







非连续分配的优点
- 一个程序的物理地址空间是非连续的;
- 更好地内存利用和管理;
- 允许共享代码与数据(共享库等…);
- 支持动态加载和动态链接。
非连续分配的缺点
建立虚拟地址和物理地址之间的转换开销大。
一、分段
1. 程序分段
- 程序 text 段:库、用户代码
- 程序数据
- 运行栈
- 堆
2. 段访问机制
-
程序访问内存地址的要求:段号 + 段内偏移
-
实现方案
- 段寄存器 + 地址寄存器实现方案
- 单地址实现方案
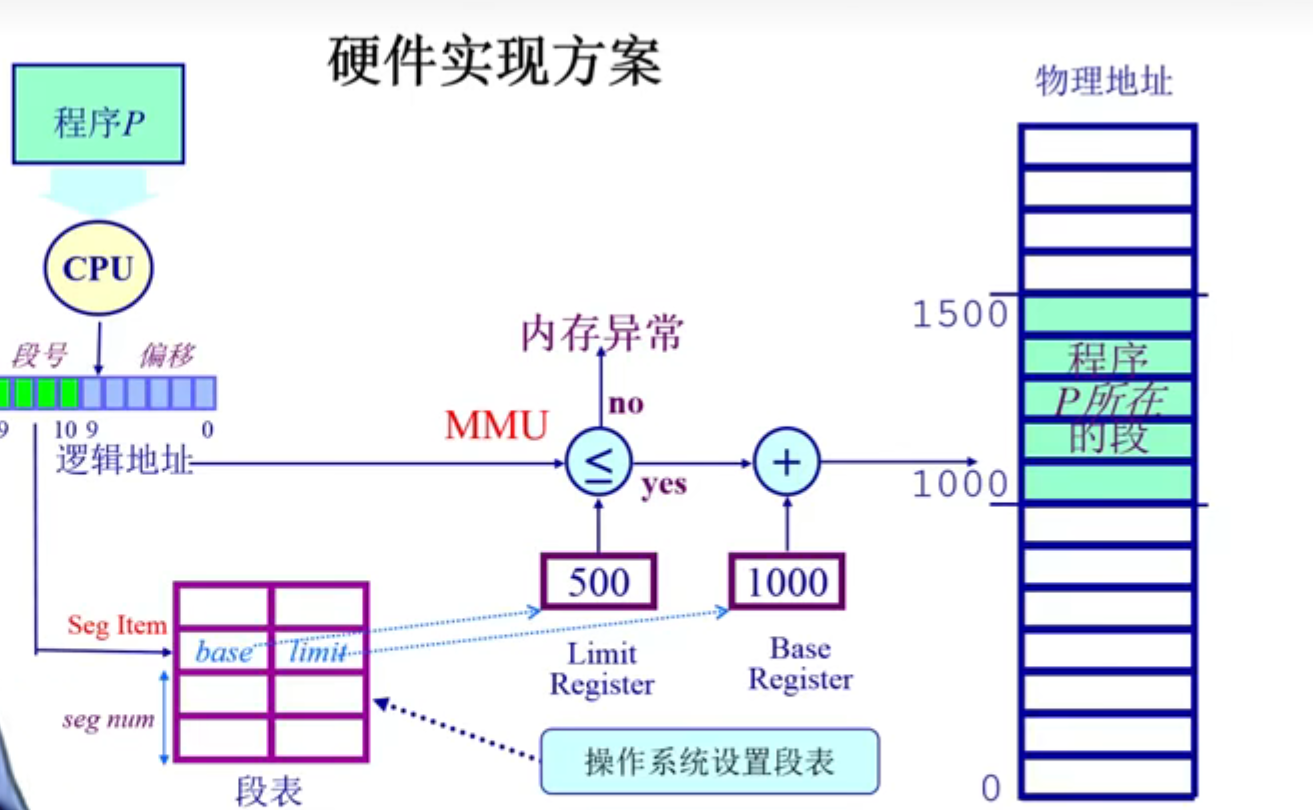
3. 硬件实现方案
二、分页
1. 分页机制
- 划分物理内存至固定大小的帧(大小是 2 的幂)
- 划分逻辑地址空间至相同大小的页(大小是 2 的幂)
- 建立方案转换逻辑地址为物理地址(页表、MMU/TLB)
- 页的大小和偏移块的大小是固定的
2. 帧(frame)
- 物理内存被分为大小相等的帧
- 一个内存物理地址是一个二元组:(帧号 f,帧内偏移 o)
- 物理地址 = 2 S ⋅ f + o 2^S · f + o 2S⋅f+o
3. 页(page)
- 一个程序的逻辑地址空间被划分为大小相等的页
- 页内偏移的大小 = 帧内偏移的大小
- 页号大小通常不等于帧号大小
- 逻辑地址二元组:(页号 p,页内偏移 o)
- 虚拟地址 = 2 S ⋅ p + o 2^S · p + o 2S⋅p+o
4. 页寻址机制
![![[Pasted image 20220802214618.png]]](https://img-blog.csdnimg.cn/65601af8ec9b4fa0879b7fcbb7c85c16.png)
- 页映射到帧
- 页是连续的虚拟内存
- 帧是非连续的物理内存
- 不是所有的页都有对应的帧
三、页表-概述、TLB
1.页表结构
- 每一个运行的程序都有一个页表,页表属于程序运行状态,会动态变化
- PTBR:页基址寄存器
- 页表项的内容:标志位 + 帧号
2. 分页机制的性能问题
- 访问一次内存单元需要两次内存访问:获取页表项、访问数据
- 页表占用空间可能非常大
- 处理方式:缓存(Caching)==> 时间、间接访问 ==> 空间
3. Translation Look-aside Buffer(TLB)
- TLB 在 CPU 里缓存近期访问的页帧转换表项
- TLB 使用 associative memory(关联内存)实现,具备快速访问性能
- 如果 TLB 命中,物理页号可以很快被获取到
- 如果 TLB 未命中,对应的表项被更新到 TLB 中。
注意:写代码时注意访问的局部性, TLB miss 之后的存入操作可能因为 CPU 的不同而由软件或硬件来完成。
四、页表-多级页表
- 通过把页表分为 k 个部分,来实现多级间接页表,建立页表树;
- 对于那些不存在映射关系的页表,其后面的低级别页表均不存在,因此节省了空间;
- 多层页表的查询消耗了更多的时间
五、页表-反向页表
不是让页表与逻辑地址空间的大小相对应,而是让页表与物理地址空间的大小相对应。逻辑地址空间增长速度快于物理地址空间。
1. 页寄存器
- 每个帧和一个寄存器关联;
- 寄存器内容:resident bit(此帧是否被占用)、occupier(对应的页号 p)、protection bit(保护位)
- 优势:转换表的大小相对于物理内存来说很小,且和逻辑地址空间的小无关;
- 劣势:需要的信息对调了,即根据帧号可以找到页号,需要在反向页表中搜索想要的页号。
2. 基于哈希查找的方案
在反向页表中通过哈希算法来搜索一个页对应的帧号。















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









