







目标检测论文阅读笔记
目标检测论文阅读 SPPNet Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition-CSDN博客
目标检测论文阅读 Cascade R-CNN: Delving into High Quality Object Detection-CSDN博客
目标检测论文阅读 YOLO You Only Look Once:Unified, Real-Time Object Detection-CSDN博客
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition---深度卷积网络中使用空间金字塔实现视觉识别
1 INTRODUCTION
原有的卷积神经网络对图像的输入有固定的要求---必须是224*224,这会降低对于原本不是该尺寸的图像的识别效果。 论文采用了空间金字塔池化的策略,无视图像的大小尺寸来生成固定长度的表达。
原本为了是图像满足输入有求(224*224),需要裁剪/仿射变换图像,导致内容缺失/集合扭曲,进而影响识别精度。另外,输入的图像中的对象的尺度可能变换(如两张相同尺寸的图像,一张是某人的合影,另一张的该人的证件照),这会导致预定义的网络参数不再适用。
那么要固定输入尺寸的原因是? CNN由卷积层和全连接层组成,前者不需要固定输入大小,可以输出任意大小的特征映射。固定大小限制只来自完全连接的层,它们存在于网络的更深阶段。
论文的解决方案是在最后一个卷积层之后添加一个空间金字塔池化层,输出固定长度的输出给全连接层。换句话说,我们在网络层次结构的更深阶段(在卷积层和全连接层之间)执行一些信息“聚合”,以避免在开始时需要裁剪或扭曲。
SPP(空间金字塔池化)的前身为SPM(空间金字塔匹配),是在深度学习兴起之前火热的目标检测算法
论文开发了一种多尺度训练方法:通过多个共享所有参数的网络来近似一个接受可变输入大小的单个网络。每一轮训练(epoch)我们用相同的输入大小,不同的epoch用不同的输入大小。
在RCNN上改进:
RCNN的特征计算是耗时的,因为它反复将深度卷积网络应用到每张图像数千个扭曲区域的原始像素上。论文证明了可以在整个图像上只运行一次卷积层(不管窗口的数量),然后用SPP-net在特征映射上提取特征。
2.具有空间金字塔池的深度网络
将最后一个池化层改为空间金字塔池化层(SPP)

SPP的输出是km维向量,m是桶/块的数量(如图中有1+4+16个块),K是最后一个卷积层中卷积核的数量(即每个块产生一个K维向量)
有了空间金字塔池化,输入图像就可以是任意尺寸了。不但允许任意比例关系,而且支持任意缩放尺度。我们也可以将输入图像缩放到任意尺度、并且使用同一个深度网络。当输入图像处于不同的尺度时,带有相同大小卷积核的网络就可以在不同的尺度上抽取特征。
网络训练:
SPPnet存在问题:反向传播开销大
单一尺寸训练:
作者首先考虑接收裁剪成224×224图像的网络。对于一个给定尺寸的图像,我们先计算空间金字塔池化所需要的块(bins)的大小。试想一个尺寸是a x a(也就是13×13)的第五层卷积后得到的特征图。对于n x n块的金字塔级,我们实现一个滑窗池化过程,窗口大小为win = 上取整[a/n],步幅str = 下取整[a/n]. 对于i层金字塔,我们实现i个这样的层。然后将i个层的输出进行连接,输出给全连接层。
单尺寸训练并非SPPnet所特有的(没发挥出SPP层的作用),以往的图像识别算法如RCNN也可以,作者使用单尺寸训练的目的是测试SPP层对CNN的影响。
多尺寸训练:
输入为不同尺寸,并且包含空间金字塔池化,目的是模拟多尺度输入的训练。作者预先设定了2个尺寸,224*224和180*180,,180通过224缩放得到。这样,不同尺度的区域仅仅是分辨率上的不同,而不是内容和布局上的不同。
两个尺寸独立训练两个网络,两个网络卷积层用相同的参数(池化层不需要参数)。这样的本质是通过共享参数的多个固定输入的网络实现了不同尺寸输入的SPPNet。
为了降低从一个网络(比如224)向另一个网络(比如180)切换的开销,我们在每个网络上训练一个完整的epoch,然后在下一个完成的epoch再切换到另一个网络(权重保留)。依此往复。实验中我们发现多尺寸训练的收敛速度和单尺寸差不多。
多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。
注意:
1、SPPnet的金字塔结构使之本身就具有处理多尺寸图像的能力,其实没必要用多尺寸训练(哪怕只单尺寸训练,预测阶段直接输入各种尺寸的图像也没问题)。多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸,并不必要。
2、上面的单尺寸或多尺寸方法只用于训练阶段。在测试阶段,是直接对各种尺寸的图像应用SPP-net。
 3.SPPnet目标检测
3.SPPnet目标检测
RCNN:
SPPnet:
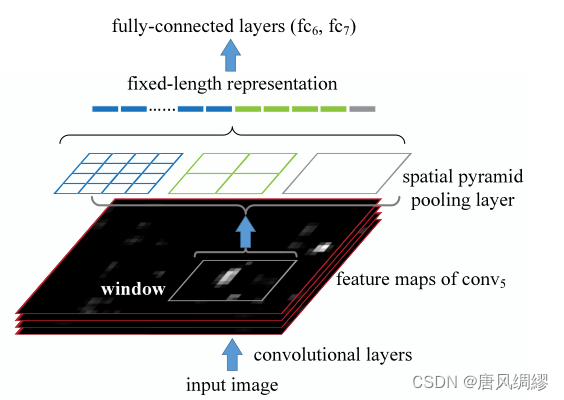
RCNN先找到ROI,ROI仿射变换后丢进CNN,然后CNN的输出做分类
SPPnet整张图像扔进CNN,卷积后,把ROI区域SPP,SPP后固定长度特征输入全连接层,全连接层输出做分类
SPM
SPP(空间金字塔池化)的前身为SPM(空间金字塔匹配),是在深度学习兴起之前火热的目标检测算法

原始方法是首先提取原图像的全局特征,然后在每个金字塔水平把图像划分为细网格序列,从每个金字塔水平的每个网格中提取出特征,并把它们连接成一个大特征向量。
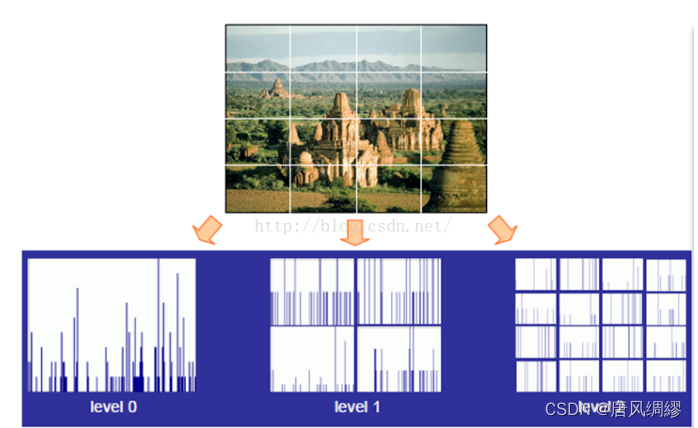
第0层是原始图像,第1层为4个cell ……
每个cell中提取固定长度的特征向量(设长度为K),
设一共有三层金字塔,最终特征是K+4K+16K维,与图像大小无关
但由于图像中每个局部区域反映的信息量不同,由此提出加权空间金字塔方法,即给每层每网格分配一个权重,按权重把每层每网格特征加权串联在一起。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









