







一、项目背景
目的:通过分析销售数据可以帮助商家了解在线销售业务的消费情况,进而分析顾客消费数据来分析顾客的消费行为和顾客特征,更好的为用户推荐相匹配的商品。
工具:Python、PowerBi
数据来源:https://www.heywhale.com/mw/project/60ceb85d056f570017c0ae42/dataset
字段说明:
event_time -购买时间
order_id -订单编号
product_id -产品编号
category_id -产品的类别ID
category_code -产品的类别分类法(代码名称)
brand -品牌名称
price -产品价格
user_id -用户ID
一、数据处理
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Line,Bar,Pie,Grid
#导入数据
df=pd.read_csv('电子产品销售分析.csv')
df.info()
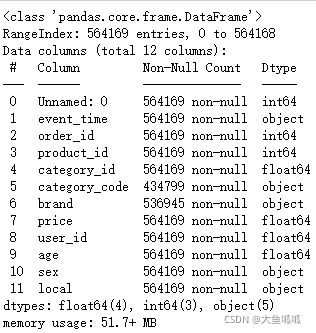
#删掉Unnamed: 0列
df.drop(['Unnamed: 0'],axis=1,inplace= True)
#查看缺失值
df.isnull().sum()
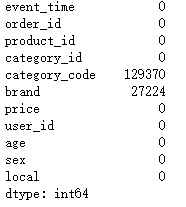
#有两列中有数据缺失值,两列缺失值可由missing填充
df.fillna('missing',inplace=True)
#时间处理
#将1970年替换成2020年
df['event_time'] = df['event_time'].str.replace('1970','2020')
df['event_time'] = pd.to_datetime(df['event_time'].str[:19],format="%Y-%m-%d %H:%M:%S")
df['Month'] = df['event_time'].dt.month
df['Dayofweek']=df['event_time'].dt.dayofweek
df['hour'] = df['event_time'].dt.hour
#删除重复值
df = df.drop_duplicates()
#去掉price为0的记录
#len(df[df['price'] == 0])为0的有39条数据,对整体影响不大,可以去掉
df=df[df.price!=0]
二、时间行为分析
月订单数量、消费人数、销售额
order_m=df.groupby('Month')['order_id'].nunique()
user_m=df.groupby('Month')['user_id'].nunique()
sale_m=df.groupby('Month')['price'].sum()
index_m=['{}月'.format(i) for i in range(1, 12)]
line1=(
Line()
.add_xaxis(index_m)
.add_yaxis('月订单数',order_m.values.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title='月订单数'),legend_opts=opts.LegendOpts(pos_left='10%'))
)
line2=(
Line()
.add_xaxis(index_m)
.add_yaxis('月独立用户数',user_m.values.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title='月独立用户数', pos_left='35%'),legend_opts=opts.LegendOpts(pos_left='50%'))
)
line3=(
Line()
.add_xaxis(index_m)
.add_yaxis('月销售额',sale_m.values.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title='月销售额', pos_left='70%'),legend_opts=opts.LegendOpts(pos_left='80%'))
)
grid1 = (
Grid()
.add(line1, grid_opts=opts.GridOpts(pos_right='65%'))
.add(line2, grid_opts=opts.GridOpts(pos_left='40%',pos_right='35%'))
.add(line3, grid_opts=opts.GridOpts(pos_left='70%'))
)
grid1.render_notebook()
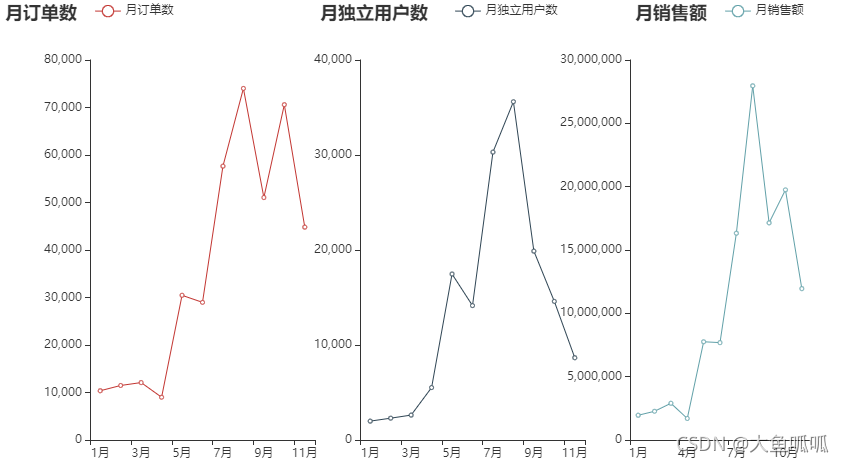
店铺5月到8月的销售额上升,8月后的销量下降,主要是独立用户数的下降导致。
与同期市场相比,店铺销量有明显的背离,如果5月到8月不是活动引流导致的销量变化,需要马上复盘8月后的下跌问题。
时订单数量、销售额
order_h=df.groupby('hour')['order_id'].nunique()
sale_h=df.groupby('hour')['price'].sum()
index_h=['{}时'.format(i) for i in range(0, 23)]
line4=(
Line()
.add_xaxis(index_h)
.add_yaxis('时订单数',order_h.values.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(yaxis_opts=opts.AxisOpts(name = '订单数'))
.extend_axis(yaxis=opts.AxisOpts(name='销售额',position='right'))
)
bar1=(
Bar()
.add_xaxis(index_h)
.add_yaxis('时销售额',sale_h.values.tolist(), label_opts=opts.LabelOpts(is_show=False),yaxis_index=1)
)
line4.overlap(bar1)
line4.render_notebook()
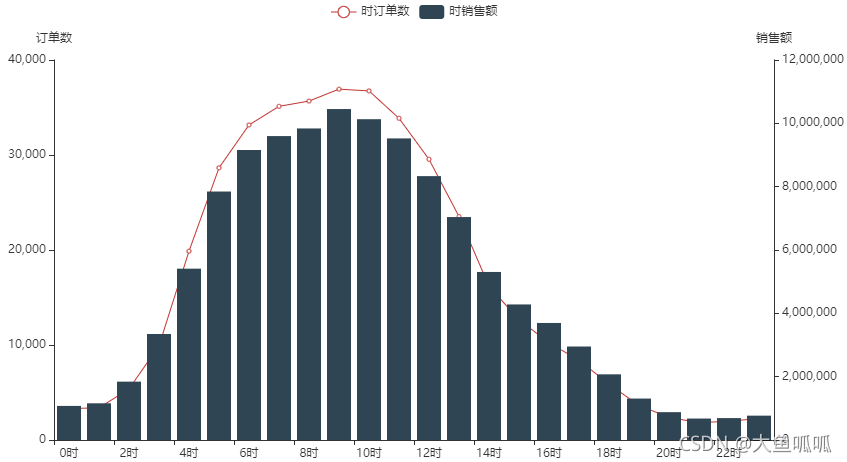
在5-13点之间出现销售高峰,顾客偏向于在早晨到中午的时间段内下单。
周订单数量、销售额
order_w=df.groupby('Dayofweek')['order_id'].nunique()
sale_w=df.groupby('Dayofweek')['price'].sum()
index_w=['周一','周二','周三','周四','周五','周六','周日']
line5=(
Line()
.add_xaxis(index_w)
.add_yaxis('周订单数',order_w.values.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(yaxis_opts=opts.AxisOpts(name = '订单数'))
.extend_axis(yaxis=opts.AxisOpts(name='销售额',position='right'))
)
bar2=(
Bar()
.add_xaxis(index_w)
.add_yaxis('周销售额',sale_w.values.tolist(), label_opts=opts.LabelOpts(is_show=False),yaxis_index=1)
)
line5.overlap(bar2)
line5.render_notebook()
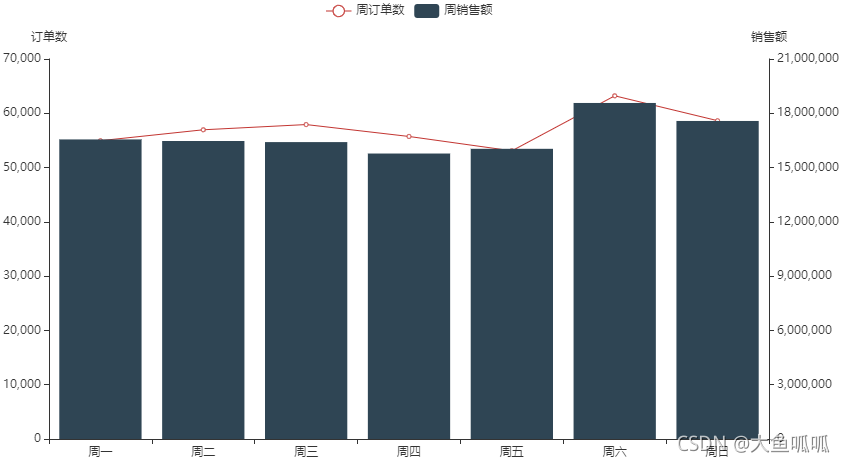
周一到周五订单数差别不大,周六是订单数量最高,周日次之,用户消费行为主要集中在周末。
三、用户行为分析
性别比例
df_sex=df.groupby('sex').agg({'user_id':['nunique'],'price':['sum']})
df_sex.columns = df_sex.columns.to_flat_index()
df_sex=df_sex.rename(columns={('user_id','nunique'):'独立用户数',('price','sum'):'销售额'})
df_sex['人均销售额']=(df_sex['销售额']/df_sex['独立用户数']).apply(lambda x:'%.2f' % x)
pie1 = (
Pie()
.add('',[list(z) for z in zip(df_sex.index.tolist(), df_sex.独立用户数.tolist())])
.set_global_opts(title_opts=opts.TitleOpts(title='性别比例'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie1.render_notebook()
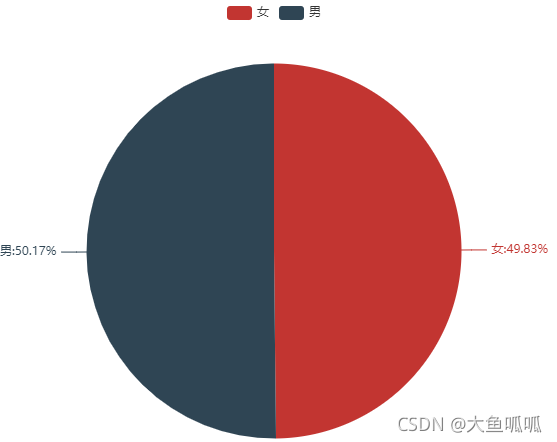
用户男女占比接近。
各年龄段情况
bins = [10,20,30,40,50]
df['age_group'] = pd.cut(df['age'],bins,labels = ['10-20','20-30','30-40','40-50'])
age_df=df.groupby('age_group').agg({'order_id':['nunique'],'user_id':['nunique'],'price':['sum']})
age_df.columns = age_df.columns.to_flat_index()
age_df=age_df.rename(columns={('order_id','nunique'):'订单数',('user_id','nunique'):'独立用户数',('price','sum'):'销售额'})
age_df['人均订单']=(age_df['订单数']/age_df['独立用户数']).apply(lambda x:'%.2f' % x)
age_df['每单均价']=(age_df['销售额']/age_df['订单数']).apply(lambda x:'%.2f' % x)
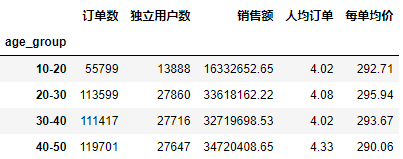
age_df
pie2 = (
Pie()
.add('',[list(z) for z in zip(age_df.index.tolist(), age_df.独立用户数.tolist())])
.set_global_opts(title_opts=opts.TitleOpts(title='各年龄段占比'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie2.render_notebook()
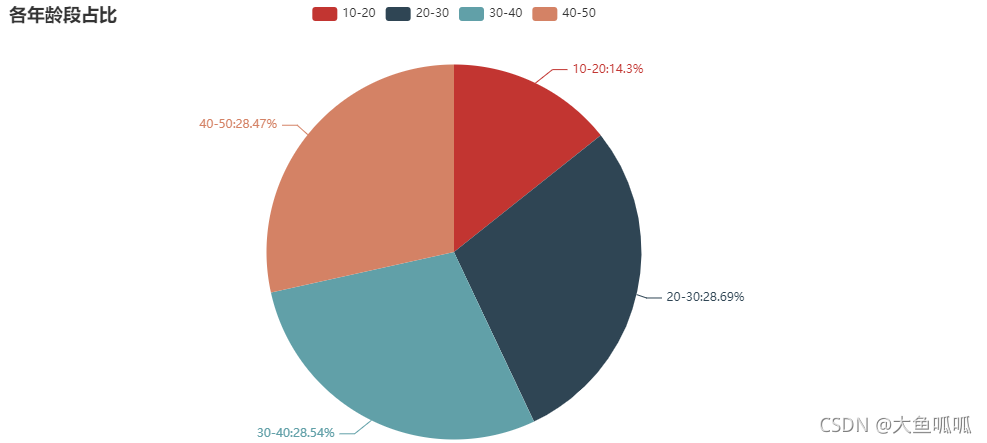
年龄集中在20-50,20-50年龄段的用户占比差距不大。
line6=(
Line()
.add_xaxis(age_df.index.tolist())
.add_yaxis('订单数',age_df.订单数.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(yaxis_opts=opts.AxisOpts(name = '订单数',min_=50000,max_=120000))
.extend_axis(yaxis=opts.AxisOpts(name='销售额',min_=16000000,max_=35000000,position='right'))
)
bar3=(
Bar()
.add_xaxis(age_df.index.tolist())
.add_yaxis('销售额',age_df.销售额.tolist(), label_opts=opts.LabelOpts(is_show=False),yaxis_index=1)
)
line6.overlap(bar3)
line6.render_notebook()
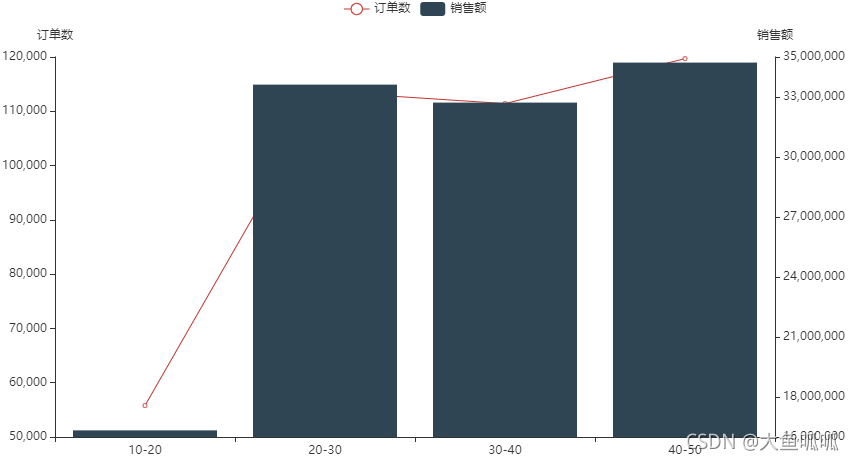
40-50岁的用户订单数和销售额都排第一。
line7=(
Line()
.add_xaxis(age_df.index.tolist())
.add_yaxis('人均订单',age_df.人均订单.tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(yaxis_opts=opts.AxisOpts(name = '人均订单',min_=3,max_=4.5))
.extend_axis(yaxis=opts.AxisOpts(name='每单均价',min_=290,max_=296,position='right'))
)
bar4=(
Bar()
.add_xaxis(age_df.index.tolist())
.add_yaxis('每单均价',age_df.每单均价.tolist(), label_opts=opts.LabelOpts(is_show=False),yaxis_index=1)
)
line7.overlap(bar4)
line7.render_notebook()
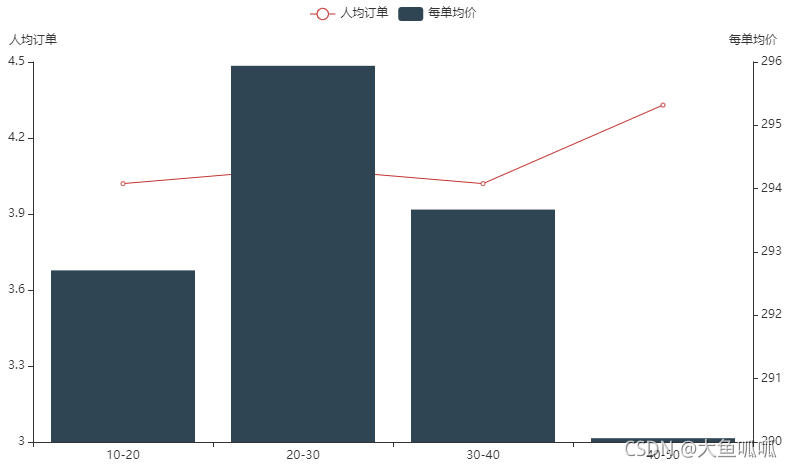
40-50岁的用户,人均订单多,每单均价低;但与其他年龄段相差不大
地区分布情况
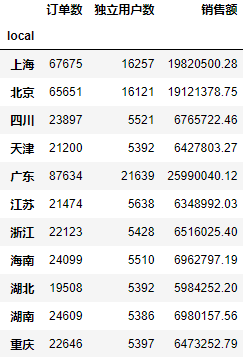
locals=df.groupby('local').agg({'order_id':['nunique'],'user_id':['nunique'],'price':['sum']})
locals.columns = locals.columns.to_flat_index()
locals=locals.rename(columns={('order_id','nunique'):'订单数',('user_id','nunique'):'独立用户数',('price','sum'):'销售额'})
locals
bar5=(
Bar()
.add_xaxis(locals.sort_values(['独立用户数']).index.tolist())
.add_yaxis('独立用户数',locals.sort_values(['独立用户数']).独立用户数.tolist(), label_opts=opts.LabelOpts(is_show=False))
.reversal_axis()
.set_global_opts(legend_opts=opts.LegendOpts(pos_left='15%'))
)
bar6=(
Bar()
.add_xaxis(locals.sort_values(['订单数']).index.tolist())
.add_yaxis('订单数',locals.sort_values(['订单数']).订单数.tolist(), label_opts=opts.LabelOpts(is_show=False))
.reversal_axis()
.set_global_opts(legend_opts=opts.LegendOpts(pos_left='45%'))
)
bar7=(
Bar()
.add_xaxis(locals.sort_values(['销售额']).index.tolist())
.add_yaxis('销售额',locals.sort_values(['销售额']).销售额.tolist(), label_opts=opts.LabelOpts(is_show=False))
.reversal_axis()
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts={'rotate': 25}),legend_opts=opts.LegendOpts(pos_left='75%'))
)
grid2 = (
Grid()
.add(bar5, grid_opts=opts.GridOpts(pos_right='65%'))
.add(bar6, grid_opts=opts.GridOpts(pos_left='40%',pos_right='35%'))
.add(bar7, grid_opts=opts.GridOpts(pos_left='70%'))
)
grid2.render_notebook()
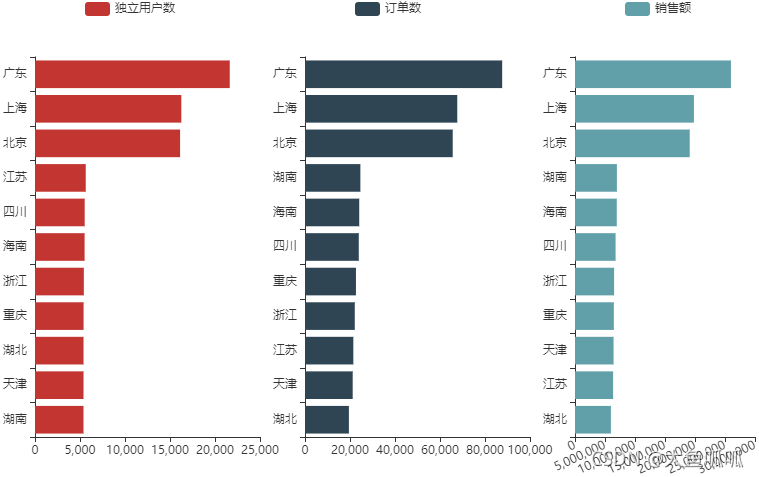
北上广的用户数量、订单数量、成交金额都稳居前三。
湖南的客户数量虽然少,但是订单数,客单价仅次于北上广,湖南客户的潜力巨大,需要加大宣传,增加客户数量。
用户消费次数、费金额、消费周期
df.groupby('user_id').agg({'order_id':'nunique','price':'sum'}).describe([0.1,0.25,0.5,0.75,0.8,0.9,0.99]).T

1、超一半的用户下单两次,最大的用户用户消费了666次,可能是批发转卖。
2、用户平均消费金额是1251,标准差是4204.5,用户平均消费金额大于75分位数,存在高额消费用户,需要注意。
purchase_time=df.groupby('user_id').apply(lambda x: x['event_time']-x['event_time'].shift()).astype('timedelta64[m]')/(24*60)
print(purchase_time.describe([0.1,0.25,0.5,0.75,0.8,0.85,0.9,0.99]))
print(purchase_time[purchase_time>0].describe([0.1,0.25,0.5,0.75,0.8,0.85,0.9,0.99]))
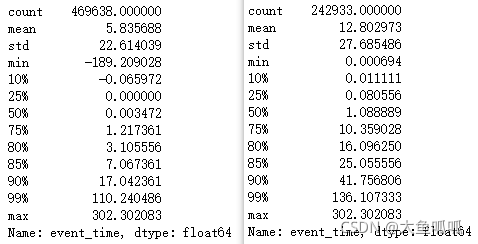
至少消费两次的用户有一半在1天左右复购,75%的用户在10天左右复购,可以在10天左右时间点对用户进行推送和提醒。
RFM分析
通过RFM方法判断用户类别,针对不同类别的用户,制定不同的刺激措施,来提高用户价值
def RFM(x):
r='1' if x[0]<= 30 else '0' # 最近购物天数在30天以内
f='1' if x[1]>= 3 else '0' # 累计购物次数大于2次(均值)
m='1' if x[2]>=1251 else '0' # 累计消费金额大于1251(均值)
return dic_rfm[r+f+m]
dic_rfm ={
'111':'重要价值会员', #倾斜更多资源,VIP服务,个性化服务,附加销售
'011':'重要保持会员',#DM营销,提供有用的资源,通过新的商品召唤回
'101':'重要发展会员',#交叉销售,制定会员忠诚度计划,推荐其他商品
'001':'重要挽留会员',#重点联系或摆放,提高留存率
'110':'一般价值会员',#向上营销,销售价值更高的商品
'100':'新会员',#提供免费试用,提高会员兴趣,创建品牌知名度
'010':'一般发展会员',#积分制,分享宝贵资源,以折扣推荐热门商品
'000':'低价值会员'}#恢复会员兴趣,否者暂时放弃
r=(df.event_time.sort_values().iloc[-1]-df.groupby('user_id')['event_time'].max()).astype('timedelta64[D]').astype('int')
f=df.groupby('user_id')['order_id'].nunique()
m=df.groupby('user_id')['price'].sum()
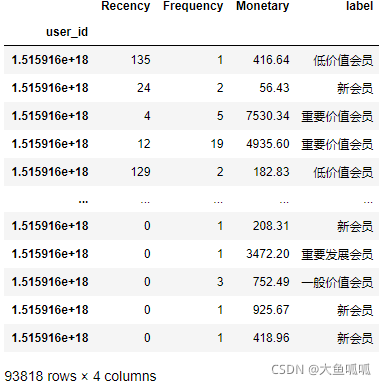
rmf=pd.concat([r,f,m],axis=1)
rmf=pd.concat([rmf,rmf.apply(RFM,axis=1)],axis=1)
rmf=rmf.rename(columns={'event_time':'Recency','order_id':'Frequency','price':'Monetary',0:'label'})
rmf
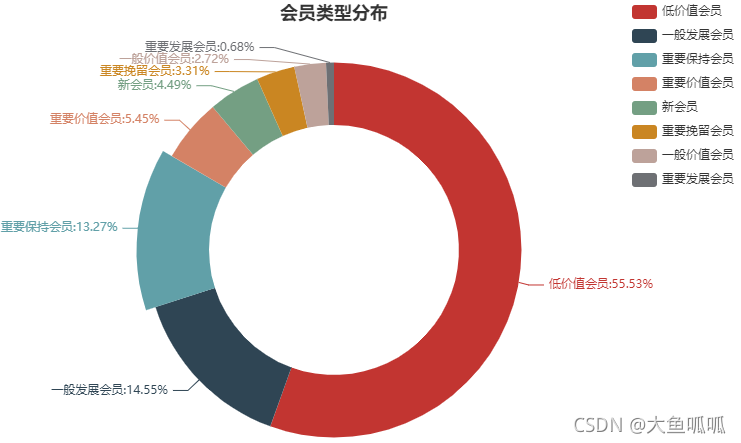
member=rmf['label'].value_counts()
pie3 = (
Pie()
.add('',[list(z) for z in zip(member.index.tolist(), member.values.tolist())],radius=['50%', '75%'])
.set_global_opts(title_opts=opts.TitleOpts(title='会员类型分布',pos_left='center'),
legend_opts=opts.LegendOpts(pos_right='5%',orient='vertical'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie3.render_notebook()
结论
时间维度分析:
●店铺5月到8月的销售额上升,8月后的销量下降,主要是独立用户数的下降导致;
与同期市场相比,店铺销量有明显的背离,如果5月到8月不是活动引流导致的销量变化,需要马上复盘8月后的下跌问题。
●在5-13点之间出现销售高峰,顾客偏向于在早晨到中午的时间段内下单;
用户消费行为主要集中在周末。
整体用户分析:
●年龄
用户男女占比接近;年龄集中在20-50岁,且该段用户占比差距不大
40-50岁的用户订单数和销售额都排第一
40-50岁的用户人均订单多,每单均价低;但与其他年龄段相差不大
●地区
北上广的用户数量、订单数量、成交金额都稳居前三
湖南的客户数量虽然少,但是订单数,客单价仅次于北上广,湖南客户的潜力巨大,需要加大宣传,增加客户数量。
用户消费行为分析:
●超一半的用户下单两次,用户平均消费金额是1251
●至少消费两次的用户有一半在1天左右复购,75%的用户在10天左右复购,可以在10天左右时间点对用户进行推送和提醒
●通过RFM方法判断用户类别,针对不同类别的用户,制定不同的刺激措施,来提高用户价值















 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









