







文章目录
A Simple Framework for Text-Supervised Semantic Segmentation
摘要
文本监督语义分割是一个新颖的研究课题,它允许在图像文本对比的情况下出现语义片段。然而,开创性的方法可能受制于专门设计的网络架构。
本文证明了一般对比语言图像预训练(CLIP)模型本身就是一种有效的文本监督语义分割器。
首先,我们揭示了普通CLIP不如定位和分割,因为它的优化是由密集对齐的视觉和语言表示驱动的。
其次,我们提出了局部驱动对齐(LoDA)来解决这个问题,其中CLIP优化是通过稀疏对齐局部表示来驱动的。
第三,我们提出了一个简单分割(SimSeg)框架。LoDA和SimSeg联合改进了一个普通的CLIP,产生了令人印象深刻的语义分割结果
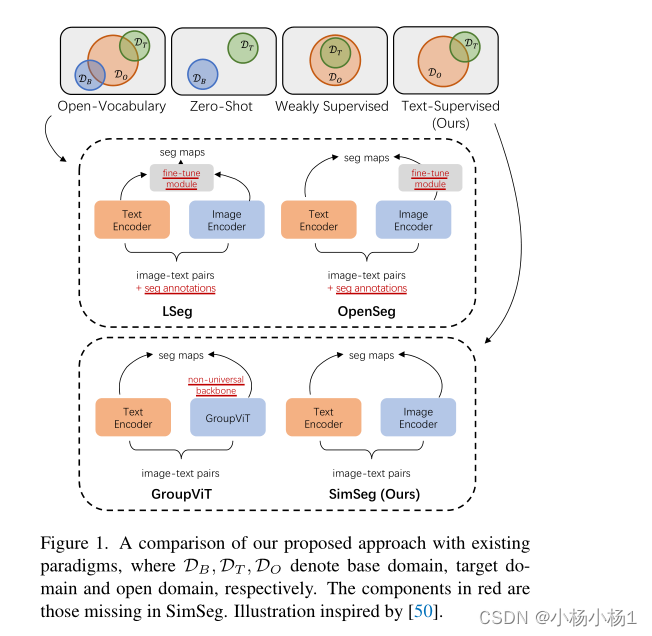
本文方法
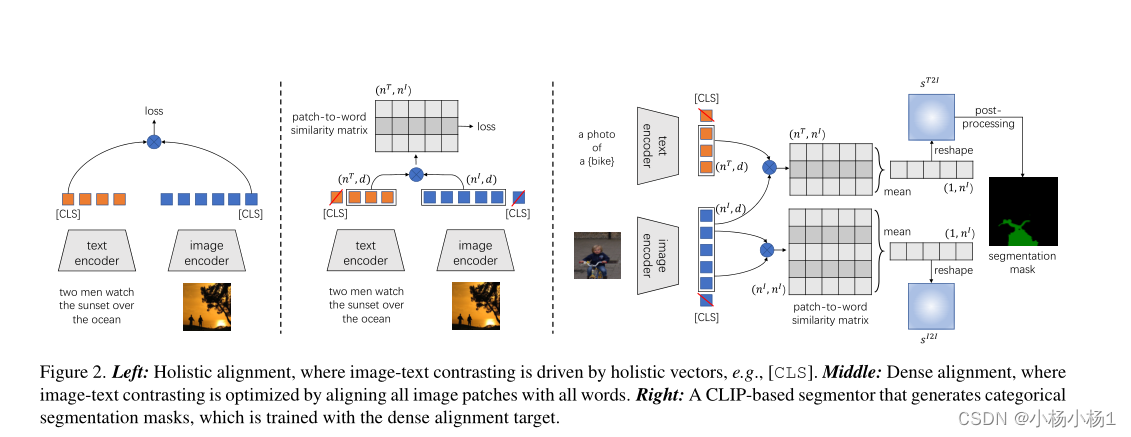
左:整体对齐,其中图像-文本对比是由整体向量驱动的,例如[CLS]
中间:密集对齐,通过将所有图像patch与所有单词对齐来优化图像文本对比
右:一个基于CLIP的分割器,生成分类分割掩码,使用密集对齐目标进行训练
上下文是一种统计特性,有助于人们和网络解决感知推理任务[30]。它在图像和文本理解任务中发挥着重要作用[30,32]。
为了更好地描述视觉概念,我们定义了“上下文词”和“非上下文词”。在字幕中,上下文单词(如森林或海洋)指场景、环境等。非上下文单词(例如人、自行车或猫)指主要对象(或前景)。上下文像素和非上下文像素分别表示与上下文单词和非上下文单词相对应的图像区域。
问题1:视觉编码器关注上下文像素。
直观地,用于分割的编码器应该将非上下文像素视为图像的主要内容。
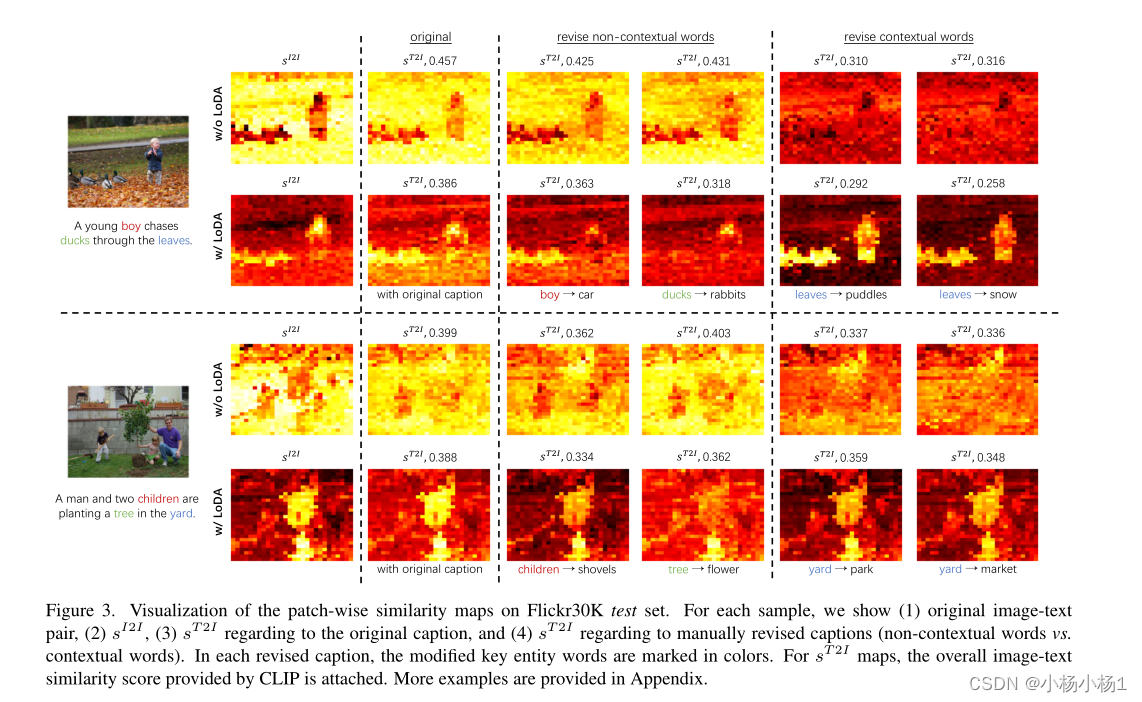
然而,我们的观察表明,CLIP的视觉编码器专注于上下文像素。如图3所示,为“w/o LoDA”行。
sI2I是关于全局图像特征的相似度图。它可以被解释为每个补丁特征对全局特征的贡献。上下文补丁具有较高的相似性(较亮的颜色),而非上下文补丁具有较低的相似性,表示上下文对全局特征的贡献更大。因此,视觉编码器关注上下文像素。
问题2:图文对比依赖于语境词。
一般来说,CLIP的训练是由对比正面和负面的图像-文本对驱动的。一批中的每个图像-文本对都会产生相似性得分,而InfoNCE损失会使正/负对的相似性最大化/最小化。在下面,我们手动替换图片说明中的关键词,观察图像文本相似性的变化,分析CLIP的图像文本对比行为
非语境词对对比的影响。当替换主要对象的单词(例如,“男孩!车”和“鸭子!兔子”)时,相似性图sT 2I几乎没有变化,如图3所示(没有LoDA)。同时,图文相似度得分也几乎没有变化(如“0.457!0.431”)。特别是“树!花”导致相似度得分的非理性上升(0.399到0.403)。因此,CLIP对非上下文单词的修订不敏感,即使是原始单词和修订单词也非常无关。
语境词对对比的影响。当替换上下文单词(例如,“yard!park”和“leaves!buddles”)时,相似性图sT 2I会发生剧烈变化。如图3(w/o LoDA)所示,相似性图变得比原始图暗得多。更重要的是,替换上下文单词会大大降低相似性得分(例如,“0.457!0.310”)。
动机
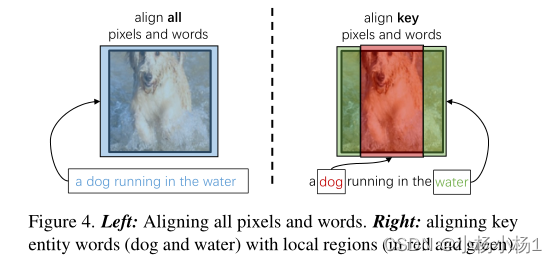
用于分割的通用CLIP模型应该自适应地感知主要对象和上下文。如图4(左)所示,并在第3.3节中证明,密集排列像素和单词将导致严重依赖上下文信息的琐碎解决方案。如图4(右)所示,理想的CLIP模型有望将关键实体词(如狗和水)与相应的局部像素(红色和绿色)对齐。如果模型得到充分优化,给定类名,则与该类相对应的像素区域将被强烈激活。防止CLIP的优化使像素和实体密集对齐是一种实用的策略。根据这一想法,我们提出了一种名为位置驱动对齐(LoDA)的策略

左图:该模型是通过位置驱动对齐(LoDA)与网络图像-文本对进行预训练的。
中间:模型被零样本转换为类别语义分割。
右:分类分割图被堆叠以基于置信度得分生成最终输出。
Locality-Driven Alignment(LoDA)
最大响应选择
为了实现局部驱动对齐(LoDA)训练范式,我们提出了一种称为最大响应选择的特征选择技术。它自适应地选择具有最大响应的局部特征
最大响应选择会自动选择每个通道上具有最大值的特征。这些特征被期望包含关于重要视觉概念和用于图像-文本对比的关键实体的局部信息,而不管上下文和非上下文。
Pre-training objective
与密集排列的紧凑特征f(xI)和g(xT)不同,LoDA旨在稀疏计算VI和VT的对比度损失。VI和VT分别表示来自图像区域和关键字的最大局部响应的特征。因此LoDA实现了最受关注的区域和单词的稀疏排列。更重要的是,LoDA进一步防止了模型在严重依赖上下文像素的情况下进行优化,因为建模上下文需要大量(即>MI)的特征
SimSeg Framework
我们提出了一个简单的分割框架(SimSeg),该框架基于具有LoDA的CLIP。对于每个原始图像,SimSeg首先为每个类别生成二进制分割掩码,然后将它们组合成分割图。
类别语义分割
我们的模型经过预训练,可以预测图像-文本对的感兴趣区域和关键实体词之间的相似性。为了执行零镜头语义分割,我们重用了这一功能。
如图5(中)所示,对于语义分割数据集,我们通过提示将类名转换为句子。一个例子可以是“一张{class}的照片”。
首先,我们通过各自的编码器计算图像和文本特征。由于输入的句子每个都包含一个类名,所以我们设置MT=1。将uT表示为排序后的文本特征g0(xT)的第一个元素,用作查询图像补丁的文本特征。接下来,我们取uT来计算每个图像块特征[f(xT)]k的相似性得分,生成粗略分割掩模。
应用诸如上采样和DenseCRF之类的后处理操作来细化粗略掩模。此外,我们基于uT和VI计算类置信度得分,这与预训练中的机制相同。
组合分类掩码
我们的模型结合了置信类的二进制掩码来产生最终结果,如图5(右)所示。我们计算一个自适应阈值来选择有信心的对象类,而不是使用固定值。我们使用平均值(µ)和标准偏差前半类的相似性分数
高分类的掩码将覆盖得分较低类的掩码,并且未分配给任何对象类的区域被确定为背景类。
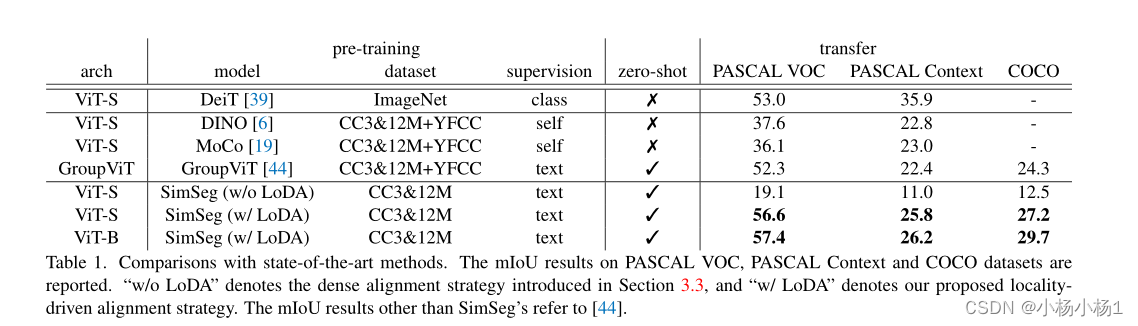
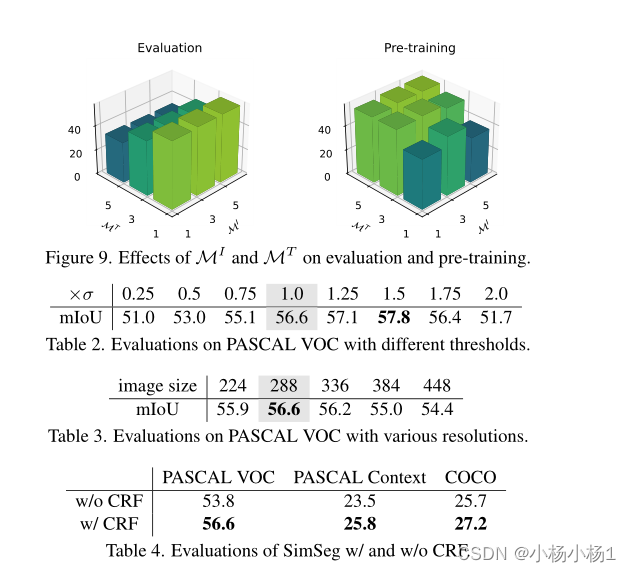
实验结果




















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











