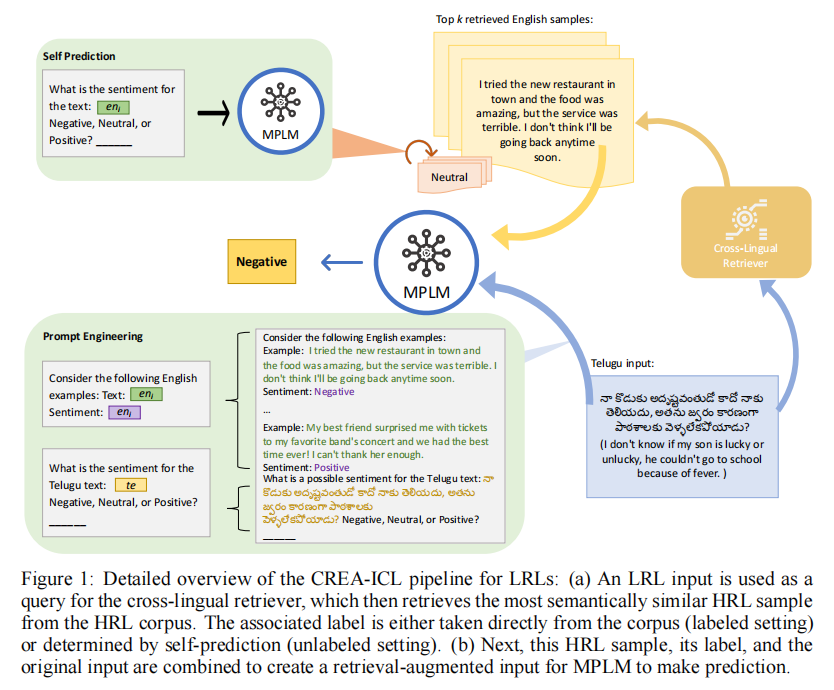
上图是一个对孟加拉语的问题做情感分类的示例。Telugu input 是一个孟加拉语表述的文本,首先会通过 Cross-Lingual Retriever 从高资源语言的 corpus 中检索出 k 个最相关的英文 samples,根据 sample 是否存在 label:
- 如果有 label,那就使用这个 label
- 如果没有 label,那就使用 self-prediction 让 LLM 生成一个 label
然后把 (English sample, label) 作为 ICL 的 exemplars,通过 prompt 让 LLM 去解决 Telugu input 文本的情感分类问题。
总结
论文提出的方法的思路都在这个图中了,看懂这个图就可以看懂这个方法了。
这篇论文讨论了一个常见问题:低资源语言该如何利用好 LLM 的各项能力。因为中文和英文的语料较多,导致了 LLM 能够表现不错,但对于很多小语种来说,资料的缺乏可能会让 LLM 在某些能力上出现缺失,通过跨语言检索也许能解决其中的一些问题。















 2260
2260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









