






一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图。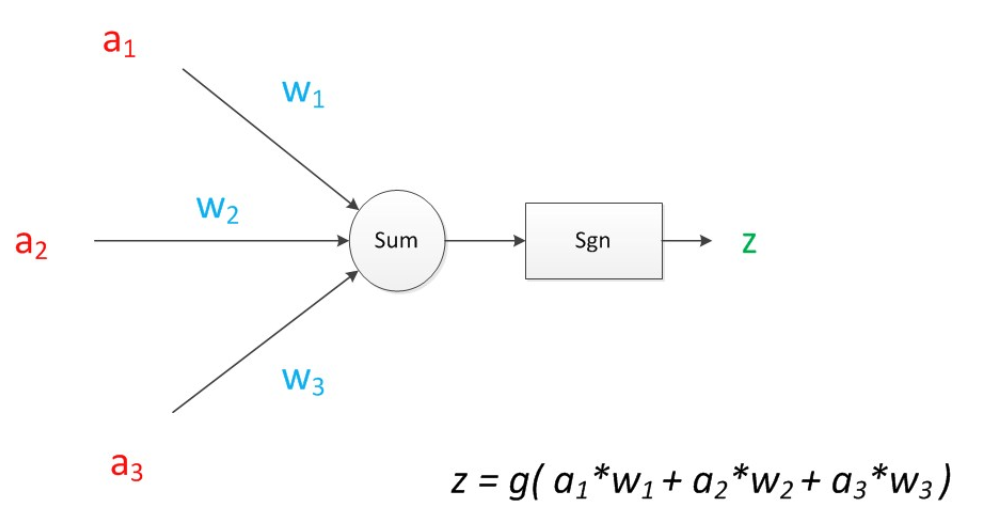
因此我们改用二维的下标,用wx,y来表达一个权值。下标中的x代表后一层神经元的序号,而y代表前一层神经元的序号(序号的顺序从上到下)。
例如,w1,2代表后一层的第1个神经元与前一层的第2个神经元的连接的权值(这种标记方式参照了Andrew Ng的课件)。根据以上方法标记,我们有了下图。
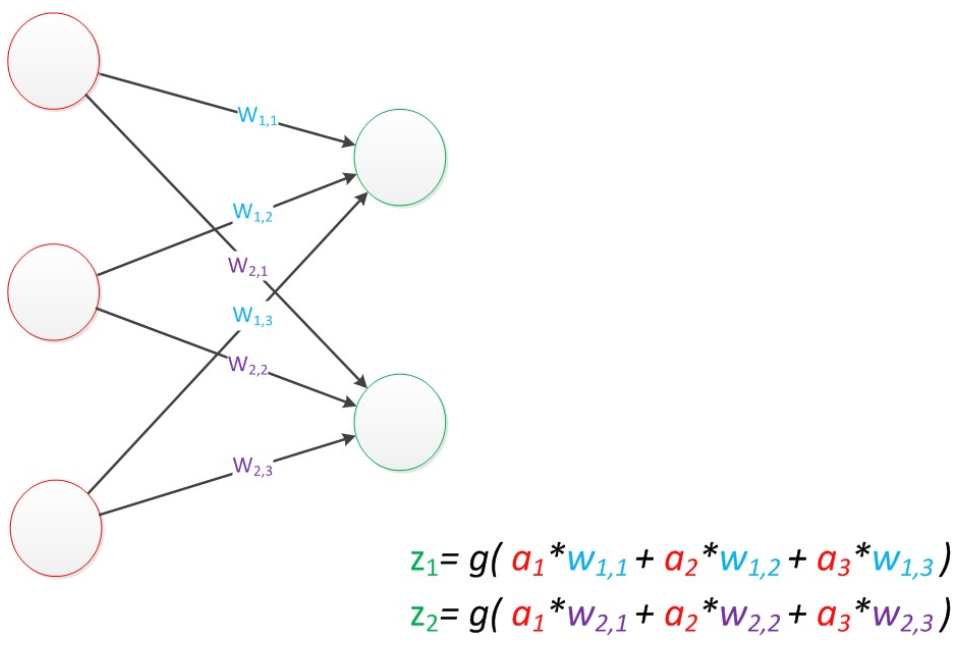
例如,输入的变量是[a1,a2,a3]T(代表由a1,a2,a3组成的列向量),用向量a来表示。方程的左边是[z1,z2]T,用向量z来表示。
系数则是矩阵W(2行3列的矩阵,排列形式与公式中的一样)。
于是,输出公式可以改写成:
g(W * a) = z;这个公式就是神经网络中从前一层计算后一层的矩阵运算。
我们可以用决策分界来形象的表达分类的效果。决策分界就是在二维的数据平面中划出一条直线,当数据的维度是3维的时候,就是划出一个平面,当数据的维度是n维时,就是划出一个n-1维的超平面。
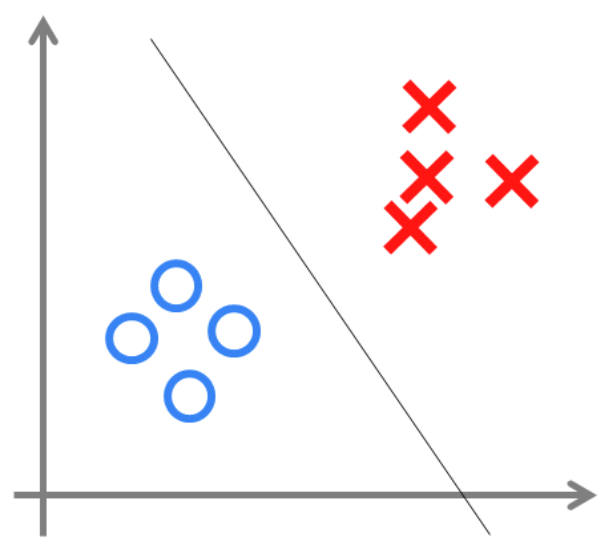
感知机:两层神经网络
例如ax(y)代表第y层的第x个节点。z1,z2变成了a1(2),a2(2)。下图给出了a1(2),a2(2)的计算公式。
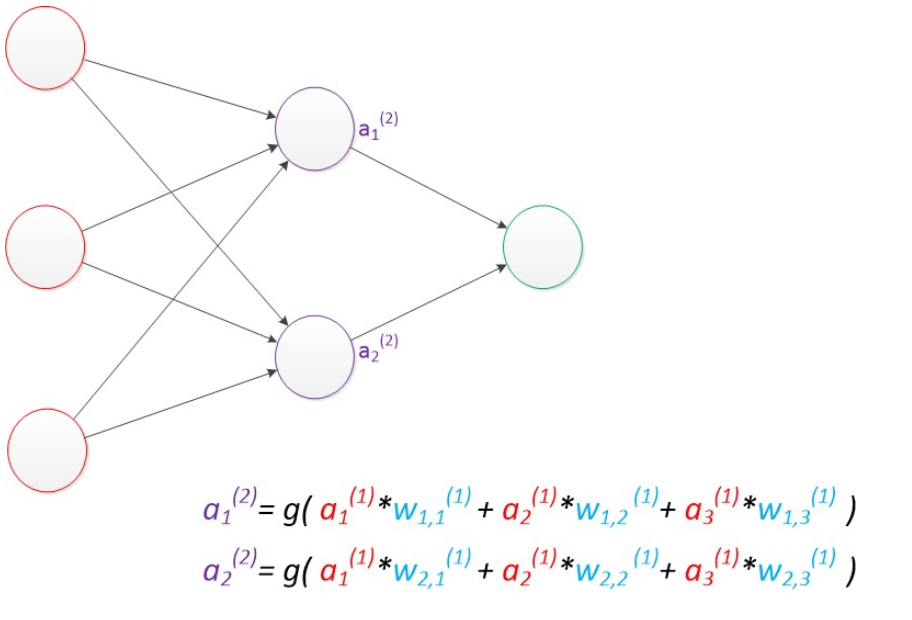
计算最终输出z的方式是利用了中间层的a1(2),a2(2)和第二个权值矩阵计算得到的,如下图。
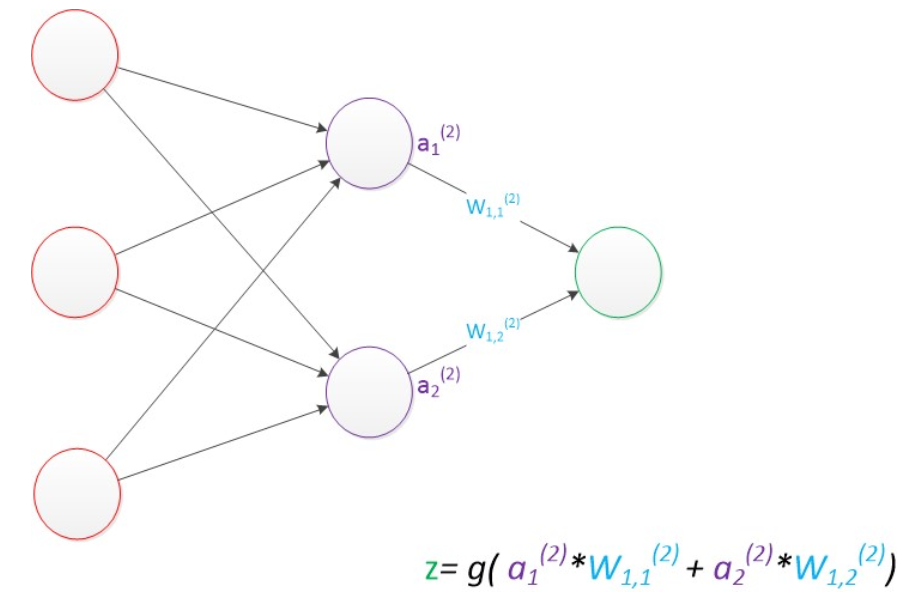
由此可见,使用矩阵运算来表达是很简洁的,而且也不会受到节点数增多的影响(无论有多少节点参与运算,乘法两端都只有一个变量)。因此神经网络的教程中大量使用矩阵运算来描述。
偏置节点很好认,因为其没有输入(前一层中没有箭头指向它)。有些神经网络的结构图中会把偏置节点明显画出来,有些不会。一般情况下,我们都不会明确画出偏置节点。
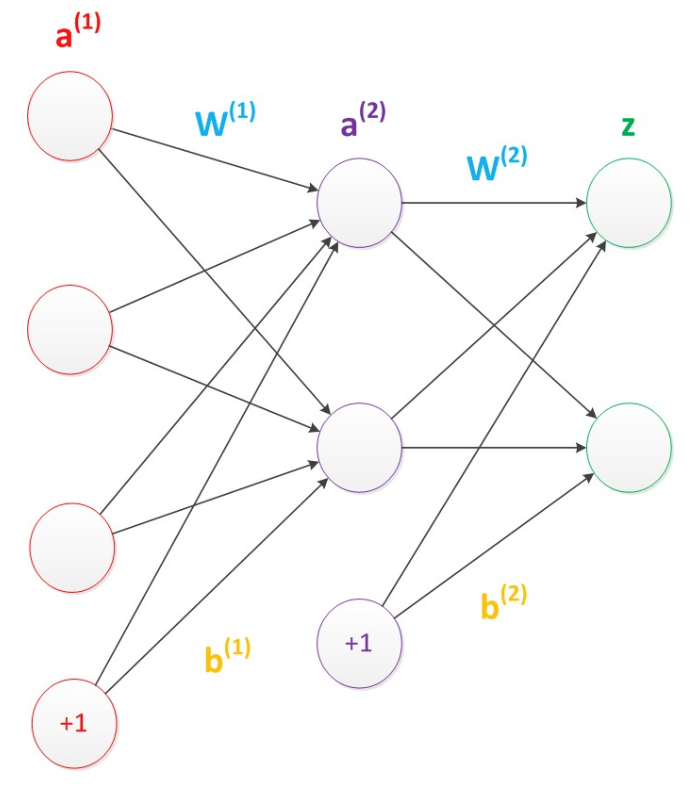
在考虑了偏置以后的一个神经网络的矩阵运算如下:
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
实现一个神经网络最需要的是线性代数库。
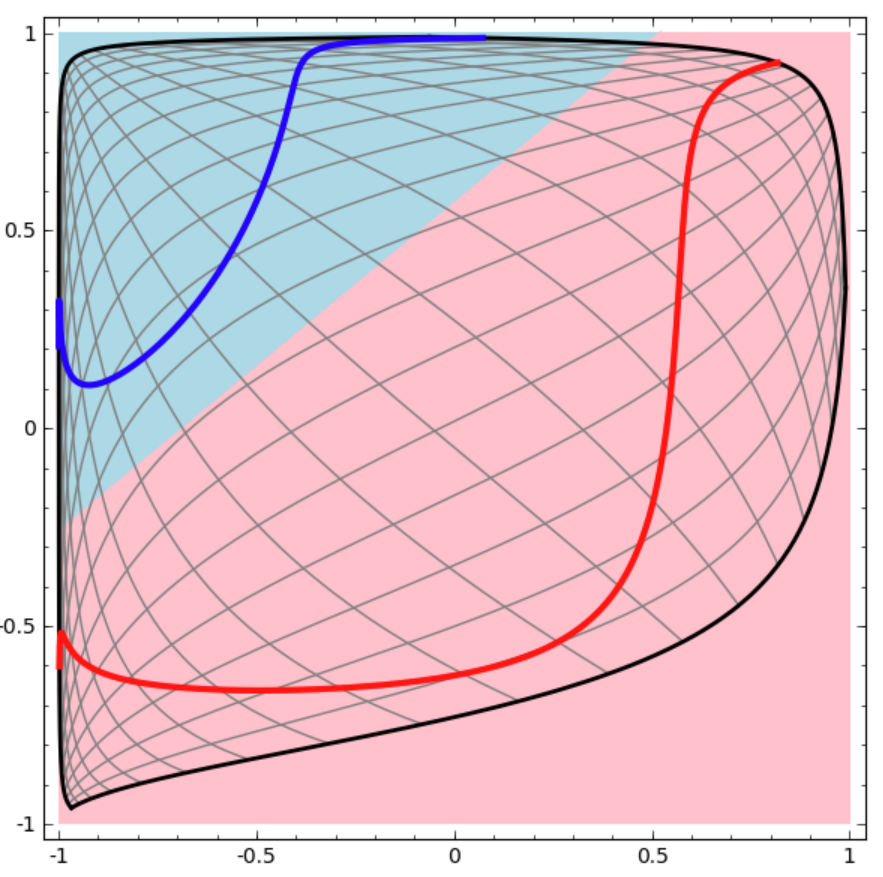
可以看到,输出层的决策分界仍然是直线。关键就是,从输入层到隐藏层时,数据发生了空间变换。也就是说,两层神经网络中,隐藏层对原始的数据进行了一个空间变换,使其可以被线性分类,然后输出层的决策分界划出了一个线性分类分界线,对其进行分类。 因此,隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分。
两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数。因此,多层的神经网络的本质就是复杂函数拟合。
下面来讨论一下隐藏层的节点数设计。在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。一般是根据经验来设置。较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,选择效果最好的值作为最终选择。这种方法又叫做Grid Search(网格搜索)。
多层神经网络(深度学习)
在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。所以可以得到下图。
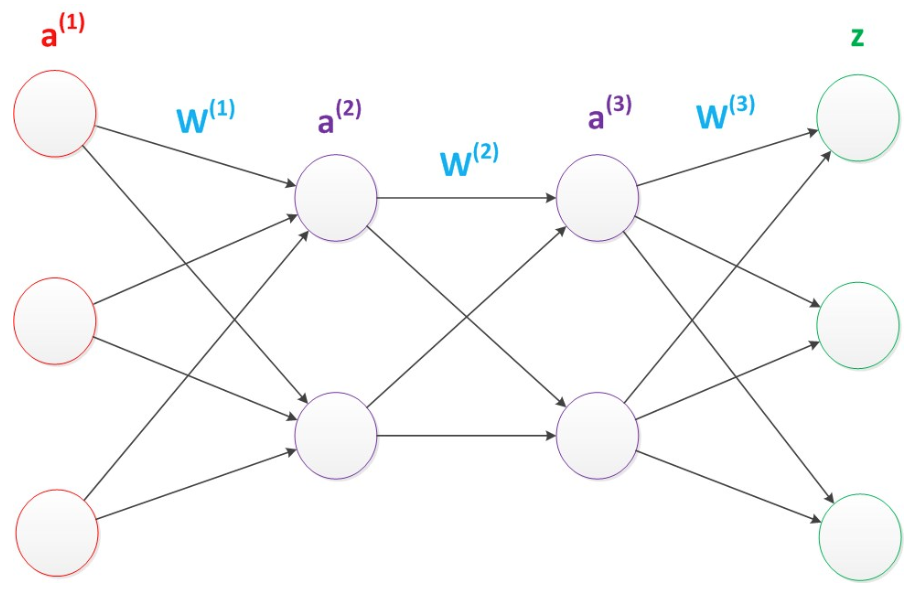
在已知输入a(1),参数W(1),W(2),W(3)的情况下,输出z的推导公式如下:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = a(3);
g(W(3) * a(3)) = z;















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









