






 论文介绍了一种名为DSNet的视频摘要方法,结合检测与摘要网络结构,解决时序连贯约束问题。它采用anchor-based和anchor-free两种方法,利用GoogleNet特征提取和自注意力机制,通过IOU定义正负样本,生成摘要关键帧。亮点在于将目标检测技术应用到视频理解中。
论文介绍了一种名为DSNet的视频摘要方法,结合检测与摘要网络结构,解决时序连贯约束问题。它采用anchor-based和anchor-free两种方法,利用GoogleNet特征提取和自注意力机制,通过IOU定义正负样本,生成摘要关键帧。亮点在于将目标检测技术应用到视频理解中。
论文标题: DSNet: A Flexible Detect-to-Summarize Network for Video Summarization
代码链接:https://github.com/li-plus/DSNet
前言
首先什么是视频摘要?
就是将视频中的主要部分抽离出来生成一段新视频,用这段新视频可以概括原视频的内容。
由两种方式,第一种是直接提取视频中的关键帧合成新的视频。第二种是利用不同的镜头进行合成,本文是利用第二种方法。
摘要
本文针对有监督学习方法中没有时序连贯约束导致的,在同一语义段中视频帧的预测分数不能准确地表示相应片段的重要性的问题,提出了一种从检测到摘要的网络结构DSnet, 包括两种网络框架,分别为anchor-based method和anchor-free method。
anchor-based method:我们首先提供一个多尺度区间的proposals进行密集抽样 (这里我个人理解,proposals类似于yolov1里面的不同大小的anchor) , 然后提取其长期的具有时间依赖的特征,用于 proposal location 回归和重要性预测,这里分配了正负样本(后续提到是根据交并比来生成的)来用于生成摘要的正确性和完整性信息。
anchor-free method: 直接预测视频帧和片段位置的重要性分数。
具体方法
1.anchor-based method
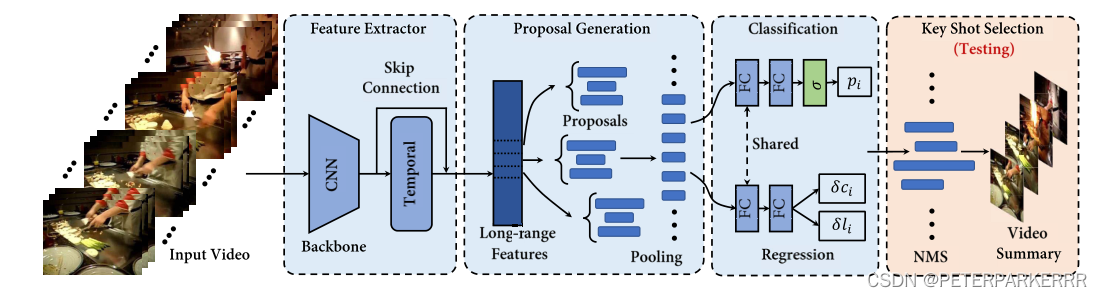
图片来自论文DSNet: A Flexible Detect-to-Summarize Network for Video Summarization
anchor-based method:
1)先对视频抽帧,一共T帧,然后用GoogleNet去掉后三层提取特征,输出通过自注意力机制,目的在于捕捉长时间的依赖关系(这里也可以替换成LSTM和GRU),再利用一个类似resnet的残差结构输出两路特征的加和,这里我理解的目的有两个,一是多尺度的信息聚合,防止信息丢失,二是防止梯度消失。
2)使用预定义的多尺度间隔生成 proposals。一段视频共有T帧,每一帧产生K个proposal,这样一共就是K*T个proposals, 假设第k个每个proposal的长度为lk,以时间节点t为中心,向前向后延申lk/2长度。
3)在训练阶段,分配二进制类标签,即正和负。为了缓解类别不平衡问题,以1:3的比例对正和负的proposal进行抽样。具体正负proposal是怎么界定的呢?这里引入交并比的概念(IOU),当proposal和groundtruth(简称GT)的IOU>0.6看作正样本,IOU = 0为负样本,介于0和0.3之间认定为未完成,视作负样本;0.3和0.6之间的proposal对摘要有负面效果,这有可能是由于积极和消极proposal之间的模糊性导致的。实验阶段设定的IOU阈值就是0.6。输出做了一个pooling操作,将提出的特征都统一尺度(这里其实暴力池化会丢失信息,但由于提取的是关联帧,所以可以看作相关性比较强所以这样处理也合理,个人理解)。
4)池化输出以后就有不同分支了,第一条分支用于正负样本的分类,第二条用于输出中心偏移量和长度偏移量。
5)NMS非极大值抑制。目标检测中也有这个,这里我个人理解就是yolov1筛选boundingbox的过程,很多个bounddingbox最后只留下2个,镜头之间存在较大重叠,因此抑制置信度也就是得分低的进行筛选。最终生成镜头组成摘要。
anchor-free method:
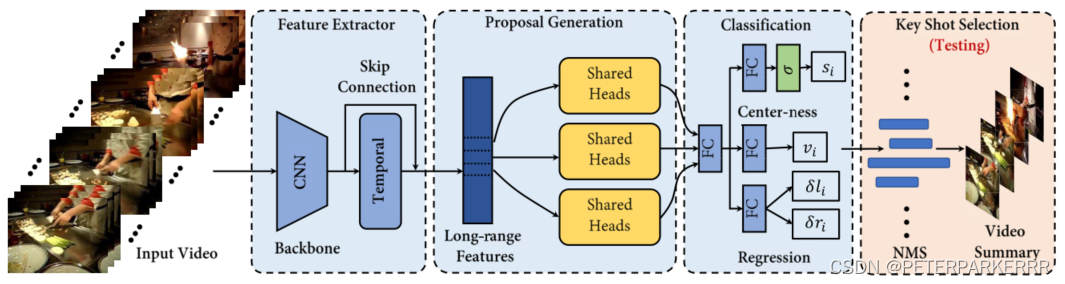
图片来自论文DSNet: A Flexible Detect-to-Summarize Network for Video Summarization
1)同上
2)不再生成proposals,直接预测每个视频帧的重要性分数、片段边界和中心度分数;
3)正负样本的生成方式为:如果在GT里面有第j帧,就是正样本,没有就是负样本;
4)特征提取后直接加一个公共的线性层,然后分成三路,分别用于正负样本的分类(每一帧),中心度预测,和左右边界损失。
5)NMS同上
总结
个人认为这篇文章最大的亮点在于,将图片目标检测的知识利用在了视频上,对于静态图片的检测中的anchor,在视频中变成了框帧长的anchor, 然后根据这段框出来的帧长进行一系列特征提取和预测任务,在视频理解方面提供了一种全新思路。

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









