







Prediction of Infant Cognitive Development with Cortical Surface-Based Multimodal Learning
摘要
探索认知能力与婴儿皮质结构和功能发育之间的关系对于促进我们对早期大脑发育的理解至关重要,然而,由于出生后早期大脑发育复杂而动态,这是非常具有挑战性的。传统方法通常使用结构性 MRI 或静息态功能性 MRI,并依靠皮质包裹后的区域水平特征或区域间连接特征来预测认知评分。然而,这些方法存在两个主要问题:1)空间信息丢失,它丢弃了包含与认知发展相关的丰富信息的关键细粒度空间模式;2)模态信息丢失,忽略了结构图像和功能图像之间的互补信息和相互作用。
本文发明了一种新的框架,即基于皮层表面的多模态学习框架(CSML),以利用细粒度的多模态特征进行认知发展预测。
首先引入了细粒度的表面数据表示,以捕获空间上详细的结构和功能信息。
然后,提出一种双分支网络,分别提取各模态的判别特征,并利用解纠缠策略进一步捕获模态共享和互补信息。
最后,基于认知随年龄发展的先验,开发了年龄引导的认知预测模块。
方法
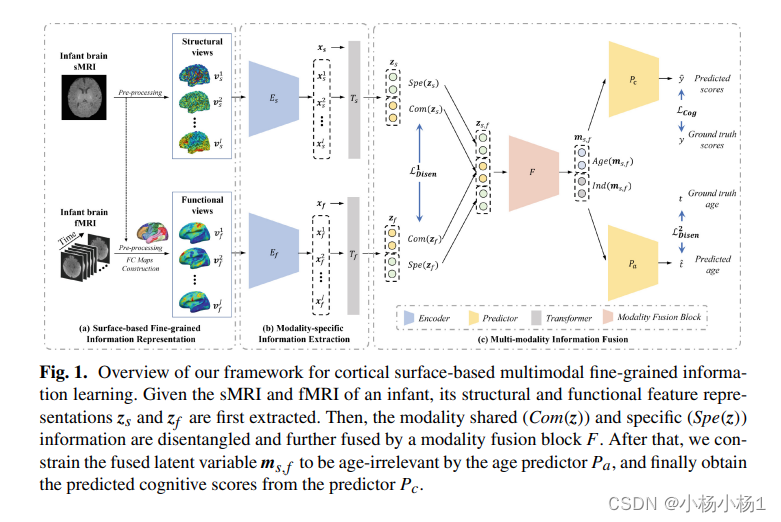
给定婴儿的 sMRI 和 fMRI,首先提取其结构和功能特征表示 zs 和 zf。然后,共享的模态 (Com(z)) 和特定 (Spe(z)) 信息被解开,并由模态融合块 F 进一步融合。然后,我们将融合的潜在变量ms,f约束为年龄预测因子Pa与年龄无关,最后从预测因子Pc获得预测的认知分数。
基于表面的细粒度信息表示
网络框架的输入由两个分支组成,分别用于编码皮层结构信息和功能连接信息。将所有模态数据映射到一个公共空间,即注册到 UNC 4D 婴儿表面图谱的皮质表面,并按照完善的管道进一步用 40,962 个顶点重新采样。为了在结构 MRI 中捕获空间细粒度信息,结构分支包含一组具有生物学意义的皮质特性的表面图,包括皮质厚度、表面积、皮质体积、沟深度、平均曲率和平均凸度。为了保留功能连接的细粒度空间模式,我们利用了婴儿专用的皮层功能覆盖图。首先计算所有顶点的平均功能时间序列与每个皮层顶点的功能时间序列之间的 Pearson 相关系数,以构建皮层功能连接 (FC) 映射,然后进行 Fisher 的 r-to-z 变换。最后,使用皮层 FC 图作为功能分支的输入,这些图表征了丰富的空间详细 FC 信息。
模态专用编码器
采用 Spherical Res-Net:f球形卷积层和球形池化层
模态融合模块
为了更好地学习两种模态之间的互补信息,我们进一步将模态特异性的潜在变量zs和zf分解为两部分:Com(zn)和Spe(zn),其中{s,f }分别代表结构(s)和函数(f)相关变量。Com(zn) 是表示模态之间共享信息的通用代码,而 Spe(zn) 是表示将一种模态与另一种模态区分开来的互补信息的特定代码。这种解纠的基本要求是:(1)Com(zn)和Spe(zn)的串联等于zn;(2)Com(zs)和Com(zf)应尽可能相似;(3) Spe(zs) 尽可能与 Spe(zf) 不同。因此,L1 Disen被定义为:
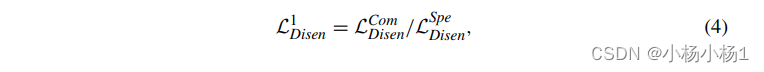
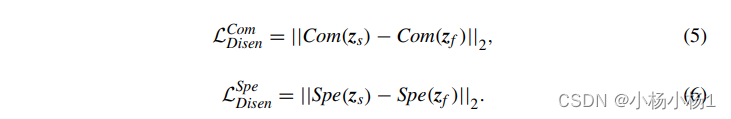
认知分数预测
给定组合的多模态信息zs,f,直接回归认知分数是很直观的。然而,考虑到认知功能在生命的最初几年发展迅速,回归者倾向于学习与年龄相关的信息,因此无法区分同一年龄组受试者之间的个体化发展差异。因此,我们通过MLP将组合的多模态信息融合如下,ms,f = F(zs,f),并进一步从ms,f中解析年龄相关方差Age(ms,f)和个体相关不变性Ind(ms,f),以精确评估认知发展水平。这种解缠的基本要求是:(1)Age(ms,f)和Ind(ms,f)的串联等于ms,f;(2)年龄(ms,f)能够通过年龄预测因子Pa进行年龄估计;(3) Ind(ms,f) 无法通过 Pa 进行年龄估计。 因此,L2 Disen 被定义为:
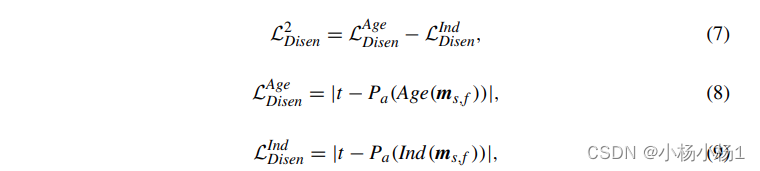

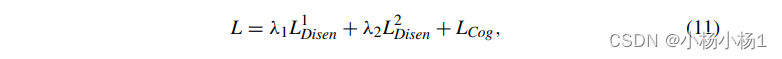
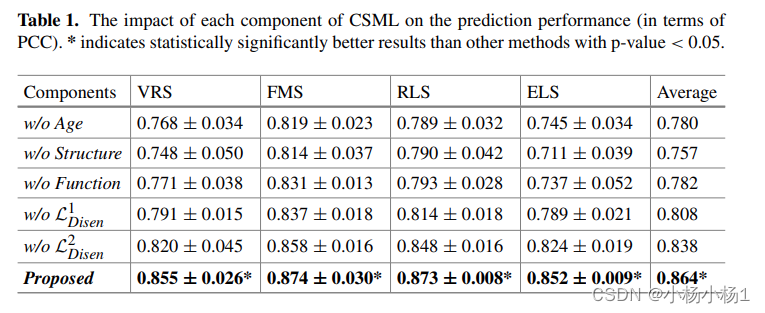
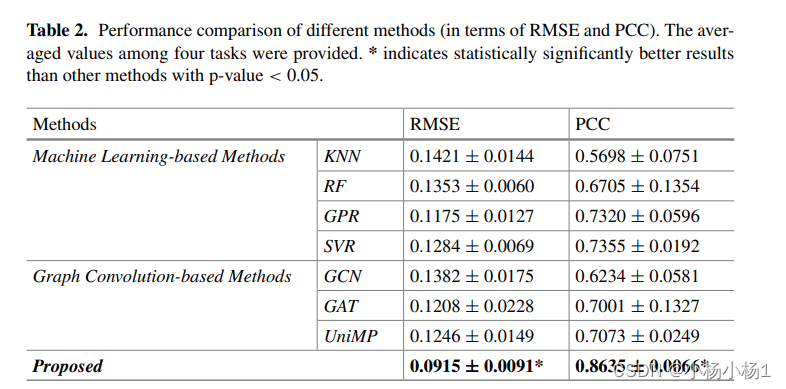
实验结果

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











