







DSNet: A Flexible Detect-to-Summarize Network for Video Summarization
GitHub地址:https://github.com/li-plus/DSNet.git
DS网络:一个从检测到生成摘要的流畅产生视频摘要的网络
1.思路
1.1 DSnet
本文针对有监督学习方法中没有时序连贯约束导致的,在同一语义段中视频帧的预测分数不能准确地表示相应片段的重要性的问题,提出了一种从检测到摘要的网络结构DSnet。
DSnet将视频摘要看作一个关注时序的检测过程,不仅预测视频中语义的时间定位,还产生相关的重要度分数。
文章提出了两种DSnet:有锚定方法和无锚定方法。
1.1.1 有锚定DSnet
首先将原始视频使用深度卷积神经网络抽取长范围特征,然后为重要性分类以及位置偏移量回归提出感兴趣建议,根据分类与感兴趣的帧所在的位置生成视频摘要。
1.1.2 无锚定DSnet
首先将原始视频使用深度卷积神经网络抽取长范围特征,然后对每个帧进行重要度预测、中心程度预测和片段位置计算,最终根据打分和相关片段生成视频摘要。
1.2 DSnet的训练
1.2.1 有锚定DSnet

作者首先应用深度卷积网络和序列建模层来提取长范围特征向量。然后,生成并汇总了关于重要性分类和位置偏移回归的建议。为了进行测试,使用预测的偏移量来精细化片段,并使用非极大抑制技术进一步过滤。最后,将创建视频摘要。
1.2.2 无锚定DSnet

作者首先使用深度卷积网络和序列建模层来提取长范围特征。 然后,应用共享分类和回归模块分别预测每个时间位置的重要性评分、中心度评分和段边界。 为了进行测试,使用预测的位置对段进行精细化,并进一步用非极大抑制技术进行过滤。 最后,利用动态规划算法生成视频摘要。
2.实现方法
2.1 Detect-to-Summarize Network(DSnet)
2.1.1 Anchor-Based Video Summarization(AB-DSnet)
首先用一个时序建模层捕获长范围的视频代表,抽取帧级特征。
使用了去掉最后三层的GoogLenet提取了特征向量,默认采用自注意力机制来提取长范围代表(视频)。
另外,调查了其他的长范围序列建模层,例如长短期记忆网络(LSTM),双向长短期记忆网络(LSTM),图卷积网络。将长范围代表wj与原始空间特征vj相加表示最终代表。
x
j
=
w
j
+
v
j
x_j=w_j+v_j
xj=wj+vj
第二步生成时序兴趣建议。用预定义的多尺度间隔生成时序兴趣建议。
第t个时间位置上生成K个感兴趣的提议,K的取值在 [ t − l k 2 , t + l k 2 ) [t-\frac{l_k}{2},t+\frac{l_k}{2}) [t−2lk,t+2lk)之间。其中 l k l_k lk代表第k个感兴趣建议的持续时长。所以,一共有 K × T K \times T K×T个感兴趣提议在一个有T帧的视频中生成。因为预先不知道哪些帧会被选为代表片段,设定所有的输入帧有相同的机会被选择,这就使得提议生成策略是时间稳定的。
在训练态中,为了减弱分类不平衡的问题,作者对感兴趣提议以1:3的概率设置了积极和消极的二分类标签。当一个提议对任一原始片段的时间交叉值都大于0.6时,认为它是积极的;等于0时认为它不重要;介于0和0.3之间认定为未完成。
另外,0.3和0.6之间的提议对摘要有负面效果,这有可能是由于积极和消极提议之间的模糊性导致的。
作者测试了SumMe和TVSum上的数据,设置了包含一系列真实长度的视频片长度。
第三步进行提议分类和回归。作者采用的池化层可以输入任意大小的提议,防止了视频的时间扭曲和裁剪带来的问题。特征被作为分类和回归的输入,经过一系列函数的处理(详情见2.2),最终产生两个输出,第一个输出提议的重要分数,第二个输出相关中心内容的分割长度偏移量。
第四步选择关键镜头。在测试中,作者通过使用预测的偏移来生成得到改善的视频分割片,这步和训练过程相似。但是,许多低置信的片段与其他片段之间有高度重叠度,为此作者采用了非极大抑制技术用来移除那些多余的低质量片段。
作者采用了KTS(kernel temporal segmentation)方法将片段拆成镜头来估计镜头级的重要分数。然后,作者使用他们的训练模型,预测片段边界以及它们的重要性分数来测试视频序列。作者为此设计了一个产生最终帧级重要性分数的策略(详细见2.3),并且在选定镜头的总长度不超过原始视频长度15%的约束下生成摘要。有如下公式:代码
max
∑
h
=
1
c
u
h
y
h
,
s.t.
∑
h
=
1
c
u
h
n
h
≤
15
%
×
T
\max \sum_{h=1}^{c} u_{h} y_{h}, \quad \text { s.t. } \sum_{h=1}^{c} u_{h} n_{h} \leq 15 \% \times T
maxh=1∑cuhyh, s.t. h=1∑cuhnh≤15%×T
其中,
u
h
u_h
uh在(0,1)间取值,代表第
h
h
h个视频镜头有无被摘要选择,
c
c
c是镜头的数量,
T
T
T是原始视频的长度。这个公式是一个经典的0/1背包问题,作者采用动态规划的方法解决这个问题。最终使得
u
h
=
1
u_h=1
uh=1.
class DSNet(nn.Module):
def __init__(self, base_model, num_feature, num_hidden, anchor_scales,
num_head):
super().__init__()
self.anchor_scales = anchor_scales
self.num_scales = len(anchor_scales)
self.base_model = build_base_model(base_model, num_feature, num_head)
self.roi_poolings = [nn.AvgPool1d(scale, stride=1, padding=scale // 2)
for scale in anchor_scales]
self.layer_norm = nn.LayerNorm(num_feature)
self.fc1 = nn.Sequential(
nn.Linear(num_feature, num_hidden),
nn.Tanh(),
nn.Dropout(0.5),
nn.LayerNorm(num_hidden)
)
self.fc_cls = nn.Linear(num_hidden, 1)
self.fc_loc = nn.Linear(num_hidden, 2)
def forward(self, x):
_, seq_len, _ = x.shape
out = self.base_model(x)
out = out + x
out = self.layer_norm(out)
out = out.transpose(2, 1)
pool_results = [roi_pooling(out) for roi_pooling in self.roi_poolings]
out = torch.cat(pool_results, dim=0).permute(2, 0, 1)[:-1]
out = self.fc1(out)
pred_cls = self.fc_cls(out).sigmoid().view(seq_len, self.num_scales)
pred_loc = self.fc_loc(out).view(seq_len, self.num_scales, 2)
return pred_cls, pred_loc
def predict(self, seq):
seq_len = seq.shape[1]
pred_cls, pred_loc = self(seq)
pred_cls = pred_cls.cpu().numpy().reshape(-1)
pred_loc = pred_loc.cpu().numpy().reshape((-1, 2))
anchors = anchor_helper.get_anchors(seq_len, self.anchor_scales)
anchors = anchors.reshape((-1, 2))
pred_bboxes = anchor_helper.offset2bbox(pred_loc, anchors)
pred_bboxes = bbox_helper.cw2lr(pred_bboxes)
return pred_cls, pred_bboxes
2.1.2 Anchor-Free Video Summarization(AF-DSnet)
AF-DSnet比AB-DSnet更加简单、顺滑。
AB-DSnet存在的几个问题:
- 需要每个时间位置密集的感兴趣提议样本,但多数提议来自消极样例,导致了极端的分类不平衡问题。
- 预定义性质不能适应复杂、动态的场景。
- 为积极和消极的样例打标签需要大量的
tIoU计算。 AB-DSnet对时序感兴趣提议需要精确相关超参数的微调。

在长范围特征提取后,作者计算出每一个视频帧的重要性分数、片段边界、中心度分数。
第一步进行特征提取。此步骤和AB-DSnet中实现方法相同。
第二步进行片段分割预测。此步骤与AB-DSnet中预测每一时间位置预定义提议的偏移量方法不同,它的目标是直接学习片段位置和每一视频帧的重要性分数。
为了训练,当第j个帧被选入摘要时,作者将第j个帧视作一个积极的类,否则视其消极。这样视频帧的标签没有歧义。
对于每一个积极标签的视频帧,学习一个二维向量
δ
t
∗
=
(
δ
l
∗
,
δ
r
∗
)
\boldsymbol{\delta} \boldsymbol{t}^{*}=\left(\delta l^{*}, \delta r^{*}\right)
δt∗=(δl∗,δr∗),其中
δ
l
∗
\delta l^{*}
δl∗和
δ
r
∗
\delta r^{*}
δr∗分别为此帧位置和关联片段的左右边界:
δ
l
∗
=
j
−
t
o
s
,
δ
r
∗
=
t
o
e
−
j
\delta l^{*}=j-t_{o}^{s}, \quad \delta r^{*}=t_{o}^{e}-j
δl∗=j−tos,δr∗=toe−j
使用指数方程来确保预测结果为正。
作者通过计算焦点损失(focal loss)
L
c
l
s
\mathcal{L}_{c l s}
Lcls 来将重要性分数分类,这样做可以降低分类效果良好的帧的误差;通过计算tIoU的损失
L
r
e
g
\mathcal{L}_{r e g}
Lreg进行位置回归;最终的训练损失计算公式为:
L
=
1
N
p
o
s
∑
j
L
c
l
s
(
s
j
,
s
j
∗
)
+
λ
N
p
o
s
∑
e
L
r
e
g
(
δ
t
e
,
δ
t
e
∗
)
\mathcal{L}=\frac{1}{N_{\mathrm{pos}}} \sum_{j} \mathcal{L}_{c l s}\left(s_{j}, s_{j}^{*}\right)+\frac{\lambda}{N_{\mathrm{pos}}} \sum_{e} \mathcal{L}_{r e g}\left(\delta \boldsymbol{t}_{e}, \delta \boldsymbol{t}_{e}^{*}\right)
L=Npos1j∑Lcls(sj,sj∗)+Nposλe∑Lreg(δte,δte∗)
其中,
s
j
s_j
sj和
s
j
∗
s^*_j
sj∗分别为第j个帧预测分数和帧真实分数;
δ
t
e
\delta \boldsymbol{t}_{e}
δte和
δ
t
e
∗
\delta \boldsymbol{t}^*_{e}
δte∗分别代表第e个积极样本的帧预测分数和帧真实分数,
λ
\lambda
λ平衡了分类和回归的损失。
此方法导致会产生许多低质量的分割,为了解决这个问题,作者提出了一个中心度约束方法,确保时间位置和预测分割片段的中心十分接近,详情见2.4.
第三步选择关键镜头。经过第二步训练后,得到每一时间位置的重要性分数
s
j
s_j
sj,位置预测
δ
l
\delta l
δl和
δ
r
\delta r
δr,中心度分数
v
j
v_j
vj,使用以下公式计算每一个预测片段的开始和结束时间:
t
o
s
=
j
−
δ
l
,
t
o
e
=
j
+
δ
r
t_{o}^{s}=j-\delta l, \quad t_{o}^{e}=j+\delta r
tos=j−δl,toe=j+δr
j代表视频帧的时序索引。它的置信分数为
c
o
=
s
j
×
v
j
c_{o}=s_{j} \times v_{j}
co=sj×vj,这说明一个好的分割需要有高重要性分数,以及关联的片段在片段中间部分。采用非极大抑制算法过滤冗余和低质量的片段。然后采用和AB-DSnet一样的帧级重要性分配策略将帧级重要性分数转化为镜头级重要性分数,同样利用0/1背包算法选择视频镜头。
class DSNetAF(nn.Module):
def __init__(self, base_model, num_feature, num_hidden, num_head):
super().__init__()
self.base_model = build_base_model(base_model, num_feature, num_head)
self.layer_norm = nn.LayerNorm(num_feature)
self.fc1 = nn.Sequential(
nn.Linear(num_feature, num_hidden),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.LayerNorm(num_hidden)
)
self.fc_cls = nn.Linear(num_hidden, 1)
self.fc_loc = nn.Linear(num_hidden, 2)
self.fc_ctr = nn.Linear(num_hidden, 1)
def forward(self, x):
_, seq_len, _ = x.shape
out = self.base_model(x)
out = out + x
out = self.layer_norm(out)
out = self.fc1(out)
pred_cls = self.fc_cls(out).sigmoid().view(seq_len)
pred_loc = self.fc_loc(out).exp().view(seq_len, 2)
pred_ctr = self.fc_ctr(out).sigmoid().view(seq_len)
return pred_cls, pred_loc, pred_ctr
def predict(self, seq):
pred_cls, pred_loc, pred_ctr = self(seq)
pred_cls *= pred_ctr
pred_cls /= pred_cls.max() + 1e-8
pred_cls = pred_cls.cpu().numpy()
pred_loc = pred_loc.cpu().numpy()
pred_bboxes = anchor_free_helper.offset2bbox(pred_loc)
return pred_cls, pred_bboxes
2.2 AB-DSnet感兴趣提议的分类器和回归器

此模块首先由一个共用的全连接网络构成。依次经过tanh层、以0.5概率丢弃层和规范化层,产生两个输出,一个重要性分数分类,另一个中心和长度的偏移量。
作者采取一个多任务损失函数L:
L
(
p
,
p
∗
,
t
,
t
∗
)
=
1
N
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
N
p
o
s
∑
i
p
i
∗
L
r
e
g
×
(
t
i
,
t
i
∗
)
\begin{aligned} \mathcal{L}\left(\boldsymbol{p}, \boldsymbol{p}^{*}, \boldsymbol{t}, \boldsymbol{t}^{*}\right)=\frac{1}{N} \sum_{i} \mathcal{L}_{c l s}\left(p_{i}, p_{i}^{*}\right)+\frac{\lambda}{N_{p o s}} & \sum_{i} p_{i}^{*} \mathcal{L}_{r e g} \times\left(\boldsymbol{t}_{i}, \boldsymbol{t}_{i}^{*}\right) \end{aligned}
L(p,p∗,t,t∗)=N1i∑Lcls(pi,pi∗)+Nposλi∑pi∗Lreg×(ti,ti∗)
超参数
λ
\lambda
λ平衡分类损失和位置回归损失,
N
p
o
s
N_{pos}
Npos代表积极提议的数量,
N
N
N是积极和消极提议的数量。
self.fc1 = nn.Sequential(
nn.Linear(num_feature, num_hidden),
nn.Tanh(),
nn.Dropout(0.5),
nn.LayerNorm(num_hidden)
)
self.fc_cls = nn.Linear(num_hidden, 1)
self.fc_loc = nn.Linear(num_hidden, 2)
2.3 AB-DSnet中产生最终帧级重要性分数的策略
将预测的第t个时间位置视频片段的最大值当作第t个视频帧的重要性分数。镜头级重要性分数的计算公式为
y
h
=
1
n
h
∑
r
=
1
n
h
s
h
,
r
y_{h}=\frac{1}{n_{h}} \sum_{r=1}^{n_{h}} s_{h, r}
yh=nh1r=1∑nhsh,r
其中,
n
h
n_h
nh是第h个镜头的长度,
s
h
,
r
s_{h,r}
sh,r是第r个视频帧的重要性分数。
这个策略被广泛地应用于视频摘要中不同原始真实视频标记格式的转换。
2.4 AF-DSnet中心度约束策略
原始真实中心度(ground truth center-ness score)计算公式:
v
e
∗
=
min
(
δ
l
∗
,
δ
r
∗
)
max
(
δ
l
∗
,
δ
r
∗
)
v_{e}^{*}=\frac{\min \left(\delta l^{*}, \delta r^{*}\right)}{\max \left(\delta l^{*}, \delta r^{*}\right)}
ve∗=max(δl∗,δr∗)min(δl∗,δr∗)
作者采用二元交叉熵损失
L
c
e
n
t
e
r
L_{center}
Lcenter和平衡量
μ
\mu
μ计算中心度,最终将三个损失求和:
L
∗
=
L
+
μ
N
pos
∑
e
L
center
(
v
e
,
v
e
∗
)
\mathcal{L}^{*}=\mathcal{L}+\frac{\mu}{N_{\text {pos }}} \sum_{e} \mathcal{L}_{\text {center }}\left(v_{e}, v_{e}^{*}\right)
L∗=L+Npos μe∑Lcenter (ve,ve∗)
3.实验
Datasets为SumMe,TVSum,OVP,YouTube.
Evaluation Metrics:采用 F β F_\beta Fβ方法评估模型生成摘要和人为生产摘要之间的相同程度。
给定第 i i i个生成摘要 g s i gs_i gsi,带注释的摘要 g t i gt_i gti:
精确率
p
i
=
length
(
g
s
i
∩
g
t
i
)
length
(
g
s
i
)
p_{i}=\frac{\text { length }\left(\boldsymbol{g} \boldsymbol{s}_{i} \cap \boldsymbol{g} \boldsymbol{t}_{i}\right)}{\operatorname{length}\left(\boldsymbol{g} \boldsymbol{s}_{i}\right)}
pi=length(gsi) length (gsi∩gti),召回率
r
i
=
length
(
g
s
i
∩
g
t
i
)
length
(
g
t
i
)
r_{i}=\frac{\operatorname{length}\left(\boldsymbol{g} \boldsymbol{s}_{i} \cap \boldsymbol{g} \boldsymbol{t}_{i}\right)}{\operatorname{length}\left(\boldsymbol{g} \boldsymbol{t}_{i}\right)}
ri=length(gti)length(gsi∩gti)
F
β
=
(
1
+
β
2
)
×
p
i
×
r
i
(
β
2
×
p
i
)
+
r
i
F_{\beta}=\frac{\left(1+\beta^{2}\right) \times p_{i} \times r_{i}}{\left(\beta^{2} \times p_{i}\right)+r_{i}}
Fβ=(β2×pi)+ri(1+β2)×pi×ri
作者采用调和中项
F
1
F_1
F1-measure(
β
\beta
β=1)作为F分数(F-score)的默认值。
Evaluation Settings:(1)规范性:80%的数据集用来训练,20%用来评估;(2)增强性:另外三个数据集的80%用来训练;(3)转移性:三个数据集用来训练,剩下的一个用来评估。

4.实验结果评估
4.1 有锚定(AB-DSnet)模型实验结果
数据集:SumMe, TVSum。
4.1.1 与State-of-the-Art视频摘要方法进行比较
State-of-the-Art分为两类:传统方法和深度学习方法。从F分数和不同视频摘要的参数个数两方面比较。

可以看出作者的模型效果最佳。vsLSTM, dppLSTM和DR-DSN包含了最少的参数,只是因为它们采用了双向LSTM网络。
4.1.2 增强性和转移性实验

和State-of-the-Art摘要方法从规范性(C)、增强性(A)和转移性(T)方面进行F分数的比较,可以看出作者的模型效果最佳。
4.1.3 长范围特征的评估
作者将自注意力机制默认层分别替换为一个LSTM层、一个双向LSTM层或一个图卷积层,分析不同特征提取产生的长范围特征的效果。

可以看出AB-DSnet的效果很有竞争力。
4.1.4 时序池化层的评估
在提取任意长度的提议特征时,作者应用了一个时间平均池化层(temporal average pooling layer),作者对两个数据集分别进行了有池化层和无池化层的对比:

时间池化层机制提高了两个数据集的性能,特别是在传输性上,由于有效地利用了时间局部信息,提高了模型的鲁棒性。
4.1.5 NMS阈值学习
对SumMe, TVSum数据集进行了切除实验。
高阈值会过滤掉高质量的片段,低阈值会引入低质量的片段,NMS阈值显著影响模型的表现效果。
作者的模型在TVSum数据集上的性能更稳定(阈值0.5左右):

4.1.6 参数分析
调整训练模型中的 λ \lambda λ参数检测分类回归模块对摘要生成的影响。

可以看出, λ \lambda λ=0时模型表现糟糕,这表明进行回归操作十分有必要。
4.1.7 召回率分析

作者的模型能够在不同长范围的时序层(long-range temporal layers)的原始真实片段中达到95%以上的召回率。
4.2 无锚定(AF-DSnet)模型实验结果
4.2.1 与State-of-the-Art方法CAT比较

与有锚定模型相比,无锚定模型在SumMe数据集上效果更好,在TVSum数据集上差。可能的原因是TVSum数据集上的原始真实片段比SumMe长,而有锚定模型因为有预定义多尺度提议更擅长处理长片段。
4.2.2 回归过程中的中心度损失和指数嵌入(exp embedding)评估
在没有中心度损失和指数嵌入条件下检测模型的F-score(F)、准确率(P)、召回率(R):

看出这导致和SumMe和TVSum和数据集的性能下降。
4.2.3 分类和回归损失的比较
使用不同的损失函数,比较了分类模块中的焦损失(focal loss)和交叉熵损失,以及回归模块中的平滑L1损失(
s
m
o
o
t
h
L
1
smooth_{L1}
smoothL1):

观察到作者的方法在焦损失和tIoU损失在两个数据集优于其他替代设置。
4.2.4 长范围特征评估
与有锚定模型评估方法类似,将自注意力机制默认层分别替换为一个LSTM层、一个双向LSTM层或一个图卷积层,分析不同特征提取产生的长范围特征的效果。

4.2.5 参数分析
改变网格搜索策略(grid search strategy)中的
λ
\lambda
λ和
μ
\mu
μ参数,观察到影响不明显,故模型为了简便设置为1。

4.2.6 NMS阈值分析

当NMS阈值为0.4时,无锚方法达到了最佳性能。故实验设置0.4为默认值。
4.2.7 时序连贯性和完整性约束效果
设置有无感兴趣提议公式(I)和完善提议约束(R),应用一个自注意力层来预测重要性分数。

4.2.8 多样性分析
在不同数据集上使用不同模型比较其多样性分数。多样性越大,视频摘要质量越好。

4.2.9 运行时间分析
无锚方法不产生感兴趣建议,节省更多运行时间。单位:毫秒。

4.2 10 定性结果
直观地比较了不同视频摘要方法的效果。

观察到,有锚定和无锚定方法都会产生与真实摘要段有高重叠的片段,说明了本文模型的有效性。
4.3 结论
有锚定方法的提出解决了现存监督学习产生视频摘要的方法中产生不正确、不完整摘要的问题,无锚定方法在有锚定的基础上减弱了感兴趣提议带来的错误。在广泛使用的数据集上,DSnet方法优于最先进的有监督学习方法。
5 Q&A
总结
| 问题 | 解答 |
|---|---|
| 1.(重点)NMS是什么?阈值是如何选择的? | Non-maximum suppression是一种单独的后处理技术,例如在用训练好的模型进行测试时,网络会预测出一系列的候选框。这时候我们会用NMS来移除一些多余的候选框。即移除一些IOU值大于某个阈值的框。然后在剩下的候选框中,分别计算与ground truth的IOU值,通常会规定当候选框和ground truth的IOU值大于0.3~0.5时,认为检测正确。在本文中,作者在第四步产生视频镜头的时候使用NMS删除改进的提议段的冗余、低质量的段。 |
| 2.(重点)skip connection的作用是什么? | 中文翻译叫跳跃连接,通常用于残差网络(ResNet),它的作用是在比较深的网络中,解决在训练的过程中梯度爆炸和梯度消失问题。Residual Network通过引入Skip Connection到CNN网络结构中,使得网络深度达到了千层的规模,并且其对于CNN的性能有明显的提升。 |
| 3.(重点)对于中心度(center-ness)的理解 | 由于许多正分类的时间位置接近真实摘要视频段的边界,作者的方法会产生许多低质量片段。为此作者增加了一个中心度约束策略来抑制产生这种低质量的片段。本文中作者将此步骤与分类操作并行,将其以一个函数形式加入损失函数中。 |
| 4.有锚定方法在为兴趣建议打标签过程中0.3~0.6之间的模糊部分如何处理? | 本文计算片段与真实摘要之间的重合度来进行判断,当重合度大于0.6时判断为正,0时判断为不重要,0~0.3之间判断为未完成(这两类是负样本)。0.3~0.6不是模糊区域,而是作者经过实验发现负样本的阈值不能取太高,否则会导致严重的问题。 |
| 5.KTS方法是否是作者自己提出的? | 不是。Kernel temporal segmentation算法是由法国国家信息与自动化研究所(Inria)的Danila Potapov等人提出的一种将视频分割为不交叉的时间片段的算法。作者在第四步时运用了KTS。 |
| 6.KTS算法是如何实现的? | 这是一个时序分割的基于核的变化点检测算法。输入一个帧与帧之间的相似度矩阵,输出一组对应于时间片段边界的最佳“变化点”。详细的算法内容和步骤见下。 |
| 7.有锚定方法中分类和回归具体是怎么实现的? | 首先作者采用了一个时序平均池化层来进行任意size的提议的特征采样,接着池化后的特征被放进如图(见2.2)所示的模块中。该模块由一个共享的全连接层构成,随后是tanh、以0.5概率丢弃、规范化层,最终产生两个输出,一个输出提议的重要性分数,另一个输出关联中心和片段长度偏移。使用了一个多任务损失函数来训练,即将多种损失函数相组合。 |
| 8.有锚定和无锚定的具体区别? | 总体上,有锚定方法会在第二步的时候产生感兴趣的提议,然后通过将这些感兴趣提议进行分类和回归,最终产生视频摘要;无锚定方法在第二步的时候不产生感兴趣提议,而是直接在每一帧计算它的重要性分数和时间位置,生成视频摘要。细节上,(1)有锚定方法一共有四步,无锚定方法三步;(2)有锚定方法在生成视频镜头时,首先用第三步预测的偏移来优化片段,接着使用NMS删除冗余和低质量片段,然后使用KTS算法来将这些片段分割为镜头;无锚定方法在生成视频镜头时,使用了第二步产生的重要性分数、预测位置和中心度分数,除去偏移优化之外,其余与有锚定方法类似。 |
| 9.无锚定和有锚定的结果哪一个比较好?(只看TVSum) | 无锚定方法。因为它可以进行任意变换。 |
| 10.有锚定方法中为什么可以生成任意长度的提议? | 作者受到区域提议网络和动作定位方法的启发,采用了监督学习中的一个时序提议生成策略:使用预定义的多尺度间隔来生成时序提议。 |
| 11.有锚定方法中,偏移量和proposal是什么关系? | 在第三步的分类与回归模块中,输入第二步生成的感兴趣提议(proposal),输出一个分支为中心偏移量和长度偏移量。这两个偏移量用来在第四步中对产生的分割片段进行优化。 |
| 12.更多loss函数有哪些? | 损失函数(loss function)又称为代价函数(cost function),损失函数是模型的评估指标,损失函数越小,表明模型在该样本上的匹配程度越高。 |
| 13.四个数据集annotation的方式? | 作者以2秒捕获视频。(1)SumMe:包含从YouTube上获取得到的25个视频。每个视频带有15-18个人类标注的视频概括。视频概括包含的视频时间长度小于原时间长度15%。本文中SumMe标注有帧级重要性分数。(2)TVSum:包含10类50个YouTube视频。每个视频有标题和类别作为元数据。本文中TVSum标注有重要度分数。(3)OVP:50个视频,标注类型为关键帧。(4)YouTube:39个视频,标注类型为关键帧。 |
| 14.CAT分别指什么? | (1)C(canonical):规范性。80%的数据集用来训练,20%用来评估;(2)A(augmented):增强性。另外三个数据集的80%用来训练;(3)T(transfer):转移性。三个数据集用来训练,剩下的一个用来评估。 |
| 15.Self-attention加在哪里了? | 在提取出视频特征之后。注意力机制模仿的是人的视觉行为,能够找到一个图像的焦点区域。近几年来,注意力机制主要在自然语言领域广泛应用,在计算机视觉领域的应用相对较少,主要是利用注意力机制的思想,提升有效特征图中的有效通道,抑制对当前任务影响较小的特征通道。 |
| 16.Temporal average pooling layer(时序平均池化层)应该怎么理解? | 在有锚定方法的第三步中,输入感兴趣的提议时加入一个平均池化层代替全连接层,可接受任意尺寸的提议。在图像处理中,平均池化即计算一个池范围内像素的平均值;而在视频处理中,时序平均池化意味着在考虑时间的维度上进行平均。作者用了keras的AveragePooling1D函数进行处理,这个函数是对于时序数据的平均池化。详细见下。 |
| 17.其他文章有没有对于TVSum数据集的阈值处理? | 下载了9篇Video Summary文章,在Google Scholar上搜索关键字,暂时没有看到其他论文中这样处理的。 |
| 18.无锚定方法中,为什么TVSum和SumMe设置的NMS阈值差别这么大? | 可能是因为TVSum数据集的样本比SumMe的多,模型训练更完善,测试的结果越好。同样的,有锚定方法和大多数方法得到的结果都是在TVSum数据集的效果比在SumMe数据集的效果好。 |
| 19.接受发表到修改经历了多长时间? | 知乎上一审稿人:“under review的话可能是再次被送审了,按照我审稿的经验,一般杂志会给审稿人一个月的期限,然后根据不同杂志,会在还有15天/10天/3天的时候发邮件给审稿人催一下审稿进度。所以,不出意外,一个月之内应该有消息。”综合来看,(大修)一般一个月,时间长两三个月也有可能;小修3-5天。 |
| 20.有锚定方法中,share指的是什么? | 一个全连接层。 |
| 21.无锚定方法中,shared head指的是什么? | 指公用的分类和回归模块。 |
详细
1.NMS实现代码
import numpy as np
def nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # 置信度从高到低排序
keep = []
while order.size > 0:
i = order[0] # 此类别中置信度最高的预测框的索引
keep.append(i) # 将其作为保留下来的第1个预测框
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter) # 计算其余预测框与置信度最高的预测框的IoU
inds = np.where(ovr <= thresh)[0] # 记录下第1个与其Iou<阈值的预测框,也就是与其Iou<阈值的预测框中置信度最高的
order = order[inds + 1] # 将与保留下来的第1个预测框Iou<阈值的预测框中置信度分数最高的预测框作为第2个要保留的
return keep # 所有经过NMS后保留下来的框
2.梯度消失与梯度爆炸
以下图的反向传播为例(假设每一层只有一个神经元且对于每一层, y i = σ ( z i ) = σ ( w i x i + b i ) y_{i}=\sigma\left(z_{i}\right)=\sigma\left(w_{i} x_{i}+b_{i}\right) yi=σ(zi)=σ(wixi+bi),其中[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JpylanIC-1618125113839)(https://www.zhihu.com/equation?tex=%5Csigma)]为sigmoid函数)

可以推导出
∂ C ∂ b 1 = ∂ C ∂ y 4 ∂ y 4 ∂ z 4 ∂ z 4 ∂ x 4 ∂ x 4 ∂ z 3 ∂ z 3 ∂ x 3 ∂ x 3 ∂ z 2 ∂ z 2 ∂ x 2 ∂ x 2 ∂ z 1 ∂ z 1 ∂ b 1 = ∂ C ∂ y 4 σ ′ ( z 4 ) w 4 σ ′ ( z 3 ) w 3 σ ′ ( z 2 ) w 2 σ ′ ( z 1 ) \begin{array}{l} \frac{\partial C}{\partial b_{1}}=\frac{\partial C}{\partial y_{4}} \frac{\partial y_{4}}{\partial z_{4}} \frac{\partial z_{4}}{\partial x_{4}} \frac{\partial x_{4}}{\partial z_{3}} \frac{\partial z_{3}}{\partial x_{3}} \frac{\partial x_{3}}{\partial z_{2}} \frac{\partial z_{2}}{\partial x_{2}} \frac{\partial x_{2}}{\partial z_{1}} \frac{\partial z_{1}}{\partial b_{1}} \\ =\frac{\partial C}{\partial y_{4}} \sigma^{\prime}\left(z_{4}\right) w_{4} \sigma^{\prime}\left(z_{3}\right) w_{3} \sigma^{\prime}\left(z_{2}\right) w_{2} \sigma^{\prime}\left(z_{1}\right) \end{array} ∂b1∂C=∂y4∂C∂z4∂y4∂x4∂z4∂z3∂x4∂x3∂z3∂z2∂x3∂x2∂z2∂z1∂x2∂b1∂z1=∂y4∂Cσ′(z4)w4σ′(z3)w3σ′(z2)w2σ′(z1)
而sigmoid的导数 σ ′ ( x ) \sigma^{\prime}(x) σ′(x)如下图
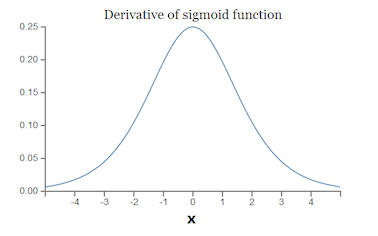
可见, σ ′ ( x ) \sigma^{\prime}(x) σ′(x)的最大值为[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hW47fzxs-1618125113844)(https://www.zhihu.com/equation?tex=%5Cfrac%7B1%7D%7B4%7D)],而我们初始化的网络权值[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5QyueOs1-1618125113845)(https://www.zhihu.com/equation?tex=%7Cw%7C)]通常都小于1,因此[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xqB2A59q-1618125113846)(https://www.zhihu.com/equation?tex=%7C%5Csigma%27%5Cleft%28z%5Cright%29w%7C%5Cleq%5Cfrac%7B1%7D%7B4%7D)],因此对于上面的链式求导,层数越多,求导结果[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NaLhTkbQ-1618125113847)(https://www.zhihu.com/equation?tex=%5Cfrac%7B%5Cpartial+C%7D%7B%5Cpartial+b_1%7D)]越小,因而导致梯度消失的情况出现。
当我们将w初始化为一个较大的值时,例如>10的值,那么从输出层到输入层每一层都会有一个s‘(zn)*wn的增倍,当s‘(zn)为0.25时s‘(zn)*wn>2.5,同梯度消失类似,当神经网络很深时,梯度呈指数级增长,最后到输入时,梯度将会非常大,我们会得到一个非常大的权重更新,这就是梯度爆炸的问题,在循环神经网络中最为常见.
3.参考论文:FCOS: Fully Convolutional One-Stage Object Detection
在FCOS中提出了一种简单而有效的策略来抑制这些低质量的预测边界框,而且不引入任何超参数。具体来说,FCOS添加单层分支,与分类分支并行,以预测"Center-ness"位置。

center-ness(可以理解为一种具有度量作用的概念,在这里称之为"中心度"),中心度取值为0,1之间,使用交叉熵损失进行训练。
6.参考文章:Category-Specific Video Summarization
1) 算法公式
令
x
i
x_i
xi代表每一个视频片段(
x
i
∈
X
,
i
=
0
,
…
,
n
−
1
\mathbf{x}_{i} \in \mathbf{X}, i=0, \ldots, n-1
xi∈X,i=0,…,n−1),
K
:
X
×
X
K:X\times X
K:X×X为核函数,
H
\mathcal{H}
H为核函数的特征空间,
ϕ
:
X
→
H
\phi: \mathbf{X} \rightarrow \mathcal{H}
ϕ:X→H为特征映射,
∥
⋅
∥
H
\|\cdot\|_{\mathcal{H}}
∥⋅∥H为特征空间
H
\mathcal{H}
H的范数,求下面公式的最小值:
Minimize
m
;
t
0
,
…
,
t
m
−
1
J
m
,
n
:
=
L
m
,
n
+
C
g
(
m
,
n
)
\underset{m ; t_{0}, \ldots, t_{m-1}}{\operatorname{Minimize}} \quad J_{m, n}:=L_{m, n}+C g(m, n)
m;t0,…,tm−1MinimizeJm,n:=Lm,n+Cg(m,n)
其中,m是变化点的数量,
g
(
m
,
n
)
g(m,n)
g(m,n)是惩罚项(采用BIC-type),惩罚过多的分段:
g
(
m
,
n
)
=
m
(
log
(
n
/
m
)
+
1
)
g(m, n)=m(\log (n / m)+1)
g(m,n)=m(log(n/m)+1),
L
m
,
n
L_{m,n}
Lm,n由视频片段之间的核变量
v
t
i
,
t
i
+
1
v_{t_i,t_{i+1}}
vti,ti+1定义,测量整体的片段间方差:
L
m
,
n
=
∑
i
=
0
m
v
t
i
−
1
,
t
i
,
v
t
i
,
t
i
+
1
=
∑
t
=
t
i
t
i
+
1
−
1
∥
ϕ
(
x
t
)
−
μ
i
∥
H
2
,
μ
i
=
∑
t
=
t
i
t
i
+
1
−
1
ϕ
(
x
t
)
t
i
+
1
−
t
i
L_{m, n}=\sum_{i=0}^{m} v_{t_{i-1}, t_{i}}, \quad v_{t_{i}, t_{i+1}}=\sum_{t=t_{i}}^{t_{i+1}-1}\left\|\phi\left(x_{t}\right)-\mu_{i}\right\|_{\mathcal{H}}^{2}, \quad \mu_{i}=\frac{\sum_{t=t_{i}}^{t_{i+1}-1} \phi\left(x_{t}\right)}{t_{i+1}-t_{i}}
Lm,n=i=0∑mvti−1,ti,vti,ti+1=t=ti∑ti+1−1∥ϕ(xt)−μi∥H2,μi=ti+1−ti∑t=titi+1−1ϕ(xt)
当片段数量增加时,
L
m
,
n
L_{m,n}
Lm,n会下降,但是会增加模型的复杂度;这个算法权衡了分段不够和分段太多的问题。
2) 算法过程

输入:时序表示量 x 0 , x 1 , . . . , x n − 1 x_0,x_1,...,x_{n-1} x0,x1,...,xn−1
-
计算格拉姆矩阵A

[^Gram matrix]: GRAM=X×X(转置),每一个I J元素就是样本向量和样本向量的内积,方便计算内积
-
计算A的累加和
-
计算非标准化方差
-
使用动态规划算法进行正向传递
-
选择变化点的最优数
-
原路返回(backtracking)寻找变化点位置
输出:变化点位置 t 0 , . . . , t m ∗ − 1 t_0,...,t_{m^*-1} t0,...,tm∗−1
12.Loss Function
机器学习中的损失函数形式如下:
L
=
∑
i
=
1
N
ℓ
(
y
i
,
y
^
i
)
L=\sum_{i=1}^{N} \ell\left(y_{i}, \hat{y}_{i}\right)
L=i=1∑Nℓ(yi,y^i)
其中,
y
i
y_i
yi为样本真实值,
y
^
i
\hat{y}_{i}
y^i为模型预测值。
常见的损失函数有:
1)0-1损失 Zero-one Loss
如果预测值与目标值不相等,那么为1,否则为0,即:
ℓ
(
y
i
,
y
^
i
)
=
{
1
,
y
i
≠
y
^
i
0
,
y
i
=
y
^
i
\ell\left(y_{i}, \hat{y}_{i}\right)=\left\{\begin{array}{ll} 1, & y_{i} \neq \hat{y}_{i} \\ 0, & y_{i}=\hat{y}_{i} \end{array}\right.
ℓ(yi,y^i)={1,0,yi=y^iyi=y^i
可以看出上述的定义太过严格,如果真实值为1,预测值为0.999,那么预测应该正确,但是上述定义显然是判定为预测错误,那么可以进行改进为Perceptron Loss。
2)感知损失 Perceptron Loss
ℓ
(
y
i
,
y
^
i
)
=
{
1
,
∣
y
i
−
y
^
i
∣
>
t
0
,
∣
y
i
−
y
^
i
∣
≤
t
\ell\left(y_{i}, \hat{y}_{i}\right)=\left\{\begin{array}{ll} 1, & \left|y_{i}-\hat{y}_{i}\right|>t \\ 0, & \left|y_{i}-\hat{y}_{i}\right| \leq t \end{array}\right.
ℓ(yi,y^i)={1,0,∣yi−y^i∣>t∣yi−y^i∣≤t
t是一个超参数阈值,如在PLA([Perceptron Learning Algorithm,感知机算法](http://kubicode.me/2015/08/06/Machine Learning/Perceptron-Learning-Algorithm/))中取t=0.5。
3)铰链损失 Hinge Loss
用于“最大边距”分类,最显着的是用于支持向量机SVM。对于预期的输出t =±1和分类器得分y,预测y的铰链损耗定义为
ℓ
(
y
)
=
max
(
0
,
1
−
t
⋅
y
)
\ell(y)=\max (0,1-t \cdot y)
ℓ(y)=max(0,1−t⋅y)
可以用来解决间隔最大化问题。
4)对数损失 Log Loss
log类型的损失函数也是一种常见的损失函数,如在LR(Logistic Regression, 逻辑回归)中使用交叉熵(Cross Entropy)作为其损失函数。即:
ℓ
(
y
i
,
y
^
i
)
=
−
y
i
⋅
log
y
^
i
−
(
1
−
y
i
)
⋅
log
(
1
−
y
^
i
)
y
i
∈
{
0
,
1
}
\begin{array}{c} \ell\left(y_{i}, \hat{y}_{i}\right)=-y_{i} \cdot \log \hat{y}_{i}-\left(1-y_{i}\right) \cdot \log \left(1-\hat{y}_{i}\right) \\ y_{i} \in\{0,1\} \end{array}
ℓ(yi,y^i)=−yi⋅logy^i−(1−yi)⋅log(1−y^i)yi∈{0,1}
5)平方误差 Square Loss
常用在回归中:
ℓ
(
y
i
,
y
^
i
)
=
(
y
i
−
y
^
i
)
2
\ell\left(y_{i}, \hat{y}_{i}\right)=\left(y_{i}-\hat{y}_{i}\right)^{2}
ℓ(yi,y^i)=(yi−y^i)2
6)绝对值误差 Absolute Loss
常用在回归中:
ℓ
(
y
i
,
y
^
i
)
=
∣
y
i
−
y
^
i
∣
\ell\left(y_{i}, \hat{y}_{i}\right)=\left|y_{i}-\hat{y}_{i}\right|
ℓ(yi,y^i)=∣yi−y^i∣
7)指数误差 Exponential Loss
常用于boosting算法中
ℓ
(
y
i
,
y
^
i
)
=
exp
(
−
y
i
⋅
y
^
i
)
y
i
∈
{
−
1
,
1
}
\begin{array}{c} \ell\left(y_{i}, \hat{y}_{i}\right)=\exp \left(-y_{i} \cdot \hat{y}_{i}\right) \\ y_{i} \in\{-1,1\} \end{array}
ℓ(yi,y^i)=exp(−yi⋅y^i)yi∈{−1,1}
8)正则项 Regularization Term
一般来说,对分类或者回归模型进行评估时,需要使得模型在训练数据上使得损失函数值最小,即使得经验风险函数最小化,但是如果只考虑经验风险(Empirical risk),容易过拟合,因此还需要考虑模型的泛化能力,一般常用的方法便是在目标函数中加上正则项,由损失项(Loss term)加上正则项(Regularization term)构成结构风险(Structural risk),损失函数为:
L
=
∑
i
=
1
N
ℓ
(
y
i
,
y
^
i
)
+
λ
⋅
R
(
ω
)
L=\sum_{i=1}^{N} \ell\left(y_{i}, \hat{y}_{i}\right)+\lambda \cdot R(\omega)
L=i=1∑Nℓ(yi,y^i)+λ⋅R(ω)
其中 λ是正则项超参数,常用的正则方法包括:L1正则与L2正则。
- L1正则: C = C 0 + λ n ∑ w ∣ w ∣ C=C_{0}+\frac{\lambda}{n} \sum_{w}|w| C=C0+nλ∑w∣w∣
- L2正则: C = C 0 + λ 2 n ∑ w w 2 C=C_{0}+\frac{\lambda}{2 n} \sum_{w} w^{2} C=C0+2nλ∑ww2
n为样本个数。
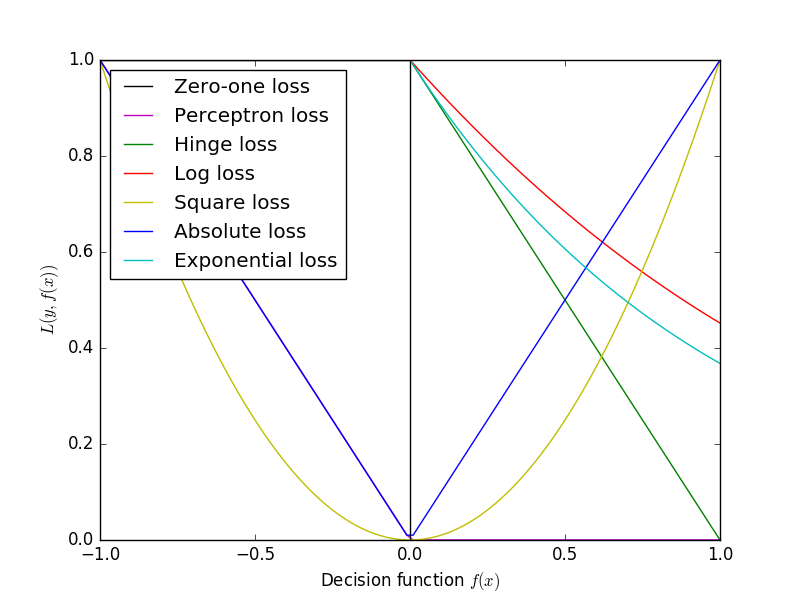
各损失函数的图像如下:
16.源码解释
官方文档:
keras.layers.AveragePooling1D(pool_size=2, strides=None, padding=‘valid’, data_format=‘channels_last’)
参数
- pool_size: 整数,平均池化的窗口大小。
- strides: 整数,或者是
None。作为缩小比例的因数。 例如,2 会使得输入张量缩小一半。 如果是None,那么默认值是pool_size。 - padding:
"valid"或者"same"(区分大小写)。padding的作用是选择卷积结果的shape。 - data_format: 字符串,
channels_last(默认)或channels_first之一。 表示输入各维度的顺序。channels_last对应输入尺寸为(batch, steps, features),channels_first对应输入尺寸为(batch, features, steps)。
源码使用格式:
ac{\lambda}{n} \sum_{w}|w|$
- L2正则: C = C 0 + λ 2 n ∑ w w 2 C=C_{0}+\frac{\lambda}{2 n} \sum_{w} w^{2} C=C0+2nλ∑ww2
n为样本个数。
各损失函数的图像如下:
16.源码解释
官方文档:
keras.layers.AveragePooling1D(pool_size=2, strides=None, padding=‘valid’, data_format=‘channels_last’)
参数
- pool_size: 整数,平均池化的窗口大小。
- strides: 整数,或者是
None。作为缩小比例的因数。 例如,2 会使得输入张量缩小一半。 如果是None,那么默认值是pool_size。 - padding:
"valid"或者"same"(区分大小写)。padding的作用是选择卷积结果的shape。 - data_format: 字符串,
channels_last(默认)或channels_first之一。 表示输入各维度的顺序。channels_last对应输入尺寸为(batch, steps, features),channels_first对应输入尺寸为(batch, features, steps)。
源码使用格式:
nn.AvgPool1d(scale, stride=1, padding=scale // 2)















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









