






目录
一、论文思想
1.将一个图像分成S*S个网格(grid cell),如果某个object的中心落在这个网格中,则这个网络就负责预测这个object。
2.每个网格要预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个的类别分数。
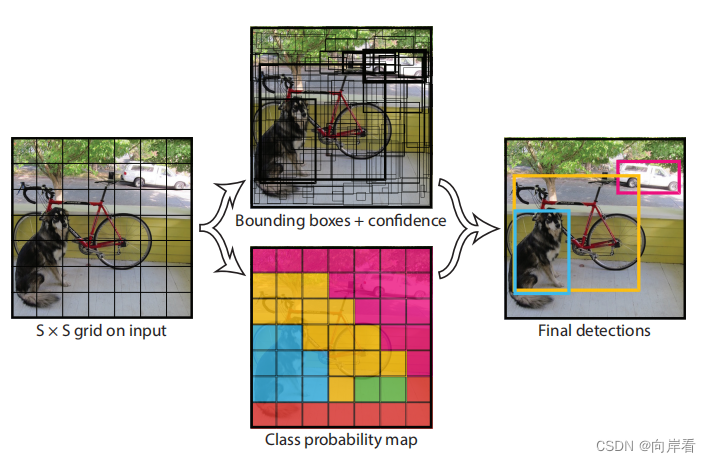
bounding box的含义:
bounding box由5个数值组成,分别为x,y,w,h,confidence,其中(x,y)是相对于grid cell预测目标的中心位置参数,(w,h)是相对于整个图像预测目标的中心位置参数,confidence值为预测目标与真实目标的交并比。

confidence分数:
本文中提到confidence分数定义的地方有两处:
pr(Object)是一个布尔值,当检测到有目标对象时为1,否则为0,因此我们可以变相的认为confidence就是IoU值。
![]()
下图为上图公式的推导过程。

二、网络结构
yolo的网络模型结构,如下图所示:

训练过程:
1.首先,输入图像先经过一个7x7,步距为2的卷积层,再经过一个2x2,步距为2的下采样,再经过类似的5组卷积层和池化层,输出一个7x7x1024的特征图。
2.其次,将特征图进行展平(flatten)处理,再经过两个全连接层,得到一个长度为1470的特征向量
3.最后,将特征向量reshape为一个7x7x30的特征矩阵
(除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数)
最终输出的是一个7 x 7 x 30的张量。
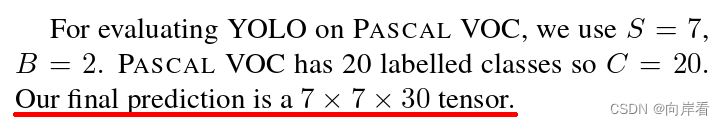
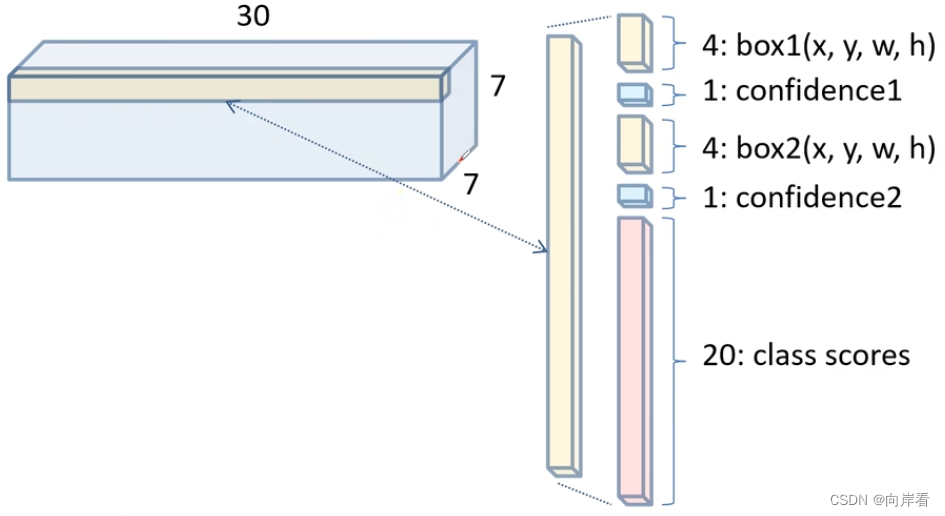
Feature map结构,如下图所示:
沿着深度方向的每一行包含30个数组,分别为2个bounding box + 2个confidence值 + 20个类别分数,每个bounding box又包含4个值,这4个值为目标的坐标信息。
三、训练
1.Leaky Relu激活函数
除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数

2.损失函数

该损失函数为误差平方和,最终的损失共包含三个部分,分别为bounding box损失、confidence损失、classes损失。以保证误差值不偏向大目标或小目标。
四、实验
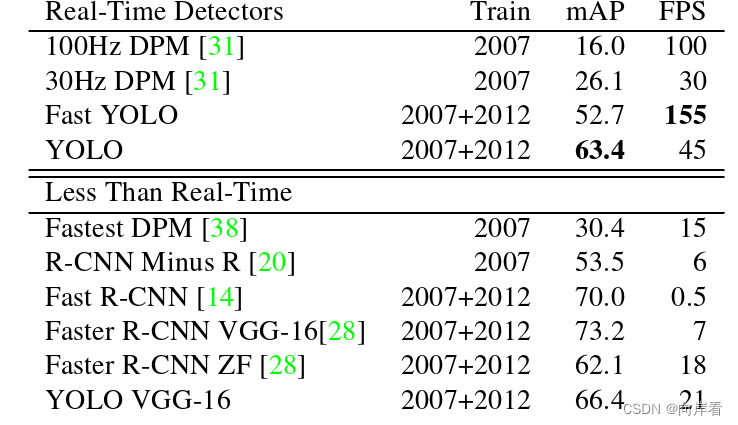
数据集:Pascal VOC 2007和2012
对比网络:R-CNN Minus R、Fast R-CNN、Faster R-CNN、DPM
对比结果:
五、结论
yolo网络可以同时预测一张图像中的所有类别的所有边界框,再通过confidence分数判断是否对框包含目标对象,只需要一次网络评估,来加快模型预测检测的速度。
















 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











