







目标检测论文阅读笔记
目标检测论文阅读 SPPNet Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition-CSDN博客
目标检测论文阅读 Cascade R-CNN: Delving into High Quality Object Detection-CSDN博客
目标检测论文阅读 YOLO You Only Look Once:Unified, Real-Time Object Detection-CSDN博客
You Only Look Once:Unified, Real-Time Object Detection 统一实时对象检测
Abstract
Yolo将目标检测定义为单个回归问题,直接从图像像素得到bounding box坐标和类别概率
YOLO使用单个卷积网络来同时预测多个bounding boxes和这些框的类别概率。它有以下优点:
(1)速度非常快,将检测视为回归问题,不需要复杂的组件,只需对一张测试图像运行网络来预测即可
(2)YOLO在预测时会对图像进行全局推理,YOLO在训练和测试时看到的是一整张图像,所以它隐含地编码了关于类别和外观的上下文信息,能够对背景产生较少的误报;
(3)YOLO学习目标的泛化表示,在自然场景上训练,在艺术作品上测试效果也不错
缺点:
尽管YOLO可以快速识别图像上的目标,但它很难精准定位一些目标,尤其是小目标。
2. Unified Detection 统一检测
首先会把输入图片分成S× S个格子(grid cell),如果一个目标的中心落入了某个格子内,那么这个格子就负责检测这个目标。每个格子会预测B个边界框--bounding boxes和它们对应的置信度分数--confidence scores。confidence scores反映的是模型对于这个box包含目标的信心,以及它认为box预测的准确度:![]() 如果没有目标存在于这个格子内,confidence score为0,否则的话confidence score等于预测的box和ground truth之间的IOU。(看来Pr(Object)要么为0,要么为1)。有的物体有多个单元格可以定位,此时非极大值抑制。
如果没有目标存在于这个格子内,confidence score为0,否则的话confidence score等于预测的box和ground truth之间的IOU。(看来Pr(Object)要么为0,要么为1)。有的物体有多个单元格可以定位,此时非极大值抑制。
每个bounding box会涉及到5个预测值,x,y,w,h,confidence,(x,y)表示的是目标的中心点坐标,相对于网格单元边界的(0~1)。w,h是相对于整个图像的。
每个格子还会预测每类目标概率值![]() (confidence是每个box都会有的,但条件概率值是每个网格才有的,也就是每个网格的B个box是共享这一组值的)
(confidence是每个box都会有的,但条件概率值是每个网格才有的,也就是每个网格的B个box是共享这一组值的)
将条件概率值和单个box的confidence相乘:![]() 即可得到这个box对每类目标的confidence score,这些scores不仅编码了该类出现在box中的概率,还表示了预测的box与gt的IOU。
即可得到这个box对每类目标的confidence score,这些scores不仅编码了该类出现在box中的概率,还表示了预测的box与gt的IOU。
预训练使用224*224的图像训练ImageNet,预训练好后使用预训练网络的前20个卷积层+平均池化层+全连接层,(其他论文说明:在预训练的网络中同时添加卷积层和连接层可以提高性能)再加4层卷积和2层全连接(随机初始化权重)去训练检测任务,输入大小为448×448
最后一层会同时输出类别概率和box的坐标。利用图像的宽和高对box的宽和高做归一化,使其介于0和1之间(box的宽高/原图像的宽高)。将box的x和y坐标参数化为特定网格单元位置的偏移量,因此它们也在0和1之间。
损失函数:
(1)损失函数简单粗暴地选择了平方差函数(因为好优化),但它将定位误差与分类误差同等地考虑,可能效果不佳。
(2)此外,图像中会有很多网格不包含任何目标,这些网格的confidence score为0,这么多的空网格会挤占包含目标的网格在损失函数中的比重,解决方法:增加有目标网格比重,减小空网格比重![]() 。
。
(3)此外,小的bbox的偏差应当比大的bbox同尺寸的偏差影响要大,解决方法:使用bbox的宽和高的平方根来计算,而不是宽和高本身。
(4)每个网格单元预测多个bounding boxes。在训练时,我们希望对每个目标只有一个bbox预测器对其负责。通过与gt的IOU选择这个bbox
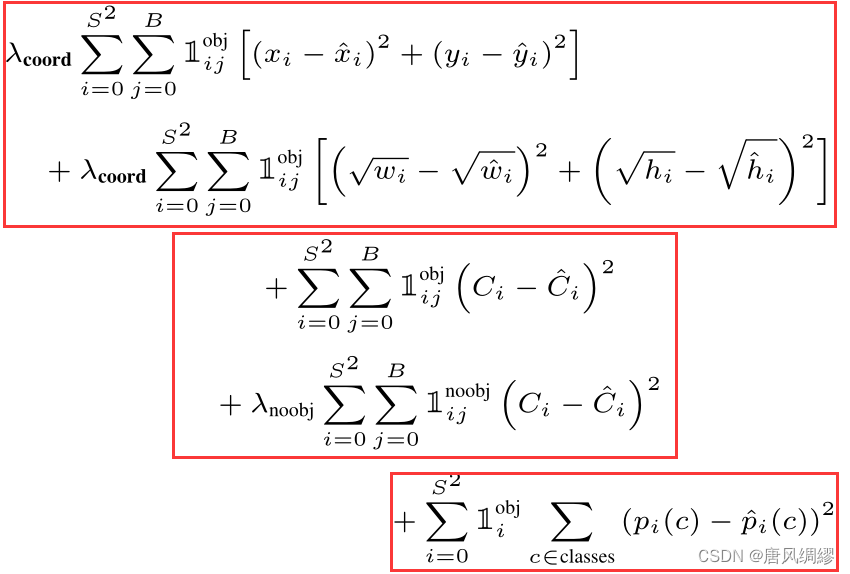
坐标的损失,![]() 意为对象是否出现在单元格i中。
意为对象是否出现在单元格i中。![]() 第i个单元格中的第j个bbox是否负责该object
第i个单元格中的第j个bbox是否负责该object
第一项:坐标的损失。xy直接平方差,wh决定了预测框的大小,为满足(3),先开根,在平方差。在这两项前面加![]() 满足(1)。
满足(1)。
第二项:confidence损失。C是目标信息得分。那对于noobj单元格Ci=0,损失函数项需要乘![]() 以满足(2)。
以满足(2)。
第三项:类别损失。P(C)指![]() ,每个单元格有C个P(C),或者说P(C)是C维向量。代表这个有目标的单元格中的目标属于每一类的概率。
,每个单元格有C个P(C),或者说P(C)是C维向量。代表这个有目标的单元格中的目标属于每一类的概率。
YOLO的局限性:
YOLO对bounding box预测施加了很强的空间约束,每个网格只预测两个box并且只能有一个类别。这种空间约束限制了模型可以预测的邻近物体的数量,比如在检测成群出现的小物体
模型从数据中学习预测bounding box,因此它很难泛化到新的/不常见的纵横比的目标。















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









