







论文:Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
⭐⭐⭐⭐⭐
ICLR 2018
Dataset: github.com/salesforce/WikiSQL
Code:Seq2SQL 模型实现
一、论文速读
本文提出了 Text2SQL 方向的一个经典数据集 —— WikiSQL,同时提出了一个模型 Seq2SQL,用于把自然语言问句转为 SQL。
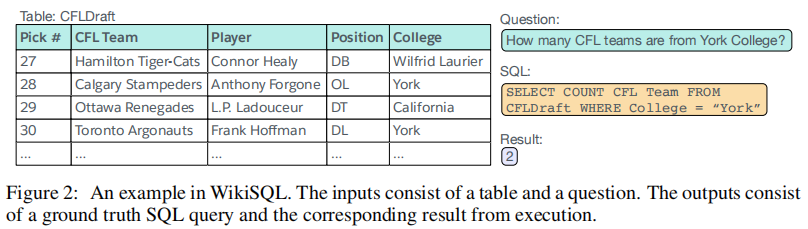
WikiSQL 数据集中的 SQL 形式较为简单,不包括排序(order by)、分组(group by)、子查询等其他复杂操作。根据这种简单的形式,本文的 Seq2SQL 模型针对一个 table 和一个 question,预测出 SELECT 部分、Aggregation 部分和 WHERE 部分,并将其构造成一个 SQL 语句。下图展示了一个示例:
Seq2SQL 基于 Augmented Pointer Network 来实现,下面先介绍一下这个网络结构,然后再介绍基于此来实现 Seq2SQL 模型。
二、Augmented Pointer Network(增广指针网络)
Augmented Pointer Network 能够从输入序列中选择 token 并逐个 token 生成输出序列。
对于一个 example,输入序列 x x x 是由"table 的列名"、“SQL 词汇表”、"question"三者用特殊分隔符拼接起来的序列:

比如在前面图片的示例中,列名 token 包括 “Pick”、“#”、“CFL” 等等组成,question token 包括 “How”、“many”、“CFL” 等等,SQL 词汇表包括 “SELECT”、“WHERE”、“COUNT”、“MIN” 等等。
这个网络首先对 input sequence x x x 做 word embedding,然后输入给两层的 Bi-LSTM 做编码得到 h e n c h^{enc} henc,其中 input 的第 i 个 token 的编码是 h t e n c h_t^{enc} htenc,这样每个 token 经过编码都变成了一个 vector。
解码器部分使用双层的单向 LSTM,每一步生成一个 token。具体生成方式是:使用上一步生成的 token y s − 1 y_{s-1} ys−1 作为输入,输出一个 state g s g_s gs,然后拿 g s g_s gs 与 input sequence 的每个位置 t 的 h t h_t ht 做计算得到一个标量的注意力分数 α s , t p t r \alpha_{s,t}^{ptr} αs,tptr,选择分数最高的对应的输入 token 作为生成的下一个 token。其中注意力分数的计算公式如下:
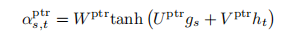
三、Seq2SQL 模型
虽然可以直接训练 Augmented Pointer Network 让他生成 SQL 序列作为结果,但是这没有利用 SQL 本身固有的结构。本论文固定 SQL 的结构由三部分组成:SELECT、WHERE 和 Aggregation,并训练三个组件来分别生成这三部分:
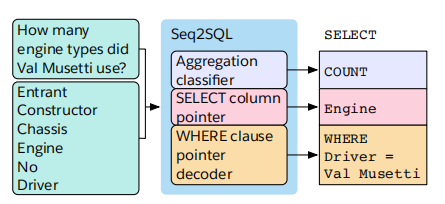
3.1 Aggregation Classifier
他就是一个 classifier,最终输出一个 softmax 计算后的分布,从 NULL、MAX、MIN、COUNT、SUM、AVG 中做分类,NULL 表示没有 aggregation 操作。其 loss
L
a
g
g
L^{agg}
Lagg 使用 cross entropy 来计算。
比如,“How many” 类型的 question 往往被分类为 COUNT。
3.2 SELECT column prediction
SELECT column prediction 是一个匹配问题,这里使用指针网络的思想来解决:输入列名序列和 question 的拼接,输出与 question 最匹配的一个 column。
首先使用 LSTM 对每一列进行编码,column j j j 对应一个 vector e j c e_j^c ejc,然后对 input x x x 编码出一个 vector κ s e l \kappa^{sel} κsel,然后使用 MLP,计算 input representation κ s e l \kappa^{sel} κsel 与每一个 column j 的分数 α j s e l \alpha^{sel}_{j} αjsel,之后使用 softmax 对分数进行归一化:
- 训练时,使用交叉熵损失 L s e l L^{sel} Lsel 来训练该模块
- 预测时,选分数最大的 column 作为预测结果
对于输入 x x x 编码为 input representation 和计算分数的详细信息可以参考论文和代码实现
3.3 WHERE Clause
这里使用类似于 Augmented Pointer Network 的 pointer decoder 来训练这一模块。但是使用 cross entropy 有一个限制:两个 WHERE 条件可以被交换并产生相同结果。但两个顺序不同的 WHERE 会被 cross entropy 错误地惩罚,比如 year>18 and male=1 和 male=1 and year>18 是等价的,但由于 cross entropy 是精确匹配 tokens,导致这个结果会被计算损失。
这里使用强化学习(RL)来训练, q ( y ) q(y) q(y) 是生成的查询, q g q_g qg 是真实查询,奖励函数的定义如下:

并根据此奖励函数计算出 loss L w h e L^{whe} Lwhe。
3.4 Seq2SQL 的训练
设置一个混合损失函数 L = L a g g + L s e l + L w h e L = L^{agg} + L^{sel} + L^{whe} L=Lagg+Lsel+Lwhe,并使用梯度下降来最小化该 loss 从而训练模型。
四、WikiSQL 数据集
该文更重要的一个贡献是提供了一个 WikiSQL 数据集,包含 80654 条样本和 24241 个 schema。这些数据被随机划分为 train、dev 和 test 三个 split。
下面是一个 example:
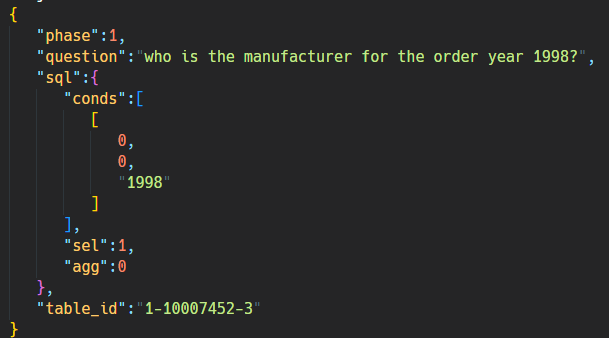
解释如下:
phase: the phase in which the dataset was collected. We collected WikiSQL in two phases.question: the natural language question written by the worker.table_id: the ID of the table to which this question is addressed.sql: the SQL query corresponding to the question. This has the following subfields:
sel: the numerical index of the column that is being selected. You can find the actual column from the table.agg: the numerical index of the aggregation operator that is being used. You can find the actual operator fromQuery.agg_opsinlib/query.py.conds: a list of triplets(column_index, operator_index, condition)where:
column_index: the numerical index of the condition column that is being used. You can find the actual column from the table.operator_index: the numerical index of the condition operator that is being used. You can find the actual operator fromQuery.cond_opsinlib/query.py.condition: the comparison value for the condition, in eitherstringorfloattype.
同时还给出了每个 table 的 schema 和数据部分。
五、评估指标
- N N N:数据集的样本总数
- N e x N_{ex} Nex:运行生成的 SQL 后,得到正确结果的样本数
- N l f N_{lf} Nlf:生成的 SQL 与 ground-truth SQL 字符串完全精确匹配的样本数
由此提出两个指标:
- A C C e x = N e x / N ACC_{ex} = N_{ex} / N ACCex=Nex/N:执行精度指标,如果生成的 SQL 与 ground-truth SQL 的执行结果相同,那就算作正确。存在一个缺点:如果构造一个错误的 SQL 但执行结果正确,依然被算作正确
- A C C l f = N l f / N ACC_{lf} = N_{lf} / N ACClf=Nlf/N:逻辑形式的精确指标,如果生成的 SQL 与 ground-truth SQL 完全匹配,才被算作正确。存在一个缺点:两个等价但写法不同的 SQL 会被算作错误
六、总结
这篇论文给出了一个 WikiSQL 数据集,并提出了 Text2SQL 的一个解决方案以及评价指标。
但是很明显,该方案存在不少缺点,之后的方案会继续改进。















 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









